




文章汉化系列目录
文章目录
摘要
图像-文本检索是多模态领域的核心任务,吸引了研究界和工业界的广泛关注。最近,视觉-语言预训练(VLP)模型的迅速发展大大提升了跨模态检索的性能。然而,不同模态间对象的细粒度交互还远未完善。在电子商务领域,这一问题更加严重,因为该领域缺乏足够的训练数据和细粒度的跨模态知识。为了解决这一问题,本文提出了一种新的增强知识的电子商务VLP模型——FashionKLIP。我们首先从大规模的电子商务图像-文本数据中自动建立多模态概念知识图谱,然后将这些先验知识注入VLP模型,以在概念层次上实现跨模态对齐。在公共基准数据集上进行的实验表明,FashionKLIP在电子商务图像-文本检索方面大幅度提升了先进VLP模型的性能。该方法在实际工业场景中的应用也证明了FashionKLIP的可行性和高效性。所有的代码和模型检查点都已在EasyNLP框架中公开发布(Wang等人,2022年)的报告。网址:https://github.com/alibaba/EasyNLP。
1 引言
互联网多模态内容的爆炸式增长推动了各类跨模态任务的研究。图像-文本检索是一项流行的跨模态任务,旨在为给定的图像(或文本)找到关联的文本(或图像)(Karpathy 和 Fei-Fei, 2015; Faghri 等, 2017),在广泛的工业应用中具有较高的实际价值。最近,视觉-语言预训练(VLP)模型的蓬勃发展(Yao 等, 2021; Zeng 等, 2021; Li 等, 2020c)显著提升了不同模态数据的表示学习,带来了显著的性能提升。
然而,在电子商务领域,图像-文本检索任务有其独特的挑战。我们认为,电子商务产品的图像-文本对具有不同于通用领域的独特特性(如 MS-COCO (Lin 等, 2014)、Flickr30k (Young 等, 2014) 和 Conceptual Captions (Sharma 等, 2018)),具体示例如图1所示。1)虽然通用领域中的文本多为包含完整句子结构的描述,但电子商务中的描述或查询通常由多个短语组成,描述产品的细节如材质或款式。2)通用领域的图像通常包含丰富的背景,而产品图像主要以中央的大商品图为主,背景元素较少。这些特有的领域特性使得通用领域模型难以直接应用于电子商务中的图像-文本检索任务。

图1:电子商务中的图像-文本对示例。
近年来,一些面向特定领域的VLP模型相继被提出,如基于电子商务图像-文本对的FashionBERT (Gao 等, 2020)、KaleidoBERT (Zhuge 等, 2021)、CommerceMM (Yu 等, 2022)、EI-CLIP (Ma 等, 2022)和Fashion-ViL (Han 等, 2022),这些模型显著提升了电子商务图像-文本检索的性能。尽管取得了成功,细粒度的跨模态对齐问题仍未解决,这可能导致图像和文本之间的细节匹配不准确。尽管一些电子商务VLP模型使用来自图像视角的细粒度信息(Han 等, 2022)或基于图像块的分类(Gao 等, 2020;Yu 等, 2022),但它们缺乏模态间的语义级对齐。其他一些研究(Ma 等, 2022;Zhu 等, 2021)关注文本模态中的实体,但很少考虑跨模态交互。在通用领域中,可以通过对象检测(Li 等, 2020c;Tan 和 Bansal, 2019)、场景图解析(Cui 等, 2021)或语义分析(Yu 等, 2021;Li 等, 2020b)实现细粒度的交互。然而,这些工具在电子商务领域中失去其有效性。
为提升电子商务中图像与文本的细粒度对齐,本文提出了一种增强电子商务知识的VLP模型——FashionKLIP。特别地,我们首先提出了一种数据驱动策略,从大规模电子商务图像-文本语料库中构建多模态概念知识图谱(称为FashionMMKG),其中时尚概念被自动提取并以语义层级的形式组织,每个概念都与其代表性图像相关联。在训练CLIP风格的模型时,FashionMMKG作为先验跨模态时尚知识被整合,以支持电子商务的图像-文本检索。在模型训练中,我们通过对比学习跨模态学习图像-文本对的表示对齐,并进一步在概念层级上优化对齐。概念对齐通过将文本表示与FashionMMKG中时尚概念的视觉原型表示进行匹配来实现。
我们的贡献可以总结如下:
- 我们创新性地提出了一种数据驱动的方法,用于构建电商领域的多模态概念知识图谱,名为FashionMMKG,实现了全自动化,无需人工干预。
- 我们构建了一个电商知识增强的视觉语言预训练(VLP)模型,称为FashionKLIP,该模型基于FashionMMKG中的先验知识,进行概念层面的对齐学习。
- 我们在知名的时尚基准数据集FashionGen(Rostamzadeh等人,2018年)上进行了实验,结果显示FashionKLIP在电商领域优于当前最先进的VLP模型。
- 我们还将该方法应用于实际工业场景,观察到在图像/文本到产品检索任务中取得了显著的提升。
2 相关工作
视觉语言预训练(VLP)
VLP模型可以分为两类:单流模型和双流模型。单流模型(Chen等人,2020;Li等人,2020a;Gan等人,2020)首先将多模态输入进行拼接,以便进行交互;而双流模型(Jia等人,2021;Radford等人,2021;Yao等人,2021;Li等人,2020b)则分别获取图像和文本的表示,随后学习它们的对齐关系。尽管单流模型因图像和文本的早期融合而可能导致较高的检索精度,但推理效率在一定程度上受到影响。最近,为了更专注于图像和文本的细粒度语义交互,一些研究通过计算图像块和文本标记之间的相似性来改进相似性策略(Yao等人,2021),或通过物体检测器利用细粒度的图像信息(Li等人,2020c,b;Gan等人,2020;Zeng等人,2021)。另一些研究则引入结构化场景图以获取语义知识(Yu等人,2021)。尽管这些方法在通用领域取得了成功,但难以适用于电商数据。
基于时尚的检索
FashionBERT(Gao等人,2020)首次将掩码策略等预训练任务应用于电商图像和文本。KaleidoBERT(Zhuge等人,2021)通过提取一系列多粒度图像块进行增强,以引导掩码策略实现细粒度匹配。CommerceMM(Yu等人,2022)提出了预训练任务,以对齐单模态和多模态特征,从而实现更一致的对齐效果。EI-CLIP(Ma等人,2022)从语言学角度定义了面向实体的检索任务,通过引入因果模型将不同元数据连接为电商实体。最近,Fashion-ViL(Han等人,2022)设计了一种灵活的架构,以适应各种下游任务。然而,现有方法仍然面临细粒度语义对齐不足的问题,这可能削弱模型在语义层面的跨模态理解能力。
3 方法论
本节介绍了FashionMMKG的构建过程,以及FashionKLIP如何整合FashionMMKG中的跨模态时尚知识,以实现概念层面的交互。
3.1 FashionMMKG构建
文本模态。 我们并未构建基于本体的知识图谱 (Deng et al., 2022),而是通过自动化方式构建了FashionMMKG,以缩小与真实用户查询之间的差距。构建流程包括首先通过大规模时尚文本挖掘确定概念集,然后将每个概念与对应的图像进行匹配。给定一个包含 N N N 个图文对的时尚数据集 D { T , I } D\{T, I\} D{
T,I},我们首先提取所有文本 T T T。我们使用 NLP 工具 spacy2 进行句子成分分析和词性标注。通过将形容词修饰词与关键词组合,我们获取了多粒度的概念短语。对于输入文本 “Heathered cotton lounge shorts in navy. Elasticized waistband with drawstring closure”,我们提取出根概念如 “navy”,“waistband”,“closure” 和 “heathered”,以及更详细的短语:“cotton lounge shorts”,“cotton lounge shorts in navy”,“heathered cotton lounge shorts in navy” 等。基于提取结果的不同概念层次粒度,我们通过判断两个概念是否互相包含,构建概念之间的上位词-下位词(“is-a”)关系,并以关系三元组的形式呈现,例如 < < <“cotton lounge shorts in navy”, is-a, “cotton lounge shorts” > > >。
在所有关系三元组提取完成后,我们将这些时尚概念组织成一个层次结构。一个以根节点“shorts”为主的子树如图3所示。该层次结构的构建过程可以进一步实现为动态过程。当出现以前未见过的概念时,可以将这些新概念添加到现有的层次树中,如图2中新增的概念“short sleeve t-shirt in white”。
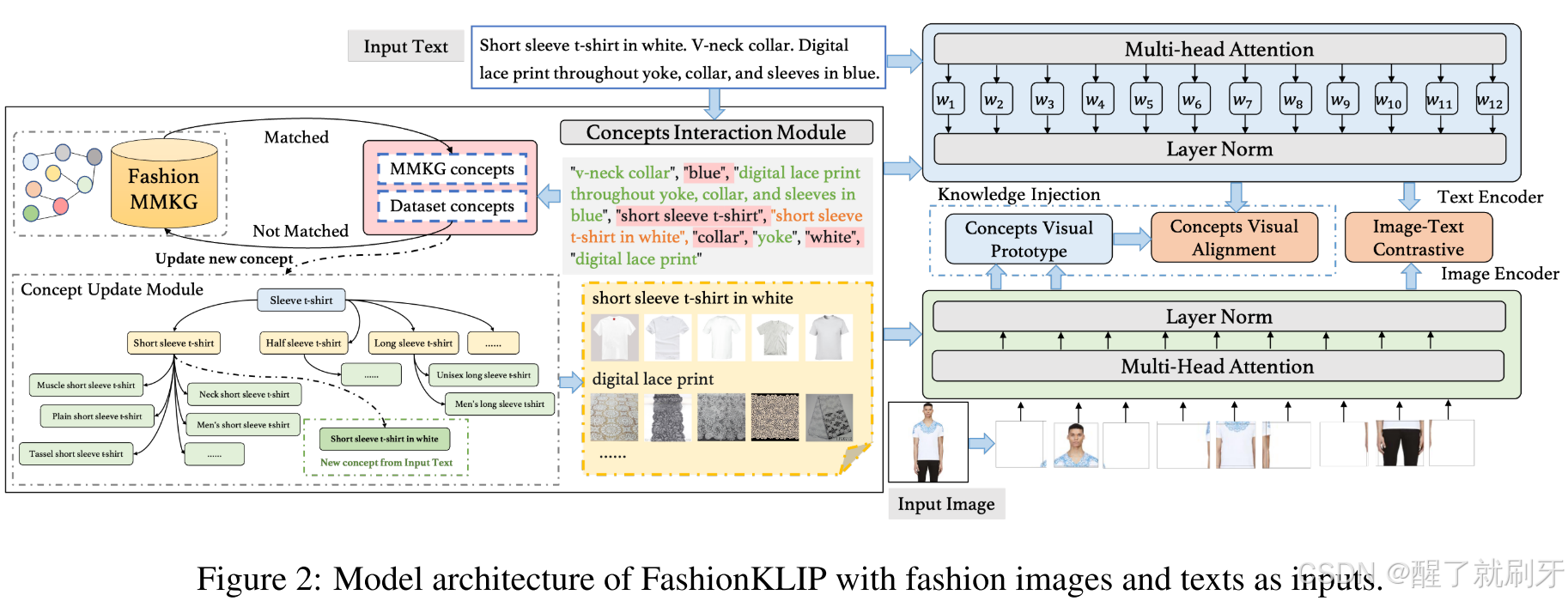
图2说明: FashionKLIP的模型架构,输入为时尚图像和文本。
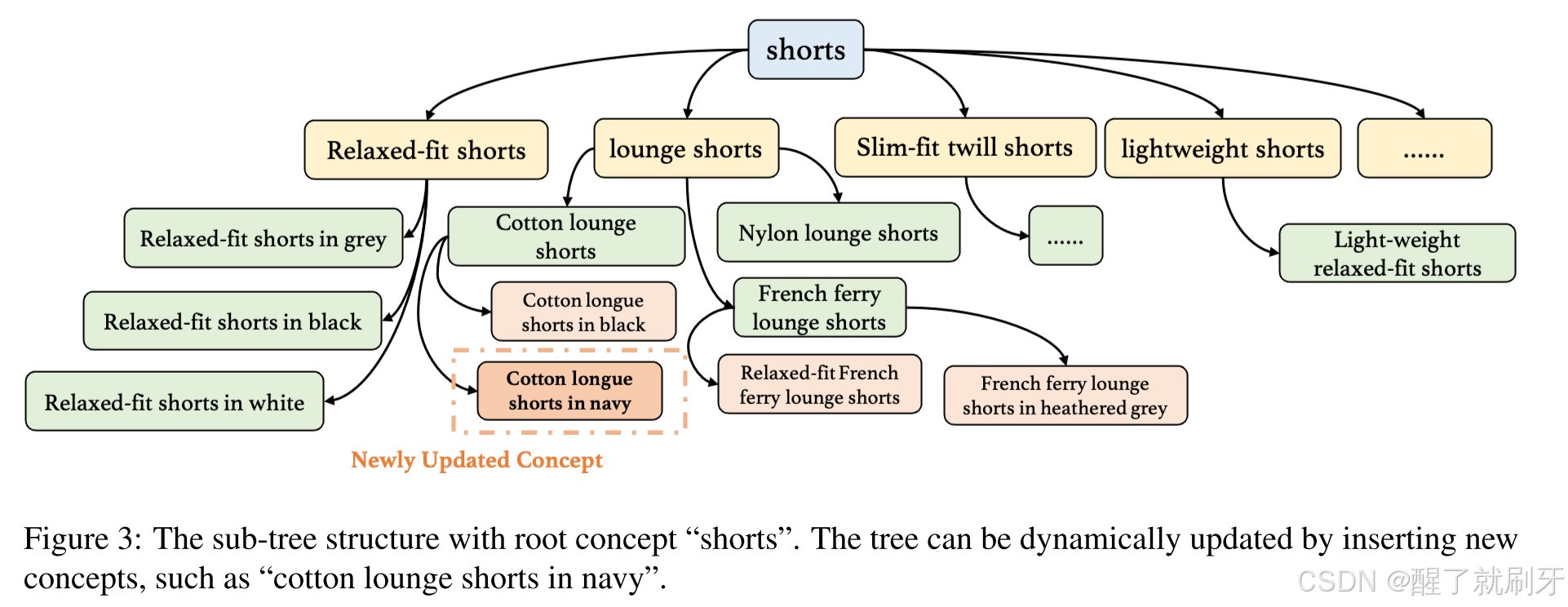
图3说明: 以“shorts”为根概念的子树结构。该树可以通过插入新概念(如“cotton lounge shorts in navy”)进行动态更新。
视觉模态。 对于视觉模态,我们为每个概念采用基于提示的图像检索方法,并在后续的视觉-语言训练过程中迭代更新该过程。利用预训练的CLIP风格模型的泛化能力,我们从图像集 I I I 中检索产品图像,查询格式为 “A photo of {concept}”(参考Radford等人,2021;Yao等人,2021;Gu等人,2022)。基于图像和文本特征的余弦距离,一种简单的方法是选择前 k k k 个相似度最高的图像,作为该概念的视觉原型。
一些概念的检索结果如图4所示。我们可以看到,粗粒度概念的前 k k k 张图像通常在视觉上更具多样性,而更具体的概念对应的图像则在语义上趋于一致。为确保每个概念的视觉表示既具有相似性又具备多样性,我们略微扩大了图像候选集的范围(使用更大的 k k k),并使用MMR算法(Carbonell 和 Goldstein,1998)来提升所选图像的多样性。该算法通过迭代过程运行,直到从 k k k 个候选中选出足够数量的图像。设 C C C 为候选图像集, S S S 为已选择用于概念 c c c 的图像集合。每次选择图像 v i v_i vi 的公式为:
MMR ( v i ) = arg max v i ∈ C ∖ S [ λ Sim ( c , v i ) − ( 1 − λ ) max v j ∈ S Sim ( v i , v j ) ] \text{MMR}(v_i) = \argmax_{v_i \in C \setminus S} [\lambda \text{Sim}(c, v_i) - (1 - \lambda) \max_{v_j \in S} \text{Sim}(v_i, v_j)] MMR(vi)=vi∈C∖Sargmax[λSim(c,vi)−(1−λ)vj∈SmaxSim(vi,vj)]
其中 Sim ( ⋅ , ⋅ ) \text{Sim}(\cdot, \cdot) Sim(⋅,⋅) 表示对应文本/图像特征之间的余弦相似度, λ \lambda λ 是调节结果相关性和多样性的系数。在此我们默认设置 λ = 0.8 \lambda = 0.8 λ=0.8。

图4说明: FashionMMKG中的粗粒度和细粒度概念及其匹配的图像。
3.2 FashionKLIP训练
在模型训练过程中,如图2所示,我们首先从文本中提取概念。如果出现新的概念,FashionMMKG将自动扩展。为了进行参数优化,FashionKLIP包括两个任务:用于全局匹配图像和文本的图像-文本对比学习(ITC),以及用于概念层次跨模态对齐的概念-视觉对齐学习(CVA)。
ITC 我们训练一个CLIP风格的模型来学习图文对的全局表示。对于每个训练批次中的 b b b 个图文对,设 L k I L^I_k LkI 和 L k T L^T_k LkT
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 464
464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









