




文章汉化系列目录
文章目录
摘要
视觉和文本已经在当代的视频-文本基础模型中得到了充分的探索,而视频中的其他模态,如音频和字幕,则未得到足够的关注。本文通过探索一个自动生成的大规模全模态视频描述数据集——VAST-27M,旨在建立视频的多模态轨迹之间的联系,包括视觉、音频、字幕和文本。具体来说,我们首先收集了2700万条开放领域的视频片段,并分别训练了视觉和音频描述模型来生成视觉和音频描述。然后,我们使用现成的大型语言模型(LLM)将生成的描述、字幕和指令提示结合起来,整合成全模态描述。基于提出的VAST-27M数据集,我们训练了一个全模态的视频-文本基础模型,命名为VAST,该模型能够感知和处理视频中的视觉、音频和字幕模态,并更好地支持各种任务,包括视觉-文本、音频-文本和多模态视频-文本任务(检索、描述和问答)。我们进行了大量实验,以验证所提VAST-27M语料库和VAST基础模型的有效性。VAST在多个跨模态基准测试中取得了22项新的最先进结果。代码、模型和数据集将发布在 https://github.com/TXH-mercury/VAST。
引言
每天都有大量的视频被录制并上传到社交媒体平台,这使得视频内容理解成为人工智能领域的一个关键研究方向。同时,文本是我们日常生活中最直接、最有效的信息传播方式。因此,视频-文本跨模态学习对于人工智能系统与人类的互动至关重要,它帮助系统理解视频内容(视频描述)、搜索所需的视频(文本到视频检索)或回答关于视频的问题(视频问答)。随着无监督预训练技术[1; 2]和大规模视频-文本语料库[3; 4]的出现,视频-文本预训练模型在上述任务中取得了快速进展,并且在相关任务上取得了相对令人印象深刻的表现。
然而,我们认为,当前的预训练模型远非完美,因为它们大多仅限于建立视频中文本和视觉内容之间的联系,而没有整合其他模态信息,如音频和字幕。具体而言,环境音频可以提供与视觉信息重叠的额外上下文,以减少歧义并提高模型的预测置信度,或者补充视觉信息,提供更多的多模态线索。人类的语音或转录(字幕)也包含关于对话、新闻或操作程序的宝贵信息,这些信息可以与视觉信息共同建模,从而增强视频的全面理解。考虑到音频和字幕在视频理解中的重要性,将它们集成到一个更先进的全模态基础模型中是必要的,如图1所示。

图1:传统跨模态预训练与提出的全模态预训练的区别示意图。得益于提出的全模态视频描述语料库VAST-27M,VAST基础模型可以从多个信息源感知视频,包括视觉、音频和字幕,并通过大规模预训练增强全模态视频(OMV)与全模态描述(OMC)之间的联系。A、V、S和T分别代表音频、视觉、字幕和文本。AC、VC和AVC分别是音频、视觉和视听描述的缩写。
主要的挑战在于缺乏适当的训练语料库。为了训练这样的基础模型,我们需要一个全模态视频描述语料库,其中描述同时与视觉、音频和字幕相对应。不幸的是,如表2所示,目前的视听文本语料库要么使用原始字幕作为描述[4; 5; 6],要么仅包含视觉描述(替代文本)[3],或者包含视听描述但规模有限[7]。另一方面,由于对描述的高需求,手动标注一个全模态语料库并不可行,因为这涉及巨大的成本。为了解决这个问题,我们提出了一种两阶段自动化流程,用于从大规模开放领域视频语料库(HD_VILA_100M [5])生成全模态描述。具体来说,如图2所示,在第一阶段,我们在公开可用的视觉和音频描述语料库上训练了分别的视觉和音频描述模型,然后利用这些模型生成高质量的单模态客观描述。在第二阶段,我们使用现成的大型语言模型(LLM)Vicuna-13b [8]作为零-shot全模态描述生成器。我们将生成的单模态描述、字幕和指令性提示输入LLM,鼓励LLM将不同模态的信息融合并总结为一个长句,形成一个全模态描述。通过这一过程,我们创建了VAST-27M数据集,其中包含2700万条视频片段,每个视频都配有11个描述(包括5个视觉描述、5个音频描述和1个全模态描述)。由于其全面的描述类型,VAST-27M可以为包括视觉-文本、音频-文本和全模态预训练在内的多个研究领域做出贡献。大量实验表明,VAST-27M在多个方面显著超越了当前的视听文本、音频文本和视听文本语料库。
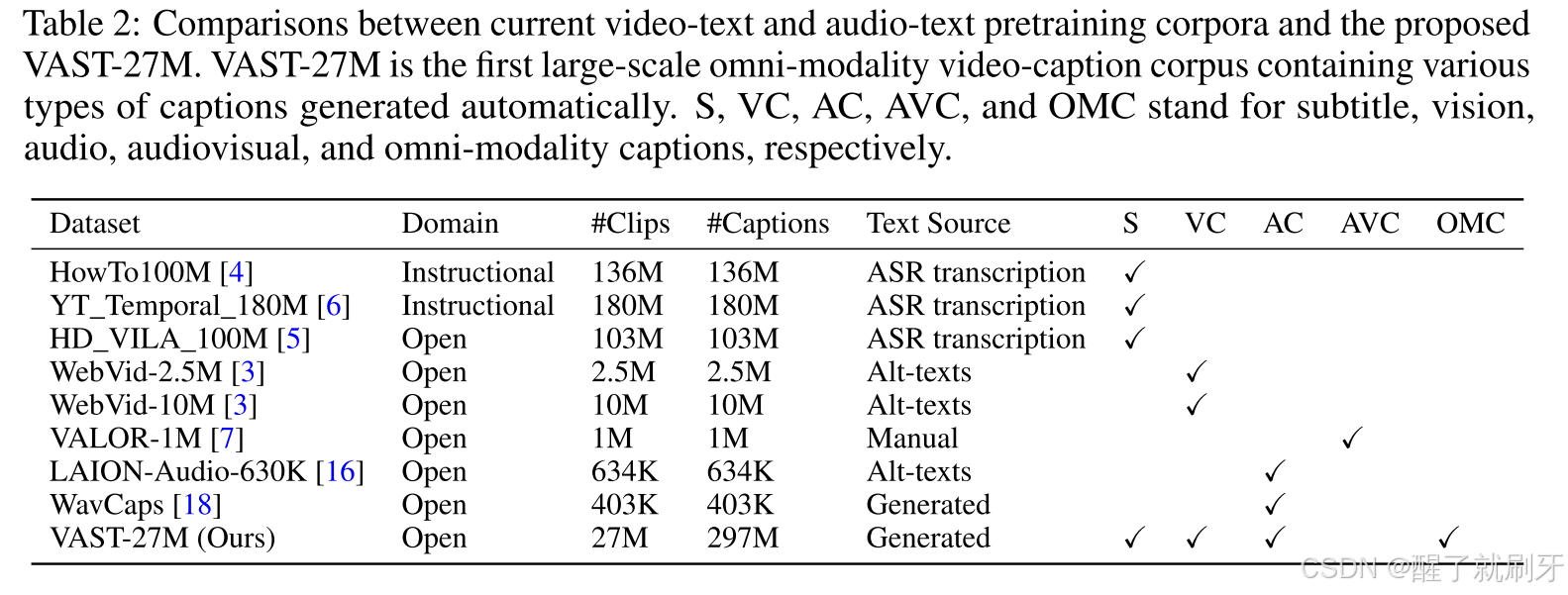
表2:当前视频-文本和音频-文本预训练语料库与提出的VAST-27M的比较。VAST-27M是首个大规模全模态视频描述语料库,包含各种类型的自动生成描述。S、VC、AC、AVC和OMC分别代表字幕、视觉、音频、视听和全模态描述。
基于VAST-27M,我们训练了一个视觉-音频-字幕-文本全模态基础模型,命名为VAST。如图2所示,VAST由三个单模态编码器组成,而文本编码器则通过交叉注意力层实现跨模态融合。VAST的训练目标包括OM-VCC、OM-VCM和OM-VCG(在第4.2节中详细介绍),旨在增强全模态理解和生成能力。如表1所示,与现有的跨模态预训练模型相比,VAST是在全模态视频描述语料库上进行训练的,能够感知和处理所有四种模态,并支持广泛的下游任务,涵盖各种模态(视觉-文本、音频-文本和多模态视频-文本),以及多种类型(检索、描述和问答)。
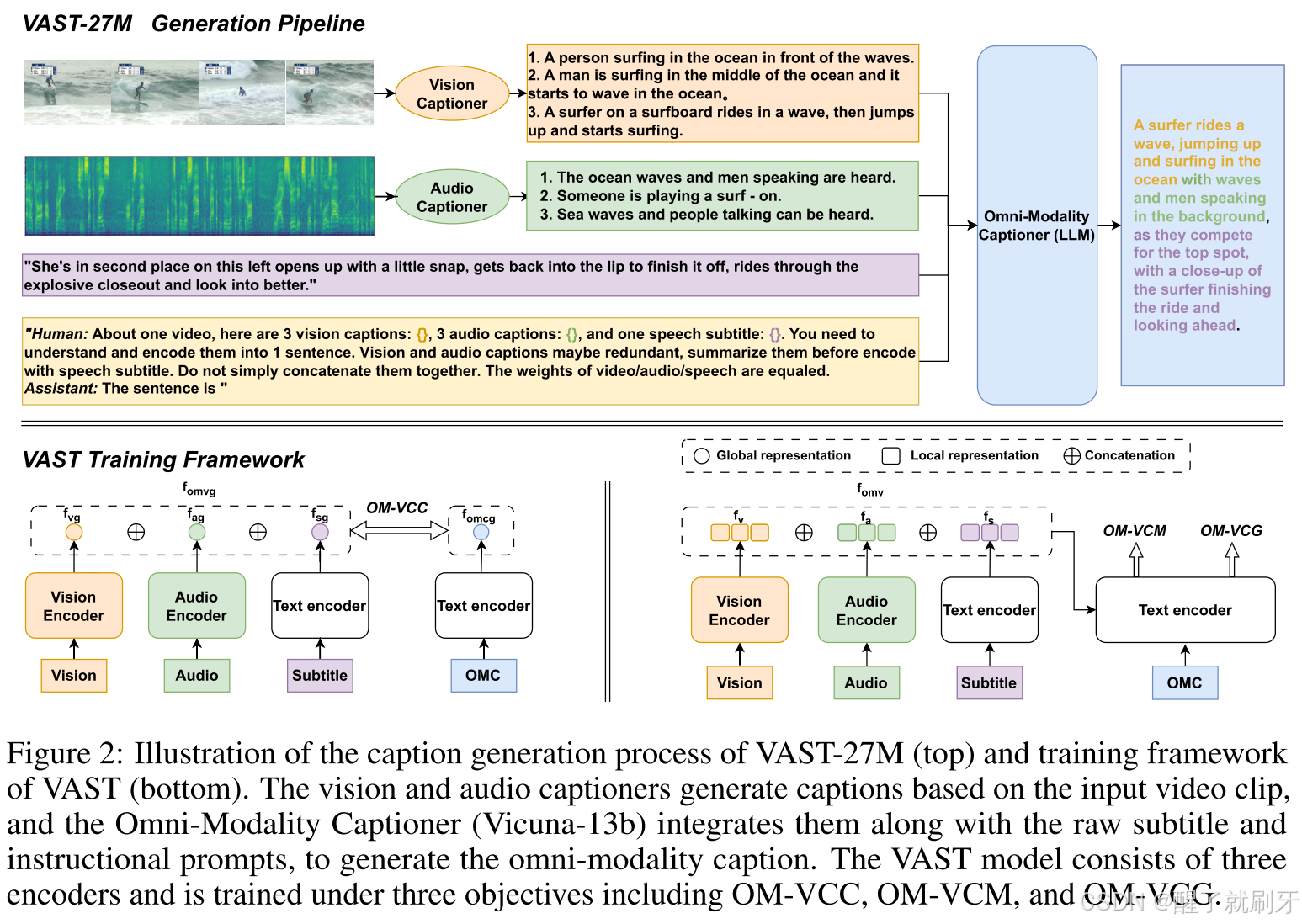
图2:VAST-27M的描述生成过程(上)和VAST的训练框架(下)。视觉和音频描述生成器根据输入的视频片段生成描述,全模态描述生成器(Vicuna-13b)将这些描述与原始字幕和指令提示结合,生成全模态描述。VAST模型由三个编码器组成,并在三个目标(OM-VCC、OM-VCM和OM-VCG)下进行训练。
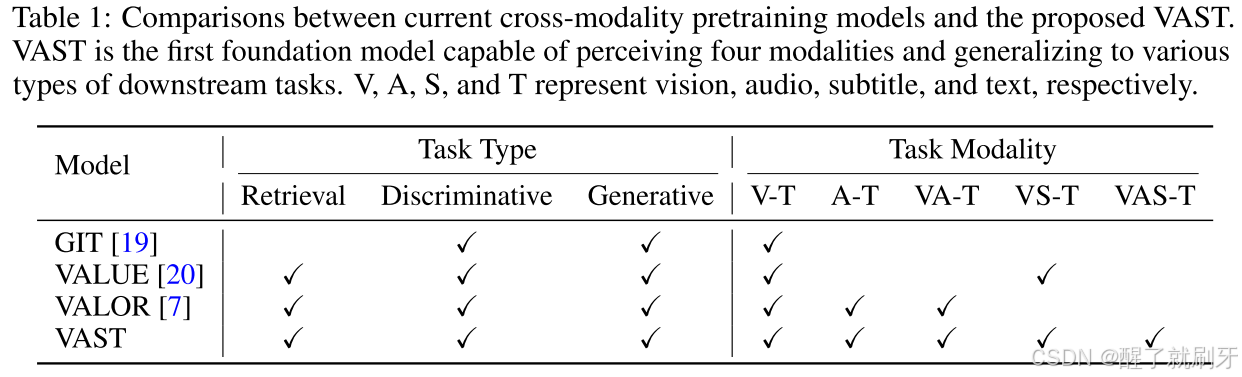
表1:当前跨模态预训练模型与提出的VAST的比较。VAST是首个能够感知四种模态并能推广到各种下游任务的基础模型。V、A、S和T分别代表视觉、音频、字幕和文本。
我们的贡献总结如下:
(i) 我们提出了VAST-27M,这是首个大规模全模态视频描述数据集,通过训练的单模态描述生成器和大型语言模型自动生成;
(ii) 我们训练了首个视觉-音频-字幕-文本基础模型VAST,该模型实现了全模态感知和理解;
(iii) 大量实验验证了VAST的有效性,并且在各种跨模态基准测试中超越了最先进的技术。
2. 相关工作
2.1 跨模态预训练语料库
视频-文本预训练语料库:在早期阶段,大多数视频-文本模型是基于大规模的HowTo100M数据集[4]进行训练的。该数据集包含来自122万部教学YouTube视频的1.36亿个视频片段,并使用自动生成的字幕(来自自动语音识别工具的转录)作为相应片段的描述。后来,Zellers等人提出了YT-Temporal-180M语料库[6],该语料库包含来自600万个YouTube视频的1.8亿个视频片段,遵循了类似的收集方案,用于收集叙事视频和字幕语料库。为了克服仅限于教学领域的局限,Xue等人构建了开放域、高分辨率的HD_VILA_100M语料库[5],该语料库包含来自330万个YouTube视频的1亿个视频片段。然而,尽管标注字幕比注释描述成本更低,但字幕通常与视觉内容的直接相关性较弱,导致模型学习中的视频-文本关联较弱。受到Conceptual Captions数据集(CC)[9; 10]的收集方案启发,Bain等人编制了WebVid2.5M和WebVid10M数据集[3],采用替代文本作为视频描述,超越了使用字幕作为描述的上述数据集。然而,尽管替代文本与视频内容的相关性比字幕更强,但它们与标准描述风格不同,且仍然包含噪声。此外,替代文本通常仅描述视觉内容,未包含其他模态。进一步超越视觉,Chen等人创建了VALOR-1M数据集[7],该数据集包含来自AudioSet[11]的100万个视频片段,并配有注释的视听描述。然而,这些描述中未反映字幕内容,且由于人工标注的高成本,该数据集的规模有限,扩展也较为困难。与上述训练语料库相比,我们的VAST-27M是第一个高质量、大规模的全模态视频描述数据集,其描述涵盖了视频的所有模态,包括视觉、音频和字幕。此外,由于采用自动化生成流程,其扩展性更具成本效益。
音频-文本预训练语料库:与视觉-文本预训练相比,由于训练语料库在数量和规模上的限制,音频-文本预训练的进展相对较慢。人类标注的数据集,如Clotho[12]、AudioCaps[13]、MCAS[14]和AudioCaption[15],都包含少于5万个音频片段,远远不能满足大规模预训练的需求。Wu等人通过抓取多个来源的音频及其相应的替代文本,编制了LAION-Audio-630K数据集[16],其中大多数音频来源于Freesound[17]。Mei等人介绍了WavCaps[18],该数据集包含来自多个来源的403,000个音频及其描述。他们使用ChatGPT对原始描述进行筛选和重写,将其转化为类似描述的句子。然而,描述的质量受原始描述质量的影响很大。与此不同,我们通过训练的高质量描述模型生成音频描述,VAST-27M的数据集规模几乎是LAION-Audio-630K或WavCaps的两个数量级。
2.2 多模态学习
早期已经有一些方法探索了用于视频-文本理解的多模态轨迹。例如,MMT [21]利用七个专家来增强文本到视频的检索,而SMPFF [22]则引入了音频用于视频描述。在视频-文本预训练的背景下,也有一些工作联合建模了字幕或音频与视觉和文本。引入字幕的著名例子包括UniVL [23]、CoMVT [24]和VALUE [20]。然而,这些模型中建立的字幕-文本关联是隐式且较弱的,通过掩蔽预测[23]或下一个话语预测[24]实现,使用原始字幕作为预测目标,而不是抽象文本。这种方法在预训练和微调阶段之间引入了不一致性。相比之下,VAST充分利用大型语言模型的泛化能力,从字幕中提取最重要的信息并转化为语言描述。
另一方面,音频引入的著名例子包括AVLNet [25]、MERLOT Reserve [26]、i-Code [27]和VALOR [7]。然而,AVLNet、MERLOT Reserve和i-Code侧重于学习音频-字幕关系,而非音频-文本关系,限制了它们在文本到音频检索和音频描述等任务中的泛化能力。虽然VALOR联合建模了音频、视觉和文本,但它主要针对感知环境声音,对人类语音的关注较少。与上述方法相比,VAST是首个能够感知四种模态的全模态基础模型,能够将视觉、音频和字幕连接到描述中。
3 数据集
3.1 VAST-27M的数据收集
视觉描述生成器训练:为了建立物体和视觉概念之间的通用对应关系,我们借鉴了BLIP [28]的灵感,首先在大规模的图像-文本语料库上训练了一个视觉描述模型,这些语料库包括CC4M、CC12M,以及从LAION-400M [29]中随机选取的1亿对图像-文本数据。随后,我们在手动标注的图像和视频描述数据集的组合上对模型进行了微调,包括MSCOCO [30]、VATEX [31]、MSRVTT [32]和MSVD [33]。通过这一过程,我们得到了一个高质量的描述生成模型,能够感知静态物体和动态动作,从而生成流畅且准确的描述。
音频描述生成器训练:对于音频描述任务,我们使用大规模的音频-文本语料库(即VALOR-1M和WavCaps数据集)训练了一个专门的音频描述生成模型。与视觉描述生成器不同,由于下游音频描述数据集的规模有限,我们没有进行第二阶段的微调,因为这可能导致模型在狭窄的音频概念范围内过拟合。此外,VALOR-1M是一个人工标注的语料库,可以确保生成的描述在一定程度上的准确性。
片段选择:由于下载、存储和计算的时间和成本因素,我们从HD_VILA_100M数据集中选择了2700万个视频片段,而没有使用全部数据。选择规则如下:
- 长度小于5秒或大于30秒的片段被剔除。
- 缺失视觉、音频或字幕模态的片段被剔除。
- 从HD_VILA_100M中的原始330万个长视频中均匀选择片段。
描述生成:对于VAST-27M中的每个视频片段,我们使用训练好的视觉和音频描述生成器每个生成5个描述,采用Top-K采样方法,K=10。随后,我们利用现成的Vicuna-13b [8]模型作为全模态描述生成器。Vicuna-13b是一个基于Transformer架构的开源自回归大型语言模型(LLM),通过对LLaMA [34]进行微调,并在ShareGPT收集的用户共享对话数据上进行训练。对于每个视频片段,我们随机选择3个视觉描述和3个音频描述,并将它们与原始字幕和设计的指令性提示一起输入到LLM中。如图2所示,LLM生成的全模态描述有效地描述了视觉、音频和字幕内容,同时遵循自然的人类描述风格。更多VAST-27M数据集的示例可以在附录中找到。
3.2 VAST-27M的统计数据
VAST-27M包含来自大规模HD_VILA_100M数据集的2700万个视频片段。该数据集涵盖了15个以上的类别,包括音乐、游戏、教育、娱乐、动物等,而不仅限于像HowTo100M那样的教学领域。与其他常用的跨模态训练语料库相比,如表2所示,VAST-27M包含更多的描述(无论是模态还是数量)。VAST-27M中视觉描述、音频描述和全模态描述的平均长度分别为12.5、7.2和32.4。
4 方法
4.1 基本框架
如图2所示,VAST采用了一个完全端到端的Transformer架构,包含一个视觉编码器(ViT [35])、一个音频编码器(BEATs [36])和一个文本编码器(BERT [2])。该框架能够处理多模态输入,如图像、视频、音频、字幕和描述。文本编码器负责编码单模态的描述或字幕,并通过交叉注意力层执行多模态的编码/解码。全模态描述和字幕使用WordPiece分词器 [37] 进行标记化,然后输入文本编码器以分别获得输出特征 f omc f_{\text{omc}} fomc 和 f s f_s fs。
视觉编码器以原始图像或稀疏采样的视频帧作为输入,产生输出特征 f v f_v fv。对于音频片段,它们首先被划分为多个10秒长的片段,用零进行填充,使用25ms的Hamming窗转换为64维的对数Mel滤波器组谱图,然后输入音频编码器以获得输出特征 f a f_a fa。这些特征的全局表示([CLS] token 特征)分别表示为 f omcg f_{\text{omcg}} fomcg、 f s g f_{sg} fsg、 f v g f_{vg} fvg 和 f a g f_{ag} fag。
4.2 预训练目标
基于传统的视觉-文本预训练目标,VAST采用以下三个预训练目标:
-
全模态视频-描述对比损失(OM-VCC):视频片段的全模态全局表示,记作 f omvg f_{\text{omvg}}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4003
4003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









