




引子 :动态规划硬核之路所有个人源码分享+解题过程共享(0)
最近搞完了dp动态规划问题+贪心算法问题,这里是所有题型的全览:
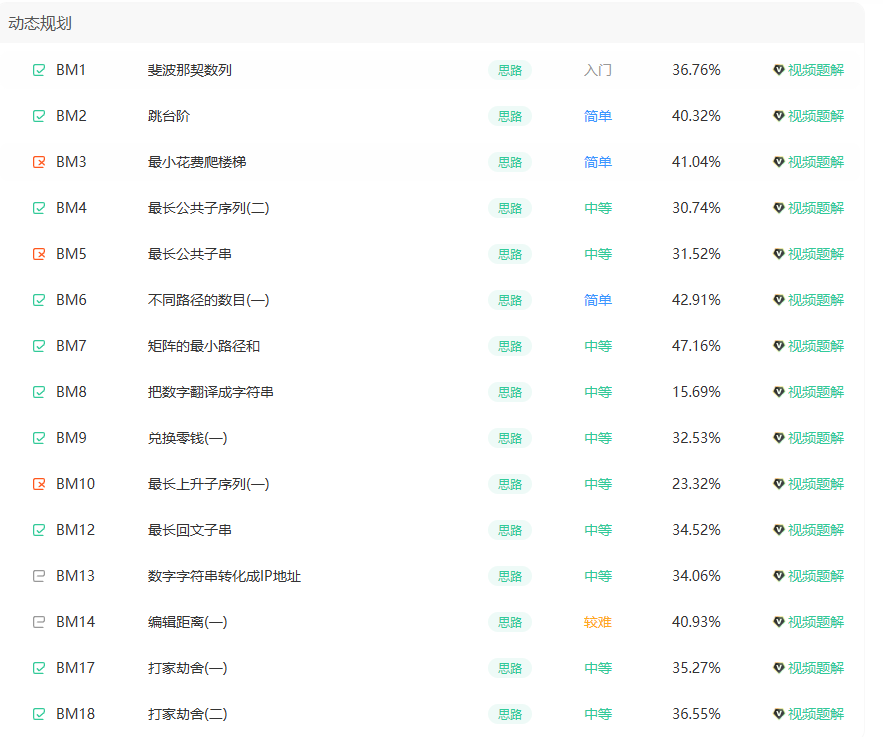
以下是值得思考、值得反复练习的经典动态规划算法问题!!!
一共10道题
1 最长公共子序列:
2 最长公共子串:

#3刷 2025/7/15
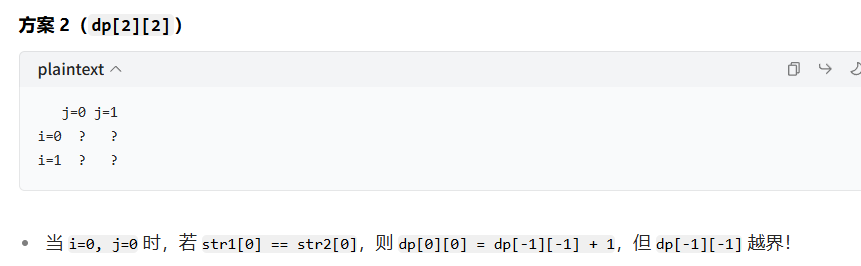
这里变成了:dp[i][j] = dp[i-1][j-1]+1就是回越界
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
* longest common substring
* @param str1 string字符串 the string
* @param str2 string字符串 the string
* @return string字符串
*/
#include <stdio.h>
char *LCS(char *str1, char *str2)
{
// write code here
// int l1 =strlen(str1);
// int l2 = strlen(str2);
// if(l1==0 || l2 ==0 ){
// return NULL;
// }
// int Max = 0,end = 0;
// int dp[5001][5001] = {0};
// for(int i =1 ;i<=l1;i++){
// for(int j=1;j<=l2;j++){
// if(str1[i-1]==str2[j-1]){
// dp[i][j]=dp[i-1][j-1]+1;
// if(dp[i][j]>Max){
// end = i-1;
// Max = dp[i][j] ;
// }
// }
// else{
// dp[i][j]=0;
// }
// }
// }
// //存到了产犊Max end结束的位置
// char* res = (char* )malloc(sizeof(char)*3000);
// for(int i = 0;i<Max;i++){
// res[i]= str1[end-Max+1+i];
// }
// res[Max]='\0';
// return res;
// #2刷
// 最长公共子串,两个位置的必须相同,不然直接跳过为0
// int len1 = strlen(str1) , len2 = strlen(str2);
// int dp[len1+1][len2+1] ;
// dp[0][0] = 0 ;
// int maxLen = 0;
// int endPos = 0;
// for(int i=1;i<=len1;i++){
// for(int j =1;j<=len2;j++){
// if(str1[i-1]==str2[j-1]){
// dp[i][j] = dp[i-1][j-1]+1;
// if(dp[i][j]>maxLen){
// endPos = i;
// maxLen = dp[i][j];
// }
// }
// else{
// dp[i][j]=0;
// }
// }
// }
// endPos-=1;
// char* res = (char*)malloc(5001*sizeof(char));
// for(int i = 0;i<maxLen;i++){
// res[i] = str1[endPos-maxLen+i];
// }
// res[maxLen] = '\0';
// return res;
// #3刷
int len1 = strlen(str1);
int len2 = strlen(str2);
int **dp = (int **)malloc((len1 + 1) * sizeof(int *));
for (int i = 0; i <= len1; i++)
{
dp[i] = (int *)calloc((len2 + 1), sizeof(int));
}
int maxLen = 0;
int end = 0;
for (int i = 1; i <= len1; i++)
{
for (int j = 1; j <= len2; j++)
{
if (str1[i - 1] == str2[j - 1])
{
dp[i][j] = dp[i - 1][j - 1] + 1;
if (dp[i][j] > maxLen)
{
maxLen = dp[i][j];
// #vip 容易错
end = i - 1;
}
}
else
{
dp[i][j] = 0;
}
}
}
// 处理这个start ->end 的序列:
int start = end - maxLen + 1;
char *res = (char *)malloc(5000 * sizeof(char));
for (int i = 0; i < maxLen; i++)
{
res[i] = str1[start + i];
}
res[maxLen] = '\0';
return res;
}
3 数字翻译成字符串?

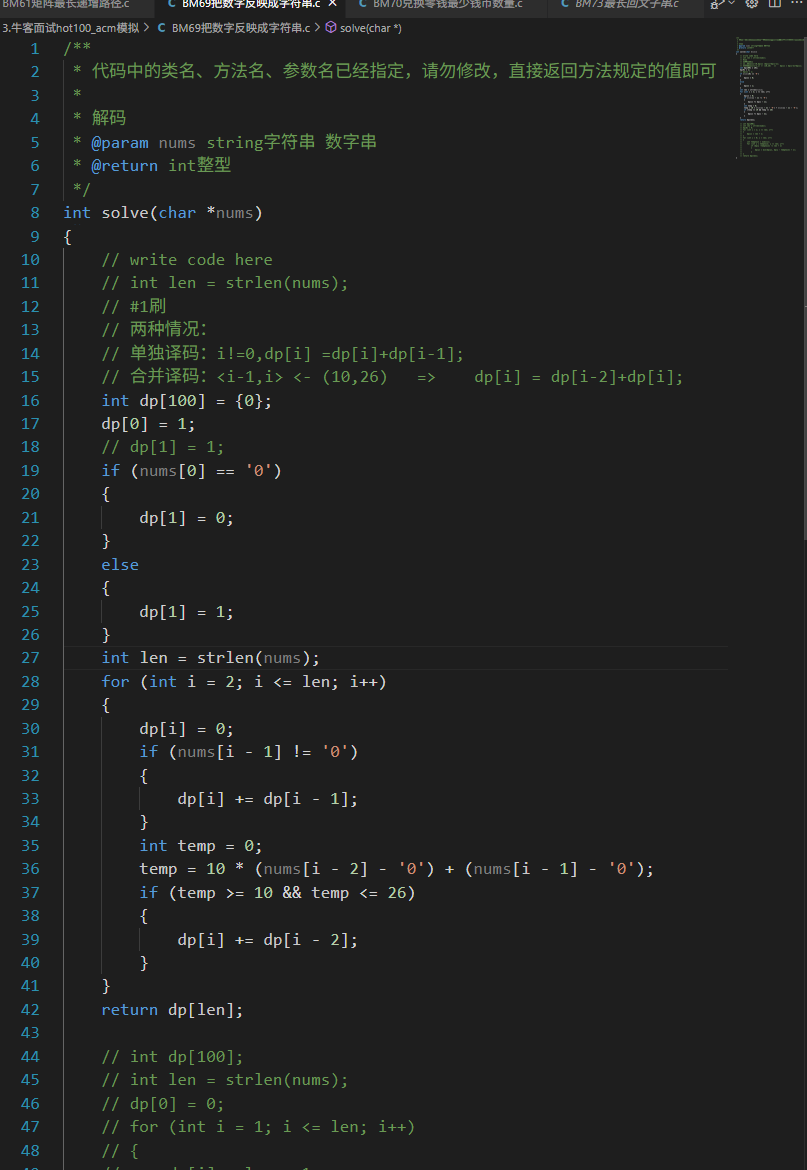
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
* 解码
* @param nums string字符串 数字串
* @return int整型
*/
int solve(char *nums)
{
// write code here
// int len = strlen(nums);
// #1刷
// 两种情况:
// 单独译码:i!=0,dp[i] =dp[i]+dp[i-1];
// 合并译码:<i-1,i> <- (10,26) => dp[i] = dp[i-2]+dp[i];
int dp[100] = {0};
dp[0] = 1;
// dp[1] = 1;
if (nums[0] == '0')
{
dp[1] = 0;
}
else
{
dp[1] = 1;
}
int len = strlen(nums);
for (int i = 2; i <= len; i++)
{
dp[i] = 0;
if (nums[i - 1] != '0')
{
dp[i] += dp[i - 1];
}
int temp = 0;
temp = 10 * (nums[i - 2] - '0') + (nums[i - 1] - '0');
if (temp >= 10 && temp <= 26)
{
dp[i] += dp[i - 2];
}
}
return dp[len];
// int dp[100];
// int len = strlen(nums);
// dp[0] = 0;
// for (int i = 1; i <= len; i++)
// {
// dp[i] = len + 1;
// }
// for (int i = 0; i < len; i++)
// {
// int tempCoin = nums[i];
// for (int j = tempCoin; j <= len; j++)
// if (dp[j -tempCoin] != len + 1)
// {
// dp[j] = min(dp[j], dp[j - tempCoin] + 1);
// }
// }
// return dp[len];
}
关键:
(1)第一种情况:a[i]!=0
(2) 第二章情况:a[i]<(10,26)
4 兑换零钱?
遍历所有的1->len长度的序列的每一个硬币面值:
如果dp[j-coin]!=aim+1 那么更新整个dp[j]的值
比如【5,2,3】 20
第一轮,从5>>>20,更新的有:dp[5] dp[10] dp[15] dp[20]
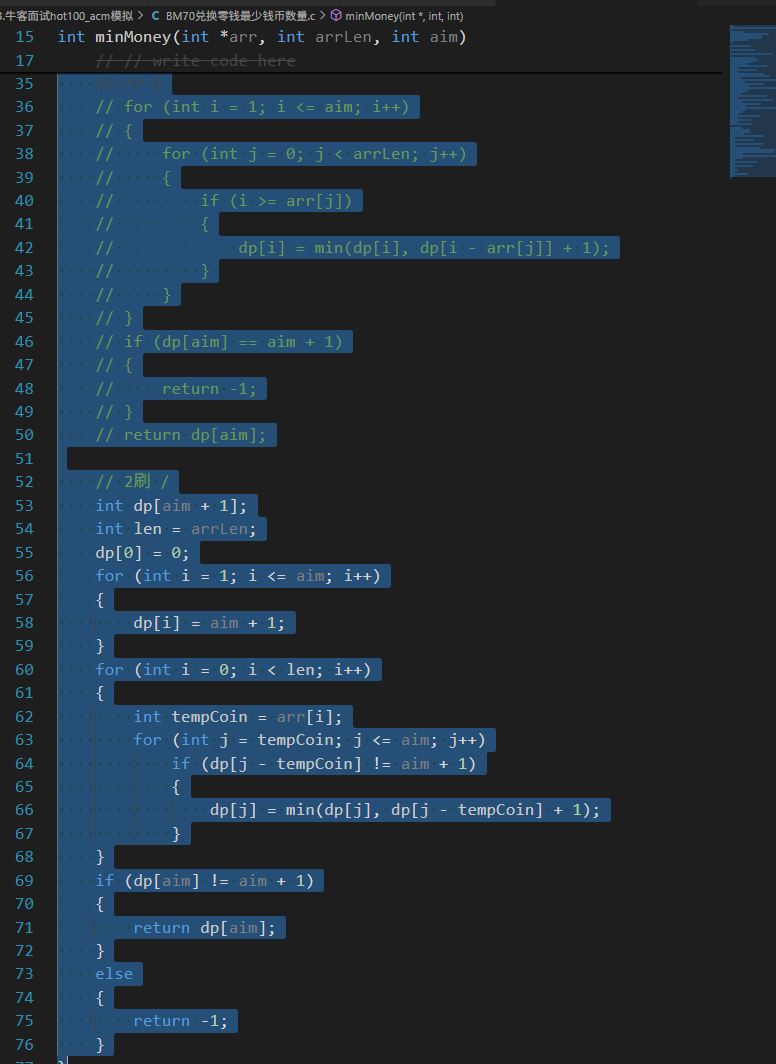
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
* 最少货币数
* @param arr int整型一维数组 the array
* @param arrLen int arr数组长度
* @param aim int整型 the target
* @return int整型
*/
int min(int a, int b)
{
return a < b ? a : b;
}
int minMoney(int *arr, int arrLen, int aim)
{
// // write code here
// int maxLen = aim + 1;
// int dp[aim + 1];
// dp[0] = 0;
// for (int i = 1; i <= aim; i++)
// {
// dp[i] = aim + 1;
// }
// // 随你怎么变 总会比aim+1小
// // for (int i = 1; i <= aim; i++)
// // {
// // for (int j = 0; j < arrLen; j++)
// // {
// // if (i >= arr[j])
// // {
// // dp[i] = min(dp[i], dp[i - arr[j]] + 1);
// // }
// // }
// // }
// for (int i = 1; i <= aim; i++)
// {
// for (int j = 0; j < arrLen; j++)
// {
// if (i >= arr[j])
// {
// dp[i] = min(dp[i], dp[i - arr[j]] + 1);
// }
// }
// }
// if (dp[aim] == aim + 1)
// {
// return -1;
// }
// return dp[aim];
// 2刷 /
int dp[aim + 1];
int len = arrLen;
dp[0] = 0;
for (int i = 1; i <= aim; i++)
{
dp[i] = aim + 1;
}
for (int i = 0; i < len; i++)
{
int tempCoin = arr[i];
for (int j = tempCoin; j <= aim; j++)
if (dp[j - tempCoin] != aim + 1)
{
dp[j] = min(dp[j], dp[j - tempCoin] + 1);
}
}
if (dp[aim] != aim + 1)
{
return dp[aim];
}
else
{
return -1;
}
}5 最长回文?
#include <stdio.h>
#include <math.h>
#include <string.h>
// int doFunc(char *A, int left, int right)
// {
// // 从left和right开始一个个往两边拓展,用一个cnt计数
// // int len = strlen(A);
// // int cnt = 0, flag = 0;
// // if (left == right)
// // {
// // cnt = 1;
// // left--;
// // right++;
// // }
// // while (A[left] == A[right] && left >= 0 && right < len)
// // {
// // cnt += 2;
// // left--;
// // right++;
// // }
// // return cnt;
// //最开始一个都没有,绝对是0
// int res =0;
// //中间相等bab 、 不相等baab
// if(left==right){
// res =1;
// left-=1;
// right+=1;
// }
// // int len = strLen(A);
// int len = strlen(A);
// while(A[left]==A[right] && left>=0 && right<len ){
// res+=2;
// left-=1;right+=1;
// }
// return res;
// }
// int max(int a, int b)
// {
// return a > b ? a : b;
// }
// int getLongestPalindrome(char *A)
// {
// // write code here
// // dp方法:初始状态 - 装填转移 - 边界条件
// // 干活的函数: s , left , right
// // mid 开始,left -1 ,right+1 向两边拓展
// // 主函数,从0到右边,一个个找,
// // #self 从左边开始一个个找
// // int maxLen = 1;
// // int len = strlen(A);
// // if (len == 0)
// // {
// // return 0;
// // }
// // int r1, r2;
// // for (int i = 0; i < len; i++)
// // {
// // r1 = doFunc(A, i, i);
// // r2 = doFunc(A, i, i + 1);
// // int res = max(r1, r2);
// // if (res > maxLen)
// // {
// // maxLen = res;
// // }
// // }
// // return maxLen;
// int maxLen = 1;
// int len = strlen(A);
// for(int i =0;i<len;i++){
// int res1= doFunc(A,i,i);
// int res2 = doFunc(A,i,i+1);
// int res = max(res1,res2);
// if(res>maxLen) maxLen =res;
// }
// return maxLen;
}
// 3刷
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param A string字符串
* @return int整型
*/
int max(int a, int b)
{
return a > b ? a : b;
}
int doFunc(char *a, int len, int left, int right)
{
while (left >= 0 && right < len && a[left] == a[right])
{
left--;
right++;
}
return right - left - 1;
}
int getLongestPalindrome(char *A)
{
// write code here
if (!A)
return -1 + 1;
int len = strlen(A);
if (len == 1)
{
return 1;
}
int maxLen = 1;
for (int i = 0; i < len; i++)
{
int len1 = doFunc(A, len, i, i);
int len2 = doFunc(A, len, i, i + 1);
int tempM = max(len1, len2);
if (tempM > maxLen)
{
maxLen = tempM;
}
}
return maxLen;
}
6 最长上升子序列?
// #include <stdio.h>
// int main()
// {
// int arr[] = {47, 89, 23, 76, 12, 55, 34, 91, 62, 7, 38, 81, 44, 50, 99};
// printf("最长上升子序列是:%d\n\n", LTS(arr, 15));
// printf("最长上升子序列是\n");
// return 0;
// }
// int LTS(int *arr, int arrLen)
// {
// int dp[arrLen];
// if (arrLen == 0)
// {
// return 0;
// }
// for (int i = 0; i < arrLen; i++)
// {
// dp[i] = 1;
// }
// dp[0] = 1;
// int maxLen = 1;
// // for (int i = 1; i < arrLen; i++)
// // {
// // for (int j = 0; j < i; j++)
// // {
// // if (arr[i] > arr[j])
// // {
// // if (dp[j] + 1 > dp[i])
// // {
// // dp[i] = dp[j] + 1;
// // }
// // }
// // }
// // if (dp[i] > maxLen)
// // {
// // maxLen = dp[i];
// // }
// // }
// for(int i =1;i<arrLen;i++){
// for(int j = 0 ;j<i;j++){
// if(arr[i]>arr[j]){
// if(dp[j]+1>dp[i]){
// dp[i] = dp[j]+1;
// }
// }
// }
// if(dp[i]>maxLen ){
// maxLen = dp[i];
// }
// }
// return maxLen;
// }
# 2刷
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
* 给定数组的最长严格上升子序列的长度。
* @param arr int整型一维数组 给定的数组
* @param arrLen int arr数组长度
* @return int整型
*/
int LIS(int *arr, int arrLen)
{
// write code here
if (!arr)
{
return 0;
}
int dp[arrLen];
for (int i = 0; i < arrLen; i++)
{
dp[i] = 1;
}
int maxLen = 1;
for (int i = 0; i < arrLen; i++)
{
for (int j = 0; j < i; j++)
{
if (arr[j] < arr[i])
{
dp[i] = max(dp[i], dp[j] + 1);
maxLen = max(maxLen, dp[i]);
}
else
{
// dp[i] = dp[j];
;
}
}
}
// return dp[arrLen - 1];
return maxLen;
}dp[i] dp[j] 的动态规划:
0-》arrlen
0->i
如果大,
dp[i] = 挑一个大的
记录一下
7 字符串转化ip地址?
8 编辑距离?
9 打家劫舍(1)+(2)?
20257.20三刷!
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param nums int整型一维数组
* @param numsLen int nums数组长度
* @return int整型
*/
#define MaxV 15000
typedef struct Person
{
char name[];
int age;
} chinese;
#include <stdio.h>
int max(int a, int b)
{
return a > b ? a : b;
}
int rob(int *nums, int numsLen)
{
// write code here
// 打家劫舍问题:要么搞nums[i]+dp[i-2] ,要么dp[i-1]
// int dp[numsLen] ;
// dp[1] =max(nums[0],nums[1]);
// dp[0] = nums[0];
// for(int i=2;i<numsLen;i++){
// dp[i] = max(dp[i-1],nums[i]+dp[i-2]);
// }
// return dp[numsLen-1];
// 2刷
char* a[];
int b[100];
int* ptr_Int = b;
if (!nums || numsLen == 0)
{
return 0;
}
if (numsLen == 1)
{
return nums[0];
}
if (numsLen == 2)
{
return max(nums[0], nums[1]);
}
int dp[numsLen];
for (int i = 2; i < numsLen; i++)
{
dp[i] = 0;
}
for (int i = 2; i < numsLen; i++)
{
dp[i] = max(dp[i - 1], dp[i - 2] + nums[i]);
}
return dp[numsLen - 1];
}
// int main(){
// int a[] = {12, 9,6,6,7,7,4,5,3,7,3,3,7,5,23,6,2,36,26,4,23,6,2,36,24,36,3,68,8 ,12};
// int len = sizeof(a)/sizeof(a[0]);
// printf("结果是:%d \n",rob(a,len));
// }环形:
int max(int a, int b)
{
return a > b ? a : b;
}
int rob(int *nums, int numsLen)
{
int dp1[numsLen];
int dp2[numsLen];
int m1 = 0;
int m2 = 0;
// 第一家偷,最后一个不能偷!
// 1st不,last one 可以!
dp1[0] = nums[0];
dp1[1] = dp1[0];
for (int i = 2; i < numsLen - 1; i++)
{
dp1[i] = max(dp1[i - 2] + nums[i], dp1[i - 1]);
}
m1 = dp1[numsLen - 2];
dp2[0] = 0;
dp2[1] = nums[1];
for (int i = 2; i < numsLen; i++)
{
dp2[i] = max(dp2[i - 2] + nums[i], dp2[i - 1]);
}
m2 = dp2[numsLen - 1];
return max(m1, m2);
}
以上是笔记本手写的思维分析+总结
---------------------------------------------------------------------------------------------------------最近更新于2025.7.21 晚上1:00
1 x做过了就会,你不看试试?
2 多回顾题目!
3 脑子过 反复
---------------------------------------------------------------------------------------------------------------------重制版>>>>>更新于2025.7.22晚上10:00
动态规划硬核之路:从最长公共子串到数字翻译(第一部分)
前言:DP,嵌入式面试的“拦路虎”还是“敲门砖”?
兄弟们,咱们搞嵌入式的,C语言是基本功,但算法,特别是动态规划,那绝对是面试大厂的“分水岭”。很多人觉得DP难,无从下手,但我告诉你,DP不是玄学,它有套路,有思想。一旦你掌握了它,它就会从“拦路虎”变成你进入大厂的“敲门砖”!
我大学四年学嵌入式,研究生搞了几年区块链,现在又回来刷C语言准备嵌入式工作,深知这种“半路出家”的痛苦。但正是这种经历,让我对知识的理解更深了一层:基础,永远是王道! 而DP,正是检验你基础功底和逻辑思维能力的绝佳利器。
这篇博客,我将结合我在牛客、力扣上刷题的真实代码,手把手带你剖析DP问题的核心,从最基本的概念讲起,深入浅出,力求让每一个看过100道热题榜的C程序员都能看懂,都能有所收获。
1 动态规划初探:核心思想与基本要素
在深入具体题目之前,咱们先来聊聊动态规划到底是个啥。
动态规划 (Dynamic Programming, DP),简单来说,就是把一个复杂的大问题,拆分成若干个相互关联的子问题,通过解决这些子问题,并把子问题的解存储起来(避免重复计算),最终得到大问题的解。
它的核心思想就俩字:“重叠子问题” 和 “最优子结构”。
-
重叠子问题 (Overlapping Subproblems):解决大问题时,会反复遇到相同的子问题。DP通过记忆化(Memoization)或填表(Tabulation)来存储子问题的解,避免重复计算,大大提高效率。
-
最优子结构 (Optimal Substructure):大问题的最优解可以通过子问题的最优解来构造。这意味着,如果你能找到子问题的最优解,那么把它们组合起来就能得到整个问题的最优解。
构建一个DP解决方案,通常需要明确以下几个要素:
-
DP 状态定义:
dp[i]或dp[i][j]代表什么?这是最关键的一步,定义好了,后面就水到渠成了。 -
DP 状态转移方程:
dp[i]或dp[i][j]如何从之前的状态推导出来?这是DP的核心逻辑。 -
初始化:DP 数组的初始值是多少?通常是边界条件,或者一些特殊情况。
-
边界条件:最小的子问题是什么?它们的解是什么?
-
计算顺序:是自底向上(填表法)还是自顶向下(记忆化搜索)?通常填表法更常见。
我们可以用一张思维导图来概括DP的核心要素:
| DP核心要素 |
描述 |
常见表现形式 |
|---|---|---|
| 状态定义 |
|
数组、二维数组 |
| 转移方程 |
如何从已知状态推导出当前状态? |
|
| 初始化 |
最小子问题的解,或数组的起始值。 |
|
| 边界条件 |
问题的最小规模,或特殊情况的处理。 |
|
| 计算顺序 |
遍历方向,确保计算当前状态时所需的前置状态已计算。 |
通常是嵌套循环,从小到大遍历 |
2 经典问题剖析:最长公共子串 (Longest Common Substring)
好了,理论说完了,咱们直接上硬菜!第一个要讲的,就是最长公共子串。用户在代码里把它写成了 LCS,但从实现来看,它确实是最长公共子串,而不是最长公共子序列。这里咱们先明确一下概念:
-
最长公共子串 (Longest Common Substring):两个字符串中,最长的连续的公共部分。例如 "ABCDE" 和 "ABFCE",最长公共子串是 "AB"。
-
最长公共子序列 (Longest Common Subsequence):两个字符串中,最长的非连续的公共部分(保持相对顺序)。例如 "ABCDE" 和 "ABFCE",最长公共子序列是 "ABCE"。
这两个问题虽然名字相似,但DP状态转移方程有本质区别。咱们先聚焦最长公共子串。
问题描述
给定两个字符串 str1 和 str2,找出它们的最长公共子串。
用户代码分析与思考
我们先来看看用户提供的LCS函数(实际是最长公共子串)的代码:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
* longest common substring
* @param str1 string字符串 the string
* @param str2 string字符串 the string
* @return string字符串
*/
#include <stdio.h>
#include <string.h> // 补充头文件
#include <stdlib.h> // 补充头文件
char *LCS(char *str1, char *str2){
// write code here
// #3刷
int len1 = strlen(str1);
int len2 = strlen(str2);
// 动态分配二维数组,避免栈溢出,尤其是在大字符串时
int **dp = (int **)malloc((len1 + 1) * sizeof(int *));
for (int i = 0; i <= len1; i++)
{
// calloc 会自动将内存初始化为0,非常适合DP数组
dp[i] = (int *)calloc((len2 + 1), sizeof(int));
}
int maxLen = 0; // 记录最长公共子串的长度
int end = 0; // 记录最长公共子串在str1中的结束位置(索引)
for (int i = 1; i <= len1; i++)
{
for (int j = 1; j <= len2; j++)
{
// 如果当前字符匹配
if (str1[i - 1] == str2[j - 1])
{
// 状态转移:当前公共子串长度等于前一个字符匹配时的长度加1
dp[i][j] = dp[i - 1][j - 1] + 1;
// 更新最大长度和结束位置
if (dp[i][j] > maxLen)
{
maxLen = dp[i][j];
// #vip 容易错:end记录的是str1中子串的结束索引
// 因为i是基于1的索引,str1[i-1]是当前字符,所以i-1就是当前字符的索引
end = i - 1;
}
}
else
{
// 如果当前字符不匹配,则公共子串断开,长度重置为0
dp[i][j] = 0;
}
}
}
// 处理这个start ->end 的序列:
// 根据最长子串的长度和结束位置,计算起始位置
int start = end - maxLen + 1;
// 分配结果字符串内存,maxLen + 1 用于存放 '\0'
char *res = (char *)malloc((maxLen + 1) * sizeof(char));
if (res == NULL) { // 内存分配失败检查
// 释放之前分配的dp内存
for (int i = 0; i <= len1; i++) {
free(dp[i]);
}
free(dp);
return NULL; // 返回错误
}
// 复制子串到结果字符串
for (int i = 0; i < maxLen; i++)
{
res[i] = str1[start + i];
}
res[maxLen] = '\0'; // 添加字符串结束符
// 释放动态分配的dp内存,避免内存泄漏
for (int i = 0; i <= len1; i++)
{
free(dp[i]);
}
free(dp);
return res;
}
我的分析和思考:
用户这份代码已经是第三次刷了,进步非常明显!从注释的 #3刷于7/15 和 #vip 容易错 都能看出,用户在思考和解决问题过程中遇到的困惑和进步。
优点:
-
DP 状态定义清晰:
dp[i][j]表示以str1[i-1]和str2[j-1]结尾的最长公共子串的长度。这个定义非常关键,因为它直接决定了状态转移方程。 -
状态转移方程正确:
if (str1[i-1] == str2[j-1]) { dp[i][j] = dp[i-1][j-1] + 1; } else { dp[i][j] = 0; }完美体现了子串连续性的要求。 -
动态分配
dp数组:用户从之前的固定大小数组int dp[5001][5001]改为malloc动态分配,这是一个巨大的进步!避免了栈溢出,使得代码能处理更长的字符串。 -
calloc初始化:使用calloc自动初始化为0,省去了手动清零的步骤,代码更简洁。 -
记录
maxLen和end:能够正确地记录最长公共子串的长度和其在str1中的结束位置,这是构建结果字符串的关键。
可以优化和改进的地方:
-
头文件缺失:
strlen,malloc,free都需要<string.h>和<stdlib.h>。虽然在某些IDE或编译器下可能隐式包含,但为了代码的健壮性和可移植性,必须显式包含。 -
malloc大小:在char* res = (char* )malloc(sizeof(char)*3000);或char* res = (char*)malloc(5001*sizeof(char));处,虽然用户在第三次刷的时候改成了5000 * sizeof(char),但更精确和安全的做法是根据maxLen来分配,即(maxLen + 1) * sizeof(char),因为maxLen可能远小于5000,造成内存浪费;也可能在极端情况下maxLen超过5000,导致内存不足。 -
内存泄漏:在返回
res之前,需要free掉之前malloc出来的dp数组。用户在第三次刷的时候已经考虑到了这一点,并在返回前释放了dp数组,非常棒! -
边界条件处理:虽然代码中
if(len1==0 || len2 ==0 )的注释部分被删除了,但对于空字符串的输入,最好在函数开头进行显式检查,避免后续操作出现空指针解引用。
深入浅出:最长公共子串的DP原理与实现
咱们来彻底捋一遍最长公共子串的DP思路。
1. DP 状态定义:
dp[i][j] 表示以 str1[i-1] 结尾且以 str2[j-1] 结尾的最长公共子串的长度。 注意这里的 i 和 j 是为了方便DP数组的索引,它们分别对应 str1 和 str2 的前 i 个和前 j 个字符。所以实际字符索引是 i-1 和 j-1。
2. DP 状态转移方程:
-
如果
str1[i-1] == str2[j-1](当前字符匹配):dp[i][j] = dp[i-1][j-1] + 1这意味着,如果当前字符匹配,那么最长公共子串的长度就是它们前一个字符匹配时的长度加1。 -
如果
str1[i-1] != str2[j-1](当前字符不匹配):dp[i][j] = 0因为是“子串”,要求连续,一旦不匹配,公共子串就断了,长度自然归零。
3. 初始化:
-
dp[0][j] = 0(当str1为空时,没有公共子串) -
dp[i][0] = 0(当str2为空时,没有公共子串) -
由于我们使用
calloc动态分配并初始化为0,这些边界条件自然满足。
4. 计算顺序:
从 i = 1 到 len1,从 j = 1 到 len2,双重循环遍历。
DP 状态表(以 str1 = "ABCDE", str2 = "ABFCE" 为例):
| "" |
A=0 |
B=1 |
F=2 |
C=3 |
E=4 |
|
|---|---|---|---|---|---|---|
| "" |
0 |
0 |
0 |
0 |
0 |
0 |
| A=0 |
0 |
1 |
0 |
0 |
0 |
0 |
| B=1 |
0 |
0 |
2 |
0 |
0 |
0 |
| C=2 |
0 |
0 |
0 |
0 |
1 |
0 |
| D=3 |
0 |
0 |
0 |
0 |
0 |
0 |
| E=4 |
0 |
0 |
0 |
0 |
0 |
1 |
解释:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1129
1129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









