




一、String 类的 hashCode() 方法
1、源码
- 一个好的 hash 函数应该是这样的:为不相同的对象产生不相等的 hashCode 。
/**
* s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
*/
public int hashCode() {
// 获取缓存的 hash 值。
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
// 每个字符参与计算,确保 每个字符 都影响哈希值。
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
// 将首次计算得到的 哈希值 缓存到 hash 字段,避免重复计算。
hash = h;
}
return h;
}
分析:
- hash 值**默认**为 0 。以三个字母 “ABC” 来分析一下:
- 第一次循环完成 h=A (因为, hash 默认为 0)。
- 第二次循环完成 h= 31h+B= 31A+B = A*311 + B*310
- 第三次循环完成 h= 31h+C=31(31A+B)+C = A*312 + B*311 + C*310
2、哈希码 的 计算公式:

- String 的 hashCode() 通过多项式哈希算法,结合质数 31 的优化,高效生成唯一性较高的哈希码。
- 其缓存机制和不可变性设计提升了性能。
- 允许出现的哈希冲突通过 equals() 方法解决。
3、哈希函数 中的 乘数(Multiplier)
- 定义:
- 在哈希函数(如:多项式哈希)中,用于逐字符 迭代计算的固定数值。
- 如:Java String.hashCode() 使用 31 作为乘数。
- 作用:
- 将字符的贡献混合到哈希值中。
- 避免哈希冲突(通过质数特性减少周期性模式)。
4、哈希表 的 负载因子(Load Factor)
- 定义:
- 哈希表中已存储元素数量与哈希表容量的比值(负载因子 = 元素数量 / 容量)。
- 作用:
- 衡量哈希表的填充程度。
- 触发扩容的阈值(如:Java HashMap 默认负载因子为 0.75)。
- 示例:
- 若哈希表 容量为 16,负载因子为 0.75。
- 当元素数量达到 12(16 * 0.75)时,哈希表会扩容。
二、选 31 为 hashCode() 的乘数,是以下因素的综合结果
- 质数又称素数。
- 一个大于 1 的自然数,除了 1 和它自身外,不能被其它自然数整除的数叫做质数;
- 否则称为合数。
- 规定 1 既不是质数也不是合数。
- 《Effective Java》中文版,原书第 3 版的 46 页中的原话:
- 之所以选择 31 ,是因为它是一个奇素数。
- 质数特性:可减少 哈希冲突。
- 如果乘数是偶数,并且乘法溢出的话,信息就会丢失。因为,与 2 相乘等价于移位运算。
- 使用素数的好处并不很明显。但是,习惯上都使用素数来计算散列结果。
- 历史经验:实验验证其在常见场景中的有效性。
- 平衡设计:在哈希质量和计算成本之间取得最佳平衡。
- 数字 31 有个很好的特性,即:用移位和减法来代替 乘法,可以得到更好的 性能:
- 即:31 * i = (32-1) * i = 25 * i - i = (i << 5) - i。现在的 JVM 可以自动完成这种优化。
- 现代 CPU 的乘法指令已高度优化,直接使用 31 * x 与位运算差异不大。
- 尽管存在冲突的可能性,但 31 在绝大多数实际应用中表现优异。
- 因此,成为 Java 字符串哈希计算的经典选择。
1、详解 – 数学基础:质数的优势
1)、质数的特性
- 减少冲突:
- 质数(如:31)与其它数相乘时,结果更容易均匀分布,减少哈希碰撞的概率。
- 避免因子的干扰:
- 若选择非质数(如:32),其因子(如:2、4、8)可能导致某些字符的哈希贡献被“稀释”。
- 因子干扰 示例:
- 因子干扰:32 是 2 的幂(25),其因子为 2、4、8、16 等。
- 低位信息丢失:乘以 32 相当于左移 5 位,低位被清零。
- 这导致低 5 位始终为 0,不同字符的低位差异 被掩盖。
- 周期性模式:
- 若字符值存在偶奇规律,乘数 32 会放大偶数的贡献。
- 导致哈希值分布偏向偶数倍数,增加冲突概率。

- 无因子干扰 示例:
- 无公共因子:31 是质数,没有除 1 和自身外的因子,避免周期性抵消。
- 位混合效果:31 的二进制为11111,乘法操作混合高、低位信息,减少信息丢失:
- 这种操作保留了字符值的更多位信息。
- 均匀分布:质数的不可分性确保不同字符的贡献独立叠加,哈希值 更均匀。
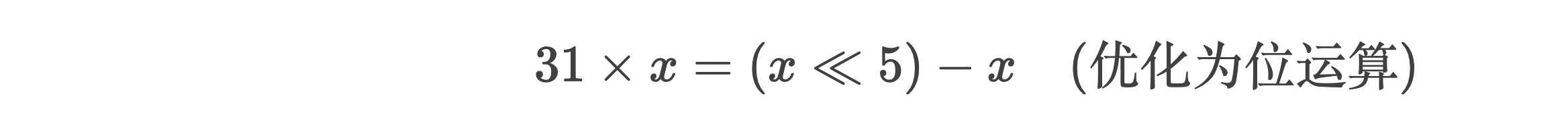
2)、为何不是更大的质数?
- 计算溢出:
- Java 的 int 类型为 32 位,较大的乘数(如: 101)会更快导致整数溢出,可能加剧哈希冲突。
- 性能折衷:
- 更大的质数需要更复杂的 乘法运算,而 31 的乘法可通过位运算优化。
2、详解 – 性能优化:位运算替代乘法
31 的乘法,可以进行位运算优化
- 31 可以分解为 25 - 1,因此乘法 31 * x 可转换为:
- 其中 << 是左移操作符。这种优化在早期处理器中比直接乘法更快。

// 传统乘法
int a = 31 * x;
// 优化为位运算
int a = (x << 5) - x; // 等效于 x * 31
3、详解 – 经验验证:哈希分布的实际效果
- 早期研究:
- 《Effective Java》和《Java 编程思想》等经典书籍中,31 被推荐为哈希计算的合理默认值。
- 实验数据:
- 通过对常见词汇和字符串的哈希分布测试,31 在冲突率和计算效率之间表现出较好的平衡。
4、详解 – 设计权衡:哈希质量与计算成本

5、详解 – 替代方案的局限性
1)、更大的质数(如 101、131)
- 优点:哈希分布更均匀。
- 缺点:
- 计算成本高(无法通过位运算优化)。
- 整数溢出更频繁,可能反向增加冲突。
2)、非质数(如 32、64)
- 优点:位运算优化更直接(如: 32 = 25 )。
- 缺点:
- 哈希分布不均匀(因子导致信息丢失)。
- 对特定字符模式敏感(如:全偶数 ASCII 码)。
三、计算哈希算法的冲突率 的 试验 及 数据分析
1、实验数据 以及 实验代码
- 数据是 Unix/Linux 平台中的**英文字典文件**,文件中有 235886 个单词。
- 文件路径为 /usr/share/dict/words。
- 将使用不同的数字作为乘子,对超过23万个英文单词进行哈希运算,并计算哈希算法的冲突率。
/**
*
* @author zhangxw
* @since 1.0.0
*/
public class StringHashCodeTest {
public static int hashCode(char[] value, int prim) {
int h = 0;
for (int i = 0; i < value.length; i++) {
h = prim * h + value[i];
}
return h;
}
/**
* 计算 hash code 冲突率,顺便分析一下 hash code 最大值和最小值,并输出
*/
public static void calculateConflictRate(Integer multiplier, List<Integer> hashes) {
Comparator<Integer> cp = (x, y) -> x > y ? 1 : (x < y ? -1 : 0);
int maxHash = hashes.stream().max(cp).get();
int minHash = hashes.stream().min(cp).get();
// 计算冲突数及冲突率
int uniqueHashNum = (int) hashes.stream().distinct().count();
int conflictNum = hashes.size() - uniqueHashNum;
double conflictRate = (conflictNum * 1.0) / hashes.size();
System.out.println(String.format("multiplier=%4d, minHash=%11d, maxHash=%10d, conflictNum=%6d, conflictRate=%.4f%%",
multiplier, minHash, maxHash, conflictNum, conflictRate * 100));
}
/**
* 将整个哈希空间等分成64份,统计每个空间内的哈希值数量
*
* @param hashs
*/
public static Map<Integer, Integer> partition(List<Integer> hashs) {
// step = 2^32 / 64 = 2^26
final int step = 67108864;
List<Integer> nums = new ArrayList<>();
Map<Integer, Integer> statistics = new LinkedHashMap<>();
int start = 0;
for (long i = Integer.MIN_VALUE; i <= Integer.MAX_VALUE; i += step) {
final long min = i;
final long max = min + step;
int num = (int) hashs.parallelStream()
.filter(x -> x >= min && x < max).count();
statistics.put(start++, num);
nums.add(num);
}
// 为了防止计算出错,这里验证一下
int hashNum = nums.stream().reduce((x, y) -> x + y).get();
assert hashNum == hashs.size();
return statistics;
}
public static void main(String[] args) throws IOException {
List<String> list = new ArrayList<>(235886);
URL url = StringHashCodeTest.class.getClassLoader().getResource("words.txt");
Reader reader = new FileReader(url.getFile());
BufferedReader bufferedReader = new BufferedReader(reader);
String string;
while ((string = bufferedReader.readLine()) != null) {
list.add(string);
}
bufferedReader.close();
reader.close();
args = new String[]{"2","3","5","7","17","31","32","33","36","37","41","47","101","199"};
for (String arg : args) {
int prim = Integer.parseInt(arg);
List<Integer> result = new ArrayList<>();
for (String s : list) {
result.add(hashCode(s.toCharArray(), prim));
}
calculateConflictRate(prim, result);
System.out.println();
// 输出分布区域
Map<Integer, Integer> map = partition(result);
for (Integer key : map.keySet()){
System.out.println(/*key + "\t" + */map.get(key));
}
System.out.println();
}
}
}
结果:

结论分析:
- 使用较小的质数做为乘子时,冲突率会很高。尤其是质数 2,冲突率达到了 55.14%。
- 使用 31、33、37、39、41、101、199 做为乘子时,算出的哈希值冲突数都小于 7 个。
2、哈希值分布可视化
- int 类型 的数值区间是 [-2147483648, 2147483647],区间大小为 232。
- 所以,将整个 哈希空间 等分成 64 份,每个自子区间大小为 226。
- 统计 每个空间 内的哈希值数量,详细的分区对照表如下:
| 分区编号 | 分区下限 | 分区上限 | 分区编号 | 分区下限 | 分区上限 |
|---|---|---|---|---|---|
| 0 | -2147483648 | -2080374784 | 32 | 0 | 67108864 |
| 1 | -2080374784 | -2013265920 | 33 | 67108864 | 134217728 |
| 2 | -2013265920 | -1946157056 | 34 | 134217728 | 201326592 |
| 3 | -1946157056 | -1879048192 | 35 | 201326592 | 268435456 |
| 4 | -1879048192 | -1811939328 | 36 | 268435456 | 335544320 |
| 5 | -1811939328 | -1744830464 | 37 | 335544320 | 402653184 |
| 6 | -1744830464 | -1677721600 | 38 | 402653184 | 469762048 |
| 7 | -1677721600 | -1610612736 | 39 | 469762048 | 536870912 |
| 8 | -1610612736 | -1543503872 | 40 | 536870912 | 603979776 |
| 9 | -1543503872 | -1476395008 | 41 | 603979776 | 671088640 |
| 10 | -1476395008 | -1409286144 | 42 | 671088640 | 738197504 |
| 11 | -1409286144 | -1342177280 | 43 | 738197504 | 805306368 |
| 12 | -1342177280 | -1275068416 | 44 | 805306368 | 872415232 |
| 13 | -1275068416 | -1207959552 | 45 | 872415232 | 939524096 |
| 14 | -1207959552 | -1140850688 | 46 | 939524096 | 1006632960 |
| 15 | -1140850688 | -1073741824 | 47 | 1006632960 | 1073741824 |
| 16 | -1073741824 | -1006632960 | 48 | 1073741824 | 1140850688 |
| 17 | -1006632960 | -939524096 | 49 | 1140850688 | 1207959552 |
| 18 | -939524096 | -872415232 | 50 | 1207959552 | 1275068416 |
| 19 | -872415232 | -805306368 | 51 | 1275068416 | 1342177280 |
| 20 | -805306368 | -738197504 | 52 | 1342177280 | 1409286144 |
| 21 | -738197504 | -671088640 | 53 | 1409286144 | 1476395008 |
| 22 | -671088640 | -603979776 | 54 | 1476395008 | 1543503872 |
| 23 | -603979776 | -536870912 | 55 | 1543503872 | 1610612736 |
| 24 | -536870912 | -469762048 | 56 | 1610612736 | 1677721600 |
| 25 | -469762048 | -402653184 | 57 | 1677721600 | 1744830464 |
| 26 | -402653184 | -335544320 | 58 | 1744830464 | 1811939328 |
| 27 | -335544320 | -268435456 | 59 | 1811939328 | 1879048192 |
| 28 | -268435456 | -201326592 | 60 | 1879048192 | 1946157056 |
| 29 | -201326592 | -134217728 | 61 | 1946157056 | 2013265920 |
| 30 | -134217728 | -67108864 | 62 | 2013265920 | 2080374784 |
| 31 | -67108864 | 0 | 63 | 2080374784 | 2147483648 |
- 对数字 2、3、17、31、101 的散点曲线图进行简单的分析。先从数字 2 开始,数字 2 对于的散点曲线图如下:

- 上面的图还是很一幕了然的,乘子 2 算出的哈希值几乎全部落在第32分区,也就是 [0, 67108864)数值区间内,落在其他区间内的哈希值数量几乎可以忽略不计。
- 这也就不难解释为什么数字2作为乘子时,算出哈希值的冲突率如此之高的原因了。

- 3 作为乘子时,算出的哈希值分布情况和 2 很像,只不过稍微好了那么一点点。从图中可以看出绝大部分的哈希值最终都落在了第32分区里,哈希值的分布性很差。

- 数字 17 作为乘子时的表现,明显比上面两个数字好点了。
- 虽然哈希值在第32分区和第34分区有一定的聚集,但是相比较上面2和3,情况明显好好了很多。除此之外,17作为乘子算出的哈希值在其他区也均有分布,且较为均匀,还算是一个不错的乘子吧。

- 31 作为乘子算出的哈希值在第 33 分区有一定的小聚集。不过相比于数字 17,数字 31 的表现又好了一些。
- 首先,是哈希值的聚集程度没有 17 那么严重,其次哈希值在其他区分布的情况也要好于 17。
- 总之,选 31,准没错啊。

- 再看看大质数 101 的表现,不难看出,质数 101 作为乘子时,算出的哈希值分布情况要好于主角 31,有点喧宾夺主的意思。不过不可否认的是,质数 101 的作为乘子时,哈希值的分布性确实更加均匀。
- 所以,如果不在意质数 101 容易导致数据信息丢失问题,或许其是一个更好的选择。

- 乘数是 199 是不能用的散列结果,但是它的数据是更加分散的,从图上能看到有两个小山包。
- 由于 hashcode 会超出 int 的表示范围,会导致一部分位数据丢失问题,所以,不能选择。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









