










论文题目:Modeling Relational Data with Graph Convolutional Networks
论文来源:ESWC 2018
论文链接:https://arxiv.org/abs/1703.06103
代码链接:https://github.com/tkipf/relational-gcn
关键词:知识图谱,GCN,基函数分解,块对角分解
提出关系图卷积网络(R-GCNs),用于两个知识库的补全任务:链接预测、实体分类(恢复丢失的实体属性)。
1 引言
知识图谱中存储了大量的知识,可用于问答系统、信息检索等下游任务。但是许多知识图谱都是不完备的,例如DBPedia、Wikidata、Yago,有许多信息的缺失,这会影响其在下游任务中的应用。预测知识库中缺失的信息是统计关系学习(SRL)的主要研究内容。
考虑两个基本的SRL任务:链接预测(恢复缺失的三元组)、实体分类(为实体分配类型或类别属性)。
许多缺失的信息都是隐含在通过邻居结构编码的图中。作者从这一思想出发,设计了一个编码器,编码关系网络中的实体,并应用于这两个任务中。
实体分类模型:对图上的每个节点使用softmax分类器,R-GCN得到的节点表示作为分类器的输入。这个模型以及R-GCN的参数都是通过优化交叉熵损失学习得到的。
链接预测模型:可视为由一个encoder和一个decoder组成的自编码器。
1)encoder:R-GCN为实体生成隐层的特征表示;
2)decoder:张量的分解模型,利用encoder生成的表示预测边的label。
按理说decoder可以使用任何一种形式的分解/打分函数,作者使用了最简单并最有效的分解方法:DistMult。
贡献
(1)第一个将GCN用于建模关系型数据的工作,尤其是针对链接预测和实体分类任务。
(2)在R-GCN中使用了参数共享和稀疏约束,应用于有大量关系的多个图。
(3)实验证明,以DistMult为例,使用一个在关系图中执行多步信息传播的encoder模型来丰富矩阵分解的模型,可以显著提高其性能。
2 神经关系建模
定义有向的且有标签的多个图为 G = ( V , E , R ) G=(\mathcal{V}, \mathcal{E}, \mathcal{R}) G=(V,E,R),节点为 v i ∈ V v_i\in \mathcal{V} vi∈V,有标签的边为 ( v i , r , v j ) ∈ E , r ∈ R (v_i,r,v_j)\in \mathcal{E}, r\in \mathcal{R} (vi,r,vj)∈E,r∈R。
2.1 Relational Graph Convolutional Networks
模型的动机是使用图中局部的邻居信息,将GCN扩展到大规模的关系型数据中。可以理解成是一个简单可微的消息传递框架:
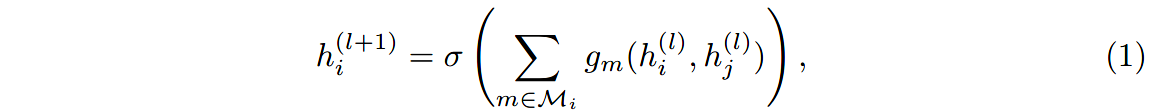
其中 M i \mathcal{M}_i Mi表示节点 v i v_i vi的传入消息集合,通常为入度的边缘集。 g m ( ⋅ , ⋅ ) g_m(\cdot, \cdot) gm(⋅,⋅)可以是类似神经网络的函数,也可以是简单的线性转换。
这种方式可以有效地聚合编码局部邻域结构的特征,并且在图分类和基于图的半监督学习等任务中表现出了很好的效果。
受上述架构的启发,作者定义了如下的消息传播模型:
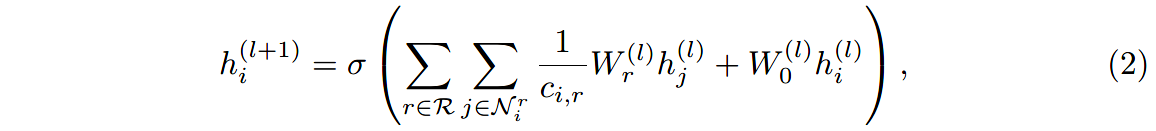
其中 N i r \mathcal{N}^r_i Nir表示与节点 i i i有 r r r类型连边的邻居节点。 c i , r c_{i,r} ci,r是针对特定问题的归一化常数,可以学习得到也可以预先设定(例如 c i , r = ∣ N i r ∣ c_{i,r}=|\mathcal{N}^r_i| ci,r=∣Nir∣)。
使用 W h j Wh_j Whj这种线性的转换形式的优点:(1)不需要储存中间过程的基于边的表示信息,节省了存储空间;(2)可进行向量化的运算。
和正规的GCN不同的是,作者引入的是relation-specific的转换,依赖于边的类型以及边的方向。为了保证第 l l l层的节点表示信息可以传递给第 l + 1 l+1 l+1层的节点,作者为每个节点都添加了一个特殊类型的关系——自连接。
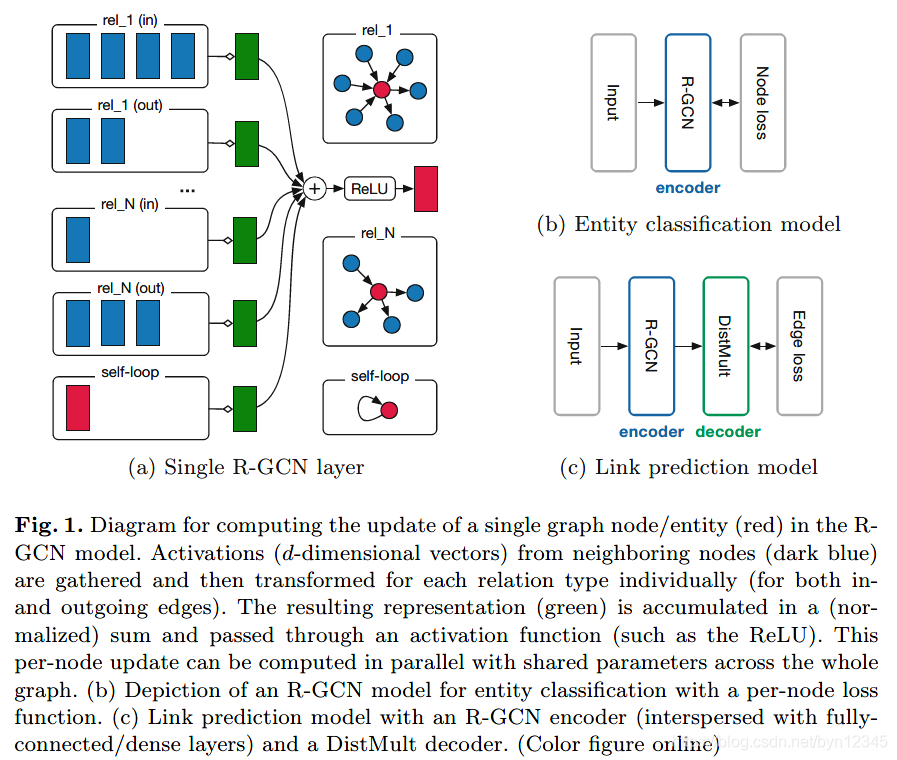
式(2)对所有节点进行并行计算,就可以实现神经网络层的更新,堆叠多层可以捕获多步之间的关系依赖。将这个图编码模型就是R-GCN。图1描述了使用R-GCN模型对图中一个节点的更新过程。
2.2 Regularization
式(2)应用于多关系型数据面临的主要问题就是:随着图中关系数量的增长,参数的数量迅速增长。这很容易导致过拟合。
有两种方法可以解决参数量过大的问题:
- 在权重矩阵间共享参数
- 在权重矩阵中进行稀疏约束
针对这两种策略,作者引入了两种方法,用于R-GCN层权重的正则化:基函数分解(basis-decomposition) 和 块对角分解(block-diagonal-decomposition)。
(1)基函数分解
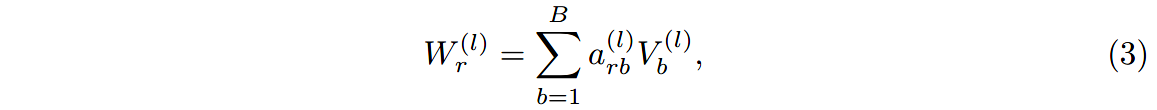
W r ( l ) W^{(l)}_r Wr(l)定义为基变换 V b ( l ) ∈ R d ( l + 1 ) × d ( l ) V^{(l)}_b\in \mathbb{R}^{d^{(l+1)}\times d^{(l)}} Vb(l)∈Rd(l+1)×d(l)的线性组合, a r b ( l ) a^{(l)}_{rb} arb(l)是系数,只有系数依赖于关系 r r r。
(2)块对角分解
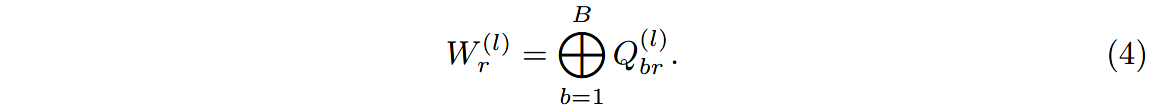
W r ( l ) W^{(l)}_r Wr(l)求得后是块对角矩阵:
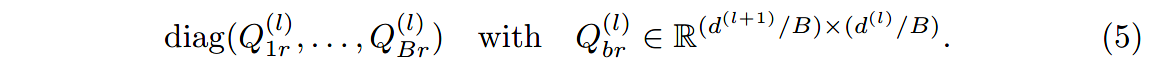
块对角分解就是(DistMult)解码器中使用的对角稀疏约束的推广。
基函数分解是实现不同关系类型间权重共享的一种形式;块分解可看成是对每种关系的权重矩阵的稀疏约束。
块分解的结构认为潜在的特征可以被分成多组变量,组内的联系比组间的更加紧密。
对于高度多关系类型的数据(例如 知识库),这两种分解的方式都减少了参数。
R-GCN模型的流程如下:像式(2)定义的那样,堆叠 L L L层,当前层的输出为下一层的输入。若没有给定节点的特征,则为每个节点赋予唯一的one-hot向量,作为第一层的输入。对于块分解,通过一层线性变换将one-hot向量映射成稠密的表示。
本文只考虑节点无特征的方法,当然GCN类型的方法可以结合预定义的特征向量。
3 实体分类
堆叠多层R-GCN层,最后一层的输出后再过一个softmax函数。忽略未标注的节点,对所有已标注的节点最小化如下的交叉熵损失:
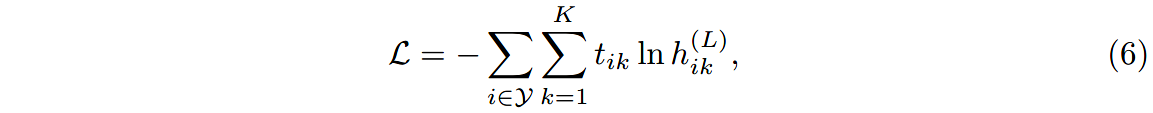
其中 Y \mathcal{Y} Y是有标签的节点集合, h i k ( L ) h^{(L)}_{ik} hik(L)是第 i i i个已标注的节点在第 k k k个位置的输出, t i k t_{ik} tik表示对应的ground truth标签。如图1b所示。
4 链接预测
知识库由有向的有标签的图 G = ( V , E , R ) G=(\mathcal{V}, \mathcal{E}, \mathcal{R}) G=(V,E,R)组成。通常边的集合不是完全给定的,只给定了不完整的边集合 E ^ \mathcal{\hat{E}} E^。链接预测的目标就是给定可能的边 ( s , r , o ) (s, r, o) (s,r,o),计算打分函数 f ( s , r , o ) f(s, r, o) f(s,r,o),判断边属于$ \mathcal{E}$的可能性。
为了解决这一问题,引入如图1 c所示的自编码器模型,由实体编码器和打分函数(decoder)组成。
编码器将每个实体 v i v_i vi映射成实值向量 e i ∈ R d e_i\in \mathbb{R^d} ei∈Rd。
解码器根据编码器得到的节点表示信息,重构图中的边。具体而言,解码器使用打分函数为三元组 ( s u b j e c t , r e l a t i o n , o b j e c t ) (subject, relation, object) (subject,relation,object)打分,判断这个三元组对应的边在图中是否存在。现有的链接预测的方法几乎都采用了这种方式。
本文的方法和先前方法的主要区别在于对编码器的依赖。先前的方法大多对每个节点 v i v_i vi使用单一的、实值的向量 e i e_i ei,直接在训练过程中优化。本文的方法是使用带有 e i = h i ( L ) e_i=h^{(L)}_i ei=hi(L)的R-GCN编码器计算表示。
实验中,使用DistMult分解作为打分函数。其中,每个关系 r r r都和一个对角矩阵 R r ∈ R d × d R_r\in \mathbb{R^{d\times d}} Rr∈Rd×d相关联,对三元组 ( s , r , o ) (s, r, o) (s,r,o)的评分计算如下:
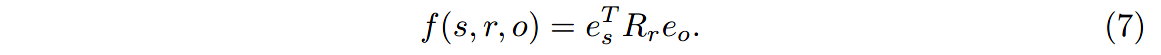
训练时使用负采样技术,随机替换正样本的subject或object,生成 w w w个负样本。使用交叉熵损失,让模型对正样本的打分值比负样本高:
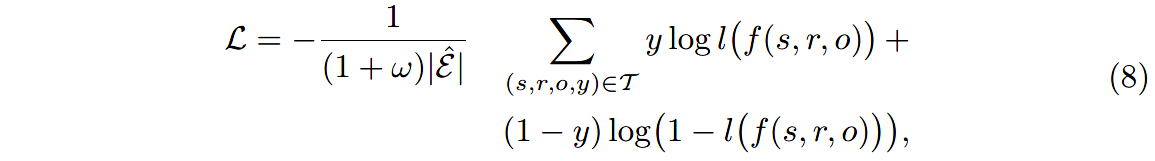
其中, T \mathcal{T} T是正样本和负样本的三元组集合, l l l是logistic sigmoid函数, y y y是正负样本的指示函数。
5 实验
数据集:
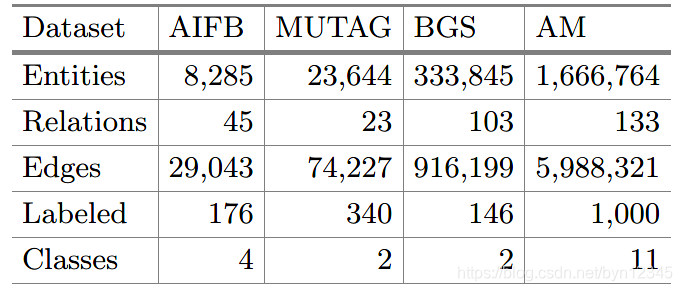
实验任务:链接预测、实体分类
实验结果:
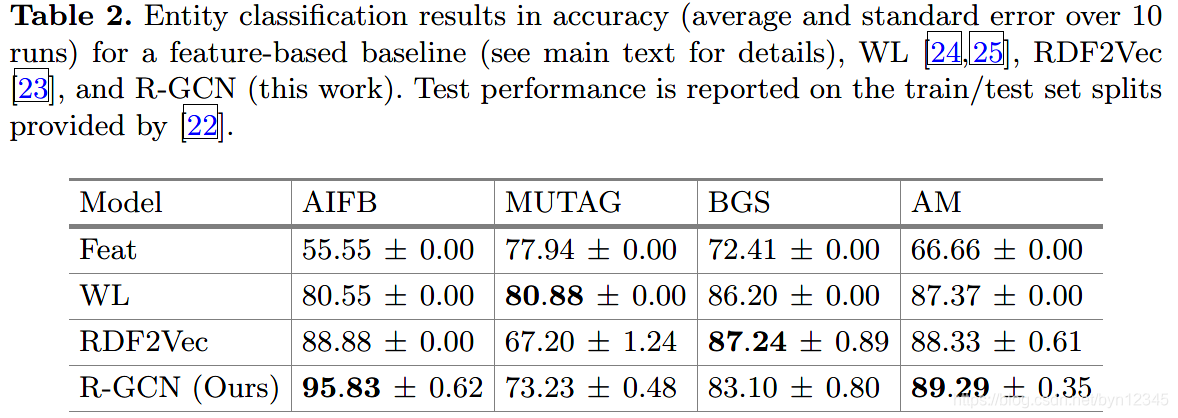
(1)实体分类
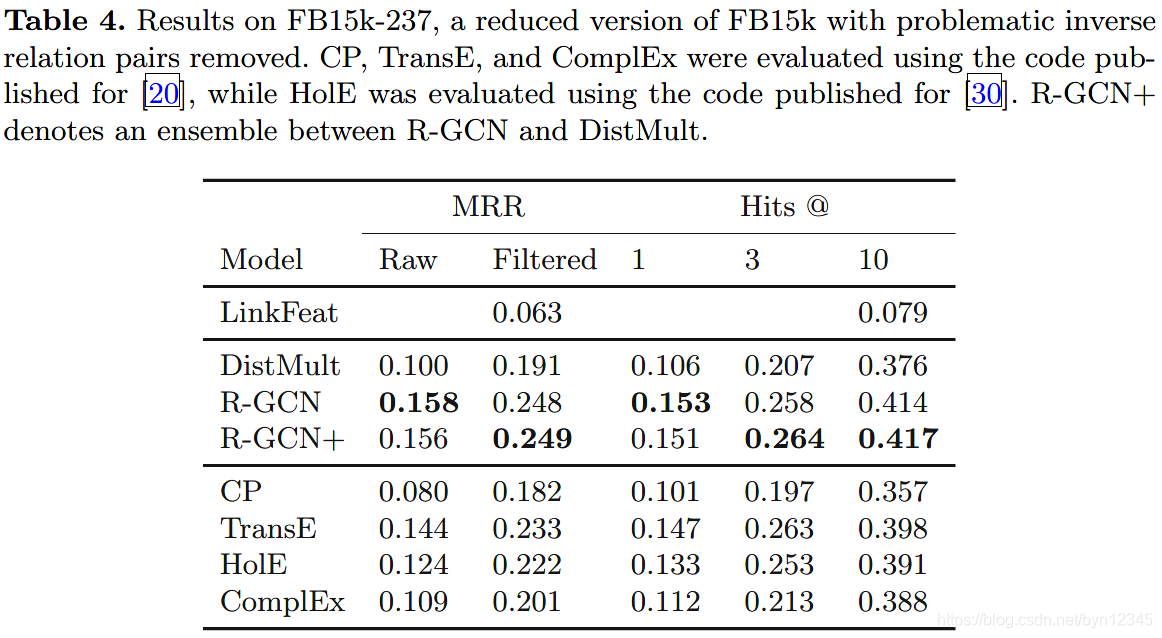
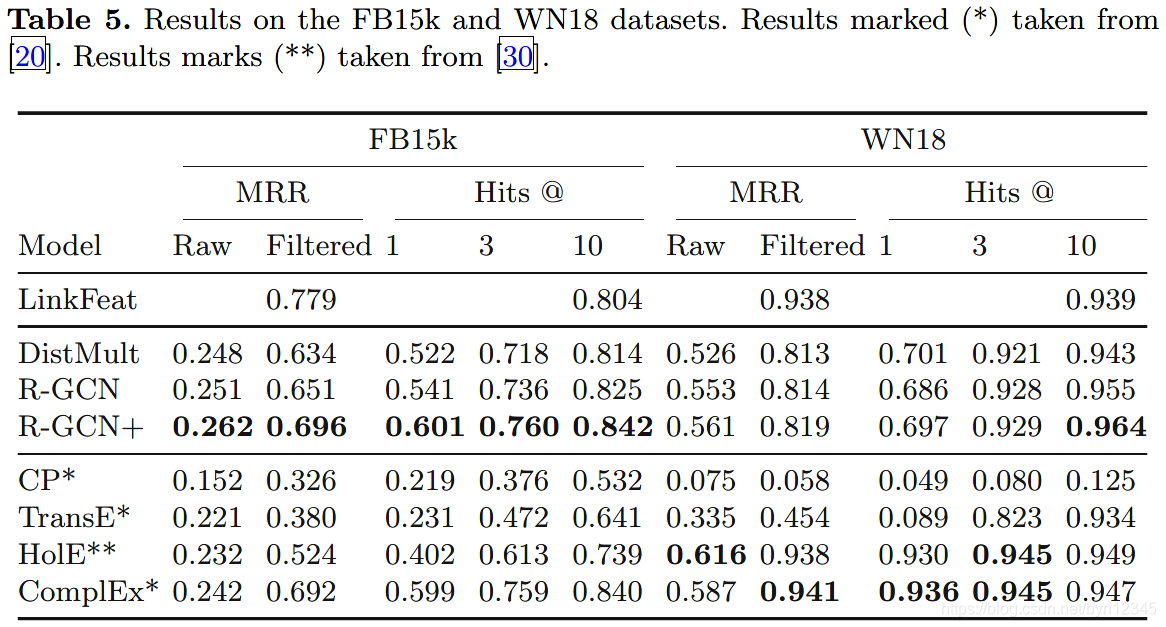
(2)链接预测

















 665
665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









