




概述
最近决定将数据结构这块,系统的整理复习一下,这次来到HashMap这块了。在之前的JDK1.7时代,HashMap的内部是基于数组+链表实现的,采用链表法解决哈希冲突,但是要知道哈希算法很难保证所有元素都能均匀分布,因此会有大量的元素都存放在一个哈希桶中,此时查找的时间复杂度就是O(n)了,而在JDK1.8中HashMap的实现有较大的优化,改为数组+链表+红黑树,查找时间复杂度为O(logn)。
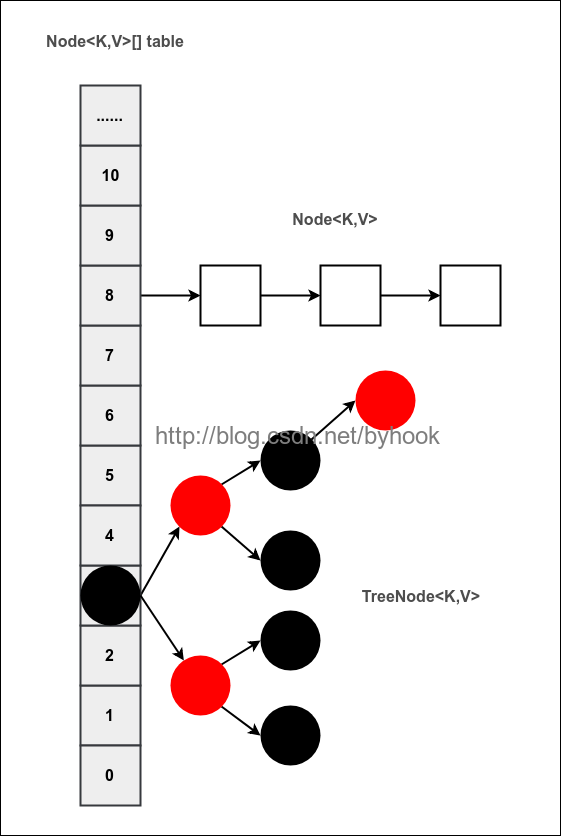
结构图
根据网上很多作者的博客,以及笔者自己对源码的认识,整理的一张结构图:
关键参数
`哈希桶的阀值:当哈希桶中的元素超过这个值时,就会转换为红黑树节点替换链表节点。`
static final int TREEIFY_THRESHOLD = 8;
`树的链表还原阈值:当扩容时,桶中元素个数小于这个值的时候就会把树形的桶元素还原为链表结构。`
static final int UNTREEIFY_THRESHOLD = 6;
`哈希表的最小树形化容量:当哈希表中的容量大于这个值时,表中的桶才能进行树形化,
否则桶内元素太多时会扩容,而不是树形化,为了避免进行扩容、树形化选择的冲突,这个值不能小于 4 * TREEIFY_THRESHOLD
static final int MIN_TREEIFY_CAPACITY = 64;
下面是TreeNode的说明
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent;//父节点
TreeNode<K,V> left;//左子树
TreeNode<K,V> right;//右子树
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red; //红黑属性
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
/**
* 返回当前节点的根节点
*/
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
}
put操作
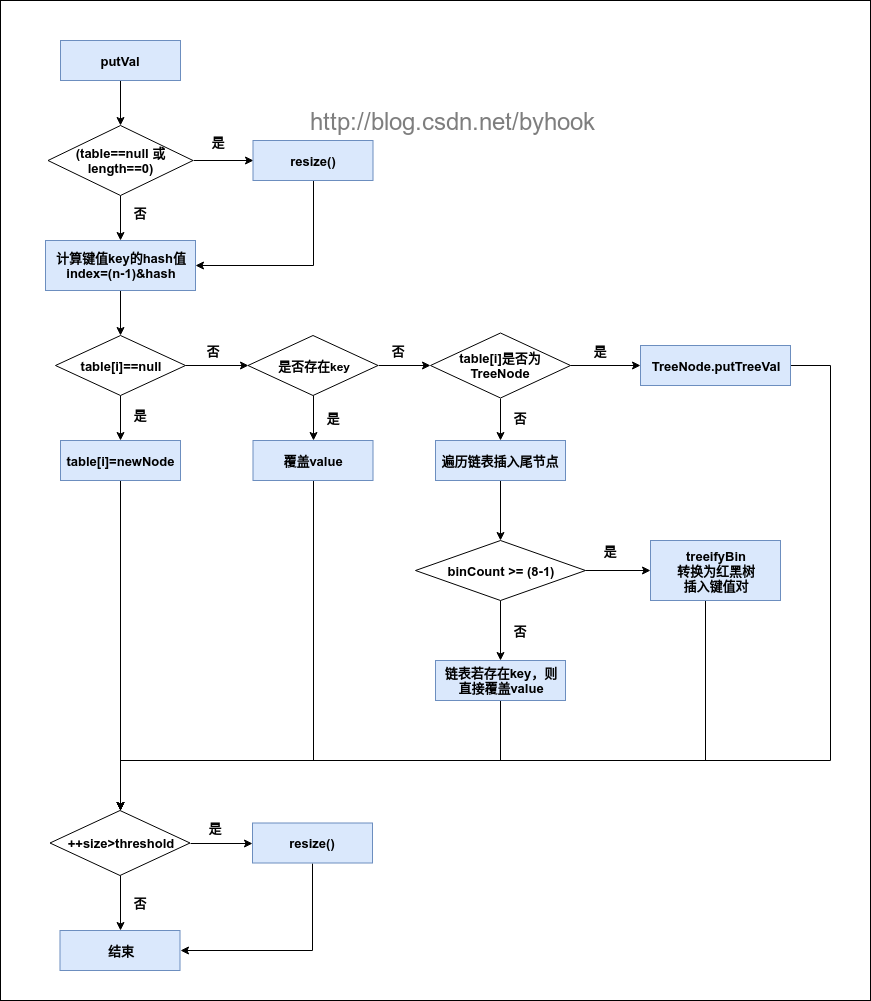
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
//如果table为空或者table长度为0,则进行扩容操作
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
//计算key的hash值并计算下标,如果未命中则直接赋值
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//如果成功命中当前key的hash值,则直接覆盖
e = p;
else if (p instanceof TreeNode)
//如果该链为红黑树,则加入树节点
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
//遍历链表
if ((e = p.next) == null) {
//链表尾部直接插入新的节点
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//数量已经达到定义的阀值,则转换为红黑树
treeifyBin(tab, hash);
break;
}
//判断链表中结点的key值与插入的元素的key值是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 在桶中找到key值、hash值与插入元素相等的结点
if (e != null) {
//记录旧值
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 实际大小大于阈值则扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
get操作
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//如果table已经初始化,长度大于0,且根据key命中的table项也不为空
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//检查哈希桶中第一个元素
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
//哈希桶中还有下一个节点
if (first instanceof TreeNode)
//该节点为红黑树节点,则直接从红黑树中获取
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
//遍历链表,查询该key对应的值
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
扩容操作
在JDK1.7中进行扩容的时候,所有的节点会重新计算hash,并且旧链表迁移到新链表的时候,如果在新链表的数组索引位置相同,则链表元素会倒置,而在JDK1.8中省去了重新hash的时间,重点看下图hash求余的过程:
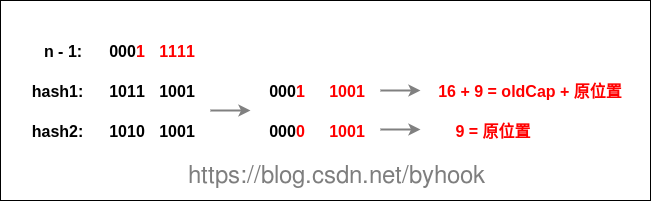
在JDK1.8中多了一个高位运算,桶数组每次扩容都是2的n次方,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),只需要通过该标识就可以判断索引是否有发生变化,是0的话索引没变,是1的话索引变成"原位置+oldCap"
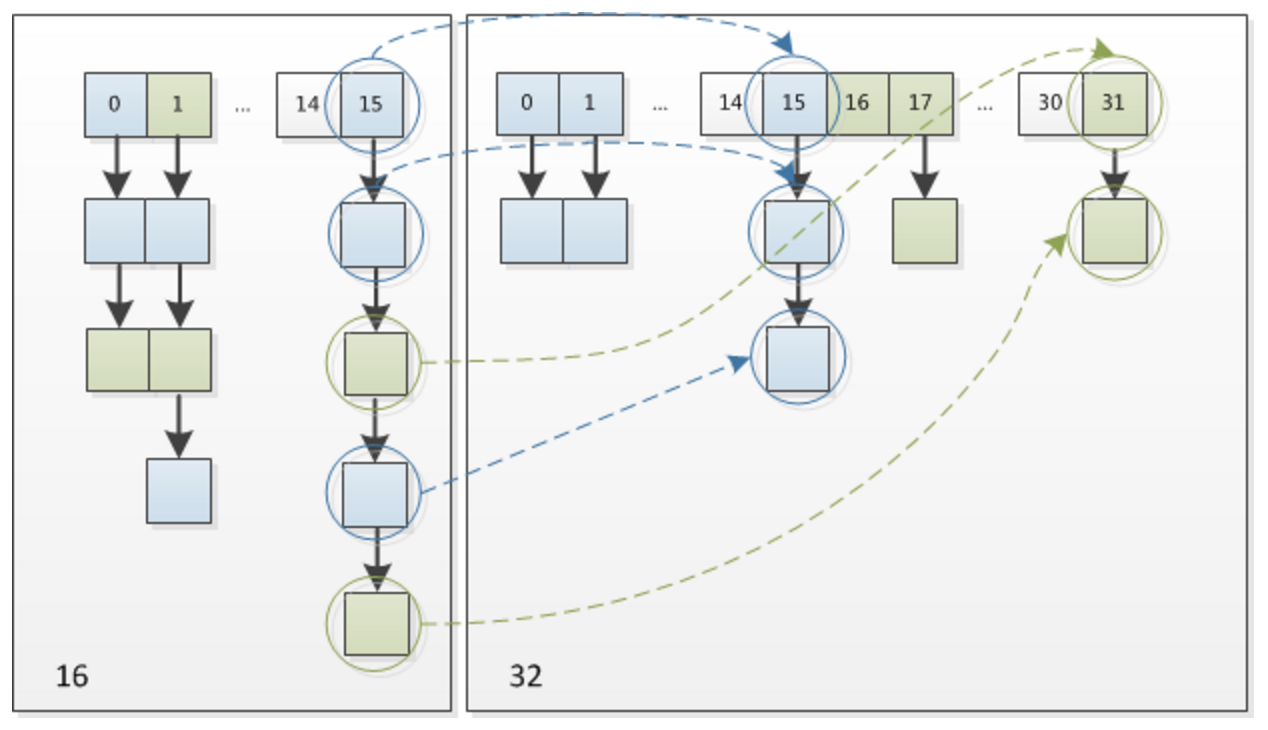
由16扩容为32的示意图:
疑问
为什么哈希桶的长度要为2的n次方?
我们先从哈希算法入手,要知道,对于一个良好的哈希算法,散列出来的元素应该是均匀分布的,我们来看看JDK1.8源码中HashMap的哈希算法实现
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
上面的过程,会先根据我们的key获取到对应的hashCode的值,然后将高16位进行与运算,接下来会计算具体的哈希桶下标:
int index = (tab.length - 1) & hash;
在二进制中,2的n次方实际就是1后面n个0,而2的n次方-1 实际就是n个1,我们设想一下:
例如长度为9时候,3&(9-1)=0 2&(9-1)=0 ,都在相同位置,碰撞了,会导致大量的元素分布在同一个位置
例如长度为8时候,3&(8-1)=3 2&(8-1)=2 ,都在不同位置,不碰撞,大量的元素均匀的分布
因此哈希桶的长度设计为2的n次方实际就是为了更方便的将大量元素均匀分布
参考:
https://blog.youkuaiyun.com/v123411739/article/details/78996181
https://www.cnblogs.com/xiaoxi/p/7233201.html
https://segmentfault.com/a/1190000012926722

















 459
459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









