 手把手从0撸C语言编译器:词法到语义分析
手把手从0撸C语言编译器:词法到语义分析





神图镇楼
代码文件夹的内容:
首先,开头附上神图一张,这是为什么本人手撸完可能是全网最适合初学者学习的c语言教程之后,收录了将近两万行代码,突然心血来潮搞这么一出编译器、手撸os、手撸最小化系统、手撸100例趣味例程:
语法、100例子、牛客大厂题目单100、课程自学到现在的《巨作》
其实也就是我个人技术博客的一个延申和mark见证,两个月的时间写了将近两万行c,从语法到大场面试到最终的自学c语言所有常见考点,再写这么一个超级硬核超级底层的内容,也更多是为了给自己一个挑战
第一章:初探编译奥秘与词法分析的基石)
朋友们,你们有没有想过,我们每天敲打的C语言代码,那些看似简单的int main() { ... },那些熟悉的printf(),它们究竟是如何从一行行人类可读的文本,最终变成计算机中央处理器(CPU)能够直接执行的二进制指令的?这中间的魔法,就是编译器!
今天,我们要干一件大事!不是简单地使用编译器,而是要亲手撸一个编译器!是的,你没听错,我们要从零开始,一步步构建一个属于我们自己的C语言编译器。这不仅仅是一个技术挑战,更是一场对C语言“底裤”的终极解密,一次彻底吃透代码到机器码极致蜕变的深度之旅!
为什么我们要“手撸”编译器?
你可能会问:“现在不是有GCC、Clang这些强大的编译器了吗?为什么还要自己造轮子?” 问得好!这就是我们今天要点燃你激情的地方:
-
掀开C语言的“底裤”: 只有当你亲手去实现每一个编译阶段,你才会真正明白C语言的每一个语法结构、每一个数据类型,是如何被编译器处理和转化的。你将看到变量如何分配内存,函数调用如何压栈弹栈,循环和条件语句如何转换为跳转指令。这是一种前所未有的透彻理解,让你对C语言的认知从“会用”跃升到“看透”!
-
吃透计算机底层原理: 编译器是连接高级语言和机器语言的桥梁。手撸编译器,意味着你将直面计算机体系结构、指令集、内存管理等核心概念。你会发现,那些抽象的计算机原理,在编译器的实现中变得如此具体和生动。
-
提升解决复杂问题的能力: 编译器是一个庞大而复杂的系统工程。从词法分析到语法分析,从语义检查到代码生成,每一步都充满了挑战。这个过程将极大地锻炼你的系统设计能力、抽象思维能力和调试排错能力。当你完成这个项目,你会发现,其他任何复杂的编程任务都将变得小菜一碟。
-
享受创造的极致快感: 想象一下,你写下一段C代码,然后用自己亲手打造的编译器将其编译成可执行文件,并成功运行!那种从无到有,将思想变为现实的成就感,是任何其他编程体验都无法比拟的!这不仅仅是写代码,这是在创造一个“生命”!
所以,朋友们,这不是一次简单的学习,这是一场冒险,一次蜕变!准备好你的键盘,点燃你的激情,让我们一起“肝爆”这4万行代码,彻底看透C语言的红尘!
编译器的宏伟蓝图:我们正在建造什么?
在深入细节之前,我们先来鸟瞰一下编译器的全貌。一个典型的编译器通常包含以下几个核心阶段:
-
词法分析(Lexical Analysis / Scanning): 这是编译器的第一步,它像一个“阅读器”,将源代码字符流分解成一个个有意义的“词素”(lexeme),并将其归类为“令牌”(token)。例如,
int是一个关键字令牌,main是一个标识符令牌,=是一个赋值操作符令牌。 -
语法分析(Syntax Analysis / Parsing): 这一阶段像一个“语法学家”,它接收词法分析器生成的令牌流,并根据语言的语法规则(比如C语言的语法)来检查令牌序列是否合法。如果合法,它会构建一个抽象语法树(Abstract Syntax Tree, AST),这棵树是源代码结构的一种抽象表示。
-
语义分析(Semantic Analysis): 语义分析器像一个“逻辑检查员”,它在AST的基础上进行更深层次的检查,比如类型检查(你不能把一个字符串赋值给一个整型变量)、变量作用域检查(你不能使用一个未声明的变量)等。它还会收集类型信息,并可能对AST进行一些转换。
-
中间代码生成(Intermediate Code Generation): 编译器不会直接从AST生成机器码。通常,它会先将AST转换成一种与特定机器无关的中间表示(Intermediate Representation, IR),比如三地址码(Three-Address Code)。这种IR更接近机器指令,但仍然是抽象的,便于后续的优化和跨平台。
-
代码优化(Code Optimization): 这一阶段像一个“性能调优师”,它对中间代码进行各种转换,以提高生成的目标代码的执行效率,比如消除冗余计算、常量折叠、循环优化等。
-
目标代码生成(Target Code Generation): 这是编译器的最后一步,它将优化后的中间代码翻译成特定目标机器(如x86、ARM)的机器指令或汇编代码。
-
链接与加载(Linking & Loading): 虽然严格来说不属于编译器本身,但链接器和加载器是编译过程不可或缺的一部分。链接器将编译好的多个目标文件和库文件组合成一个最终的可执行文件。加载器则负责将可执行文件加载到内存中并启动程序的执行。
我们的目标: 在这个系列中,我们将主要聚焦于前六个阶段,从C语言源代码出发,最终生成一个简单的自定义虚拟机(VM)的字节码。选择VM字节码而不是直接生成汇编,是为了简化目标代码生成阶段的复杂性,让我们能更专注于编译器的核心原理。
编译器干了啥?
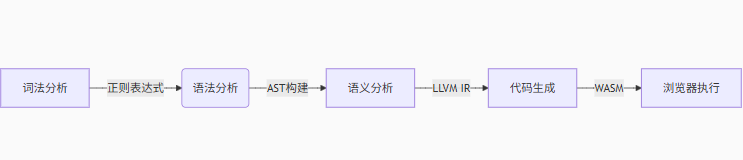
一张图总结!
第一章:词法分析的基石——扫描器(Lexer)
好了,理论铺垫到此为止,是时候撸起袖子干活了!我们的第一站是词法分析器,也就是我们常说的扫描器(Scanner)。
词法分析器是做什么的?
想象一下,你正在阅读一本厚厚的C语言书。你不会一个字符一个字符地去理解它,你会识别出“int”是一个类型,“main”是一个函数名,“=”是一个赋值符号。词法分析器做的就是类似的事情。
它接收C语言的源代码文件,这个文件本质上就是一个巨大的字符流。词法分析器的任务就是:
-
识别词素(Lexeme): 从字符流中识别出构成语言的最小有意义单元。例如,
int,main,(,),{,},return,0,;,+,*,myVariable等。 -
生成令牌(Token): 为每个识别出的词素创建一个“令牌”。令牌是一个结构化的数据,它至少包含两部分信息:
-
令牌类型(Token Type): 表示这个词素的类别,例如
KEYWORD_INT(整数关键字),IDENTIFIER(标识符),OPERATOR_ASSIGN(赋值运算符),NUMBER_INTEGER(整数常量) 等。 -
词素值(Lexeme Value / Attribute): 原始的字符序列,例如对于
IDENTIFIER类型的令牌,它的值就是myVariable;对于NUMBER_INTEGER,它的值就是123。
-
-
过滤无用字符: 忽略源代码中的空格、制表符、换行符以及注释。这些字符对于语法和语义没有直接意义。
-
错误报告: 当遇到无法识别的字符序列时,报告词法错误。
简单来说,词法分析器就是把一堆“散沙”(字符)组织成一个个“砖块”(令牌),为后续的语法分析打下基础。
令牌的结构与定义
在C语言中,我们可以用enum来定义令牌的类型,用struct来定义令牌的结构。
// token.h
#ifndef TOKEN_H
#define TOKEN_H
// 定义所有可能的令牌类型
typedef enum {
// 特殊令牌
TOKEN_EOF = 0, // 文件结束符 (End Of File)
TOKEN_UNKNOWN, // 未知令牌,用于错误处理
// 关键字
TOKEN_KEYWORD_INT, // int
TOKEN_KEYWORD_RETURN, // return
TOKEN_KEYWORD_IF, // if
TOKEN_KEYWORD_ELSE, // else
TOKEN_KEYWORD_WHILE, // while
TOKEN_KEYWORD_FOR, // for
TOKEN_KEYWORD_VOID, // void
TOKEN_KEYWORD_CHAR, // char
TOKEN_KEYWORD_SHORT, // short
TOKEN_KEYWORD_LONG, // long
TOKEN_KEYWORD_FLOAT, // float
TOKEN_KEYWORD_DOUBLE, // double
TOKEN_KEYWORD_STRUCT, // struct
TOKEN_KEYWORD_UNION, // union
TOKEN_KEYWORD_ENUM, // enum
TOKEN_KEYWORD_TYPEDEF, // typedef
TOKEN_KEYWORD_SIZEOF, // sizeof
TOKEN_KEYWORD_BREAK, // break
TOKEN_KEYWORD_CONTINUE, // continue
TOKEN_KEYWORD_SWITCH, // switch
TOKEN_KEYWORD_CASE, // case
TOKEN_KEYWORD_DEFAULT, // default
TOKEN_KEYWORD_DO, // do
TOKEN_KEYWORD_GOTO, // goto
TOKEN_KEYWORD_CONST, // const
TOKEN_KEYWORD_VOLATILE, // volatile
TOKEN_KEYWORD_EXTERN, // extern
TOKEN_KEYWORD_STATIC, // static
TOKEN_KEYWORD_REGISTER, // register
TOKEN_KEYWORD_AUTO, // auto
TOKEN_KEYWORD_SIGNED, // signed
TOKEN_KEYWORD_UNSIGNED, // unsigned
// 标识符
TOKEN_IDENTIFIER, // 变量名、函数名等
// 字面量 (常量)
TOKEN_INTEGER_LITERAL, // 整数常量,如 123, 0xAF
TOKEN_FLOAT_LITERAL, // 浮点数常量,如 3.14, 1.0e-5
TOKEN_STRING_LITERAL, // 字符串常量,如 "hello world"
TOKEN_CHAR_LITERAL, // 字符常量,如 'a', '\n'
// 运算符
TOKEN_OP_ASSIGN, // =
TOKEN_OP_PLUS, // +
TOKEN_OP_MINUS, // -
TOKEN_OP_MULTIPLY, // *
TOKEN_OP_DIVIDE, // /
TOKEN_OP_MODULO, // %
TOKEN_OP_EQ, // ==
TOKEN_OP_NE, // !=
TOKEN_OP_LT, // <
TOKEN_OP_LE, // <=
TOKEN_OP_GT, // >
TOKEN_OP_GE, // >=
TOKEN_OP_AND, // &&
TOKEN_OP_OR, // ||
TOKEN_OP_NOT, // !
TOKEN_OP_BIT_AND, // &
TOKEN_OP_BIT_OR, // |
TOKEN_OP_BIT_XOR, // ^
TOKEN_OP_BIT_NOT, // ~
TOKEN_OP_LSHIFT, // <<
TOKEN_OP_RSHIFT, // >>
TOKEN_OP_INC, // ++
TOKEN_OP_DEC, // --
TOKEN_OP_ARROW, // ->
TOKEN_OP_DOT, // .
TOKEN_OP_COMMA, // ,
TOKEN_OP_COLON, // :
TOKEN_OP_QUESTION, // ?
TOKEN_OP_ASSIGN_PLUS, // +=
TOKEN_OP_ASSIGN_MINUS, // -=
TOKEN_OP_ASSIGN_MULTIPLY, // *=
TOKEN_OP_ASSIGN_DIVIDE, // /=
TOKEN_OP_ASSIGN_MODULO, // %=
TOKEN_OP_ASSIGN_LSHIFT, // <<=
TOKEN_OP_ASSIGN_RSHIFT, // >>=
TOKEN_OP_ASSIGN_BIT_AND, // &=
TOKEN_OP_ASSIGN_BIT_OR, // |=
TOKEN_OP_ASSIGN_BIT_XOR, // ^=
// 分隔符/标点符号
TOKEN_LPAREN, // (
TOKEN_RPAREN, // )
TOKEN_LBRACE, // {
TOKEN_RBRACE, // }
TOKEN_LBRACKET, // [
TOKEN_RBRACKET, // ]
TOKEN_SEMICOLON, // ;
TOKEN_POUND, // # (用于预处理器指令)
TOKEN_ELLIPSIS, // ... (用于可变参数)
} TokenType;
// 令牌结构体
typedef struct {
TokenType type; // 令牌类型
char* lexeme; // 词素的字符串表示 (原始文本)
int line; // 令牌所在的行号
int column; // 令牌所在的列号
// 字面量的值 (根据类型存储不同数据)
union {
long long int_val; // 整数值
double float_val; // 浮点数值
char char_val; // 字符值
// 字符串字面量的值直接存储在lexeme中,因为它可能很长
} value;
} Token;
// 辅助函数:获取令牌类型的字符串表示,方便调试
const char* token_type_to_string(TokenType type);
#endif // TOKEN_H
token.c (辅助函数实现):
// token.c
#include "token.h"
#include <stdio.h> // 用于printf
// 辅助函数:将TokenType枚举值转换为可读的字符串
// 这对于调试和错误报告非常有用
const char* token_type_to_string(TokenType type) {
switch (type) {
case TOKEN_EOF: return "EOF";
case TOKEN_UNKNOWN: return "UNKNOWN";
// 关键字
case TOKEN_KEYWORD_INT: return "KEYWORD_INT";
case TOKEN_KEYWORD_RETURN: return "KEYWORD_RETURN";
case TOKEN_KEYWORD_IF: return "KEYWORD_IF";
case TOKEN_KEYWORD_ELSE: return "KEYWORD_ELSE";
case TOKEN_KEYWORD_WHILE: return "KEYWORD_WHILE";
case TOKEN_KEYWORD_FOR: return "KEYWORD_FOR";
case TOKEN_KEYWORD_VOID: return "KEYWORD_VOID";
case TOKEN_KEYWORD_CHAR: return "KEYWORD_CHAR";
case TOKEN_KEYWORD_SHORT: return "KEYWORD_SHORT";
case TOKEN_KEYWORD_LONG: return "KEYWORD_LONG";
case TOKEN_KEYWORD_FLOAT: return "KEYWORD_FLOAT";
case TOKEN_KEYWORD_DOUBLE: return "KEYWORD_DOUBLE";
case TOKEN_KEYWORD_STRUCT: return "KEYWORD_STRUCT";
case TOKEN_KEYWORD_UNION: return "KEYWORD_UNION";
case TOKEN_KEYWORD_ENUM: return "KEYWORD_ENUM";
case TOKEN_KEYWORD_TYPEDEF: return "KEYWORD_TYPEDEF";
case TOKEN_KEYWORD_SIZEOF: return "KEYWORD_SIZEOF";
case TOKEN_KEYWORD_BREAK: return "KEYWORD_BREAK";
case TOKEN_KEYWORD_CONTINUE: return "KEYWORD_CONTINUE";
case TOKEN_KEYWORD_SWITCH: return "KEYWORD_SWITCH";
case TOKEN_KEYWORD_CASE: return "KEYWORD_CASE";
case TOKEN_KEYWORD_DEFAULT: return "KEYWORD_DEFAULT";
case TOKEN_KEYWORD_DO: return "KEYWORD_DO";
case TOKEN_KEYWORD_GOTO: return "KEYWORD_GOTO";
case TOKEN_KEYWORD_CONST: return "KEYWORD_CONST";
case TOKEN_KEYWORD_VOLATILE: return "KEYWORD_VOLATILE";
case TOKEN_KEYWORD_EXTERN: return "KEYWORD_EXTERN";
case TOKEN_KEYWORD_STATIC: return "KEYWORD_STATIC";
case TOKEN_KEYWORD_REGISTER: return "KEYWORD_REGISTER";
case TOKEN_KEYWORD_AUTO: return "KEYWORD_AUTO";
case TOKEN_KEYWORD_SIGNED: return "KEYWORD_SIGNED";
case TOKEN_KEYWORD_UNSIGNED: return "KEYWORD_UNSIGNED";
// 标识符
case TOKEN_IDENTIFIER: return "IDENTIFIER";
// 字面量
case TOKEN_INTEGER_LITERAL: return "INTEGER_LITERAL";
case TOKEN_FLOAT_LITERAL: return "FLOAT_LITERAL";
case TOKEN_STRING_LITERAL: return "STRING_LITERAL";
case TOKEN_CHAR_LITERAL: return "CHAR_LITERAL";
// 运算符
case TOKEN_OP_ASSIGN: return "OP_ASSIGN";
case TOKEN_OP_PLUS: return "OP_PLUS";
case TOKEN_OP_MINUS: return "OP_MINUS";
case TOKEN_OP_MULTIPLY: return "OP_MULTIPLY";
case TOKEN_OP_DIVIDE: return "OP_DIVIDE";
case TOKEN_OP_MODULO: return "OP_MODULO";
case TOKEN_OP_EQ: return "OP_EQ";
case TOKEN_OP_NE: return "OP_NE";
case TOKEN_OP_LT: return "OP_LT";
case TOKEN_OP_LE: return "OP_LE";
case TOKEN_OP_GT: return "OP_GT";
case TOKEN_OP_GE: return "OP_GE";
case TOKEN_OP_AND: return "OP_AND";
case TOKEN_OP_OR: return "OP_OR";
case TOKEN_OP_NOT: return "OP_NOT";
case TOKEN_OP_BIT_AND: return "OP_BIT_AND";
case TOKEN_OP_BIT_OR: return "OP_BIT_OR";
case TOKEN_OP_BIT_XOR: return "OP_BIT_XOR";
case TOKEN_OP_BIT_NOT: return "OP_BIT_NOT";
case TOKEN_OP_LSHIFT: return "OP_LSHIFT";
case TOKEN_OP_RSHIFT: return "OP_RSHIFT";
case TOKEN_OP_INC: return "OP_INC";
case TOKEN_OP_DEC: return "OP_DEC";
case TOKEN_OP_ARROW: return "OP_ARROW";
case TOKEN_OP_DOT: return "OP_DOT";
case TOKEN_OP_COMMA: return "OP_COMMA";
case TOKEN_OP_COLON: return "OP_COLON";
case TOKEN_OP_QUESTION: return "OP_QUESTION";
case TOKEN_OP_ASSIGN_PLUS: return "OP_ASSIGN_PLUS";
case TOKEN_OP_ASSIGN_MINUS: return "OP_ASSIGN_MINUS";
case TOKEN_OP_ASSIGN_MULTIPLY: return "OP_ASSIGN_MULTIPLY";
case TOKEN_OP_ASSIGN_DIVIDE: return "OP_ASSIGN_DIVIDE";
case TOKEN_OP_ASSIGN_MODULO: return "OP_ASSIGN_MODULO";
case TOKEN_OP_ASSIGN_LSHIFT: return "OP_ASSIGN_LSHIFT";
case TOKEN_OP_ASSIGN_RSHIFT: return "OP_ASSIGN_RSHIFT";
case TOKEN_OP_ASSIGN_BIT_AND: return "OP_ASSIGN_BIT_AND";
case TOKEN_OP_ASSIGN_BIT_OR: return "OP_ASSIGN_BIT_OR";
case TOKEN_OP_ASSIGN_BIT_XOR: return "OP_ASSIGN_BIT_XOR";
// 分隔符/标点符号
case TOKEN_LPAREN: return "LPAREN";
case TOKEN_RPAREN: return "RPAREN";
case TOKEN_LBRACE: return "LBRACE";
case TOKEN_RBRACE: return "RBRACE";
case TOKEN_LBRACKET: return "LBRACKET";
case TOKEN_RBRACKET: return "RBRACKET";
case TOKEN_SEMICOLON: return "SEMICOLON";
case TOKEN_POUND: return "POUND";
case TOKEN_ELLIPSIS: return "ELLIPSIS";
default: return "UNKNOWN_TYPE";
}
}
词法分析器(Lexer)的核心实现
词法分析器需要维护当前扫描到的位置,并提供前进、回溯、查看下一个字符等功能。
// lexer.h
#ifndef LEXER_H
#define LEXER_H
#include "token.h" // 包含令牌定义
#include <stdio.h> // 用于文件操作
// 定义词法分析器结构体
typedef struct {
FILE* source_file; // 输入的源代码文件指针
char* source_code; // 存储整个源代码的缓冲区
size_t source_size; // 源代码文件大小
int current_pos; // 当前正在处理的字符在source_code中的位置
int line; // 当前字符所在的行号
int column; // 当前字符所在的列号
// 关键字映射表 (用于快速查找标识符是否是关键字)
// 这是一个简单的哈希表或排序数组,这里我们先用一个简单的数组模拟
// 实际编译器会用更高效的结构
struct {
const char* lexeme;
TokenType type;
} keywords[40]; // 预留足够的空间给关键字
int num_keywords; // 实际关键字数量
} Lexer;
// 函数声明
Lexer* init_lexer(const char* filepath); // 初始化词法分析器
void free_lexer(Lexer* lexer); // 释放词法分析器资源
Token get_next_token(Lexer* lexer); // 获取下一个令牌
void lexer_error(Lexer* lexer, const char* message); // 报告词法错误
#endif // LEXER_H
现在,是时候揭开lexer.c的神秘面纱了!这将是词法分析的核心逻辑,我们将在这里实现如何识别各种C语言元素。
// lexer.c
#include "lexer.h"
#include <stdlib.h> // 用于 malloc, free
#include <string.h> // 用于 strdup, strcmp, strncmp
#include <ctype.h> // 用于 isalnum, isalpha, isdigit, isspace
// --- 辅助宏和函数 ---
// 报告词法错误并退出
void lexer_error(Lexer* lexer, const char* message) {
fprintf(stderr, "词法错误 (%d:%d): %s\n", lexer->line, lexer->column, message);
if (lexer->source_code) {
// 尝试打印错误行上下文
int start_col = 0;
int end_col = lexer->current_pos;
while (start_col < lexer->current_pos && lexer->source_code[start_col] != '\n') {
start_col++;
}
if (start_col < lexer->current_pos) start_col++; // 跳过换行符
while (end_col < lexer->source_size && lexer->source_code[end_col] != '\n') {
end_col++;
}
fprintf(stderr, " %.*s\n", end_col - start_col, lexer->source_code + start_col);
for (int i = 0; i < lexer->column - 1; ++i) {
fprintf(stderr, " ");
}
fprintf(stderr, "^\n");
}
free_lexer(lexer); // 释放资源
exit(EXIT_FAILURE); // 终止程序
}
// 获取当前字符
static char current_char(Lexer* lexer) {
if (lexer->current_pos >= lexer->source_size) {
return '\0'; // 文件结束
}
return lexer->source_code[lexer->current_pos];
}
// 查看下一个字符 (不移动指针)
static char peek_char(Lexer* lexer, int offset) {
if (lexer->current_pos + offset >= lexer->source_size) {
return '\0'; // 文件结束
}
return lexer->source_code[lexer->current_pos + offset];
}
// 前进一个字符,并更新行号和列号
static void advance_char(Lexer* lexer) {
if (lexer->current_pos < lexer->source_size) {
if (lexer->source_code[lexer->current_pos] == '\n') {
lexer->line++;
lexer->column = 1; // 新行从第一列开始
} else {
lexer->column++;
}
lexer->current_pos++;
}
}
// 跳过空白字符 (空格、制表符、换行符等)
static void skip_whitespace(Lexer* lexer) {
while (lexer->current_pos < lexer->source_size && isspace(current_char(lexer))) {
advance_char(lexer);
}
}
// 创建一个新令牌
static Token create_token(Lexer* lexer, TokenType type, const char* start_ptr, int length) {
Token token;
token.type = type;
// 为词素字符串分配内存并复制
token.lexeme = (char*)malloc(length + 1);
if (!token.lexeme) {
lexer_error(lexer, "内存分配失败 (lexeme)");
}
strncpy(token.lexeme, start_ptr, length);
token.lexeme[length] = '\0'; // 确保字符串以null结尾
// 记录令牌的位置信息
// 注意:这里记录的是令牌的起始位置,而不是当前扫描到的位置
// 需要根据实际情况调整,通常是记录词素的起始行和列
// 为了简化,这里先用当前lexer的行和列,实际应在识别词素前记录
token.line = lexer->line;
token.column = lexer->column - length; // 减去词素长度得到起始列
// 初始化字面量值
token.value.int_val = 0;
token.value.float_val = 0.0;
token.value.char_val = '\0';
return token;
}
// 释放令牌内存 (特别是lexeme)
static void free_token_lexeme(Token* token) {
if (token && token->lexeme) {
free(token->lexeme);
token->lexeme = NULL;
}
}
// --- 关键字映射表初始化 ---
static void init_keywords(Lexer* lexer) {
// 这里使用一个简单的数组,实际编译器会使用哈希表来提高查找效率
lexer->num_keywords = 0;
#define ADD_KEYWORD(str, type) \
lexer->keywords[lexer->num_keywords].lexeme = str; \
lexer->keywords[lexer->num_keywords].type = type; \
lexer->num_keywords++;
ADD_KEYWORD("int", TOKEN_KEYWORD_INT);
ADD_KEYWORD("return", TOKEN_KEYWORD_RETURN);
ADD_KEYWORD("if", TOKEN_KEYWORD_IF);
ADD_KEYWORD("else", TOKEN_KEYWORD_ELSE);
ADD_KEYWORD("while", TOKEN_KEYWORD_WHILE);
ADD_KEYWORD("for", TOKEN_KEYWORD_FOR);
ADD_KEYWORD("void", TOKEN_KEYWORD_VOID);
ADD_KEYWORD("char", TOKEN_KEYWORD_CHAR);
ADD_KEYWORD("short", TOKEN_KEYWORD_SHORT);
ADD_KEYWORD("long", TOKEN_KEYWORD_LONG);
ADD_KEYWORD("float", TOKEN_KEYWORD_FLOAT);
ADD_KEYWORD("double", TOKEN_KEYWORD_DOUBLE);
ADD_KEYWORD("struct", TOKEN_KEYWORD_STRUCT);
ADD_KEYWORD("union", TOKEN_KEYWORD_UNION);
ADD_KEYWORD("enum", TOKEN_KEYWORD_ENUM);
ADD_KEYWORD("typedef", TOKEN_KEYWORD_TYPEDEF);
ADD_KEYWORD("sizeof", TOKEN_KEYWORD_SIZEOF);
ADD_KEYWORD("break", TOKEN_KEYWORD_BREAK);
ADD_KEYWORD("continue", TOKEN_KEYWORD_CONTINUE);
ADD_KEYWORD("switch", TOKEN_KEYWORD_SWITCH);
ADD_KEYWORD("case", TOKEN_KEYWORD_CASE);
ADD_KEYWORD("default", TOKEN_KEYWORD_DEFAULT);
ADD_KEYWORD("do", TOKEN_KEYWORD_DO);
ADD_KEYWORD("goto", TOKEN_KEYWORD_GOTO);
ADD_KEYWORD("const", TOKEN_KEYWORD_CONST);
ADD_KEYWORD("volatile", TOKEN_KEYWORD_VOLATILE);
ADD_KEYWORD("extern", TOKEN_KEYWORD_EXTERN);
ADD_KEYWORD("static", TOKEN_KEYWORD_STATIC);
ADD_KEYWORD("register", TOKEN_KEYWORD_REGISTER);
ADD_KEYWORD("auto", TOKEN_KEYWORD_AUTO);
ADD_KEYWORD("signed", TOKEN_KEYWORD_SIGNED);
ADD_KEYWORD("unsigned", TOKEN_KEYWORD_UNSIGNED);
#undef ADD_KEYWORD
}
// --- 词法分析器初始化与清理 ---
// 初始化词法分析器
Lexer* init_lexer(const char* filepath) {
Lexer* lexer = (Lexer*)malloc(sizeof(Lexer));
if (!lexer) {
fprintf(stderr, "错误: 内存分配失败 (Lexer)\n");
return NULL;
}
lexer->source_file = fopen(filepath, "rb"); // 以二进制读取模式打开文件
if (!lexer->source_file) {
fprintf(stderr, "错误: 无法打开文件 '%s'\n", filepath);
free(lexer);
return NULL;
}
// 获取文件大小
fseek(lexer->source_file, 0, SEEK_END);
lexer->source_size = ftell(lexer->source_file);
fseek(lexer->source_file, 0, SEEK_SET);
// 为源代码缓冲区分配内存
lexer->source_code = (char*)malloc(lexer->source_size + 1); // +1 用于null终止符
if (!lexer->source_code) {
fprintf(stderr, "错误: 内存分配失败 (source_code)\n");
fclose(lexer->source_file);
free(lexer);
return NULL;
}
// 读取整个文件内容到缓冲区
if (fread(lexer->source_code, 1, lexer->source_size, lexer->source_file) != lexer->source_size) {
fprintf(stderr, "错误: 读取文件失败 '%s'\n", filepath);
free(lexer->source_code);
fclose(lexer->source_file);
free(lexer);
return NULL;
}
lexer->source_code[lexer->source_size] = '\0'; // 确保缓冲区以null终止
// 关闭文件,因为我们已经将内容读入内存
fclose(lexer->source_file);
lexer->source_file = NULL; // 将文件指针置空,避免误用
lexer->current_pos = 0;
lexer->line = 1;
lexer->column = 1;
init_keywords(lexer); // 初始化关键字映射表
return lexer;
}
// 释放词法分析器资源
void free_lexer(Lexer* lexer) {
if (lexer) {
if (lexer->source_code) {
free(lexer->source_code);
lexer->source_code = NULL;
}
// source_file 已经在 init_lexer 中关闭,这里无需再次关闭
free(lexer);
}
}
// --- 核心词法分析逻辑 ---
// 识别标识符或关键字
static Token parse_identifier_or_keyword(Lexer* lexer) {
int start_pos = lexer->current_pos;
int start_col = lexer->column; // 记录词素起始列
// 标识符由字母、数字或下划线组成,但必须以字母或下划线开头
while (isalnum(current_char(lexer)) || current_char(lexer) == '_') {
advance_char(lexer);
}
int length = lexer->current_pos - start_pos;
const char* lexeme_start = lexer->source_code + start_pos;
// 检查是否是关键字
for (int i = 0; i < lexer->num_keywords; ++i) {
if (length == strlen(lexer->keywords[i].lexeme) &&
strncmp(lexeme_start, lexer->keywords[i].lexeme, length) == 0) {
Token token = create_token(lexer, lexer->keywords[i].type, lexeme_start, length);
token.column = start_col; // 修正列号
return token;
}
}
// 如果不是关键字,那就是标识符
Token token = create_token(lexer, TOKEN_IDENTIFIER, lexeme_start, length);
token.column = start_col; // 修正列号
return token;
}
// 识别数字字面量 (整数和浮点数)
static Token parse_number(Lexer* lexer) {
int start_pos = lexer->current_pos;
int start_col = lexer->column; // 记录词素起始列
TokenType type = TOKEN_INTEGER_LITERAL; // 默认是整数
// 处理整数部分
while (isdigit(current_char(lexer))) {
advance_char(lexer);
}
// 处理小数点和浮点数部分
if (current_char(lexer) == '.') {
// 确保小数点后有数字,避免将 `1.` 识别为浮点数
if (isdigit(peek_char(lexer, 1))) {
type = TOKEN_FLOAT_LITERAL;
advance_char(lexer); // 跳过小数点
while (isdigit(current_char(lexer))) {
advance_char(lexer);
}
}
}
// 处理指数部分 (e/E)
if (tolower(current_char(lexer)) == 'e') {
if (isdigit(peek_char(lexer, 1)) ||
((peek_char(lexer, 1) == '+' || peek_char(lexer, 1) == '-') && isdigit(peek_char(lexer, 2)))) {
type = TOKEN_FLOAT_LITERAL;
advance_char(lexer); // 跳过 'e' 或 'E'
if (current_char(lexer) == '+' || current_char(lexer) == '-') {
advance_char(lexer); // 跳过 '+' 或 '-'
}
while (isdigit(current_char(lexer))) {
advance_char(lexer);
}
}
}
int length = lexer->current_pos - start_pos;
const char* lexeme_start = lexer->source_code + start_pos;
Token token = create_token(lexer, type, lexeme_start, length);
token.column = start_col; // 修正列号
// 转换字面量值
if (type == TOKEN_INTEGER_LITERAL) {
token.value.int_val = strtoll(token.lexeme, NULL, 0); // 自动处理十进制、八进制、十六进制
} else { // TOKEN_FLOAT_LITERAL
token.value.float_val = strtod(token.lexeme, NULL);
}
return token;
}
// 识别字符串字面量
static Token parse_string(Lexer* lexer) {
int start_pos = lexer->current_pos;
int start_col = lexer->column; // 记录词素起始列
advance_char(lexer); // 跳过开头的双引号 '"'
while (current_char(lexer) != '"' && current_char(lexer) != '\0') {
// 处理转义字符
if (current_char(lexer) == '\\') {
advance_char(lexer); // 跳过 '\'
// 这里可以添加更复杂的转义字符处理,例如 \n, \t, \xNN 等
// 简化起见,我们只跳过下一个字符
if (current_char(lexer) == '\0') {
lexer_error(lexer, "字符串字面量中非法的转义序列或文件意外结束");
}
}
advance_char(lexer);
}
if (current_char(lexer) == '\0') {
lexer_error(lexer, "未终止的字符串字面量");
}
advance_char(lexer); // 跳过末尾的双引号 '"'
int length = lexer->current_pos - start_pos;
const char* lexeme_start = lexer->source_code + start_pos;
Token token = create_token(lexer, TOKEN_STRING_LITERAL, lexeme_start, length);
token.column = start_col; // 修正列号
return token;
}
// 识别字符字面量
static Token parse_char_literal(Lexer* lexer) {
int start_pos = lexer->current_pos;
int start_col = lexer->column; // 记录词素起始列
advance_char(lexer); // 跳过开头的单引号 '''
char char_val;
if (current_char(lexer) == '\\') { // 处理转义字符
advance_char(lexer); // 跳过 '\'
switch (current_char(lexer)) {
case 'n': char_val = '\n'; break;
case 't': char_val = '\t'; break;
case 'r': char_val = '\r'; break;
case 'b': char_val = '\b'; break;
case 'f': char_val = '\f'; break;
case 'a': char_val = '\a'; break;
case 'v': char_val = '\v'; break;
case '\\': char_val = '\\'; break;
case '\'': char_val = '\''; break;
case '"': char_val = '"'; break;
case '?': char_val = '?'; break;
// TODO: 处理八进制和十六进制转义字符
default:
lexer_error(lexer, "字符字面量中非法的转义序列");
char_val = '\0'; // 默认值
break;
}
} else if (current_char(lexer) == '\0') {
lexer_error(lexer, "未终止的字符字面量或文件意外结束");
char_val = '\0'; // 默认值
} else {
char_val = current_char(lexer);
}
advance_char(lexer); // 跳过字符本身
if (current_char(lexer) != '\'') {
lexer_error(lexer, "未终止的字符字面量");
}
advance_char(lexer); // 跳过末尾的单引号 '''
int length = lexer->current_pos - start_pos;
const char* lexeme_start = lexer->source_code + start_pos;
Token token = create_token(lexer, TOKEN_CHAR_LITERAL, lexeme_start, length);
token.column = start_col; // 修正列号
token.value.char_val = char_val;
return token;
}
// 跳过单行注释 //
static void skip_single_line_comment(Lexer* lexer) {
while (current_char(lexer) != '\n' && current_char(lexer) != '\0') {
advance_char(lexer);
}
// 不跳过换行符,让 advance_char 在下次调用时处理
}
// 跳过多行注释 /* ... */
static void skip_multi_line_comment(Lexer* lexer) {
advance_char(lexer); // 跳过 '*'
while (!(current_char(lexer) == '*' && peek_char(lexer, 1) == '/') && current_char(lexer) != '\0') {
advance_char(lexer);
}
if (current_char(lexer) == '\0') {
lexer_error(lexer, "未终止的多行注释");
}
advance_char(lexer); // 跳过 '*'
advance_char(lexer); // 跳过 '/'
}
// 获取下一个令牌的核心函数
Token get_next_token(Lexer* lexer) {
// 1. 跳过所有空白字符和注释
while (1) {
skip_whitespace(lexer);
// 处理注释
if (current_char(lexer) == '/') {
if (peek_char(lexer, 1) == '/') { // 单行注释 //
advance_char(lexer); // 跳过第一个 '/'
advance_char(lexer); // 跳过第二个 '/'
skip_single_line_comment(lexer);
continue; // 继续循环,跳过更多空白或注释
} else if (peek_char(lexer, 1) == '*') { // 多行注释 /* ... */
advance_char(lexer); // 跳过第一个 '/'
advance_char(lexer); // 跳过 '*'
skip_multi_line_comment(lexer);
continue; // 继续循环
}
}
break; // 没有空白或注释了,退出循环
}
// 2. 检查文件是否结束
if (lexer->current_pos >= lexer->source_size) {
return create_token(lexer, TOKEN_EOF, "", 0); // 返回EOF令牌
}
// 3. 记录当前词素的起始位置信息
int token_start_pos = lexer->current_pos;
int token_start_line = lexer->line;
int token_start_column = lexer->column;
char c = current_char(lexer);
// 4. 根据当前字符识别令牌类型
// 优先级:长匹配优先(例如,先检查 `==` 再检查 `=`)
// 标识符和关键字
if (isalpha(c) || c == '_') {
return parse_identifier_or_keyword(lexer);
}
// 数字字面量
if (isdigit(c)) {
return parse_number(lexer);
}
// 字符串字面量
if (c == '"') {
return parse_string(lexer);
}
// 字符字面量
if (c == '\'') {
return parse_char_literal(lexer);
}
// 运算符和分隔符
advance_char(lexer); // 默认先前进一个字符,对于单字符令牌是正确的
// 对于多字符令牌,会在后续逻辑中进一步处理
switch (c) {
case '(': return create_token(lexer, TOKEN_LPAREN, lexer->source_code + token_start_pos, 1);
case ')': return create_token(lexer, TOKEN_RPAREN, lexer->source_code + token_start_pos, 1);
case '{': return create_token(lexer, TOKEN_LBRACE, lexer->source_code + token_start_pos, 1);
case '}': return create_token(lexer, TOKEN_RBRACE, lexer->source_code + token_start_pos, 1);
case '[': return create_token(lexer, TOKEN_LBRACKET, lexer->source_code + token_start_pos, 1);
case ']': return create_token(lexer, TOKEN_RBRACKET, lexer->source_code + token_start_pos, 1);
case ';': return create_token(lexer, TOKEN_SEMICOLON, lexer->source_code + token_start_pos, 1);
case ',': return create_token(lexer, TOKEN_OP_COMMA, lexer->source_code + token_start_pos, 1);
case ':': return create_token(lexer, TOKEN_OP_COLON, lexer->source_code + token_start_pos, 1);
case '?': return create_token(lexer, TOKEN_OP_QUESTION, lexer->source_code + token_start_pos, 1);
case '#': return create_token(lexer, TOKEN_POUND, lexer->source_code + token_start_pos, 1);
case '~': return create_token(lexer, TOKEN_OP_BIT_NOT, lexer->source_code + token_start_pos, 1);
case '+':
if (current_char(lexer) == '+') { advance_char(lexer); return create_token(lexer, TOKEN_OP_INC, lexer->source_code + token_start_pos, 2); }
if (current_char(lexer) == '=') { advance_char(lexer); return create_token(lexer, TOKEN_OP_ASSIGN_PLUS, lexer->source_code + token_start_pos, 2); }
return create_token(lexer, TOKEN_OP_PLUS, lexer->source_code + token_start_pos, 1);
case '-':
if (current_char(lexer) == '-') { advance_char(lexer); return create_token(lexer, TOKEN_OP_DEC, lexer->source_code + token_start_pos, 2); }
if (current_char(lexer) == '>') { advance_char(lexer); return create_token(lexer, TOKEN_OP_ARROW, lexer->source_code + token_start_pos, 2); }
if (current_char(lexer) == '=') { advance_char(lexer); return create_token(lexer, TOKEN_OP_ASSIGN_MINUS, lexer->source_code + token_start_pos, 2); }
return create_token(lexer, TOKEN_OP_MINUS, lexer->source_code + token_start_pos, 1);
case '*':
if (current_char(lexer) == '=') { advance_char(lexer); return create_token(lexer, TOKEN_OP_ASSIGN_MULTIPLY, lexer->source_code + token_start_pos, 2); }
return create_token(lexer, TOKEN_OP_MULTIPLY, lexer->source_code + token_start_pos, 1);
// '/' 的情况已在注释处理中处理,这里只处理作为除号和复合赋值
case '/':
if (current_char(lexer) == '=') { advance_char(lexer); return create_token(lexer, TOKEN_OP_ASSIGN_DIVIDE, lexer->source_code + token_start_pos, 2); }
return create_token(lexer, TOKEN_OP_DIVIDE, lexer->source_code + token_start_pos, 1);
case '%':
if (current_char(lexer) == '=') { advance_char(lexer); return create_token(lexer, TOKEN_OP_ASSIGN_MODULO, lexer->source_code + token_start_pos, 2); }
return create_token(lexer, TOKEN_OP_MODULO, lexer->source_code + token_start_pos, 1);
case '=':
if (current_char(lexer) == '=') { advance_char(lexer); return create_token(lexer, TOKEN_OP_EQ, lexer->source_code + token_start_pos, 2); }
return create_token(lexer, TOKEN_OP_ASSIGN, lexer->source_code + token_start_pos, 1);
case '!':
if (current_char(lexer) == '=') { advance_char(lexer); return create_token(lexer, TOKEN_OP_NE, lexer->source_code + token_start_pos, 2); }
return create_token(lexer, TOKEN_OP_NOT, lexer->source_code + token_start_pos, 1);
case '<':
if (current_char(lexer) == '=') { advance_char(lexer); return create_token(lexer, TOKEN_OP_LE, lexer->source_code + token_start_pos, 2); }
if (current_char(lexer) == '<') {
advance_char(lexer);
if (current_char(lexer) == '=') { advance_char(lexer); return create_token(lexer, TOKEN_OP_ASSIGN_LSHIFT, lexer->source_code + token_start_pos, 3); }
return create_token(lexer, TOKEN_OP_LSHIFT, lexer->source_code + token_start_pos, 2);
}
return create_token(lexer, TOKEN_OP_LT, lexer->source_code + token_start_pos, 1);
case '>':
if (current_char(lexer) == '=') { advance_char(lexer); return create_token(lexer, TOKEN_OP_GE, lexer->source_code + token_start_pos, 2); }
if (current_char(lexer) == '>') {
advance_char(lexer);
if (current_char(lexer) == '=') { advance_char(lexer); return create_token(lexer, TOKEN_OP_ASSIGN_RSHIFT, lexer->source_code + token_start_pos, 3); }
return create_token(lexer, TOKEN_OP_RSHIFT, lexer->source_code + token_start_pos, 2);
}
return create_token(lexer, TOKEN_OP_GT, lexer->source_code + token_start_pos, 1);
case '&':
if (current_char(lexer) == '&') { advance_char(lexer); return create_token(lexer, TOKEN_OP_AND, lexer->source_code + token_start_pos, 2); }
if (current_char(lexer) == '=') { advance_char(lexer); return create_token(lexer, TOKEN_OP_ASSIGN_BIT_AND, lexer->source_code + token_start_pos, 2); }
return create_token(lexer, TOKEN_OP_BIT_AND, lexer->source_code + token_start_pos, 1);
case '|':
if (current_char(lexer) == '|') { advance_char(lexer); return create_token(lexer, TOKEN_OP_OR, lexer->source_code + token_start_pos, 2); }
if (current_char(lexer) == '=') { advance_char(lexer); return create_token(lexer, TOKEN_OP_ASSIGN_BIT_OR, lexer->source_code + token_start_pos, 2); }
return create_token(lexer, TOKEN_OP_BIT_OR, lexer->source_code + token_start_pos, 1);
case '^':
if (current_char(lexer) == '=') { advance_char(lexer); return create_token(lexer, TOKEN_OP_ASSIGN_BIT_XOR, lexer->source_code + token_start_pos, 2); }
return create_token(lexer, TOKEN_OP_BIT_XOR, lexer->source_code + token_start_pos, 1);
case '.':
// 处理 ... (ellipsis)
if (peek_char(lexer, 0) == '.' && peek_char(lexer, 1) == '.') {
advance_char(lexer); // 跳过第二个 '.'
advance_char(lexer); // 跳过第三个 '.'
return create_token(lexer, TOKEN_ELLIPSIS, lexer->source_code + token_start_pos, 3);
}
return create_token(lexer, TOKEN_OP_DOT, lexer->source_code + token_start_pos, 1);
default:
// 如果遇到无法识别的字符,报告错误
lexer_error(lexer, "无法识别的字符");
// 返回一个未知令牌,但程序通常会在此处退出
return create_token(lexer, TOKEN_UNKNOWN, lexer->source_code + token_start_pos, 1);
}
}
测试驱动:让我们的词法分析器动起来!
光说不练假把式!我们需要一个main.c文件来测试我们的词法分析器。
// main.c
#include "lexer.h"
#include "token.h"
#include <stdio.h>
#include <stdlib.h>
// 这是一个简单的测试文件,用于验证词法分析器功能
const char* TEST_CODE =
"// 这是一个单行注释\n"
"/* 这是一个\n"
" * 多行注释\n"
" */\n"
"int main() {\n"
" int x = 10;\n"
" float y = 3.14e-2;\n"
" char c = 'A';\n"
" char newline_char = '\\n';\n"
" char tab_char = '\\t';\n"
" char backslash_char = '\\\\';\n"
" char single_quote_char = '\\'';\n"
" char double_quote_char = '\"';\n"
" char question_mark_char = '?';\n"
" char null_char = '\\0';\n" // C99
" char alert_char = '\\a';\n"
" char backspace_char = '\\b';\n"
" char formfeed_char = '\\f';\n"
" char vertical_tab_char = '\\v';\n"
" const char* str = \"Hello, \\\"World!\\n\";\n"
" if (x >= 5 && y < 10.0) {\n"
" return x + y * 2;\n"
" }\n"
" x++;\n"
" y--;\n"
" x += 5;\n"
" y /= 2.0;\n"
" int a = 10, b = 20;\n"
" if (a == b) { /* do something */ }\n"
" else if (a != b && (a > b || a < b)) { /* another branch */ }\n"
" else { /* final branch */ }\n"
" for (int i = 0; i < 10; i++) {\n"
" printf(\"Loop %d\\n\", i);\n"
" }\n"
" while (x > 0) { x--; }\n"
" do { y++; } while (y < 100.0);\n"
" int bit_ops = (5 & 3) | (1 << 2) ^ (~0);\n"
" int assign_ops = 10;\n"
" assign_ops >>= 1;\n"
" assign_ops &= 0xF;\n"
" assign_ops |= 0x10;\n"
" assign_ops ^= 0x20;\n"
" struct MyStruct { int member; };\n"
" struct MyStruct s;\n"
" s.member = 1;\n"
" int* ptr = &x;\n"
" ptr->member = 2; // 这是一个语法错误,但词法分析器会识别 -> 运算符\n"
" void func(int, ...);\n" // 测试省略号
" #define MACRO 1\n" // 测试 #
" sizeof(int);\n" // 测试 sizeof
" goto end_label;\n" // 测试 goto
"end_label: ;\n"
" return 0;\n"
"}\n"
;
int main(int argc, char* argv[]) {
// 将测试代码写入一个临时文件,以便lexer可以读取
const char* temp_filepath = "test_code.c";
FILE* temp_file = fopen(temp_filepath, "w");
if (!temp_file) {
fprintf(stderr, "错误: 无法创建临时文件 '%s'\n", temp_filepath);
return EXIT_FAILURE;
}
fprintf(temp_file, "%s", TEST_CODE);
fclose(temp_file);
Lexer* lexer = init_lexer(temp_filepath);
if (!lexer) {
return EXIT_FAILURE;
}
printf("--- 词法分析开始 ---\n"); 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









