







文章中文化系列目录
文章目录
摘要
本文研究了电子商务领域中产品数据的多模态预训练问题.针对图像和文本模态的多模态预训练方法在面对模态缺失和模态噪声这两真实的电子商务场景中多模态产品数据普遍存在的问题时缺乏鲁棒性。为此,本文提出了一种在多模态预训练中引入知识模态的K3M方法,以消除噪声并补充图像和文本模态的缺失。模态编码层提取每个模态的特征。模型交互层能够有效地对多模态的交互进行建模,其中设计了初始交互特征融合模型以保持图像模态和文本模态的独立性,并设计了结构聚合模块以融合图像、文本和知识模态的信息。我们使用三个预训练任务对K3M进行预训练,包括屏蔽对象建模(MOM)、屏蔽语言建模(MLM)和链接预测建模(LPM)。在一个真实的电子商务数据集和一系列基于产品的下游任务上的实验结果表明,当存在模态噪声或模态缺失时,K3M的性能比基线和现有方法有显著的提高。
CCS概念:
计算方法→信息提取;语义网络。
关键词:
知识图,多模态预训练,模态缺失,模态噪声
1 引言
电子商务的兴起极大地便利了人们的生活。在电子商务场景中,存在大量基于商品的应用任务,例如商品分类 [1,2]、商品对齐 [3]、推荐系统 [2,4,5] 等。如图1所示,通常商品会包含图片、标题和结构化的知识,这是一个典型的多模态场景。
近年来,多模态预训练受到了广泛关注 [6–15],这些方法致力于挖掘图像(或视频)模态和文本模态信息之间的关联。考虑到广泛的下游电子商务应用,我们专注于商品多模态数据的预训练。然而,直接将这些多模态预训练方法应用于电子商务场景会导致问题,因为模态丢失和模态噪声是电子商务场景中的两个挑战,这将严重降低多模态信息学习的性能 [16]。在实际的电子商务场景中,一些卖家没有上传商品图片(或标题)到平台,一些卖家提供的商品图片(或标题)主题不明确或语义不准确,使得信息特别令人困惑。图1中的Item-2和Item-3分别展示了我们场景中的模态噪声和模态丢失示例。
为了解决这个问题,我们引入了产品知识图谱(PKG) [17],并将其视为一种新模态,称为知识模态。如图1所示,PKG以三元组形式表示,例如<Item-1, Material, Cotton>表示Item-1的材质是棉花。我们引入PKG主要有两个原因:(1) PKG具有高质量。PKG描述了商品的客观属性,结构化且易于管理,通常会进行维护和标准化工作,因此PKG相对干净且可信。(2) PKG与其他模态的信息存在重叠。以图1中的Item-1为例,一方面,图片、标题和PKG都说明Item-1是一件长袖T恤。另一方面,PKG显示这件长袖T恤不仅适合秋季,也适合春季,这在图片或标题中是无法得知的。因此,当存在模态噪声或模态丢失时,PKG可以对其他模态进行纠正或补充。因此,针对商品数据的预训练,我们考虑了三种模态的信息:图像模态(商品图片)、文本模态(商品标题)和知识模态(PKG)。
本文中,我们提出了一种新颖的电子商务应用中的知识感知多模态预训练方法,称为K3M。具体来说,K3M通过两个步骤学习商品的多模态信息:(1) 编码每个模态的单独信息,(2) 建模模态之间的交互。在编码每个模态的单独信息时,对于图像模态,使用基于Transformer的图像编码器提取图像的初始特征;对于文本模态,使用基于Transformer的文本编码器提取文本的初始特征;对于知识模态,使用相同的文本编码器提取PKG中的关系和尾实体的表面形式特征。
在建模模态之间的交互时,有两个过程。第一个过程是文本模态和图像模态之间的交互,类似于之前的工作 [12];第二个过程是知识模态与其他两个模态之间的交互。在第一个过程中,基于图像和文本模态的初始特征,通过共注意力Transformer学习交互特征。为了保持单个模态的独立性,我们设计了一个初始-交互特征融合模块,将图像和文本模态的初始特征与其交互特征融合。在第二个过程中,图像和文本模态的交互结果用于初始化目标商品实体的表示,该实体是PKG中三元组的头实体,关系和尾实体的表面形式特征则作为它们的初始表示。然后,通过结构聚合模块,将实体和关系的信息传播和聚合到目标商品实体上。最后,知识引导的商品实体表示可以用于各种下游任务。
针对图像模态、文本模态和知识模态的预训练任务分别是掩码对象建模(MOM)、掩码语言建模(MLM)和链接预测建模(LPM)。
在多个下游任务上的实验结果表明,我们的K3M在实体建模中比现有的多模态预训练方法更具鲁棒性。我们的主要贡献如下:
- 我们将PKG的结构化知识引入电子商务中的多模态预训练,能够在大规模多模态数据集中纠正或减弱模态噪声和模态丢失问题。
- 我们提出了一种新颖的多模态预训练方法,K3M。在K3M中,我们将图像和文本模态的初始特征与它们的交互特征进行融合,以进一步提升模型性能。
- 在真实世界的电子商务数据集上进行的实验显示了K3M在多个下游任务中的强大能力。我们的代码和数据集可以在https://github.com/YushanZhu/K3M获取。

图1:产品的多模态数据示例。每个项目都有一个标题、一个图像和一个PKG,PKG通过三元组(<item,property,value>)描述产品的客观属性。
2 相关工作
2.1 多模态预训练
预训练技术在计算机视觉 (CV) 领域的成功应用,如VGG [18]、Google Inception [19] 和ResNet [20],以及在自然语言处理 (NLP) 领域的成功应用,如BERT [21]、XLNet [22] 和GPT-3 [23],激发了多模态预训练的发展。最近,提出了一系列多模态预训练方法,这些方法致力于不同模态信息之间的互补。
VideoBERT [6] 是第一个提出多模态预训练的工作,该方法通过BERT训练了大量未标注的视频-文本对。目前,用于图像和文本的多模态预训练模型主要有两种架构。B2T2 [15]、VisualBERT [7]、Unicoder-VL [8]、VL-BERT [9] 和UNITER [24] 提出了单流架构,在该架构中,单个Transformer同时应用于图像和文本。另一方面,LXMERT [10]、ViLBERT [12] 和FashionBERT [11] 引入了双流架构,其中图像和文本的特征首先独立提取,然后使用更复杂的机制(共注意力)来完成它们的交互。为了进一步提升性能,VLP [14] 对编码和解码使用了共享的多层Transformer,用于图像字幕生成和视觉问答 (VQA)。基于单流架构,InterBERT [13] 在单流模型的输出上添加了两个独立的Transformer流,以捕捉模态的独立性。这些多模态预训练方法无法解决模态丢失和模态噪声的问题。与之前的工作相比,K3M有几个显著的不同。我们提出的模型架构能够有效利用结构化知识来提高模型对模态丢失和模态噪声的鲁棒性。此外,我们提出将模态的初始特征和交互特征进行融合,以保持文本和图像模态的独立性,从而使模型更有效。
2.2 知识图谱增强的预训练模型
最近,越来越多的研究人员开始关注知识图谱 (KG) 和预训练语言模型 (PLM) 的结合,以提升PLM的性能。
K-BERT [25] 将三元组注入句子中,以生成统一的富含知识的语言表示。ERNIE [26] 将来自知识模块的实体表示集成到语义模块中,以在统一的特征空间中表示token和实体的异构信息。KEPLER [27] 将实体的文本描述编码为文本嵌入,并将描述嵌入视为实体嵌入。KnowBert [28] 使用集成的实体链接器通过一种单词到实体的注意力机制生成知识增强的实体跨度表示。K-Adapter [29] 通过神经适配器分别注入事实知识和语言知识到RoBERTa中,以增强其性能。DKPLM [30] 可以根据文本上下文动态选择和嵌入知识,既考虑全局知识也考虑局部知识图谱信息。JAKET [31] 提出了一个联合预训练框架,包括一个知识模块,生成实体的嵌入以生成图中上下文感知的嵌入。此外,KALM [32]、ProQA [33]、LIBERT [34] 等研究人员还在不同的应用任务中探索了知识图谱与PLM的融合实验。
然而,当前增强知识图谱的预训练模型仅针对单一模态,尤其是文本模态。据我们所知,这是首次将知识图谱结合到多模态预训练中的工作。
3 方法
在本节中,我们将描述K3M如何联合建模文本、图像和知识模态的信息。给定一组商品数据 D = { C , I , T , K } D = \{C,I,T,K\} D={C,I,T,K},其中 C C C 是一组商品, I I I 是一组商品图片, T T T 是一组商品标题, K = { E , R , T R } K = \{E,R,TR\} K={E,R,TR} 是PKG,其中 E E E、 R R R 和 T R TR TR 分别是实体、关系和三元组的集合, T R = { ⟨ h , r , t ⟩ ∣ h ∈ E , r ∈ R , t ∈ E } TR = \{\langle h, r, t \rangle | h \in E, r \in R, t \in E \} TR={⟨h,r,t⟩∣h∈E,r∈R,t∈E}。对于每个商品 e c ∈ C e_c \in C ec∈C,它有一个商品图片 i c ∈ I i_c \in I ic∈I,一个商品标题 t c ∈ T t_c \in T tc∈T,以及与其相关的一组来自PKG的三元组,即 T R c = { ⟨ e c , p r o p e r t y , v a l u e ⟩ ∣ e c ∈ E , p r o p e r t y ∈ R , v a l u e ∈ E } ⊂ T R TR_c = \{\langle e_c, property, value \rangle | e_c \in E, property \in R, value \in E \} \subset TR TRc={⟨ec,property,value⟩∣ec∈E,property∈R,value∈E}⊂TR。我们的目标是学习一个模型 M ( i c , t c , T R c ) M(i_c, t_c, TR_c) M(ic,tc,TRc),以学习商品 e c ∈ C e_c \in C ec∈C 的跨模态表示,记为 c ∗ c^* c∗。
我们的模型由三层组成,如图2所示。第一层称为模态编码层,旨在分别编码每个模态的单独信息。第二层称为模态交互层,旨在建模不同模态之间的交互。第三层是模态任务层,其中为不同模态设定了不同的预训练任务。我们首先描述如何在模态编码层中编码图像初始特征、文本初始特征以及知识的表面形式特征。然后展示模态交互层中两个交互过程的建模方法。最后描述模态任务层中的三个预训练任务。

图2:K3M的模型框架。
3.1 模态编码层
3.1.1 图像初始特征
参考[7,9,10,12,13],我们将给定商品 e c e_c ec 的商品图片 i c i_c ic (像素矩阵)通过对象检测模型转换为对象序列。具体来说,参考ViLBERT [12],我们使用Faster R-CNN [35] 从 i c i_c ic 中检测出一系列对象(RoI,感兴趣区域),并将这些对象的边界框作为它们的位置信息。15%的对象随机掩码,如[12]所述。然后如图2所示,对象嵌入和位置嵌入的总和 [ E i 1 , E i 2 , . . . , E i M 1 ] [E_{i1}, E_{i2}, ..., E_{iM1}] [Ei1,Ei2,...,EiM1] 被输入到基于Transformer的图像编码器中,图像编码器输出图像的初始特征 [ h i 1 0 , h i 2 0 , . . . , h i M 1 0 ] [h_{i1}^0, h_{i2}^0, ..., h_{iM1}^0] [hi10,hi20,...,hiM10],其中 M 1 M_1 M1 是对象序列的最大长度。
3.1.2 文本初始特征
参考BERT [21],商品 e c e_c ec 的标题 t c t_c tc 首先通过WordPieces [36] 被分词为一个token序列,15%的token被随机掩码。然后如图2所示,token嵌入和位置嵌入的总和 [ E t 1 , E t 2 , . . . , E t M 2 ] [E_{t1}, E_{t2}, ..., E_{tM2}] [Et1,Et2,...,EtM2] 被输入到基于Transformer的文本编码器中,文本编码器输出文本初始特征 [ h t 1 0 , h t 2 0 , . . . , h t M 2 0 ] [h_{t1}^0, h_{t2}^0, ..., h_{tM2}^0] [ht10,ht20,...,htM20],其中 M 2 M_2 M2 是token序列的最大长度。
3.1.3 知识的表面形式特征
在此步骤中,我们获取三元组 ⟨ e c , p r o p e r t y x , v a l u e x ⟩ \langle e_c, property_x, value_x \rangle ⟨ec,propertyx,valuex⟩ 中关系和尾实体的表面形式特征,其中 x = 1 , . . . , X c x = 1, ..., X_c x=1,...,Xc, X c X_c Xc 是 T R c TR_c TRc 中三元组的数量。我们不考虑头实体,因为它的表面形式没有语义信息,如图1所示。为了充分利用上下文信息,我们首先将 T R c TR_c TRc 中所有三元组的关系和尾实体拼接成一段长知识文本,如“property1 value1 property2 value2 property3 …”(例如,图1中Item-1的知识文本是“material cotton way to dress pullover season …”),然后根据WordPieces将其分词成一个token序列。接着,使用与3.1.2节中提取文本初始特征的相同文本编码器对知识文本的token序列进行编码。如图2所示,文本编码器输出 [ h k 1 0 , h k 2 0 , . . . , h k M 3 0 ] [h_{k1}^0, h_{k2}^0, ..., h_{kM3}^0] [hk10,hk20,...,hkM30],基于输入嵌入 [ E k 1 , E k 2 , . . . , E k M 3 ] [E_{k1}, E_{k2}, ..., E_{kM3}] [Ek1,Ek2,...,EkM3],其中 M 3 M_3 M3 是知识文本的最大token序列长度。最后,我们计算每个关系和尾实体的表面形式特征,作为其对应token最后隐藏层状态的均值池化值(一个关系或尾实体可能被分割为多个token,如图2所示),记为 p x p_x px 和 v x v_x vx,其中 x = 1 , . . . , X c x = 1, ..., X_c x=1,...,Xc, X c X_c Xc 是 T R c TR_c TRc 中三元组的数量。
3.2 模态交互层
在这一层中,有两个过程来建模模态交互。第一个是图像模态和文本模态之间的交互,第二个是知识模态与其他两个模态之间的交互。我们将分别介绍这两个过程。
3.2.1 图像模态和文本模态之间的交互
首先,图像-文本交互器(Image-text Interactor)应用共注意力Transformer [12],将图像初始特征
[
h
t
1
0
,
h
t
2
0
,
.
.
.
,
h
t
M
1
0
]
[h_{t1}^0, h_{t2}^0, ..., h_{tM1}^0]
[ht10,ht20,...,htM10] 和文本初始特征
[
h
i
1
0
,
h
i
2
0
,
.
.
.
,
h
i
M
2
0
]
[h_{i1}^0, h_{i2}^0, ..., h_{iM2}^0]
[hi10,hi20,...,hiM20] 作为输入。具体来说,在共注意力Transformer中,每个模态的“key”和“value”传递到另一个模态的注意力块中,进行图像条件的文本注意力和文本条件的图像注意力。之后,图像-文本交互器生成图像的交互特征
[
h
i
1
T
,
h
i
2
T
,
.
.
.
,
h
i
M
1
T
]
[h_{i1}^T, h_{i2}^T, ..., h_{iM1}^T]
[hi1T,hi2T,...,hiM1T] 和文本的交互特征
[
h
t
1
I
,
h
t
2
I
,
.
.
.
,
h
t
M
2
I
]
[h_{t1}^I, h_{t2}^I, ..., h_{tM2}^I]
[ht1I,ht2I,...,htM2I]。
然而,通过共注意力Transformer学习模态交互特征时,忽略了单个模态的独立性 [13]。当某个模态存在噪声或丢失时,模态交互将对另一个模态产生负面影响,从而破坏模态的交互特征。因此,保持单个模态的独立性是必要的。为了解决这个问题,我们提出保留在模态编码层中学习到的图像初始特征和文本初始特征,并设计一个初始-交互特征融合模块(IFFM),将图像和文本模态的初始特征与它们的交互特征融合。IFFM将对象(或token)的初始特征和交互特征作为输入,并将这两个特征向量融合为一个输出向量,表示为:
h
t
a
=
f
u
s
i
o
n
(
h
t
a
0
,
h
t
a
I
)
,
(
a
=
1
,
2
,
.
.
.
,
M
1
)
h_{ta} = fusion(h_{ta}^0, h_{ta}^I), (a = 1, 2, ..., M1)
hta=fusion(hta0,htaI),(a=1,2,...,M1)
h
i
b
=
f
u
s
i
o
n
(
h
i
b
0
,
h
i
b
T
)
,
(
b
=
1
,
2
,
.
.
.
,
M
2
)
h_{ib} = fusion(h_{ib}^0, h_{ib}^T), (b = 1, 2, ..., M2)
hib=fusion(hib0,hibT),(b=1,2,...,M2)
其中,函数
f
u
s
i
o
n
(
⋅
)
fusion(\cdot)
fusion(⋅) 是融合算法,K3M中有三种融合算法:(1) 均值:计算两个输入向量的均值,模型记为“K3M(mean)”。(2) 软采样(Soft-Sampling):[37]中提出的一种用于特征融合的高级采样方法,模型记为“K3M(soft-spl)”。(3) 硬采样(Hard-Sampling):[37]中提出的另一种用于特征融合的高级采样方法,模型记为“K3M(hard-spl)”。
3.2.2 知识模态与其他两个模态的交互
首先,图像和文本模态的交互结果用于初始化商品 e c e_c ec 的表示,该表示是 T R c TR_c TRc 中三元组的头实体。我们计算 e c e_c ec 的初始表示为IFFM所有输出的均值池化值: c = m e a n _ p o o l i n g ( h t 1 , . . . , h t M 1 , W 0 h i 1 , . . . , W 0 h i M 2 ) c = mean\_pooling(h_{t1}, ..., h_{tM1}, W_0h_{i1}, ..., W_0h_{iM2}) c=mean_pooling(ht1,...,htM1,W0hi1,...,W0hiM2)
其中, W 0 W_0 W0 是一个线性变换矩阵,用于将所有向量转换为相同维度。因此,三元组 ⟨ e c , p r o p e r t y x , v a l u e x ⟩ \langle e_c, property_x, value_x \rangle ⟨ec,propertyx,valuex⟩( x = 1 , . . . , X c x = 1, ..., X_c x=1,...,Xc)的头实体、关系和尾实体的表示分别初始化为 c 、 p x 和 v x c、p_x 和 v_x c、px和vx,其中 p x 和 v x p_x 和 v_x px和vx 是在模态编码层中学习到的关系和尾实体的表面特征。
受[38]中思想的启发,该思想改进了GAT [39],旨在捕捉任何给定实体的邻域中的实体和关系特征,我们设计了一个结构聚合模块,用于传播和聚合实体和关系的信息,从而融合图像、文本和知识模态的信息。具体来说,三元组 ⟨ e c , p r o p e r t y x , v a l u e x ⟩ \langle e_c, property_x, value_x \rangle ⟨ec,propertyx,valuex⟩ 的表示首先通过以下公式学习: t x = W 1 [ c ∣ ∣ p x ∣ ∣ v x ] t_x = W_1[c || p_x || v_x] tx=W1[c∣∣px∣∣vx]
其中, W 1 W_1 W1 是一个线性变换矩阵。然后,通过LeakyReLU非线性函数表示三元组的重要性:
b x = L e a k y R e L U ( W 2 t x ) b_x = LeakyReLU(W_2t_x) bx=LeakyReLU(W2tx)
其中, W 2 W_2 W2 是线性权重矩阵。每个三元组的注意力值通过Softmax计算得到:
a x = S o f t m a x ( b x ) = e x p ( b x ) ∑ i = 1 X c e x p ( b i ) a_x = Softmax(b_x) = \frac{exp(b_x)}{\sum_{i=1}^{X_c} exp(b_i)} ax=Softmax(bx)=∑i=1Xcexp(bi)exp(bx)
最后,商品 e c e_c ec 的最终表示通过其初始表示 c c c 和所有三元组在 T R c TR_c TRc 中按注意力值加权的表示之和得到:
c ∗ = W 3 c + σ ( 1 M h ∑ m = 1 M h ∑ x = 1 X c a x m t x m ) c^* = W_3c + \sigma \left(\frac{1}{M_h}\sum_{m=1}^{M_h} \sum_{x=1}^{X_c} a^m_x t^m_x \right) c∗=W3c+σ(Mh1m=1∑Mhx=1∑Xcaxmtxm)
其中, W 3 W_3 W3 是权重矩阵, σ ( ⋅ ) \sigma(\cdot) σ(⋅) 是激活函数, M h M_h Mh 是注意力头的数量, X c X_c Xc 是 T R c TR_c TRc 中三元组的数量。
3.3 模态任务层
在这一层中,我们为三种模态设计了不同的预训练任务。分别是针对文本模态的掩码语言建模(MLM)、针对图像模态的掩码对象建模(MOM)和针对知识模态的链接预测建模(LPM)。
3.3.1 掩码语言建模(MLM)
此任务与BERT预训练中的MLM任务相同,目标是预测被掩码的token。训练时通过最小化交叉熵损失来优化模型:
l M L M = − E t c ∼ T l o g P ( t o k m ∣ t o k m ) l_{MLM} = -E_{tc \sim T}logP(tok_m | tok_m) lMLM=−Etc∼TlogP(tokm∣tokm)
其中, t o k m tok_m tokm 表示被掩码的token, t o k m tok_m tokm 表示已掩码的token序列。
3.3.2 掩码对象建模(MOM)
与MLM类似,MOM的目标是预测图像中被掩码对象的类别。训练通过最小化交叉熵损失来优化:
l M O M = − E i c ∼ I l o g P ( o b j m ∣ o b j m ) l_{MOM} = -E_{ic \sim I}logP(obj_m | obj_m) lMOM=−Eic∼IlogP(objm∣objm)
其中, o b j m obj_m objm 表示被掩码的对象, o b j m obj_m objm 表示已掩码的对象序列。
3.3.3 链接预测建模(LPM)
此任务的目标是评估给定三元组的可信度。参考基于翻译的KG嵌入方法TransE [40],该方法假设如果 ⟨ h , r , t ⟩ \langle h, r, t \rangle ⟨h,r,t⟩ 是一个真实的三元组,那么 h h h 的表示向量加上 r r r 的表示向量应等于 t t t 的表示向量。我们定义三元组 ⟨ e c , p r o p e r t y x , v a l u e x ⟩ \langle e_c, property_x, value_x \rangle ⟨ec,propertyx,valuex⟩ 的得分为:
S x c = ∣ ∣ c ∗ + p x − v x ∣ ∣ 1 , x = 1 , . . . , X c S_xc = ||c^* + p_x - v_x||_1, x = 1, ..., X_c Sxc=∣∣c∗+px−vx∣∣1,x=1,...,Xc
LPM的目标是使正确三元组的得分较低,而错误三元组的得分较高。训练通过最小化边缘损失进行优化:
l L P M = E T R c ∼ K 1 X c ∑ x = 1 X c m a x { S x c − S x c ~ + γ , 0 } l_{LPM} = E_{TRc \sim K} \frac{1}{X_c} \sum_{x=1}^{X_c} max\{S_xc - \widetilde{S_xc} + \gamma, 0\} lLPM=ETRc∼KXc1x=1∑Xcmax{Sxc−Sxc +γ,0}
其中, γ \gamma γ 是边界超参数, S x c S_xc Sxc 是正三元组 ⟨ e c , p r o p e r t y x , v a l u e x ⟩ \langle e_c, property_x, value_x \rangle ⟨ec,propertyx,valuex⟩ 的得分, S x c ~ \widetilde{S_xc} Sxc 是通过随机替换头实体 e c e_c ec 或尾实体 v a l u e x value_x valuex 生成的负三元组 ⟨ e c ′ , p r o p e r t y x , v a l u e x ⟩ \langle e'_c, property_x, value_x \rangle ⟨ec′,propertyx,valuex⟩ 或 ⟨ e c , p r o p e r t y x , v a l u e x ′ ⟩ \langle e_c, property_x, value'_x \rangle ⟨ec,propertyx,valuex′⟩ 的得分。
K3M的最终预训练损失是上述三个任务的损失之和:
L p r e = l M L M + l M O M + l L P M L_{pre} = l_{MLM} + l_{MOM} + l_{LPM} Lpre=lMLM+lMOM+lLPM
4 实验
4.1 预训练(Pretraining)
4.1.1数据集。
我们的K3M是在淘宝上的数百万件商品(40132418)上经过训练和验证的,每件商品都包含一个标题、一张图片和一组来自PKG的与之相关的三元组。预训练数据集的统计量见表1。

我们的K3M在训练和有效数据集上进行了预训练,我们在测试数据集上评估了预训练的K3M,测试数据集用作下游任务的微调数据集。
4.1.2实施细节。
我们使用Pytorch实现了K3M,其中在初始交互式融合模块中应用了三种融合算法:“K3M(mean)”、“K3M(soft-spl)”和“K3M(hard-spl)”。更多详情见附录。
4.1.3基线的预训练。
我们将K3M与几种图像和文本模态预训练基线进行了比较:一种代表性的单流方法VLBERT [9],以及两种双流方法ViLBERT [12]和LXMERT [10]。基线也在淘宝数据上进行了预训练,并根据原始论文进行了初始化。我们为基线预训练了两种类型的模型:(1)使用正常的图像和文本模态进行训练,包括“ViLBERT”,“LXMERT”和“VLBERT”;(2)使用图像,文本和知识模态进行训练,包括“ViLBERT+PKG”,“VLBERT+PKG”和“LXMERT+PKG”,其中PKG的知识文本拼接在标题文本后面作为文本模态输入。更多详情见附录。
4.2微调:商品分类
4.2.1 任务定义
商品分类是将给定商品分配到相应类别的任务,这是电子商务平台产品管理中的常见任务,可以被视为多类别分类任务。给定一组商品 C C C 和一组类别 C L S CLS CLS,目标是训练一个映射函数 f : C → C L S f : C \rightarrow CLS f:C→CLS。
4.2.2 模型
K3M。对于给定商品
e
c
i
∈
C
e_{ci} \in C
eci∈C,该商品包含图像
i
c
i_c
ic、标题
t
c
t_c
tc 和一组三元组
T
R
c
TR_c
TRc,我们获取其表示
c
i
∗
=
M
(
i
c
,
t
c
,
T
R
c
)
c^*_i = M(i_c, t_c, TR_c)
ci∗=M(ic,tc,TRc),并将其输入到全连接层:
p
i
=
σ
(
W
c
i
∗
+
β
)
p_i = \sigma(Wc^*_i + \beta)
pi=σ(Wci∗+β)
其中, W ∈ R d × ∣ C L S ∣ W \in \mathbb{R}^{d \times |CLS|} W∈Rd×∣CLS∣ 是权重矩阵, d d d 是 c i ∗ c^*_i ci∗ 的维度, β \beta β 是偏置向量, p i = [ p i 1 , p i 2 , … , p i ∣ C L S ∣ ] p_i = [p_{i1}, p_{i2}, \ldots, p_{i|CLS|}] pi=[pi1,pi2,…,pi∣CLS∣],其中 p i j p_{ij} pij 是商品 e c i e_{ci} eci 属于类别 c l s j cls_j clsj 的概率, j ∈ { 1 , … , ∣ C L S ∣ } j \in \{1, \ldots, |CLS|\} j∈{1,…,∣CLS∣}。
我们使用交叉熵损失对 K3M 进行微调: L = − 1 ∣ C ∣ ∑ i = 1 ∣ C ∣ ∑ j = 1 ∣ C L S ∣ y i j log ( p i j ) L = - \frac{1}{|C|} \sum_{i=1}^{|C|} \sum_{j=1}^{|CLS|} y_{ij} \log(p_{ij}) L=−∣C∣1i=1∑∣C∣j=1∑∣CLS∣yijlog(pij)
基线模型按照原始论文中的描述,对于 ViLBERT,我们将商品的表示计算为 [ I M G ] [IMG] [IMG] 和 [ C L S ] [CLS] [CLS] 最后一层隐藏状态的逐元素积;对于 LXMERT 和 VLBERT,表示为 [ C L S ] [CLS] [CLS] 的最后一层隐藏状态。接下来的步骤与公式(11)和(12)相同。
4.2.3 数据集
更多详情请参见附录。
4.2.4 数据集的缺失和噪声
对于包含 N N N 个商品的数据集,我们设置了 3 种商品标题和图片的缺失情况:
- 仅标题缺失比例 T M R = ρ % TMR = \rho\% TMR=ρ% 表示 ρ % \rho \% ρ% 的商品没有标题。
- 仅图片缺失比例 I M R = ρ % IMR = \rho\% IMR=ρ% 表示 ρ % \rho \% ρ% 的商品没有图片。
- 混合缺失比例 M M R = ρ % MMR = \rho\% MMR=ρ% 表示 ρ % \rho \% ρ% 的商品存在标题和图片的不同缺失情况。按照文献 [41] 中的方法,对于每个商品类别,我们随机采样 N × ρ 2 % N \times \frac{\rho}{2}\% N×2ρ% 的商品去除其图片,并从剩余商品中采样 N × ρ 2 % N \times \frac{\rho}{2}\% N×2ρ% 的商品去除其标题。
还设置了 4 种商品标题和图片的噪声情况:
- 仅标题噪声比例 T N R = ρ % TNR = \rho\% TNR=ρ% 表示 ρ % \rho \% ρ% 的商品标题与其不匹配,通过用其他商品的标题替换生成。
- 仅图片噪声比例 I N R = ρ % INR = \rho\% INR=ρ% 表示 ρ % \rho \% ρ% 的商品图片与其不匹配,通过用其他商品的图片替换生成。
- 标题-图片噪声比例 T I N R = ρ % TINR = \rho\% TINR=ρ% 表示 ρ % \rho \% ρ% 的商品同时存在标题和图片不匹配的情况。
- 混合噪声比例 M N R = ρ % MNR = \rho\% MNR=ρ% 表示 ρ % \rho \% ρ% 的商品具有标题噪声、图片噪声和标题-图片噪声的不同情况。与[41]中一样,对于每个项目类,我们随机抽取 N × ρ / 3 % N \times \rho /3\% N×ρ/3%的项目来替换它们的图像/标题,并从其余项目中随机抽取 N × ρ / 3 % N \times \rho /3\% N×ρ/3%的项目来替换它们的标题和图像。
在[41]之后,为了制作平衡的数据集,我们将训练/开发/测试数据集中每个类和每个缺失或噪声情况的项目数量保持为7:1:2。数据集的模态缺失和噪声的设置对于所有下游任务都是相同的。
4.2.5 结果分析
图3显示了项目分类的各种模型的结果,从中我们可以观察到:(1)当存在模态缺失或模态噪声时,基线模型严重缺乏鲁棒性。对于“仅标题缺失”,与TMR= 0%相比,当TMR增加到20%、50%、80%和100%时,“ViLBERT”、“LXMERT”和“VLBERT”的性能平均下降10.2%、24.4%、33.1%和40.2%。(2)与图像模态相比,缺失和噪声的文本模态对性能的影响更大。比较3个基线的“仅标题噪声”和“仅图像噪声”,随着TNR的增加,模型性能下降了15.1%-43.9%,而随着INR的增加,模型性能下降了2.8%-10.3%,这表明文本信息在其中起着更重要的作用。(3)知识图的引入可以有效地改善模态缺失和模态噪声问题。有PKG的基线实验结果明显优于无PKG的基线实验结果。对于“仅标题缺失”,在没有PKG的基线基础上,当TMR从0%增加到100%时,“ViLBERT+PKG”、“LXMERT+PKG”和“VLBERT+PKG”获得了13.0%、22.2%、39.9%、54.4%和70.1%的平均改善。(4)我们的方法在这些性能指标评测中实现了最先进的性能。它进一步改善了“ViLBERT+PKG”、“LXMERT+PKG”和“VLBERT+PKG”的结果,在各种模态缺失和模态噪声设置下改善了0.6%到4.5%之间。
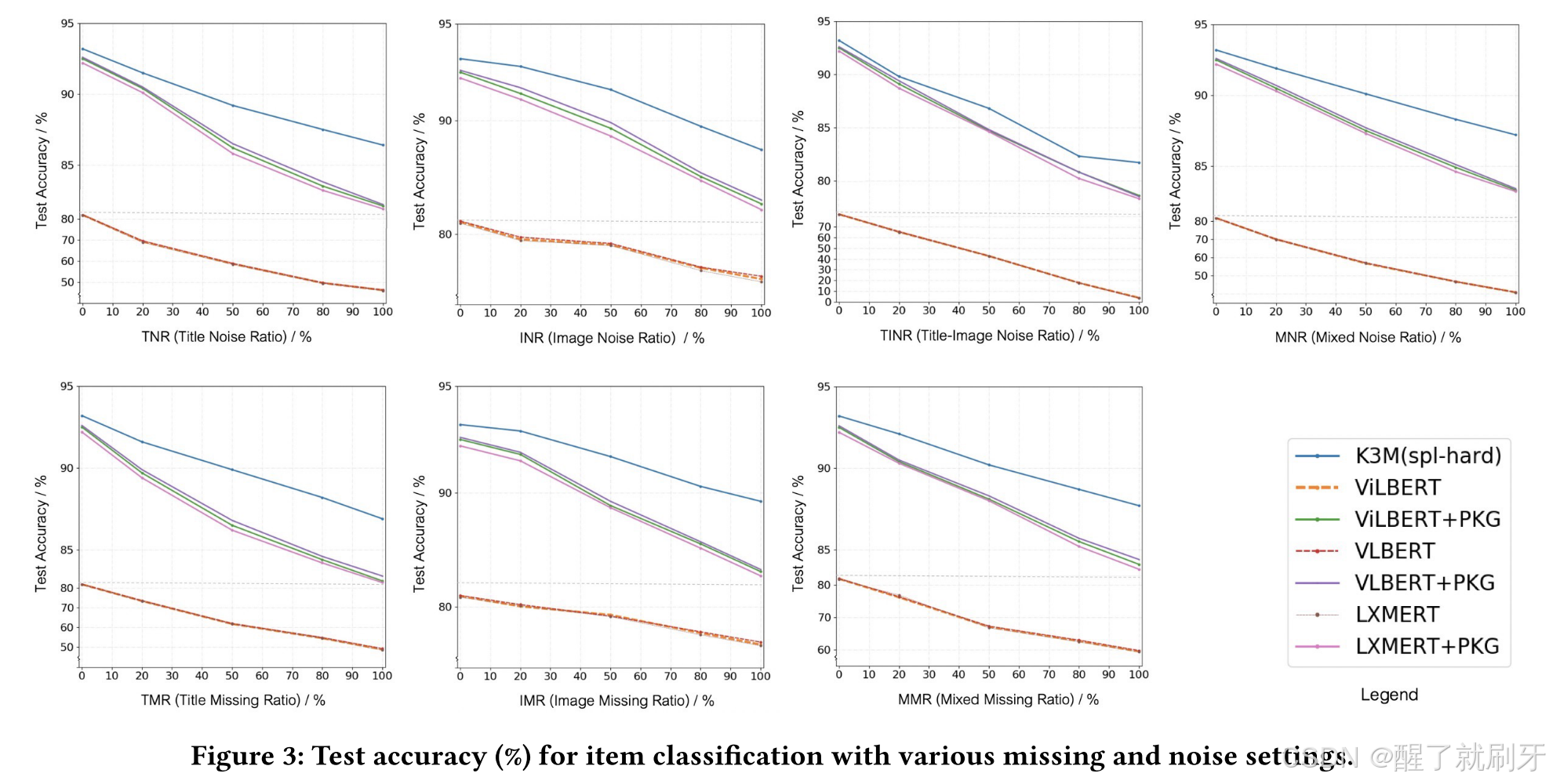
图3:在各种缺失和噪声设置下,项目分类的测试准确度(%)。
4.2微调:产品对齐
4.3.1 任务定义
产品对齐是指判断给定的一对商品是否对齐(即是否指代同一个产品)。例如,许多在线商店都在销售 iPhone 11,白色,128GB 容量。它们在平台上是不同的商品,但从产品的角度来看,它们指的是同一个产品。这项任务对于日常业务非常有帮助,例如推荐产品以帮助用户比较价格和售后服务。它可以被看作是一个二元分类任务,给定一组商品对 C p C^p Cp 和一组 Y = { T r u e , F a l s e } Y = \{True, False\} Y={True,False},目标是训练一个映射函数 f : C p ↦ Y f : C^p \mapsto Y f:Cp↦Y。
4.3.2 模型
K3M 对于给定的一对商品 ( e c i 0 , e c i 1 ) ∈ C p (e_{ci}^0, e_{ci}^1) \in Cp (eci0,eci1)∈Cp,我们首先分别获取商品 e c i 0 e_{ci}^0 eci0 和 e c i 1 e_{ci}^1 eci1 的表示,即 c i 0 ∗ = M ( i c 0 , t c 0 , T R c 0 ) c_{i0}^* = M(i_c^0, t_c^0, TR_c^0) ci0∗=M(ic0,tc0,TRc0) 和 c i 1 ∗ = M ( i c 1 , t c 1 , T R c 1 ) c_{i1}^*= M(i_c^1, t_c^1, TR_c^1) ci1∗=M(ic1,tc1,TRc1),然后将它们连接起来并输入到全连接层:
p i = σ ( W [ c i 0 ∗ ∣ ∣ c i 1 ∗ ] + β ) , (13) p_i = \sigma(W[c_{i0}^{*} || c_{i1}^{*}] + \beta), \tag{13} pi=σ(W[ci0∗∣∣ci1∗]+β),(13)
其中 W ∈ R 2 d × 2 W \in \mathbb{R}^{2d \times 2} W∈R2d×2, p i = [ p i 0 , p i 1 ] p_i = [p_{i0}, p_{i1}] pi=[pi0,pi1],其中 p i 1 p_{i1} pi1 是 e c i 0 e_{ci}^0 eci0 和 e c i 1 e_{ci}^1 eci1 对齐的概率。我们用交叉熵损失函数微调 K3M:
L = − 1 ∣ C p ∣ ∑ i = 1 ∣ C p ∣ y i log ( p i 1 ) + ( 1 − y i ) log ( p i 0 ) , (14) L = -\frac{1}{|C^p|} \sum_{i=1}^{|C^p|} y_i \log(p_{i1}) + (1 - y_i) \log(p_{i0}), \tag{14} L=−∣Cp∣1i=1∑∣Cp∣yilog(pi1)+(1−yi)log(pi0),(14)
其中,当 e c i 0 e_{ci}^0 eci0 和 e c i 1 e_{ci}^1 eci1 对齐时, y i = 1 y_i = 1 yi=1,否则 y i = 0 y_i = 0 yi=0。
基线模型 我们以与商品分类任务相同的方式计算 e c i 0 e_{ci}^0 eci0 和 e c i 1 e_{ci}^1 eci1 的表示。后续步骤与公式 (13) 和 (14) 相同。
4.3.3 数据集
更多细节见附录。
4.3.4 结果分析
该任务的评估指标为 F1-score。图 4 显示了产品对齐任务的测试 F1-score。在这个任务中,我们可以得到与商品分类任务类似的观察结果。此外,对于模态缺失,模型性能不一定随着缺失比例的增加而下降,反而波动:当缺失比例(TMR、IMR 和 MMR)为 50% 或 80% 时,模型性能有时甚至低于 100% 时的性能。实际上,这个任务的本质是学习一个模型来评估两个商品的多模态信息的相似性。从直觉上看,当对齐商品对中的两个商品同时缺少标题或图片时,它们的信息看起来比当一个缺少标题或图片而另一个没有缺失时更相似。
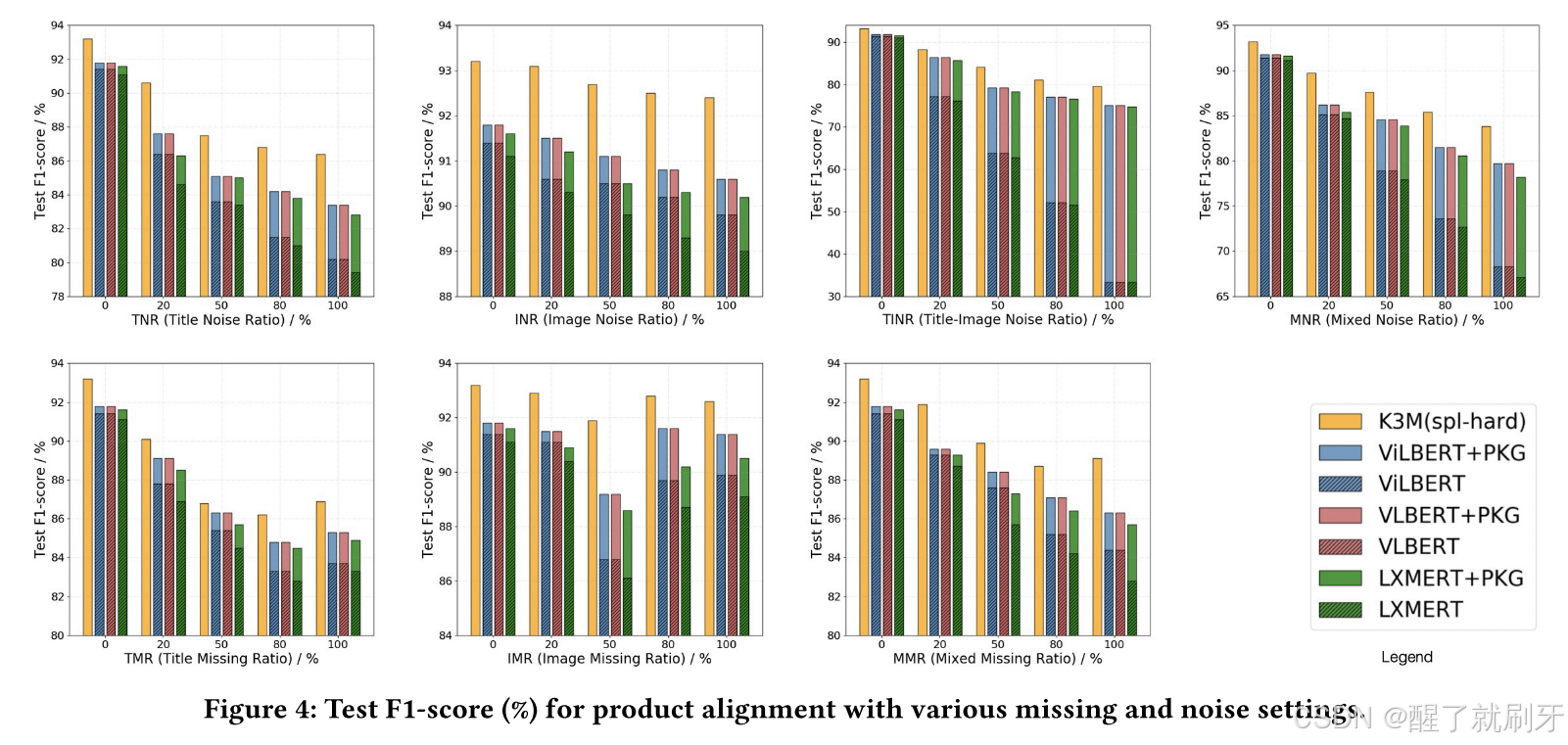
图4:测试F1-分数(%)与各种缺失和噪声设置的产品对齐。
4.4 微调:多模态问答
4.4.1 任务定义
该任务的目标是基于给定商品的多模态信息和问题返回答案。此任务可以用于自动客服系统。例如,如果用户想知道某个产品的材料或适用季节,自动客服系统可以快速给出答案。参考以往的问答任务 [9, 11–13],我们将其框定为多类分类任务。给定一组商品-问题对 Q p Q_p Qp 和一组候选答案 A A A,目标是训练一个映射函数 f : Q p ↦ A f : Q_p \mapsto A f:Qp↦A。
4.4.2 模型
K3M 对于给定的商品-问题对 ( e c i , q i ) ∈ Q p (e_{ci}, q_i) \in Q_p (eci,qi)∈Qp,我们将其表示为 c q i ∗ = M ( [ i c ∣ q i ] , t c , T R c ) c^*_{qi} = M([i_c | q_i], t_c, TR_c) cqi∗=M([ic∣qi],tc,TRc),其中 [ i c ∣ q i ] [i_c | q_i] [ic∣qi] 是“问题”和商品标题的连接,表达为“product title [SEP] question”。然后我们将 c q i ∗ c^*_{qi} cqi∗ 输入全连接层:
p i = σ ( W c q i ∗ + β ) , (15) p_i = \sigma(Wc^*_{qi} + \beta), \tag{15} pi=σ(Wcqi∗+β),(15)
其中 W ∈ R d × ∣ A ∣ W \in \mathbb{R}^{d \times |A|} W∈Rd×∣A∣ 是加权矩阵, p i = [ p i 1 , p i 2 , . . . , p i ∣ A ∣ ] p_i = [p_{i1}, p_{i2}, ..., p_{i|A|}] pi=[pi1,pi2,...,pi∣A∣],其中 p i j p_{ij} pij 是 ( e c i , q i ) (e_{ci}, q_i) (eci,qi) 的答案是 a j ∈ A a_j \in A aj∈A 的概率, j = 1 , . . . , ∣ A ∣ j = 1, ..., |A| j=1,...,∣A∣。我们使用交叉熵损失函数对 K3M 进行微调:
L = − 1 ∣ Q p ∣ ∑ i = 1 ∣ Q p ∣ ∑ j = 1 ∣ A ∣ y i j log ( p i j ) , (16) L = -\frac{1}{|Q_p|} \sum_{i=1}^{|Q_p|} \sum_{j=1}^{|A|} y_{ij} \log(p_{ij}), \tag{16} L=−∣Qp∣1i=1∑∣Qp∣j=1∑∣A∣yijlog(pij),(16)
其中,如果 ( e c i , q i ) (e_{ci}, q_i) (eci,qi) 的答案是 a j a_j aj,则 y i j = 1 y_{ij} = 1 yij=1,否则 y i j = 0 y_{ij} = 0 yij=0。
基线模型 对于 “ViLBERT”、“LXMERT” 和 “VLBERT”,我们将标题 i c i_c ic 和“问题”作为文本模态输入,表达为 “product title [SEP] question”。对于 “ViLBERT+PKG”、“LXMERT+PKG” 和 “VLBERT+PKG”,我们将 i c i_c ic、 e c i e_{ci} eci 的知识文本和“问题”作为文本模态输入,表达为 “product title [SEP] property1 value1 property2 … [SEP] question”。参考原论文,我们将 ( e c i , q i ) (e_{ci}, q_i) (eci,qi) 的表示计算为 ViLBERT 中 [CLS] 和 [IMG] 最后隐藏状态的元素积,对于 LXMERT 和 VLBERT,则使用 [CLS] 的最后隐藏状态。后续步骤与公式 (15) 和 (16) 相同。
4.4.3 数据集
更多细节见附录。
4.4.4 结果分析
该任务的评估指标为 Rank@K(K=1, 3, 10),其中 Rank@K 是在前K个排序列表中出现正确答案的百分比。特别地,与 [12] 一致,对于一个商品-问题对
(
e
c
i
,
q
i
)
(e_{ci}, q_i)
(eci,qi),我们为每个候选答案
a
j
∈
A
a_j \in A
aj∈A 打分,作为
a
j
a_j
aj 是答案的概率,即
p
i
j
p_{ij}
pij,然后对
A
A
A 中所有候选答案进行排序。表 2 显示了多模态问答任务的排名结果。在这个任务中,我们可以得到与商品分类任务类似的观察结果。
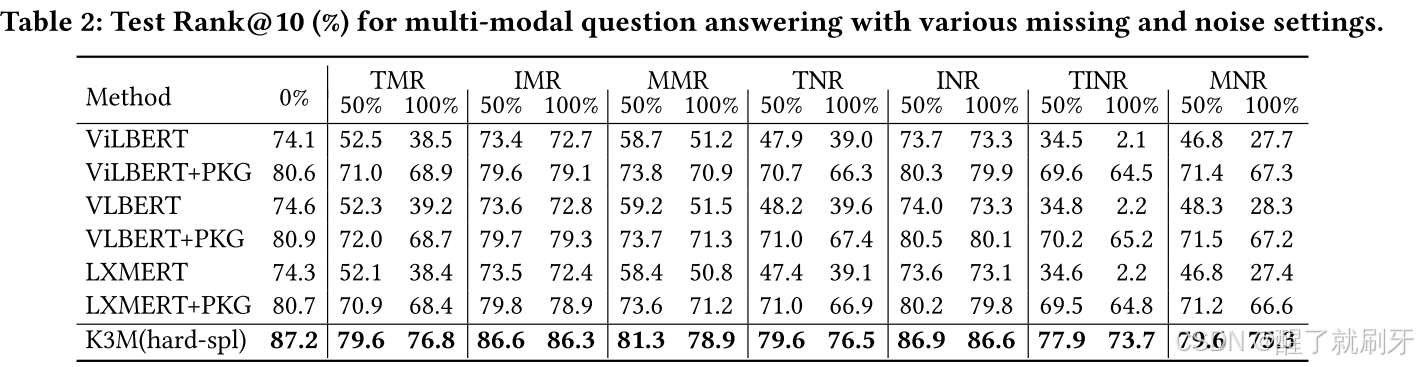
表2:具有各种缺失和噪声设置的多模态问题回答的测试等级@10(%)。
4.5 消融研究
在本节中,我们验证了我们提出的融合图像和文本模态初始特征与交互特征的有效性。我们从头开始预训练了另一个不包含初始-交互特征模块(IFFM)的 K3M,记作“K3M w/o IFFM”,其中 PKG 中三元组的头实体仅通过图像和文本模态的交互特征初始化,公式 (2) 被改写为:
c = m e a n _ p o o l i n g ( h t 1 I , . . . , h t M 1 I , W 0 h i 1 T , . . . , W 0 h i M 2 T ) . (17) c = mean\_pooling(h^I_{t1}, ..., h^I_{tM1}, W_0 h^T_{i1}, ..., W_0 h^T_{iM2}). \tag{17} c=mean_pooling(ht1I,...,htM1I,W0hi1T,...,W0hiM2T).(17)
表 3 显示了三个下游任务的结果。我们可以看到,带有 IFFM 的 K3M 应用不同的融合算法时,其表现均优于没有 IFFM 的 K3M,这表明我们提出的初始特征和交互特征的融合确实能够通过保持文本和图像模态的独立性进一步提升模型性能。由于篇幅有限,我们只展示了部分结果,更多结果请参阅附录。
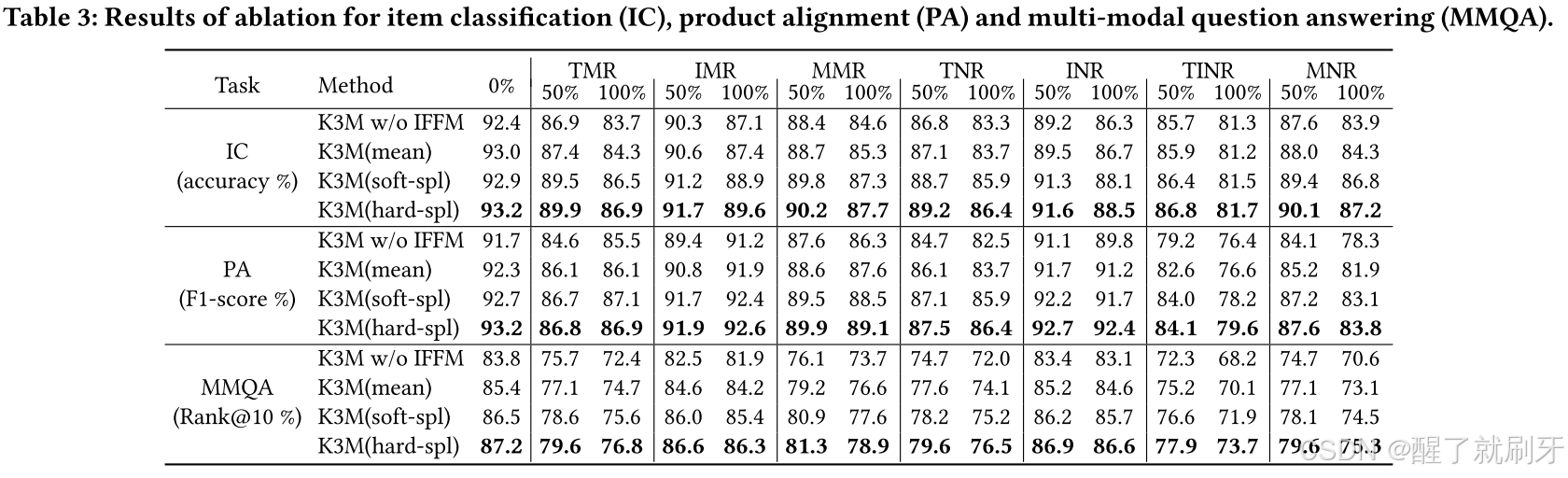
表3:项目分类(IC)、产品对齐(PA)和多模式问题回答(MMQA)的消融结果。
5 结论和今后的工作
本文将PKG的结构化知识引入到电子商务的多模态预训练中,提出了一种新的方法K3M。该模型体系结构包括模态编码层,用于提取每个模态的特征,模态交互层,用于对多个模态的交互进行建模,以及模态任务层,包含不同模态的预训练任务。在模态交互层,设计了结构聚合模块,对PKG的实体节点和关系边信息进行传播和聚合;设计了初始交互特征融合模块,对图像和文本模态的初始特征和交互特征进行融合,进一步提高模型性能。在真实电子商务数据集上的实验表明了K3 M的强大能力。在未来的工作中,我们希望将K3M应用于更多的下游任务,并在更一般的数据集上探索其性能。
该 结构聚合模块 的核心原理是通过多头注意力机制(类似于Graph Attention Network, GAT)来捕捉图像、文本和知识模态中的信息,进而融合这些信息以增强实体和关系的表示。通过这个模块,信息可以在不同模态之间传播和聚合,从而提高最终的特征表达能力。下面是对模块原理的详细解析:
1. 三元组表示的学习
首先,模块针对每个三元组
⟨
e
c
,
p
r
o
p
e
r
t
y
x
,
v
a
l
u
e
x
⟩
\langle e_c, property_x, value_x \rangle
⟨ec,propertyx,valuex⟩,通过拼接实体
e
c
e_c
ec、属性
p
r
o
p
e
r
t
y
x
property_x
propertyx 和值
v
a
l
u
e
x
value_x
valuex,来学习三元组的表示
t
x
t_x
tx。该表示通过以下公式学习:
t
x
=
W
1
[
c
∣
∣
p
x
∣
∣
v
x
]
t_x = W_1[c || p_x || v_x]
tx=W1[c∣∣px∣∣vx]
- 其中, W 1 W_1 W1 是一个线性变换矩阵。
- 该公式的作用是将三元组的实体、属性和值进行拼接,之后通过线性变换得到三元组的表示。
2. 三元组重要性的评估
接下来,为了计算每个三元组的重要性,使用 LeakyReLU 非线性函数对三元组表示进行激活:
b
x
=
L
e
a
k
y
R
e
L
U
(
W
2
t
x
)
b_x = LeakyReLU(W_2t_x)
bx=LeakyReLU(W2tx)
- 其中, W 2 W_2 W2 是一个线性权重矩阵。
- b x b_x bx 是三元组的激活值,它反映了三元组在信息聚合过程中的重要性。
3. 计算注意力值
每个三元组的注意力值通过 Softmax 函数进行计算,表示不同三元组的权重。Softmax公式如下:
a
x
=
S
o
f
t
m
a
x
(
b
x
)
=
e
x
p
(
b
x
)
∑
i
=
1
X
c
e
x
p
(
b
i
)
a_x = Softmax(b_x) = \frac{exp(b_x)}{\sum_{i=1}^{X_c} exp(b_i)}
ax=Softmax(bx)=∑i=1Xcexp(bi)exp(bx)
- 其中, a x a_x ax 是三元组的注意力值。
- 通过Softmax归一化后的结果,决定了不同三元组对最终实体表示的贡献大小。
- X c X_c Xc 是当前实体 e c e_c ec 关联的三元组的数量。
4. 最终实体表示的聚合
最后,实体 e c e_c ec 的最终表示 c ∗ c^* c∗ 是通过两个部分来加权融合的:
- 初始实体表示 c c c:这是实体的原始特征,作为输入传递到聚合模块。
- 三元组加权和:通过注意力机制加权后的三元组信息。每个三元组的表示
t
x
t_x
tx 被其对应的注意力值
a
x
a_x
ax 加权。所有三元组的加权信息被求和,并与初始实体表示融合。该过程通过以下公式实现:
c ∗ = W 3 c + σ ( 1 M h ∑ m = 1 M h ∑ x = 1 X c a x m t x m ) c^* = W_3c + \sigma \left(\frac{1}{M_h}\sum_{m=1}^{M_h} \sum_{x=1}^{X_c} a^m_x t^m_x \right) c∗=W3c+σ(Mh1m=1∑Mhx=1∑Xcaxmtxm) - W 3 W_3 W3 是一个权重矩阵,用来调节初始实体表示与加权三元组信息的融合程度。
- σ ( ⋅ ) \sigma(\cdot) σ(⋅) 是激活函数,用来增加非线性。
- M h M_h Mh 是注意力头的数量。多头注意力机制允许在多个子空间中并行学习不同的关系,从而提升模型的表达能力。
5. 总结
通过上述过程,该模块实现了以下几个关键目标:
- 信息传播与聚合:通过注意力机制,将实体和其相关的三元组信息融合,从而获得更丰富的特征表示。
- 多模态信息融合:结构聚合模块通过图神经网络的思想,在不同模态间传播信息,使得最终的实体表示能够同时包含图像、文本和知识图谱等多方面的信息。
- 注意力机制:通过多头注意力和Softmax的计算,使得模型可以根据每个三元组的重要性来动态调整信息的聚合方式。
可能应用场景
该结构聚合模块特别适合于需要结合多种模态信息的任务,如:
- 假新闻检测:结合文本内容、图片以及知识图谱的背景知识来判断新闻的真实性。
- 跨模态检索:将图像、文本、和相关背景知识通过图神经网络聚合,提升跨模态检索的效果。
- 知识图谱补全:根据实体间的关系和属性,聚合信息以补全缺失的知识。
使用 LeakyReLU 非线性函数对三元组表示进行激活 什么意思
在神经网络中,LeakyReLU(Leaky Rectified Linear Unit) 是一种常见的非线性激活函数,它用于引入非线性变换,使得网络能够学习复杂的模式。理解这一过程的关键是如何通过该激活函数对三元组表示进行非线性激活。
激活函数的作用
激活函数的作用是使得神经网络能够捕捉到数据中的非线性关系。没有激活函数的神经网络实际上只能模拟线性关系,而现实世界中的许多问题通常都是非线性的。因此,我们需要激活函数来引入非线性特性,提升模型的表达能力。
LeakyReLU 激活函数
LeakyReLU 的数学表达式为:
L
e
a
k
y
R
e
L
U
(
x
)
=
{
x
,
if
x
≥
0
α
x
,
if
x
<
0
LeakyReLU(x) = \begin{cases} x, & \text{if } x \geq 0 \\ \alpha x, & \text{if } x < 0 \end{cases}
LeakyReLU(x)={x,αx,if x≥0if x<0
其中:
- x x x 是输入值, α \alpha α 是一个很小的常数(通常是 0.01)。
- 当输入值 x x x 大于等于零时,LeakyReLU 函数直接返回 x x x(即线性响应)。
- 当输入值 x x x 小于零时,LeakyReLU 会将输入乘以一个小的常数 α \alpha α,以避免神经元“死亡”(即输出为零)。
在三元组表示中的应用
在你提到的 三元组表示的激活 中,我们首先有三元组的表示 t x t_x tx,它通过拼接实体、属性和属性值进行计算得到。这个三元组的表示是一个线性向量,可能会包含正数和负数。接下来,我们通过 LeakyReLU 对这个三元组的表示进行 非线性激活。
具体来说,这里是如何操作的:
- 计算三元组的表示:首先,三元组 ⟨ e c , p r o p e r t y x , v a l u e x ⟩ \langle e_c, property_x, value_x \rangle ⟨ec,propertyx,valuex⟩ 通过线性变换得到其表示 t x t_x tx。
- 应用 LeakyReLU 激活:然后,LeakyReLU 激活函数应用于这个表示 t x t_x tx,以提高其在后续处理中捕捉非线性关系的能力。即使 t x t_x tx 中有负值,LeakyReLU 也会让这些负值保持一定的影响(通过 α t x \alpha t_x αtx)。这有助于避免完全丧失某些重要的特征信息。
公式:
b
x
=
L
e
a
k
y
R
e
L
U
(
W
2
t
x
)
b_x = LeakyReLU(W_2 t_x)
bx=LeakyReLU(W2tx)
- 这里, W 2 W_2 W2 是一个线性变换矩阵,用来进一步调整三元组的表示。
- b x b_x bx 是经过 LeakyReLU 激活后的三元组表示。
为什么使用 LeakyReLU?
- 避免“死神经元”问题:传统的 ReLU 函数会导致部分神经元在计算过程中永远输出零,从而无法学习。LeakyReLU 通过引入一个小的斜率 α \alpha α 来解决这个问题,即使在输入值小于零时也有微弱的梯度,避免了“死神经元”的情况。
- 提高模型的表达能力:LeakyReLU 能够增加神经网络的非线性,帮助模型学习更加复杂的关系。
总结
在结构聚合模块中,LeakyReLU 激活函数被用来增强三元组表示的非线性特征,从而提升模型的表达能力。在计算过程中,每个三元组表示 t x t_x tx 被激活成 b x b_x bx,并通过 LeakyReLU 处理后的激活值作为后续计算中的输入,帮助捕捉更加复杂的信息
Vit论文中是如何对图像进行编码的?
参考如下格式给我一段文字参考[7,9,10,12,13],我们将给定商品 e c e_c ec 的商品图片 i c i_c ic (像素矩阵)通过对象检测模型转换为对象序列。具体来说,参考ViLBERT [12],我们使用Faster R-CNN [35] 从 i c i_c ic 中检测出一系列对象(RoI,感兴趣区域),并将这些对象的边界框作为它们的位置信息。15%的对象随机掩码,如[12]所述。然后如图2所示,对象嵌入和位置嵌入的总和 [ E i 1 , E i 2 , . . . , E i M 1 ] [E_{i1}, E_{i2}, ..., E_{iM1}] [Ei1,Ei2,...,EiM1] 被输入到基于Transformer的图像编码器中,图像编码器输出图像的初始特征 [ h i 1 0 , h i 2 0 , . . . , h i M 1 0 ] [h_{i1}^0, h_{i2}^0, ..., h_{iM1}^0] [hi10,hi20,...,hiM10],其中 M 1 M_1 M1 是对象序列的最大长度。
我们将给定商品 e c e_c ec 的商品图片 i c i_c ic(像素矩阵)通过以下步骤进行编码。首先,图像 i c i_c ic 的大小为 H × W × 3 H \times W \times 3 H×W×3,我们将其划分为 N N N 个大小为 P × P P \times P P×P 的补丁,得到补丁序列 { p 1 , p 2 , . . . , p N } \{p_1, p_2, ..., p_N\} {p1,p2,...,pN}。每个补丁 p n p_n pn 的尺寸为 P × P × 3 P \times P \times 3 P×P×3,然后将其展平成一维向量 v n v_n vn,即每个补丁 v n v_n vn 的维度是 P 2 × 3 P^2 \times 3 P2×3。
接下来,我们通过一个线性变换将每个补丁展平后的向量 v n v_n vn 转换为固定维度空间中的嵌入表示 e n e_n en,即:
- e n ∈ R D e_n ∈ ℝ^D en∈RD
其中 D D D 是Transformer中的嵌入维度。为每个补丁添加位置编码 P E n PE_n PEn,得到最终的补丁表示 E n E_n En:
- E n = e n + P E n E_n = e_n + PE_n En=en+PEn
然后,所有补丁的嵌入表示 { E 1 , E 2 , . . . , E N } \{E_1, E_2, ..., E_N\} {E1,E2,...,EN} 被输入到Transformer编码器中,经过多层自注意力(Self-Attention)和前馈网络(Feed-Forward Network)后,生成每个补丁的最终表示 { h 1 L , h 2 L , . . . , h N L } \{h_1^L, h_2^L, ..., h_N^L\} {h1L,h2L,...,hNL},其中 L L L 是Transformer的层数。
通过这种方法,ViT将图像表示为一系列补丁的序列,并通过自注意力机制来捕捉图像的全局信息,最终形成图像的特征表示,用于后续任务(如图像分类、检测等)。
这样的描述可以直接展示出核心内容和过程。如果需要进一步简化或调整,请告诉我!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









