




文章汉化系列目录
摘要
当代的视觉图像描述模型常常会“幻想”出图像中实际上并不存在的物体,这主要是由于视觉误分类或过度依赖先验知识,导致视觉信息与目标词汇之间的语义不一致。解决这一问题的最常见方法是鼓励描述模型动态地将生成的物体词或短语与图像的适当区域关联起来,即基于定位的图像描述(Grounded Image Captioning, GIC)。然而,GIC使用的辅助任务(物体定位)并没有解决物体幻觉的关键问题,即语义不一致性。本文从一个新颖的角度来看待这个问题:利用视觉和语言模态之间的语义一致性。具体而言,我们提出了基于共识图表示学习框架(Consensus Graph Representation Learning, CGRL),该框架将共识表示引入到基于定位的图像描述流程中。共识通过对齐视觉图(如场景图)与语言图来学习,考虑图中的节点和边。在对齐的共识帮助下,描述模型可以同时捕捉到正确的语言特征和视觉相关性,从而进一步定位适当的图像区域。我们在Flickr30k Entities数据集上验证了模型的有效性,发现物体幻觉显著减少(-9% CHAIRi)。此外,我们的CGRL也通过多个自动评估指标和人工评估进行了验证,结果表明该方法可以同时提升图像描述性能(+2.9 Cider)和定位精度(+2.3 F1LOC)。
引言
近年来,图像描述模型在许多基准数据集上取得了令人印象深刻甚至超越人类的表现(He et al. 2019;Shuster et al. 2019;Deshpande et al. 2019)。然而,进一步的定量分析表明,这些模型往往会生成幻觉描述(Zhou et al. 2019;Ma et al. 2019),例如虚构的物体词。以往的研究(Rohrbach et al. 2018)认为,这种描述幻觉问题是由数据集中学习到的偏倚或不恰当的视觉-文本关联所导致的,即视觉和语言领域之间的语义不一致。因此,提出了基于定位的图像描述(Grounded Image Captioning, GIC)方法,通过引入一个新的辅助任务来解决这一问题,该任务要求描述模型在生成描述的过程中将物体词与对应的图像区域关联起来。这个辅助定位任务为视觉和文本模态之间提供了额外的标签,可以用来消除偏差并重建这两种模态之间的正确关联。
然而,基于定位的图像描述(GIC)可能并不是解决物体幻觉问题的真正救世主。首先,定位物体词仍然远未解决问题,因为模型仍然可能会幻觉化物体的属性,甚至物体之间的关系。当然,我们可以引入更多的定位任务来缓解这些新问题,但这会带来巨大的成本,并且可能会引发更难以发现的新偏差。其次,单纯通过定位标注来构建正确的关联是难以完全实现的,因为图像和标注的描述并不总是一致的(?)。众所周知,这种不一致在现实生活中是常见的,然而,我们人类具备推理能力,能够在当前不完美的信息与来自不一致环境的已有经验之间总结或推断出共识知识。这种能力使我们在高层次的推理上表现得比机器更好,并且将是现代人工智能最宝贵的能力。因此,提升模型的推理能力比仅仅创造更多标注数据更为重要。
基于这一洞察,我们提出了一种新颖的学习框架,旨在模仿人类推理过程,即共识图表示学习框架(CGRL)。CGRL可以利用来自视觉和文本的结构化知识(例如场景图,SG),并进一步基于共识图推理生成定位描述,以缓解幻觉问题。如图1所示,共识表示通过将视觉图与语言图对齐来推断。利用这种共识,模型可以捕捉到物体之间准确而细致的信息,从而合理地预测一些非视觉功能词(例如,关系动词:“骑”、“玩”、属性形容词:“红色”、“条纹”),而这些词在GIC方法中通常是难以预测的。此外,共识中的图像和标注描述之间的适当关联可以帮助克服视觉-语言领域中的语义不一致问题。正如图1所示,尽管视觉图和语言图存在较大差异,但CGRL利用对齐的共识,保持语义一致性,从而生成准确的描述,捕捉到正确的语言特征和视觉相关性。此外,物体词“女人”、“衬衫”、“笔记本电脑”和“桌子”也能在空间区域中被适当地定位。
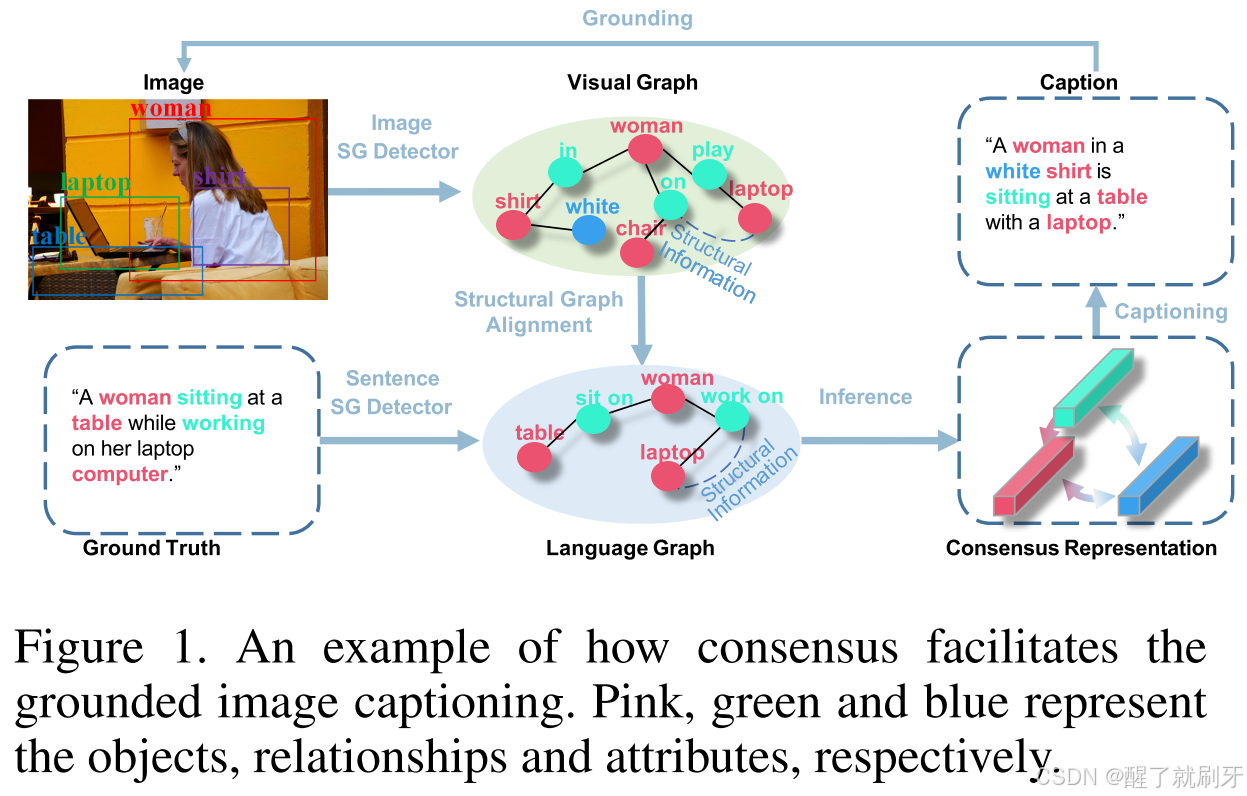
图1. 共识如何促进定位图像描述的示例。粉色、绿色和蓝色分别代表物体、关系和属性。
具体来说,在我们的设置中,CGRL的训练流程包括三个部分:
-
共识推理模块:我们首先在训练阶段根据图像及其真实标签(GT)构建图像场景图(SGV)和语言场景图(SGL)。然后,通过将SGV与SGL对齐来推断共识表示。这是一个具有挑战性的任务:如图1所示,SG中的视觉概念的类别和数量在视觉和语言领域中是多样的;此外,对于一个图,结构信息(例如,物体、属性和关系之间的多样性)也需要对齐。为了推断共识,我们提出了一种生成对抗结构网络(GASN),用于将SGV对齐到SGL。我们首先通过图卷积网络(GCN)在三个统一层次(物体、关系、属性)对SG进行编码,然后通过GASN同时对节点和边进行对齐,以利用跨领域的语义一致性。对齐结果的表示可以看作是共识表示,有助于更好的图像描述生成(GIC)。
-
句子解码器:我们首先利用图像建议框之间的潜在空间关系,并将其链接为增强区域信息,供句子生成器使用。然后,句子解码器学习决定如何利用增强的区域和共识表示,以更合理和准确地描述图像。
-
定位模块:我们构建了一个定位和本地化机制。它不仅鼓励模型基于当前的语义上下文动态地为预测词汇定位区域,还通过生成的物体词来对区域进行本地化。这种设置可以提高物体词生成的准确性。
总的来说,我们论文的主要贡献如下:
- 我们提出了一种新的视角,通过利用共识来保持视觉-语言模态之间的语义一致性,从而减轻了物体幻觉问题(CHAIRi:-9%);
- 我们提出了一种新的共识图表示学习框架(CGRL),将共识表示有机地融入到GIC管道中,以更好地生成定位图像描述;
- 我们提出了一种对抗图对齐方法来推理共识表示,主要解决了图对齐中数据表示和结构信息的问题;
- 我们通过自动评估指标和人工判断,展示了CGRL的优越性,相比于最先进的基线模型,在提升描述质量(Cider:+2.9)和定位准确性(F1LOC:+2.3)方面的表现。
结论
在本文中,我们提出了一种新颖的共识图表示学习(CGRL)框架,用于训练基于定位的图像描述(GIC)模型。我们设计了一种基于共识的方法,通过一种新型的生成对抗结构网络将视觉图与语言图对齐,旨在保持多模态之间的语义一致性。基于共识,我们的模型不仅能够生成更准确的描述,还能定位适当的区域,并极大地缓解幻觉问题。我们希望我们的CGRL能够为现有的视觉描述文献提供补充,并促进视觉与语言领域的进一步研究。

















 1689
1689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









