







 本文探讨了深度学习中的Lipschitz约束,解释了它如何提高模型的泛化性能。通过分析矩阵范数、谱范数和L约束,展示了其在神经网络中的应用,特别是对于生成模型如WGAN的重要性。作者介绍了谱范数正则化作为改进模型泛化的手段,并与梯度惩罚方案进行了对比,强调了谱归一化在WGAN中的优势。
本文探讨了深度学习中的Lipschitz约束,解释了它如何提高模型的泛化性能。通过分析矩阵范数、谱范数和L约束,展示了其在神经网络中的应用,特别是对于生成模型如WGAN的重要性。作者介绍了谱范数正则化作为改进模型泛化的手段,并与梯度惩罚方案进行了对比,强调了谱归一化在WGAN中的优势。

作者丨苏剑林
单位丨广州火焰信息科技有限公司
研究方向丨NLP,神经网络
个人主页丨kexue.fm
去年写过一篇 WGAN-GP 的入门读物互怼的艺术:从零直达WGAN-GP,提到通过梯度惩罚来为 WGAN 的判别器增加 Lipschitz 约束(下面简称“L 约束”)。前几天遐想时再次想到了 WGAN,总觉得 WGAN 的梯度惩罚不够优雅,后来也听说 WGAN 在条件生成时很难搞(因为不同类的随机插值就开始乱了),所以就想琢磨一下能不能搞出个新的方案来给判别器增加L约束。
闭门造车想了几天,然后发现想出来的东西别人都已经做了,果然是只有你想不到,没有别人做不到呀。主要包含在这两篇论文中:Spectral Norm Regularization for Improving the Generalizability of Deep Learning [1] 和 Spectral Normalization for Generative Adversarial Networks [2]。
所以这篇文章就按照自己的理解思路,对L约束相关的内容进行简单的介绍。注意本文的主题是 L 约束,并不只是 WGAN。它可以用在生成模型中,也可以用在一般的监督学习中。
L约束与泛化
扰动敏感
记输入为 x,输出为 y,模型为 f,模型参数为 w,记为:

很多时候,我们希望得到一个“稳健”的模型。何为稳健?一般来说有两种含义,一是对于参数扰动的稳定性,比如模型变成了 fw+Δw(x) 后是否还能达到相近的效果?如果在动力学系统中,还要考虑模型最终是否能恢复到 fw(x);二是对于输入扰动的稳定性,比如输入从 x 变成了 x+Δx 后,fw(x+Δx) 是否能给出相近的预测结果。
读者或许已经听说过深度学习模型存在“对抗攻击样本”,比如图片只改变一个像素就给出完全不一样的分类结果,这就是模型对输入过于敏感的案例。
L约束
所以,大多数时候我们都希望模型对输入扰动是不敏感的,这通常能提高模型的泛化性能。也就是说,我们希望 ||x1−x2|| 很小时:

也尽可能地小。当然,“尽可能”究竟是怎样,谁也说不准。于是 Lipschitz 提出了一个更具体的约束,那就是存在某个常数 C(它只与参数有关,与输入无关),使得下式恒成立:
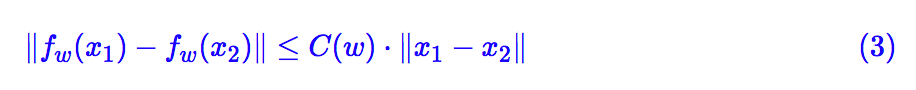
也就是说,希望整个模型被一个线性函数“控制”住。这便是 L 约束了。
换言之,在这里我们认为满足 L 约束的模型才是一个好模型。并且对于具体的模型,我们希望估算出 C(w) 的表达式,并且希望 C(w) 越小越好,越小意味着它对输入扰动越不敏感,泛化性越好。
神经网络
在这里我们对具体的神经网络进行分析,以观察神经网络在什么时候会满足 L 约束。
简单而言,我们考虑单层的全连接 f(Wx+b),这里的 f 是激活函数,而 W,b 则是参数矩阵/向量,这时候 (3) 变为:
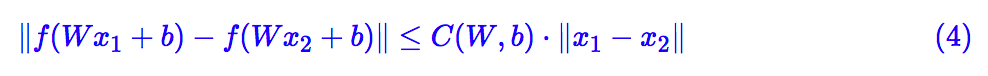
让 x1,x2 充分接近,那么就可以将左边用一阶项近似,得到:
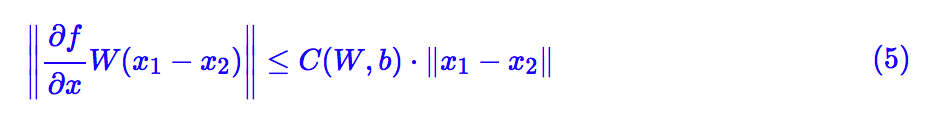
显然,要希望左边不超过右边,∂f/∂x 这一项(每个元素)的绝对值必须不超过某个常数。这就要求我们要使用“导数有上下界”的激活函数,不过我们目前常用的激活函数,比如sigmoid、tanh、relu等,都满足这个条件。假定激活函数的梯度已经有界,尤其是我们常用的 relu 激活函数来说这个界还是 1,因此 ∂f/∂x 这一项只带来一个常数,我们暂时忽略它,剩下来我们只需要考虑 ||W(x1−x2)||。
多层的神经网络可以逐步递归分析,从而最终还是单层的神经网络问题,而 CNN、RNN 等结构本质上还是特殊的全连接,所以照样可以用全连接的结果。因此,对于神经网络来说,问题变成了:如果下式恒成立,那么 C 的值可以是多少?
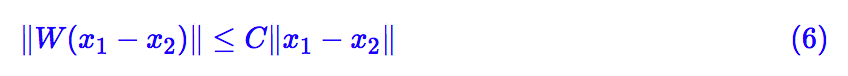
找出 C 的表达式后,我们就可以希望 C 尽可能小,从而给参数带来一个正则化项![]() 。
。
矩阵范数
定义
其实到这里,我们已经将问题转化为了一个矩阵范数问题(矩阵范数的作用相当于向量的模长),它定义为:

如果 W 是一个方阵,那么该范数又称为“谱范数”、“谱半径”等,在本文中就算它不是方阵我们也叫它“谱范数(Spectral Norm)”好了。注意 ||Wx|| 和 ||x|| 都是指向量的范数,就是普通的向量模长。而左边的矩阵的范数我们本来没有明确定义的,但通过右边的向量模型的极限定义出来的,所以这类矩阵范数称为“由向量范数诱导出来的矩阵范数”。
好了,文绉绉的概念就不多说了,有了向量范数的概念之后,我们就有:
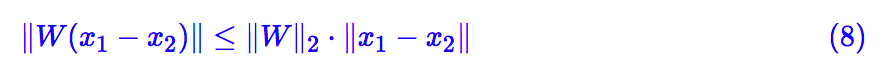
呃,其实也没做啥,就换了个记号而已,||W||2 等于多少我们还是没有搞出来。
Frobenius范数
其实谱范数 ||W||2 的准确概念和计算方法还是要用到比较多的线性代数的概念,我们暂时不研究它,而是先研究一个更加简单的范数:Frobenius 范数,简称 F 范数。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









