








 超级会员免费看
超级会员免费看

主要内容
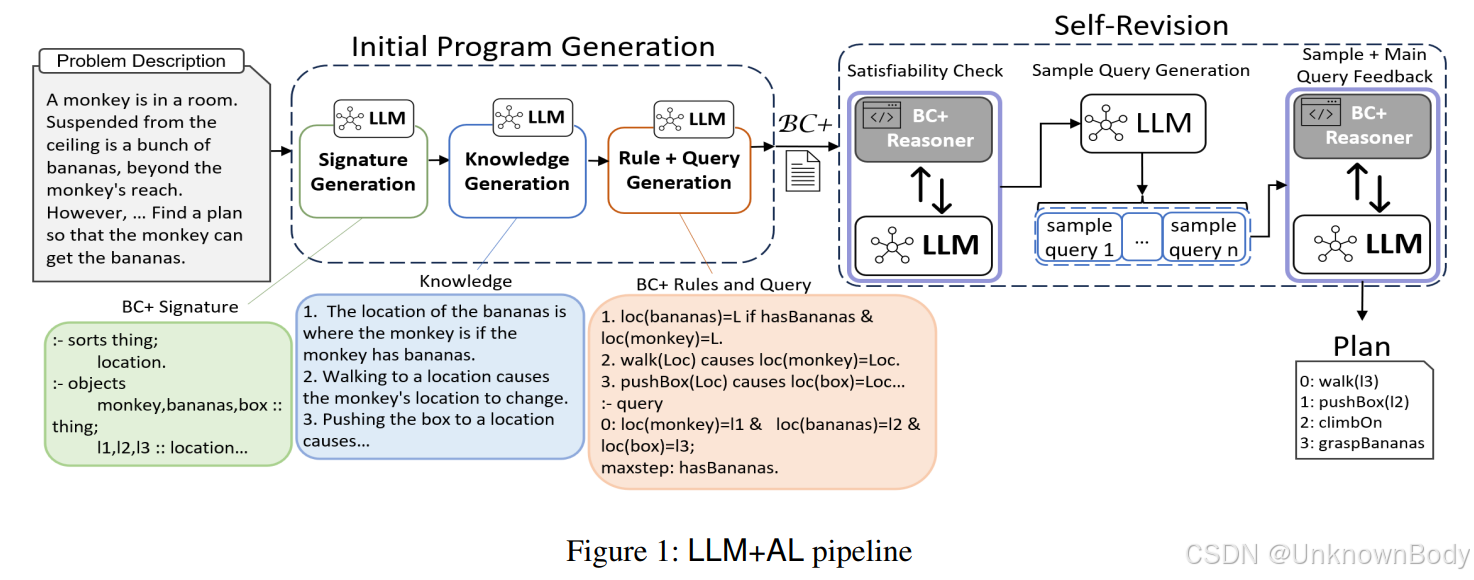
- 研究背景:大语言模型(LLMs)在复杂行动推理任务上存在局限,将其作为语义解析器转换自然语言为符号表示(如Python程序、PDDL等)的方法也有不足。行动语言在表示行动知识和推理方面有优势,但自动化生成存在挑战。
- 方法介绍:提出LLM+AL框架,结合LLMs的自然语言理解能力和行动语言的符号推理优势。该框架包含BC+签名生成、知识生成、BC+规则和查询生成以及自我修正四个主要组件,通过一系列提示引导LLM完成从自然语言问题描述到BC+程序的转换,并利用BC+推理器的反馈进行迭代修正。
- 实验评估:使用麦卡锡提出的传教士与食人族谜题(MCP)及其变体等基准测试,对比LLM+AL与CHATGPT-4、CLAUDE 3 OPUS等先进LLMs。结果表明,LLM+AL在解决复杂推理问题上表现更优,虽仍需少量人工修正,但能得出正确答案,而独立的LLMs即使在人工反馈下也难以改进。
- 结果分析:分析了LLMs在实验中出现的问题,如难以遵守状态约束、无法可靠区分可解和不可解问题、代码生成难以适应问题变化等。同时指出LLM+AL中BC+的声明性语义与LLMs配合良好,自我修正机制能显著提高BC+程序质量,且该方法从人工修正中受益。

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











