





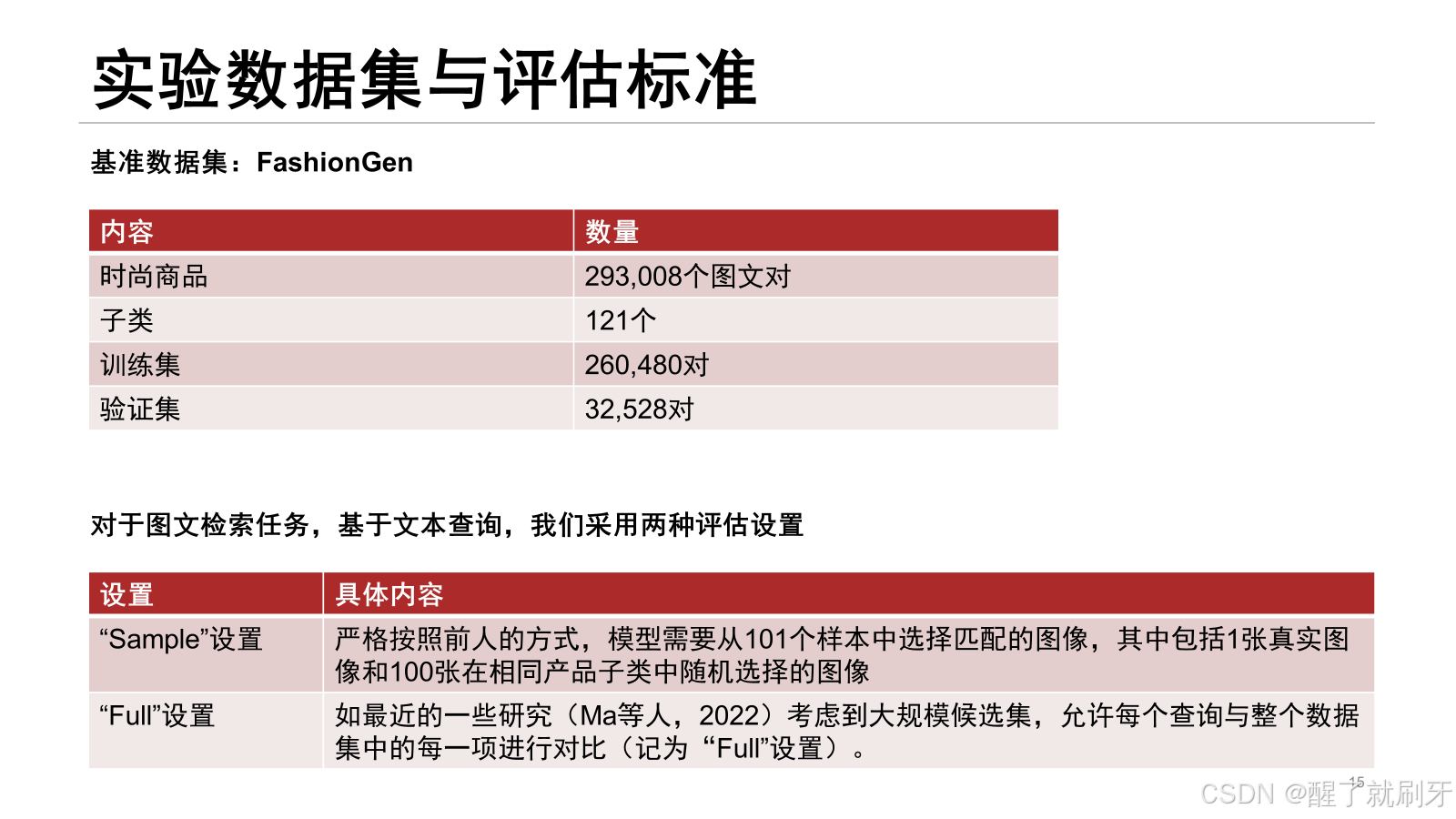
首先是电子商务领域图文检索独特挑战:电子商务产品的图像-文本对具有不同于通用领域的独特特性。主要为下面表格中的两部分。
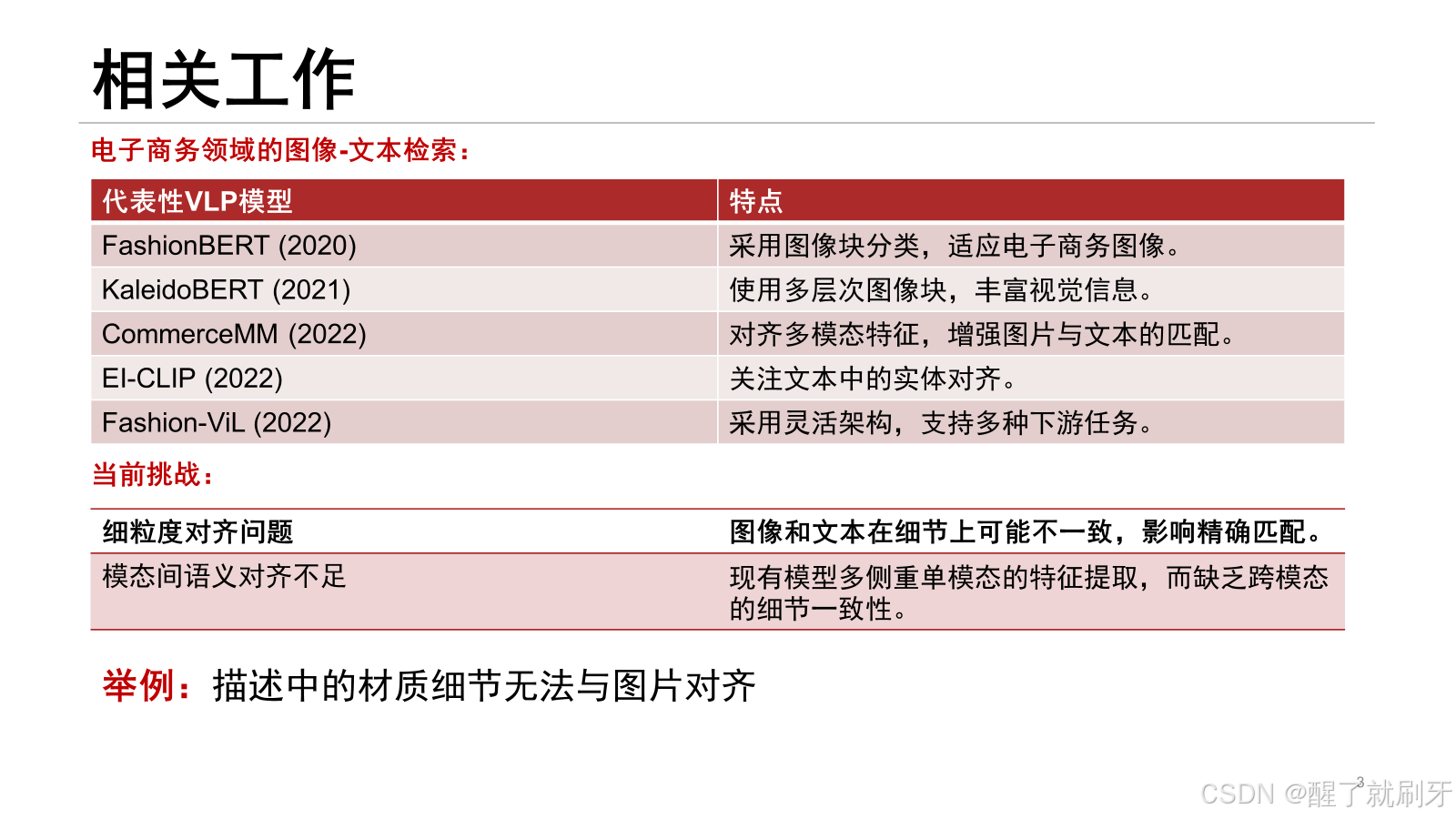
之前的电商领域的图像-文本检索,都存在两个问题,一个是细粒度对齐问题,就是图像和文本在细节上可能不一致,影响精确匹配。
还有就是模态间语义对齐不足,现有模型多侧重单模态的特征提取,而缺乏跨模态的细节一致性。

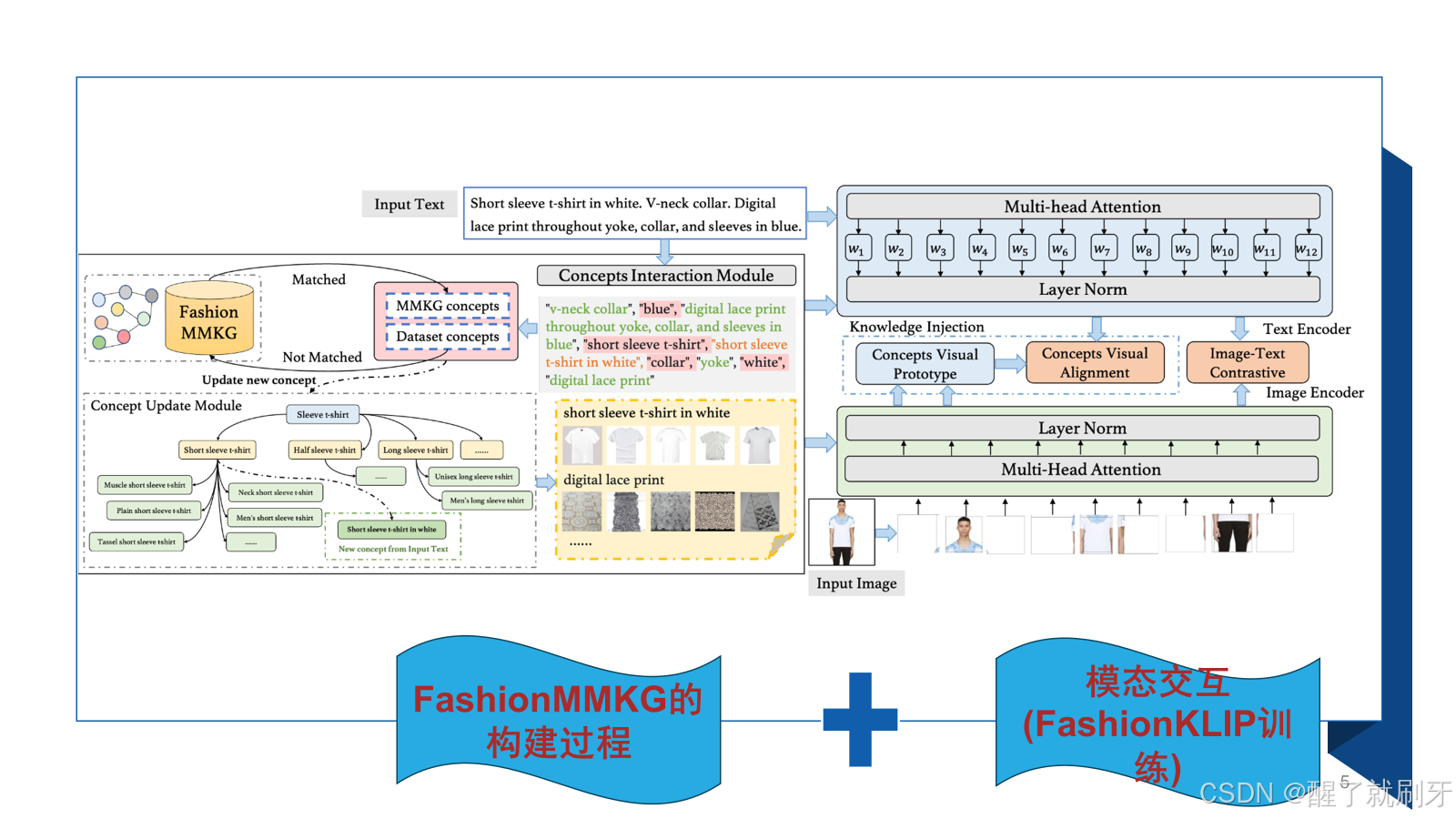
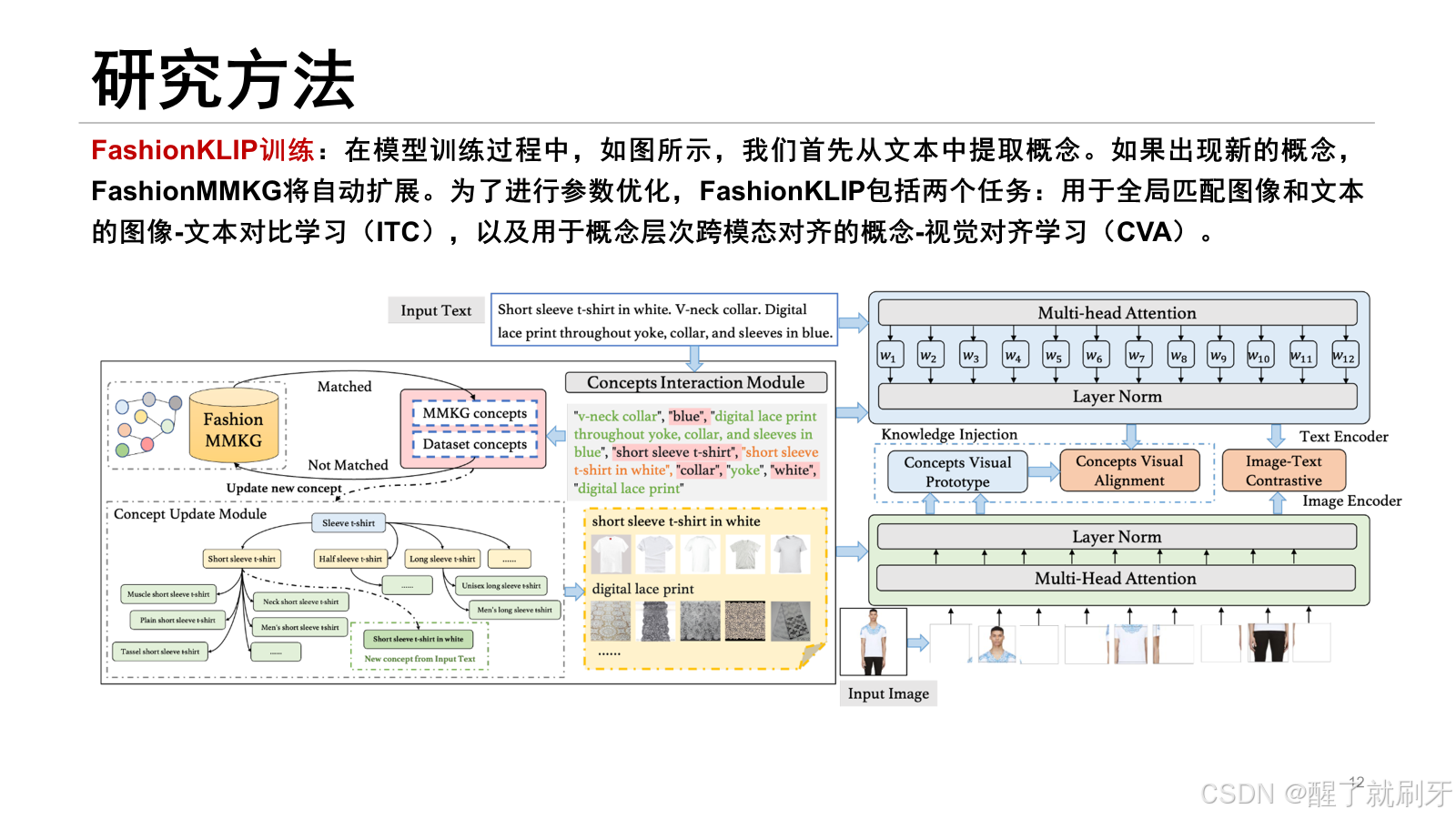
论文框架分为两部分,左边是FashionMMKG的构建,右边是模态交互,也就是FshionKLIP的训练。


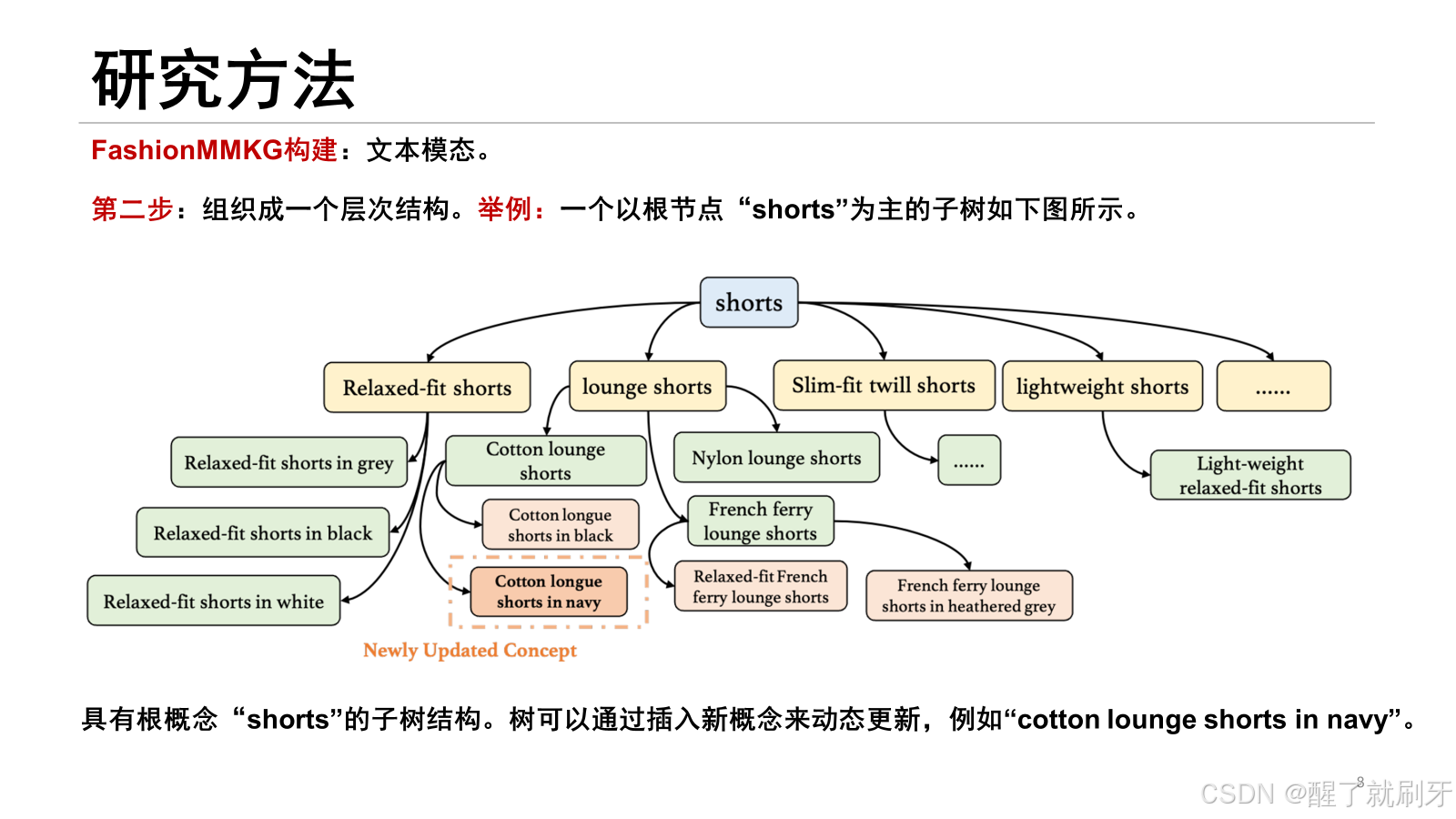


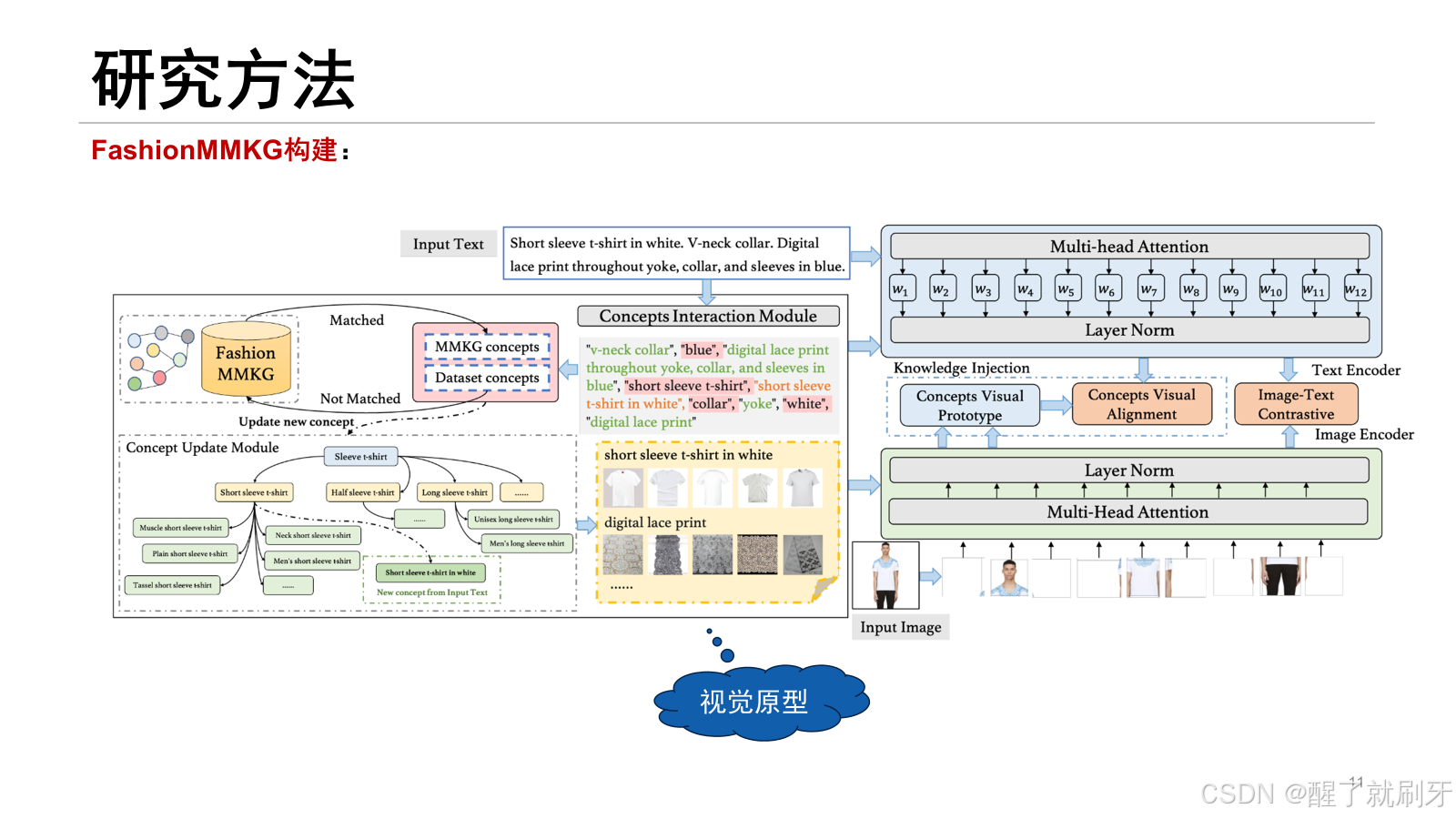
对于输入的文本,首先进行概念提取,然后进行知识图谱的构建,多模态知识图谱中存在的概念就不用进行处理,没有存在的概念就需要更新。然后针对这些概念有每个概念的视觉原型。


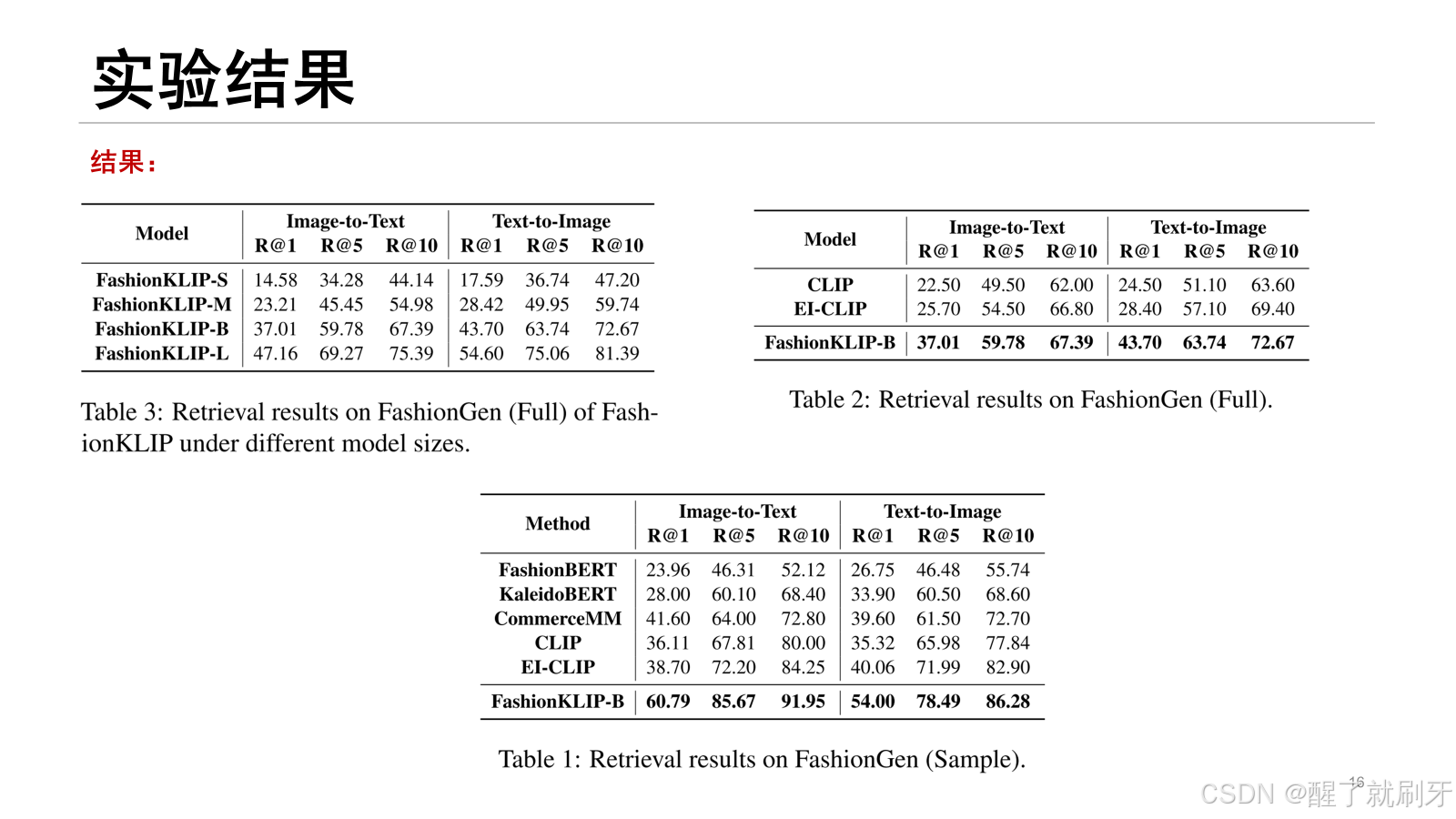
在FashionGen数据集上基于完整评估标准报告了不同版本FashionKLIP模型的结果,见表3。
对FashionKLIP-B模型进行了“full”和“sample”评估,与现有的SOTA模型进行了对比。
表1中的主要实验结果所示,FashionKLIP模型在各项指标上均显著超越了现有SOTA模型,特别是在R@1指标上,FashionKLIP-B甚至大幅超越了使用多模态融合编码器实现更统一表示学习的方法,如CommerceMM(Yu等人,2022)。
在表2的完整评估结果中,FashionKLIP-B相比EI-CLIP(Ma等人,2022)有显著的11-15%的提升。
对于较小的模型版本(如FashionKLIP-M),检索性能也具有竞争力,并且接近CLIP。
由于“full”设置更贴近真实的检索场景,且更具挑战性,因为它需要从大量候选集中进行选择,FashionKLIP在该设置中的表现尤为突出,进一步证明了该框架的广泛应用潜力。基于各项实验结果,可以得出结论:融入时尚知识的效果显著,并且更注重跨模态概念层次的交互,能够提升电商图文匹配的效果。
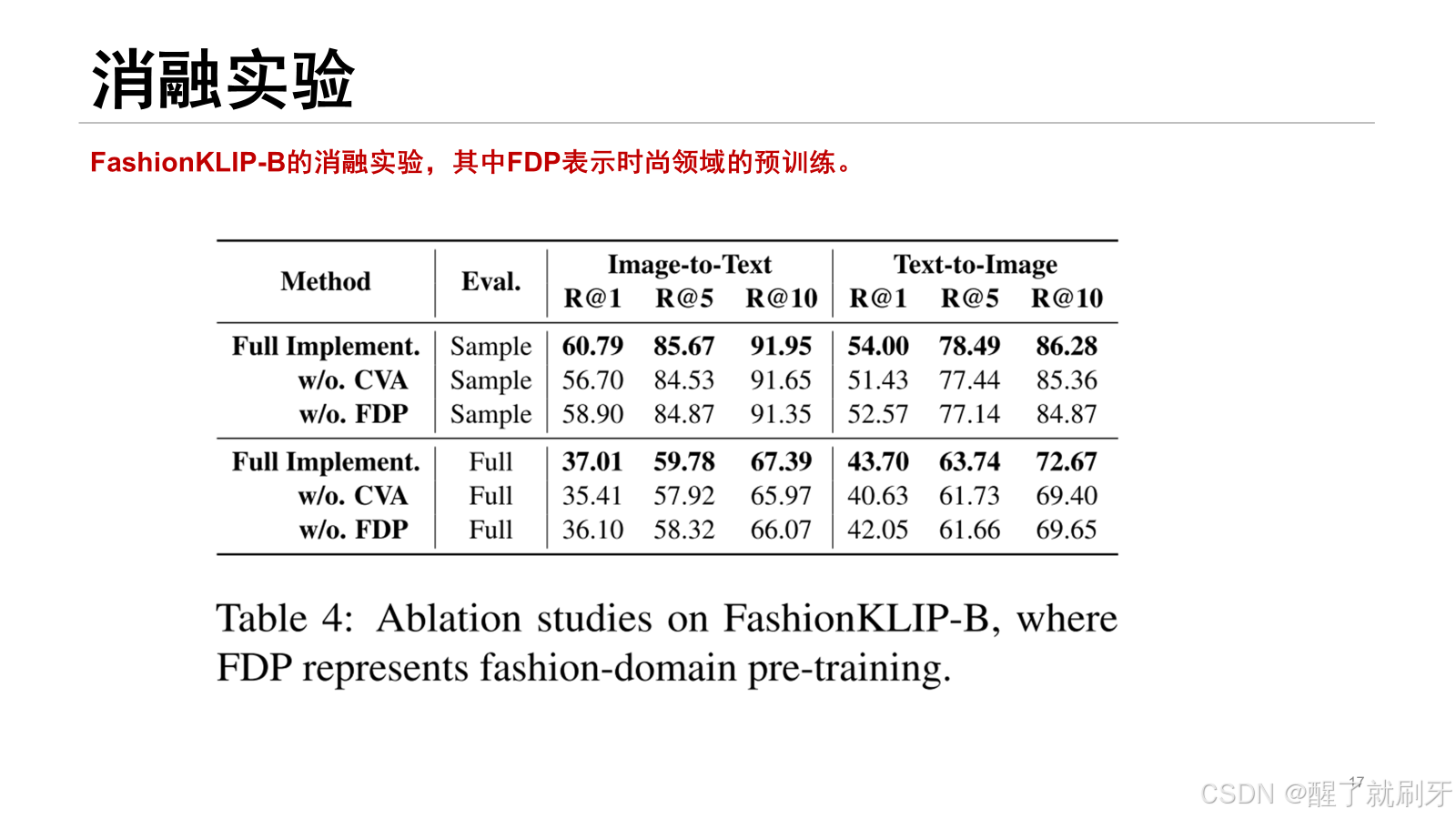
CVA和FDP均对性能提升有贡献。尽管不使用FDP时检索结果略有下降,但移除CVA对检索性能的影响更为显著。此外,FDP和CVA的同时引入显著提升了模型性能,如“Full Implement.”所示,证明利用时尚数据进行预训练的必要性,这有助于建立概念与图像之间的更佳映射作为先验知识。更重要的是,聚焦于时尚知识更好地引导了概念层次的交互,从而提升了图像与文本的对齐表现。

















 1362
1362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









