




文章汉化系列目录
文章目录
摘要
自然场景的图像-文本检索一直是一个热门的研究主题。由于图像和文本是异质的跨模态数据,其中一个关键挑战是如何学习综合且统一的表示来表达多模态数据。一幅自然场景图像主要涉及两种视觉概念,即对象及其关系,这两者对图像-文本检索同样重要。因此,一个好的表示应该同时考虑这两者。在许多计算机视觉(CV)和自然语言处理(NLP)任务中,场景图在描述复杂自然场景方面取得了最近的成功,因此我们提出用两种场景图来表示图像和文本:视觉场景图(VSG)和文本场景图(TSG),每种场景图都被用于共同表征相应模态中的对象和关系。图像-文本检索任务因此被自然地形式化为跨模态场景图匹配。具体而言,我们在模型中为VSG和TSG设计了两个特定的场景图编码器,这些编码器通过聚合邻域信息来优化图中每个节点的表示。因此,可以获得对象级别和关系级别的跨模态特征,这使我们能够以更合理的方式评估图像和文本在这两个层面的相似性。我们在Flickr30k和MS COCO上取得了最先进的结果,验证了我们基于图匹配的方法在图像-文本检索中的优势。
1. 引言
视觉媒体和自然语言是我们日常生活中最常见的两种不同模态的信息。为了实现计算机上的人工智能,使计算机能够理解、匹配和转换这种跨模态数据是至关重要的。因此,图像-文本跨模态检索成为一个具有挑战性的研究课题。在这种检索中,给定一种模态的查询(图像或文本句子),其目标是从数据库中检索出另一种模态中最相似的样本。这里的关键挑战在于如何通过理解内容和测量语义相似性来匹配跨模态数据,尤其是在跨模态数据中存在多个对象的情况下。
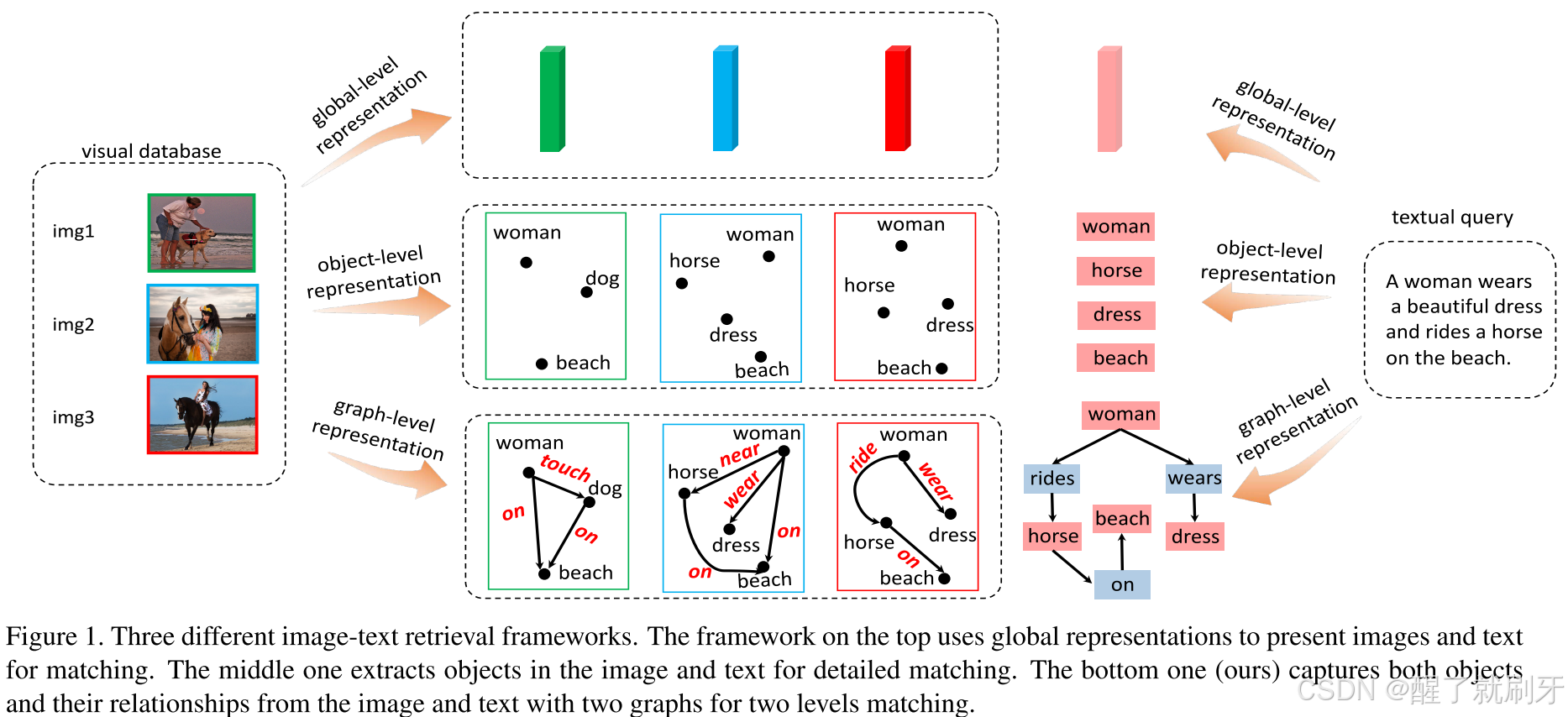
图1. 三种不同的图像-文本检索框架。顶部的框架使用全局表示来呈现图像和文本以进行匹配。中间的框架提取图像和文本中的对象以进行详细匹配。底部的框架(我们的方法)通过两个图来捕捉图像和文本中的对象及其关系,以实现两个层面的匹配。
为了解决这一任务,提出了许多方法。如图1顶部所示,早期的方法[14, 3, 27, 28, 38]使用全局表示来表达整个图像和句子,但忽略了局部细节。这些方法在只包含单一对象的简单跨模态检索场景中表现良好,但在涉及复杂自然场景的更现实案例中却不够令人满意。近期的研究[12, 11, 7, 8, 17]关注于通过检测图像和文本中的对象进行局部详细匹配,并在先前的工作基础上取得了一定的改进,如图1中间所示。
自然场景不仅包含多个对象,还包含它们之间的关系[10],这些关系对图像-文本检索同样重要。例如,图1左侧的三张图像包含相似的对象。图1中的“狗”可以将该图像与其他两张区分开,而图2和图3则包含相同的对象,包括“女人”、“马”、“海滩”和“裙子”。为了区分这两张图像,关系起着至关重要的作用。显然,图2中的“女人”是“站在”马旁边,而图3中的“女人”则是“骑在”马上的。同样,在句子经过句法分析后,文本对象之间也存在语义关系,例如图1中的文本查询中的“女人-穿裙子”、“女人-骑在马上”。
随着近期研究主题逐渐聚焦于图像场景中的对象和关系,场景图[10]被提出以形式化地建模对象和关系,并迅速成为高层语义理解任务中一种强大的工具[18, 35, 9, 29, 34]。场景图由多个节点和边组成,每个节点代表一个对象,每条边表示连接的两个节点之间的关系。为了在图像-文本检索任务中全面表示图像和文本,我们将对象和关系组织成两种模态的场景图,如图1底部所示。我们引入视觉场景图(VSG)和文本场景图(TSG)分别表示图像和文本,将传统的图像-文本检索问题转换为两个场景图的匹配。
具体而言,我们从图像和文本中提取对象和关系以形成VSG和TSG,并设计了一种称为场景图匹配(SGM)模型,其中两个定制的图编码器将VSG和TSG编码为视觉特征图和文本特征图。VSG编码器是一个多模态图卷积网络(MGCN),通过聚合来自其他节点的有用信息来增强VSG中每个节点的表示,并以不同的方式更新对象和关系特征。TSG编码器包含两个不同的双向GRU,分别用于编码对象和关系特征。之后,在每个图中学习对象级别和关系级别的特征,最终可以以更合理的方式在两个层面上匹配对应于两种模态的两个特征图。
为了评估我们方法的有效性,我们在两个具有挑战性的数据集Flickr30k[36]和MS COCO[19]上进行了图像-文本检索实验。结果表明,我们的方法显著超越了最先进的方法,并验证了关系在图像-文本检索中的重要性。
2. 相关工作
图像-文本检索任务近年来已成为一个热门的研究主题。为了解决这一任务,提出了几项优秀的工作[14, 3, 24, 27, 12, 11, 7, 8, 17, 15, 38, 5],这些工作可以分为两大类:i) 基于全局表示的方法和 ii) 基于局部表示的方法。
基于全局表示的方法[3, 27, 28, 38, 4, 14]通常由图像编码器(例如CNN)和句子编码器(例如RNN)组成,分别提取图像和句子的全局特征。然后,设计一种度量来衡量不同模态下的一对特征的相似性。Frome等人[4]提出了一种深度视觉语义嵌入模型,使用CNN从整个图像中提取视觉表示,并使用SkipGram[20]获取语义标签的表示。类似地,Kiros等人[14]使用LSTM对完整句子进行编码,并使用三元组损失使匹配的图像-句子对在嵌入空间中比未匹配对更接近。Wehrmann等人[31]设计了一种高效的字符级Inception模块,通过对句子中的原始字符进行卷积来编码文本特征。Faghri等人[3]通过将困难负样本挖掘引入三元组损失,显著提高了检索性能。
更详细地说,近年来发展了关注图像和句子之间局部对齐的基于局部表示的方法[12, 11, 7, 8, 17]。Karpathy等人[12]从图像中提取对象,并将这些视觉对象与句子中的单词进行匹配。为了改进这种方法,Lee等人[17]通过注意网络关注更重要的片段(单词或区域)。Huang等人[8]提出语义概念及其顺序对于图像-文本匹配至关重要。为了解决多义实例的嵌入问题,Song和Soleymani[25]从每个图像中提取K个嵌入,而不是注入嵌入。
然而,上述某些方法忽视了多模态数据中对象之间的关系,而这也是图像-文本检索的关键点。尽管其中一些方法[11, 7, 8, 17]使用RNN嵌入上下文中的单词,但仍然没有明确揭示文本对象之间的语义关系。在我们的方法中,通过场景图明确捕捉了视觉和文本对象及其关系。因此,跨模态数据可以在两个层面上匹配,这更为合理。
场景图最初由[10]提出用于图像检索,它通过图形描述图像中的对象、属性和关系。随着场景图生成的最新突破[37, 18, 33, 30],许多高层视觉语义任务相继发展,如视觉问答(VQA)[26]、图像描述[34, 35, 18]和指称表达的定位[29]。这些方法大多受益于使用场景图来表示图像。另一方面,已经提出几种方法[1, 30, 22]将句子解析为场景图,并应用于一些跨模态任务[34]。近年来,也有尝试使用图结构来表示视觉和文本数据,如[26]利用图来表示图像和文本问题用于VQA。与我们的方法不同,他们的图没有语义关系,因此不被称为场景图。
3. 方法
给定一种模态的查询(句子查询或图像查询),图像-文本跨模态检索任务的目标是从数据库中找到另一种模态中最相似的样本。因此,我们的场景图匹配(SGM)模型旨在通过将输入的图像和文本句子解构为场景图来评估图像-文本对的相似性。SGM的框架如图2所示,由两个分支网络组成。在视觉分支中,输入图像被表示为视觉场景图(VSG),然后编码为视觉特征图(VFG)。与此同时,句子被解析为文本场景图(TSG),然后在文本分支中编码为文本特征图(TFG)。最后,模型从VFG和TFG中收集对象特征和关系特征,并分别在对象级别和关系级别计算相似性得分。SGM子模块的架构将在以下小节中详细说明。
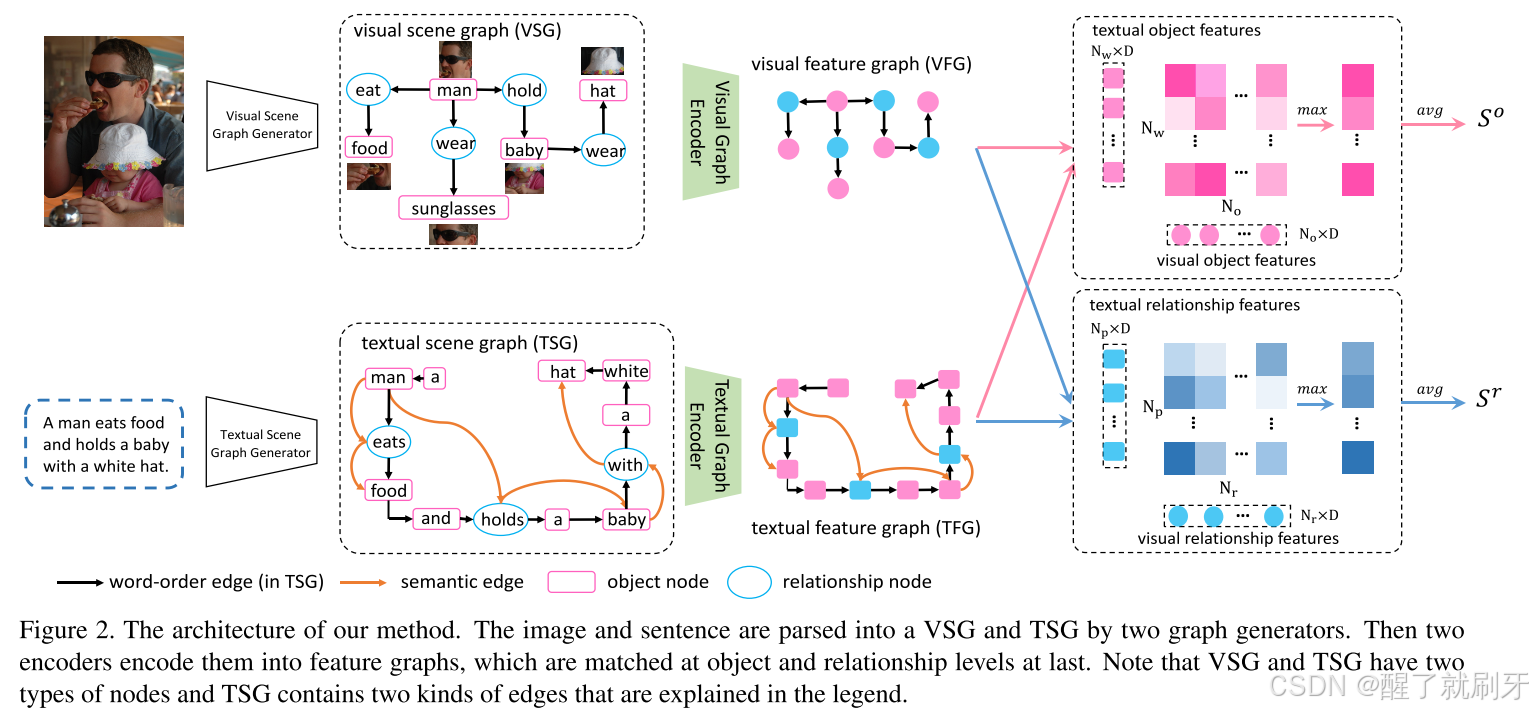
图2. 我们方法的架构。图像和句子通过两个图生成器分别解析为视觉场景图(VSG)和文本场景图(TSG)。随后,两个编码器将它们编码为特征图,最后在对象级别和关系级别进行匹配。请注意,VSG和TSG包含两种类型的节点,且TSG包含图例中解释的两种边。
3.1.视觉特征嵌入
3.1.1视觉场景图生成
给定一张原始图像,视觉场景图是通过现成的场景图生成方法生成的,例如MSDN [18]和Neural Motifs [37]。我们将视觉场景图表示为 G = { V , E } G = \{V, E\} G={ V,E},其中 V V V是节点集, E E E是边集。我们的视觉场景图中有两种类型的节点,如图2所示。粉色矩形表示对象节点,每个对象节点对应于图像的一个区域。浅蓝色的椭圆表示关系节点,每个关系节点通过有向边连接两个对象节点。此外,每个节点都有一个类别标签,例如“man”、“hold”。具体来说,假设在一个VSG中有 N o N_o No个对象节点和 N r N_r Nr个关系节点。对象节点集可以表示为 O = { o i ∣ i = 1 , 2 , … , N o } O = \{o_i | i = 1, 2, \ldots, N_o\} O={ oi∣i=1,2,…,No}。关系节点集为 R = { r i j } ⊆ O × O R = \{r_{ij}\} \subseteq O \times O R={ rij}⊆O×O,其中 ∣ R ∣ = N r |R| = N_r ∣R∣=Nr,且 r i j r_{ij} rij是 o i o_i oi和 o j o_j oj之间的关系。节点 o i o_i oi和关系 r i j r_{ij} rij的标签可以用独热向量表示,分别为 l o i l_{o_i} loi和 l r i j l_{r_{ij}} lrij。
3.1.2 视觉场景图编码器
在生成视觉场景图后,我们设计了一种多模态图卷积网络(MGCN)来学习VSG上的良好表示,该网络包括一个预训练的视觉特征提取器、一个标签嵌入层、一个多模态融合层和一个图卷积网络,如图3所示。

图3. VSG编码器的框架。每个节点对应的图像区域通过视觉特征提取器嵌入为一个特征向量。然后,每个节点的视觉特征与单词标签通过多模态融合层进行融合。最后,通过GCN对图进行编码,输出视觉特征图。
视觉特征提取器。预训练的视觉特征提取器用于将图像区域编码为特征向量,可以是预训练的CNN网络或目标检测器(例如Faster-RCNN [21])。VSG中的每个节点将通过提取器编码为 d 1 d_1 d1维视觉特征向量。对于对象节点 o i o_i oi,其视觉特征向量 v o i v_{o_i} voi是从其对应的图像区域提取的。对于关系节点 r i j r_{ij} rij,其视觉特征向量 v r i j v_{r_{ij}} vrij是从 o i o_i oi和 o j o_j oj的联合图像区域提取的。
标签嵌入层。每个节点都有一个由视觉场景图生成器预测的单词标签,这可以提供辅助的语义信息。标签嵌入层被构建用于将每个节点的单词标签嵌入为特征向量。给定独热向量 l o i l_{o_i} loi和 l r i j l_{r_{ij}} lrij,嵌入的标签特征 e o i e_{o_i} eoi和 e r i j e_{r_{ij}} erij的计算如下:
e o i = W o l o i e_{o_i} = W_o l_{o_i} eoi=Woloi
e r i j = W r l r i j e_{r_{ij}} = W_r l_{r_{ij}} erij=Wrlrij
其中 W o ∈ R d 2 × C o W_o \in \mathbb{R}^{d_2 \times C_o} Wo∈R
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3401
3401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









