



前言
最近学习了一新概念,叫科学发现和科技发明,科学发现是高于科技发明的,而这个说法我觉得还是挺有道理的,我们总说中国的科技不如欧美,但我们实际感觉上,不论建筑,硬件还是软件,理论,我们都已经高于欧美了,那为什么还说我们不如欧美呢?
科学发现是高于科技发明就很好的解释了这个问题,即,我们的在线支付,建筑行业等等,这些都是科技发明,而不是科学发现,而科学发现是引领科技发明的,而欧美在科学发现上远远领先我们,科技发明上虽然领先的不多,但也有很多大幅领先的,比如chatgpt。
说这些的主要目的是想说明,软件开发也是科技发明,所以这个行业的高手,再高的水平,也就那么回事。
也就是说,即便你是清北的,一旦你进入科技发明的队伍,那也就那么回事了。
现在的硕士博士90%都是在研究科技发明的方向,也就是说绝大部分硕士博士都将是工人。
神经网络并不难,我的这个系列文章就证明了,你完全不会python,完全没学过算法,一样可以在短时间内学会。
我个人感觉,一周到一个月之内,都能学会。
但这个东西是很多研究生博士在学的东西,那也就是说,普通的研究生和博士生最后搞出来的论文,其实就是一个星期的知识,而具体的深度理论,他们也只是知道个模糊的概念,这是因为研究生导师和博士生导师本身也就只知道个模糊的概念。
那最后的结果就是,从学者的角度来看,这些人都不能算搞学术的。从工人的角度来看,这些人都不具备熟练的技能。
然而,这些人如果未进入甲方,那最终都是要走向工人岗位,那就出现了一个现象,清北毕业生跟高中生是一个起跑线,在熟练的工人眼中,他们都是一张白纸。
而至于谁能在短时间内熟练掌握这一个星期的知识和技能的运用,根本与出身无关。
所以,只要都在工人这个领域,大家都是一样的。
会的不必高人一等的看别人,不会的也不用觉得人家是高水平。
本文内容
本文主要介绍结合神经网络进行机器人开发。
准备工作
运行代码前,我们需要先下载nltk包。
首先安装nltk的包。
pip install nltk
然后下载nltk工具,编写一个py文件,写代码如下:
import nltk
nltk.download()
然后使用管理员打开cmd,运行这个py文件。
C:\Project\python_test\github\PythonTest\venv\Scripts\python.exe C:\Project\python_test\github\PythonTest\robot_nltk\dlnltk.py
然后弹出界面如下,修改保存地址:
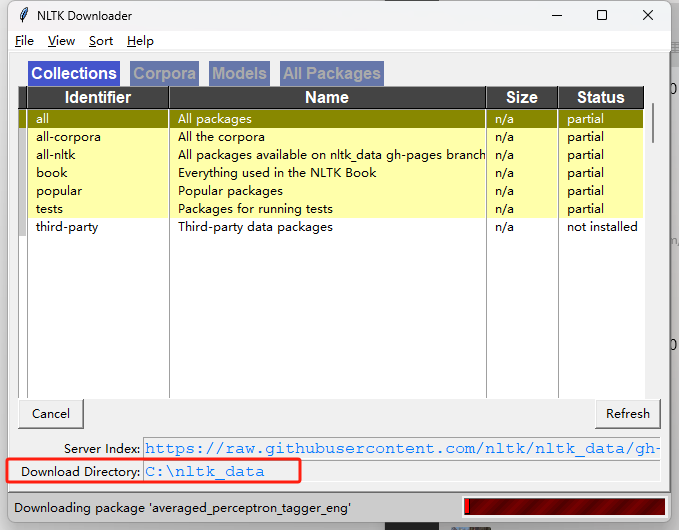
PS:有资料说可以直接运行 nltk.download('punkt') ,下载我们需要的指定的包,但我没下载成功,我还是全部下载了。
# nltk.download('punkt') #是 NLTK (Natural Language Toolkit) 库中的一个命令,用来下载名为 'punkt' 的资源,通常用于 分词(Tokenization)
# nltk.download('popular') #命令会下载 NLTK 中大部分常用的资源,比punkt的资源更多
代码编写
编写model
首先编写一个NeuralNet(model.py)如下:
import torch.nn as nn
class NeuralNet(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(NeuralNet, self).__init__()
self.l1 = nn.Linear(input_size, hidden_size)
self.l2 = nn.Linear(hidden_size, hidden_size)
self.l3 = nn.Linear(hidden_size, num_classes)
self.relu = nn.ReLU()
def forward(self, x):
out = self.l1(x)
out = self.relu(out)
out = self.l2(out)
out = self.relu(out)
out = self.l3(out)
# no activation and no softmax at the end
return out
然后编写一个工具nltk_utils.py如下:
import numpy as np
import nltk
from nltk.stem.porter import PorterStemmer
stemmer = PorterStemmer()
def tokenize(sentence):
return nltk.word_tokenize(sentence)
def stem(word):
return stemmer.stem(word.lower())
def bag_of_words(tokenized_sentence, words):
sentence_words = [stem(word) for word in tokenized_sentence]
bag = np.zeros(len(words), dtype=np.float32)
for idx, w in enumerate(words):
if w in sentence_words:
bag[idx] = 1
return bag
a="How long does shipping take?"
print(a)
a = tokenize(a)
print(a)
这个文件可以直接运行,测试工具内函数的应用。
词干化和token化
词干化就是把单词提取成词干。逻辑如下:
b.92demo.com
anshan.b.92demo.com
ankang.b.92demo.com
alaer.b.92demo.com
aletai.b.92demo.com
ali.b.92demo.com
anyang.b.92demo.com
anqing.b.92demo.com
anshun.b.92demo.com
beijing.b.92demo.com
baicheng.b.92demo.com
baishan.b.92demo.com
benxi.b.92demo.com
baotou.b.92demo.com
bayannaoer.b.92demo.com
baoding.b.92demo.com
baoji.b.92demo.com
binzhou.b.92demo.com
bayinguoleng.b.92demo.com
boertala.b.92demo.com
baiyin.b.92demo.com
bengbu.b.92demo.com
bozhou.b.92demo.com
bijie.b.92demo.com
bazhong.b.92demo.com
baoshan.b.92demo.com
baise.b.92demo.com
beihai.b.92demo.com
baisha.b.92demo.com
baoting.b.92demo.com
chongqing.b.92demo.com
changchun.b.92demo.com
chaoyang.b.92demo.com
chifeng.b.92demo.com
chengde.b.92demo.com
cangzhou.b.92demo.com
changzhi.b.92demo.com
changji.b.92demo.com
changdu.b.92demo.com
changzhou.b.92demo.com
chuzhou.b.92demo.com
chizhou.b.92demo.com
changsha.b.92demo.com
chenzhou.b.92demo.com
changde.b.92demo.com
chengdu.b.92demo.com
chaozhou.b.92demo.com
chuxiong.b.92demo.com
chongzuo.b.92demo.com
chengmai.b.92demo.com
changjiang.b.92demo.com
daxinganling.b.92demo.com
daqing.b.92demo.com
dalian.b.92demo.com
dandong.b.92demo.com
datong.b.92demo.com
dezhou.b.92demo.com
dongying.b.92demo.com
dingxi.b.92demo.com
dazhou.b.92demo.com
deyang.b.92demo.com
dongguan.b.92demo.com
dali.b.92demo.com
diqing.b.92demo.com
dehong.b.92demo.com
dongfang.b.92demo.com
danzhou.b.92demo.com
dingan.b.92demo.com
eerduosi.b.92demo.com
ezhou.b.92demo.com
enshi.b.92demo.com
fushun.b.92demo.com
fuxin.b.92demo.com
fuyang.b.92demo.com
fuzhou.b.92demo.com
fuzhouf.b.92demo.com
foshan.b.92demo.com
fangchenggang.b.92demo.com
guoluo.b.92demo.com
gannan.b.92demo.com
guyuan.b.92demo.com
ganzhou.b.92demo.com
guiyang.b.92demo.com
guangan.b.92demo.com
ganzi.b.92demo.com
guangyuan.b.92demo.com
guangzhou.b.92demo.com
guilin.b.92demo.com
guigang.b.92demo.com
haerbin.b.92demo.com
heihe.b.92demo.com
hegang.b.92demo.com
huludao.b.92demo.com
huhehaote.b.92demo.com
hulunbeier.b.92demo.com
hengshui.b.92demo.com
handan.b.92demo.com
hanzhong.b.92demo.com
heze.b.92demo.com
hami.b.92demo.com
hetian.b.92demo.com
haidong.b.92demo.com
huangnan.b.92demo.com
haixi.b.92demo.com
haibei.b.92demo.com
hebi.b.92demo.com
huaian.b.92demo.com
huanggang.b.92demo.com
huangshi.b.92demo.com
hangzhou.b.92demo.com
huzhou.b.92demo.com
hefei.b.92demo.com
huainan.b.92demo.com
huangshan.b.92demo.com
huaibei.b.92demo.com
hengyang.b.92demo.com
huaihua.b.92demo.com
huizhou.b.92demo.com
heyuan.b.92demo.com
honghe.b.92demo.com
hezhou.b.92demo.com
hechi.b.92demo.com
haikou.b.92demo.com
jiamusi.b.92demo.com
jixi.b.92demo.com
jilin.b.92demo.com
jinzhou.b.92demo.com
jinzhong.b.92demo.com
jincheng.b.92demo.com
jinan.b.92demo.com
jining.b.92demo.com
jinchang.b.92demo.com
jiuquan.b.92demo.com
jiayuguan.b.92demo.com
jiaozuo.b.92demo.com
jiyuan.b.92demo.com
jingzhou.b.92demo.com
jingmen.b.92demo.com
jiaxing.b.92demo.com
jinhua.b.92demo.com
jiujiang.b.92demo.com
jian.b.92demo.com
jingdezhen.b.92demo.com
jiangmen.b.92demo.com
jieyang.b.92demo.com
kelamayi.b.92demo.com
kashi.b.92demo.com
kaifeng.b.92demo.com
kunming.b.92demo.com
liaoyuan.b.92demo.com
liaoyang.b.92demo.com
langfang.b.92demo.com
linfen.b.92demo.com
lvliang.b.92demo.com
linyi.b.92demo.com
laiwu.b.92demo.com
liaocheng.b.92demo.com
lasa.b.92demo.com
linzhi.b.92demo.com
lanzhou.b.92demo.com
longnan.b.92demo.com
linxia.b.92demo.com
luoyang.b.92demo.com
luohe.b.92demo.com
lianyungang.b.92demo.com
lishui.b.92demo.com
luan.b.92demo.com
longyan.b.92demo.com
loudi.b.92demo.com
liupanshui.b.92demo.com
luzhou.b.92demo.com
leshan.b.92demo.com
liangshan.b.92demo.com
lincang.b.92demo.com
lijiang.b.92demo.com
liuzhou.b.92demo.com
laibin.b.92demo.com
lingao.b.92demo.com
lingshui.b.92demo.com
ledong.b.92demo.com
mudanjiang.b.92demo.com
maanshan.b.92demo.com
mianyang.b.92demo.com
meishan.b.92demo.com
meizhou.b.92demo.com
maoming.b.92demo.com
naqu.b.92demo.com
nanyang.b.92demo.com
nanjing.b.92demo.com
nantong.b.92demo.com
ningbo.b.92demo.com
ningde.b.92demo.com
nanping.b.92demo.com
nanchang.b.92demo.com
nanchong.b.92demo.com
neijiang.b.92demo.com
nujiang.b.92demo.com
nanning.b.92demo.com
panjin.b.92demo.com
pingliang.b.92demo.com
pingdingshan.b.92demo.com
puyang.b.92demo.com
putian.b.92demo.com
pingxiang.b.92demo.com
panzhihua.b.92demo.com
puer.b.92demo.com
qiqihaer.b.92demo.com
qitaihe.b.92demo.com
qinhuangdao.b.92demo.com
qingdao.b.92demo.com
qingyang.b.92demo.com
qianjiang.b.92demo.com
quzhou.b.92demo.com
quanzhou.b.92demo.com
qiannan.b.92demo.com
qiandongnan.b.92demo.com
qianxinan.b.92demo.com
qingyuan.b.92demo.com
qujing.b.92demo.com
qinzhou.b.92demo.com
qiongzhong.b.92demo.com
qionghai.b.92demo.com
rizhao.b.92demo.com
rikaze.b.92demo.com
shanghai.b.92demo.com
suihua.b.92demo.com
shuangyashan.b.92demo.com
siping.b.92demo.com
songyuan.b.92demo.com
shenyang.b.92demo.com
shijiazhuang.b.92demo.com
shuozhou.b.92demo.com
shangluo.b.92demo.com
shihezi.b.92demo.com
shannan.b.92demo.com
shizuishan.b.92demo.com
shangqiu.b.92demo.com
sanmenxia.b.92demo.com
suzhou.b.92demo.com
suqian.b.92demo.com
shiyan.b.92demo.com
shennongjia.b.92demo.com
suizhou.b.92demo.com
shaoxing.b.92demo.com
suzhous.b.92demo.com
sanming.b.92demo.com
shangrao.b.92demo.com
shaoyang.b.92demo.com
suining.b.92demo.com
shaoguan.b.92demo.com
shantou.b.92demo.com
shenzhen.b.92demo.com
shanwei.b.92demo.com
sanya.b.92demo.com
sansha.b.92demo.com
tianjin.b.92demo.com
tonghua.b.92demo.com
tieling.b.92demo.com
tongliao.b.92demo.com
tangshan.b.92demo.com
taiyuan.b.92demo.com
tongchuan.b.92demo.com
taian.b.92demo.com
tulufan.b.92demo.com
tacheng.b.92demo.com
tumushuke.b.92demo.com
tianshui.b.92demo.com
taizhou.b.92demo.com
tianmen.b.92demo.com
taizhout.b.92demo.com
tongling.b.92demo.com
tongren.b.92demo.com
tunchang.b.92demo.com
wuhai.b.92demo.com
wulanchabu.b.92demo.com
weinan.b.92demo.com
weifang.b.92demo.com
weihai.b.92demo.com
wulumuqi.b.92demo.com
wujiaqu.b.92demo.com
wuwei.b.92demo.com
wuzhong.b.92demo.com
wuxi.b.92demo.com
wuhan.b.92demo.com
wenzhou.b.92demo.com
wuhu.b.92demo.com
wenshan.b.92demo.com
wuzhou.b.92demo.com
wenchang.b.92demo.com
wanning.b.92demo.com
wuzhishan.b.92demo.com
xilinguole.b.92demo.com
xingtai.b.92demo.com
xinzhou.b.92demo.com
xian.b.92demo.com
xianyang.b.92demo.com
xining.b.92demo.com
xinxiang.b.92demo.com
xuchang.b.92demo.com
xinyang.b.92demo.com
xuzhou.b.92demo.com
xiangyang.b.92demo.com
xiaogan.b.92demo.com
xianning.b.92demo.com
xiantao.b.92demo.com
xuancheng.b.92demo.com
xiamen.b.92demo.com
xinyu.b.92demo.com
xiangtan.b.92demo.com
xiangxi.b.92demo.com
xishuangbanna.b.92demo.com
yichun.b.92demo.com
yanbian.b.92demo.com
yingkou.b.92demo.com
yangquan.b.92demo.com
yuncheng.b.92demo.com
yanan.b.92demo.com
yulin.b.92demo.com
yantai.b.92demo.com
yili.b.92demo.com
yushu.b.92demo.com
yinchuan.b.92demo.com
yangzhou.b.92demo.com
yancheng.b.92demo.com
yichang.b.92demo.com
yichuny.b.92demo.com
yingtan.b.92demo.com
yiyang.b.92demo.com
yueyang.b.92demo.com
yongzhou.b.92demo.com
yibin.b.92demo.com
yaan.b.92demo.com
yunfu.b.92demo.com
yangjiang.b.92demo.com
yuxi.b.92demo.com
yuliny.b.92demo.com
zhangjiakou.b.92demo.com
zibo.b.92demo.com
zaozhuang.b.92demo.com
zhangye.b.92demo.com
zhongwei.b.92demo.com
zhengzhou.b.92demo.com
zhoukou.b.92demo.com
zhumadian.b.92demo.com
zhenjiang.b.92demo.com
zhoushan.b.92demo.com
zhangzhou.b.92demo.com
zhuzhou.b.92demo.com
zhangjiajie.b.92demo.com
zunyi.b.92demo.com
zigong.b.92demo.com
ziyang.b.92demo.com
zhuhai.b.92demo.com
zhaoqing.b.92demo.com
zhanjiang.b.92demo.com
zhongshan.b.92demo.com
zhaotong.b.92demo.com
words =["0rganize","organizes", "organizing"]
stemmed_words =[stem(w) for w in words]
print(stemmed_words)
过程如下图:
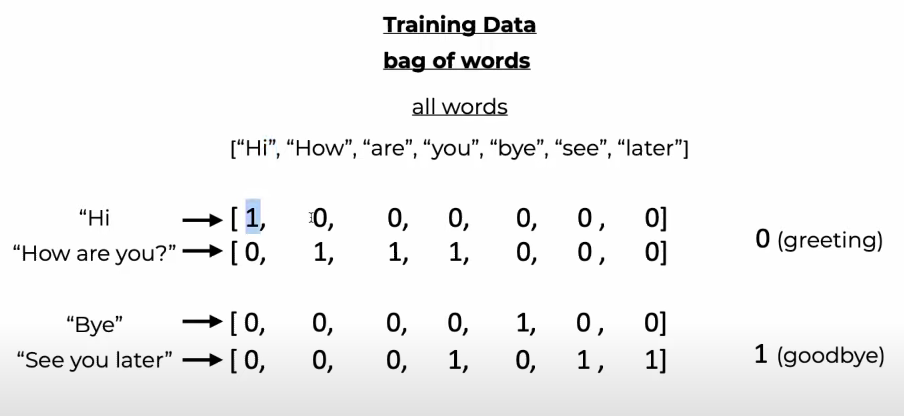
token化就是把单词转换成token。
下面这段代码就是测试token化。
a="How long does shipping take?"
print(a)
a = tokenize(a)
print(a)
token化的逻辑大致如下:

编写测试数据
编写json文件intents.json(英文版)
{
"intents": [
{
"tag": "greeting",
"patterns": [
"Hi",
"Hey",
"How are you",
"Is anyone there?",
"Hello",
"Good day"
],
"responses": [
"Hey :-)",
"Hello, thanks for visiting",
"Hi there, what can I do for you?",
"Hi there, how can I help?"
]
},
{
"tag": "goodbye",
"patterns": ["Bye", "See you later", "Goodbye"],
"responses": [
"See you later, thanks for visiting",
"Have a nice day",
"Bye! Come back again soon."
]
},
{
"tag": "thanks",
"patterns": ["Thanks", "Thank you", "That's helpful", "Thank's a lot!"],
"responses": ["Happy to help!", "Any time!", "My pleasure"]
},
{
"tag": "items",
"patterns": [
"Which items do you have?",
"What kinds of items are there?",
"What do you sell?"
],
"responses": [
"We sell coffee and tea",
"We have coffee and tea"
]
},
{
"tag": "payments",
"patterns": [
"Do you take credit cards?",
"Do you accept Mastercard?",
"Can I pay with Paypal?",
"Are you cash only?"
],
"responses": [
"We accept VISA, Mastercard and Paypal",
"We accept most major credit cards, and Paypal"
]
},
{
"tag": "delivery",
"patterns": [
"How long does delivery take?",
"How long does shipping take?",
"When do I get my delivery?"
],
"responses": [
"Delivery takes 2-4 days",
"Shipping takes 2-4 days"
]
},
{
"tag": "funny",
"patterns": [
"Tell me a joke!",
"Tell me something funny!",
"Do you know a joke?"
],
"responses": [
"Why did the hipster burn his mouth? He drank the coffee before it was cool.",
"What did the buffalo say when his son left for college? Bison."
]
}
]
}
intents_cn.json中文版数据。
{
"intents": [
{
"tag": "greeting",
"patterns": [
"你好",
"嗨",
"您好",
"有谁在吗?",
"你好呀",
"早上好",
"下午好",
"晚上好"
],
"responses": [
"你好!有什么我可以帮忙的吗?",
"您好!感谢您的光临。",
"嗨!有什么我可以为您效劳的吗?",
"早上好!今天怎么样?"
]
},
{
"tag": "goodbye",
"patterns": [
"再见",
"拜拜",
"下次见",
"保重",
"晚安"
],
"responses": [
"再见!希望很快能再次见到你。",
"拜拜!祝你有个愉快的一天。",
"保重!下次见。",
"晚安,祝你做个好梦!"
]
},
{
"tag": "thanks",
"patterns": [
"谢谢",
"感谢",
"多谢",
"非常感谢"
],
"responses": [
"不客气!很高兴能帮到你。",
"没问题!随时为您服务。",
"别客气!希望能帮到您。",
"很高兴能帮忙!"
]
},
{
"tag": "help",
"patterns": [
"你能帮我做什么?",
"你能做什么?",
"你能帮助我吗?",
"我需要帮助",
"能帮我一下吗?"
],
"responses": [
"我可以帮您回答问题、提供信息,或者进行简单的任务。",
"我能帮助您查询信息、安排任务等。",
"您可以问我问题,或者让我做一些简单的事情。",
"请告诉我您需要的帮助!"
]
},
{
"tag": "weather",
"patterns": [
"今天天气怎么样?",
"今天的天气如何?",
"天气预报是什么?",
"外面冷吗?",
"天气好不好?"
],
"responses": [
"今天的天气很好,适合外出!",
"今天天气有点冷,记得穿暖和点。",
"今天天气晴朗,适合去散步。",
"天气晴,温度适宜,非常适合外出。"
]
},
{
"tag": "about",
"patterns": [
"你是什么?",
"你是谁?",
"你是做什么的?",
"你能做些什么?"
],
"responses": [
"我是一个聊天机器人,可以回答您的问题和帮助您解决问题。",
"我是一个智能助手,帮助您完成各种任务。",
"我是一个虚拟助手,可以处理简单的任务和查询。",
"我可以帮助您获取信息,或者做一些简单的任务。"
]
}
]
}
训练数据
训练数据逻辑如下:
import numpy as np
import random
import json
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from nltk_utils import bag_of_words, tokenize, stem
from model import NeuralNet
with open('intents_cn.json', 'r', encoding='utf-8') as f:
intents = json.load(f)
all_words = []
tags = []
xy = []
# loop through each sentence in our intents patterns
for intent in intents['intents']:
tag = intent['tag']
# add to tag list
tags.append(tag)
for pattern in intent['patterns']:
# tokenize each word in the sentence
w = tokenize(pattern)
# add to our words list
all_words.extend(w)
# add to xy pair
xy.append((w, tag))
# stem and lower each word
ignore_words = ['?', '.', '!']
all_words = [stem(w) for w in all_words if w not in ignore_words]
# remove duplicates and sort
all_words = sorted(set(all_words))
tags = sorted(set(tags))
print(len(xy), "patterns")
print(len(tags), "tags:", tags)
print(len(all_words), "unique stemmed words:", all_words)
# create training data
X_train = []
y_train = []
for (pattern_sentence, tag) in xy:
# X: bag of words for each pattern_sentence
bag = bag_of_words(pattern_sentence, all_words)
X_train.append(bag)
# y: PyTorch CrossEntropyLoss needs only class labels, not one-hot
label = tags.index(tag)
y_train.append(label)
X_train = np.array(X_train)
y_train = np.array(y_train)
# Hyper-parameters
num_epochs = 1000
batch_size = 8
learning_rate = 0.001
input_size = len(X_train[0])
hidden_size = 8
output_size = len(tags)
print(input_size, output_size)
class ChatDataset(Dataset):
def __init__(self):
self.n_samples = len(X_train)
self.x_data = X_train
self.y_data = y_train
# support indexing such that dataset[i] can be used to get i-th sample
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
# we can call len(dataset) to return the size
def __len__(self):
return self.n_samples

















 1133
1133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









