




- 字符串 操作 是计算机程序设计中 最常见的 行为 。
- 人们之间的 语言交流 都可归属于 字符串 的 范畴。
一、String 类
1、概念
- 从概念上讲,Java 字符串 就是 Unicode 字符序列。
- 如:字符串 “Java\u2122” 由 5 个 Unicode 字符 ‘J’、‘a’、‘v’、‘a’、'™' 组成。
- Java 没有内置的字符串类型,而是 标准 Java 类库 中提供了一个预定义类。
- 很自然地叫作 String 。
- 每个用双引号括起来的字符串都是 String 类的一个实例。
String e = ""; // an empty string
String greeting = "Hello";
2、空串、null 串、空格字符串
- 空串(“”):是长度为 0 的字符串。
- 空串是一个 java 对象,有自己的 串长度 (0) 和 内容 (没有内容)。
String emptyStr = "";
- null 串:String 变量的值为 null 。
- 表示目前没有任何对象与该变量关联。
String nullStr = null;
- 空格字符串:
- String 变量的值为一个或多个空格组成的字符串。
String blankStr = " ";
3、字符串工具类 isEmpty 和 isBlank 的区别
- StringUtils.isEmpty(String str):判断某字符串为 null 或 “” 。
- 但是,空格组成的字符串不为 empty !

- StringUtils.isBlank(String str):判断字符串为 null 或 由空格组成。
- Blank 【空白、空格、空白的】




4、文本块
- Java 15 新增的文本块 (text block) 特性,可以很容易地提供 跨多行 的字符串字面量。
- 示例
// 文本块
String greeting = """
Hello
world !!!
""";
// 文本块比相应的字符串字面量更易于读写:
String greeting = "Hello\nWorld !!!\n";
// 如果不想要最后一行后面的换行符,可以让结束 """ 紧跟在最后一个字符后面:
String greeting = """
Hello
world !!!""";
// 文本块特别适合包含用其他语言编写的代码,如 SQL 或 HTML 。
// 可以直接将那些代码粘贴到一对三重引号之间:
String html = """
<div class="Warning">
Beware of those who say "Hello" to the world
</div>
""";
// 在文本块中,可以在行尾添加 / 会把这一行与下一行连接起来.
String greeting = """
Hello \
world !!!""";
// 等同于
String greeting = "Hello world !!!";
- 注意:如果一个文本块中 包含非 Java 代码,实际上最好 沿左边界放置。
- 这样可以与 Java 代码区分开,而且可以为长代码行留出更多空间。
二、String 的不可变性
1、String 类的不可继承性
- String 不能被继承,使用了 final 修饰。
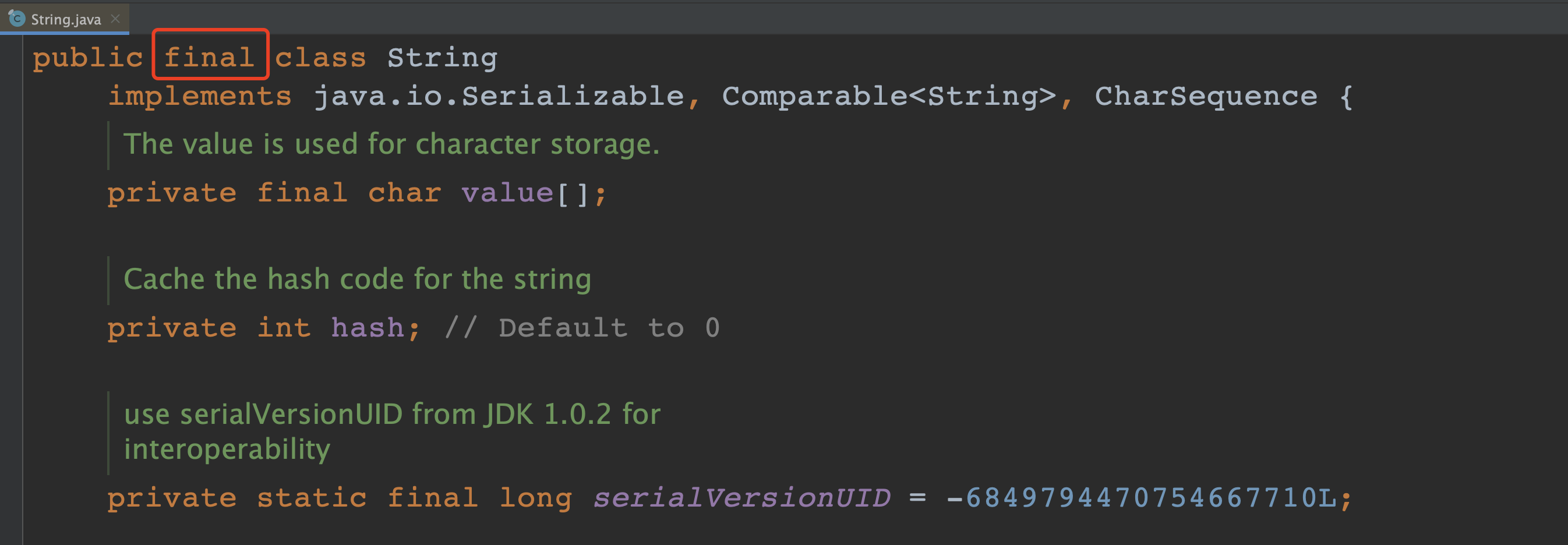
- 联想到 基本数据类型的包装类 以及 记录(Record)类。
2、String 内部存储结构的不可变性
- String 用 private final char value[] (Java 9 开始,改成 byte value[])来 实现字符串的 存储。
- 用 final 关键字修饰该数组。这确保了数组引用 不可变。

- String 类没有提供任何可以修改内部 数组 的公共方法。
- 所有看似修改 字符串的方法都会返回一个新的 String 对象,而不是修改原对象。
- 如:concat()、replace()、substring()、toUpperCase() 等。
- 因此,String 对象创建之后,就不能再修改此对象中存储的字符串内容 。
- 所以,String 对象的 hashcode 可以被缓存。
3、String 不可变性 的 优点
1、安全性
- 字符串广泛用于敏感信息(如:文件路径、URL、密码等)。
- 如果字符串可变,可能被恶意修改,导致安全漏洞。
- 示例:
- String 作为方法的参数传递时,不可变性确保了参数值不会被意外修改。
2、线程安全
- 不可变对象天生是线程安全的,无需同步。
- 多个线程可以安全地共享同一个 String 对象。
3、字符串常量池(String Pool)优化
- Java 使用字符串常量池来重用字符串字面量(如:“abc”)。
- 不可变性确保了不同的 字符串变量可以安全地共享池中的同一实例,减少内存开销。
- 示例:
- String s1 = “abc”; String s2 = “abc”;。
- s1 和 s2 指向字符串常量池中的同一个对象。
4、哈希值缓存
- String 的哈希值(hashCode())在第一次计算后会被缓存。
- 由于字符串不可变,后续调用 hashCode() 直接返回缓存值,提高了效率。
- 尤其在作为 HashMap 的键时。
5、作为键的可靠性
- String 常用于 HashMap 的键。
- 不可变性保证了键的哈希值在存入后不会改变,确保键值对的正确性。
4、String 不可变性 的 缺点
- 如果,需要频繁修改字符串(如:循环拼接),会产生大量中间对象。
- 此时,应使用 StringBuilder 或 StringBuffer(可变字符序列)。
5、通过 反射 来破坏 String 内部存储结构的不可变性
- 注意:
- 可通过反射修改 String 中 char[] 数组的引用 以及 char[] 数组中存储的内容。
String s = "Hello";
System.out.println(s);
System.out.println(System.identityHashCode(s));
// 可以通过反射修改 String 中 char[] 数组的引用。
Class clazz = s.getClass();
// 1556956098
Field valueField = clazz.getDeclaredField("value");
valueField.setAccessible(true);
System.out.println(Arrays.toString((char[])valueField.get(s)));
valueField.set(s, new char[]{'w','o','r','l','d'});
System.out.println(s);
// 1556956098
System.out.println(System.identityHashCode(s));
6、在 Java 中,验证两个对象是否是同一个对象的方法:
- 方法 1:使用 == 判断两个对象的引用,是否指向同一个内存地址。
- 方法 2:通过比较两个对象的 System.identityHashCode() 是否相等。
- 大多数 JVM 实现(如:HotSpot)会基于对象的内存地址计算哈希码。
- 如:通过位移或哈希函数处理对象的内存地址。
- 但哈希码不是 直接的内存地址,而是 JVM 内部生成的一个唯一标识符。
// 示例:字符串拼接实际上是创建新对象
String s = "Hello";
System.out.println(s);
// 旧字符串的哈希码
int oldHash = System.identityHashCode(s);
// 新对象 "Hello World",原对象 "Hello" 不变
String s0 = s.concat(" World");
// 新字符串的哈希码
int newHash = System.identityHashCode(s0);
// 输出结果为:false
// 表明 s0 是与 s 不同的【新对象】。
System.out.println(s == s0);
// 输出结果为:false
// 表明 s0 是与 s 不同的【新对象】。
System.out.println(oldHash == newHash);
String s2 = s.toUpperCase(); // 新对象 "HELLO"
System.out.println(s2); // 输出 "Hello"(表明:原对象未变)
三、String 有没有长度限制?是多少?
String 的长度是有限制的。
- 1、编译期:
- 字符串字面量的字符个数必须小于 65535 且 字符串字面量 存储能占用的最大字节数为 65535。
- 2、运行期:
- 受到物理内存大小 以及 JVM 对数组长度额外约束。
1、编译时的字符串字面量长度的限制 – 限制一
- 字符串字面量(如:“Hello”)会被存储在字节码文件的常量池中。
- 它对应的数据结构 CONSTANT_Utf8_info 使用 16 位无符号整数(u2)表示字符串的字节长度。
- 因此,字符串字面量被允许的最大字节数为 65535。
// CONSTANT_Utf8 的数据结构
CONSTANT_Utf8_info {
u1 tag;
u2 length; // 存储 字符串字面量 的 字节数组 的长度。
// 数据类型为 16 位无符号整数(即:u2)最大字节数为 65535。
u1 bytes[length]; // 存储 字符串字面量 的 字节数组。
}
- 验证:
- 结果,长度为 65535 的字符串 s 还是编译失败了。
// 65535 个 d,编译报错
String s = "dd..dd";
// 65534 个 d,编译通过
String s1 = "dd..d";
// 一个英文字母 d 加上 21845 个中文”自“,编译失败。
// 在 UTF-8 编码中,一个中文,占用 3 个字节。一个字母 d 的 UTF8 编码占用一个字节。
// 一个英文字母 d 加上 21845 个中文”自“占用 【65536 个字节】,超过了存储最大限制,编译失败。
String s3 = "d自自...自";
2、编译时的字符串字面量长度的限制 – 限制二
- 在 javac 编译器的额外限制。在 Javac 的源代码中可以找到以下代码:
// 当参数类型为 String,并且 字符串字面量 的 长度 大于等于 65535 时,会导致编译失败。
private void checkStringConstant(DiagnosticPosition var1, Object var2) {
if (this.nerrs == 0 && var2 != null && var2 instanceof String
&& ((String)var2).length() >= 65535) {
this.log.error(var1, "limit.string", new Object[0]);
++this.nerrs;
}
}
- 验证:
// 65534 个字母,编译通过
// 一个字母 d 的 UTF8 编码占用一个字节,65534 字母占用 65534 个字节,长度是 65534。
// 此时,长度和存储都没超过限制,所以可以编译通过。
String s1 = "dd..d";
// 21845 个中文”自“,编译通过
// 在 UTF-8 编码中,一个中文,占用 3 个字节。一个字母 d 的 UTF8 编码占用一个字节。
// 21845 个中文”自“正好占用 65535 个字节,而且字符串长度是 21845。
// 此时,长度和存储也都没超过限制,所以可以编译通过。
String s2 = "自自...自";
// 一个英文字母 d 加上 21845 个中文”自“,编译失败。
// 在 UTF-8 编码中,一个中文,占用 3 个字节。一个字母 d 的 UTF8 编码占用一个字节。
// 一个英文字母 d 加上 21845 个中文”自“占用 【65536 个字节】,超过了存储最大限制,编译失败。
String s3 = "d自自...自";
3、运行时的字符串长度限制 – 限制一
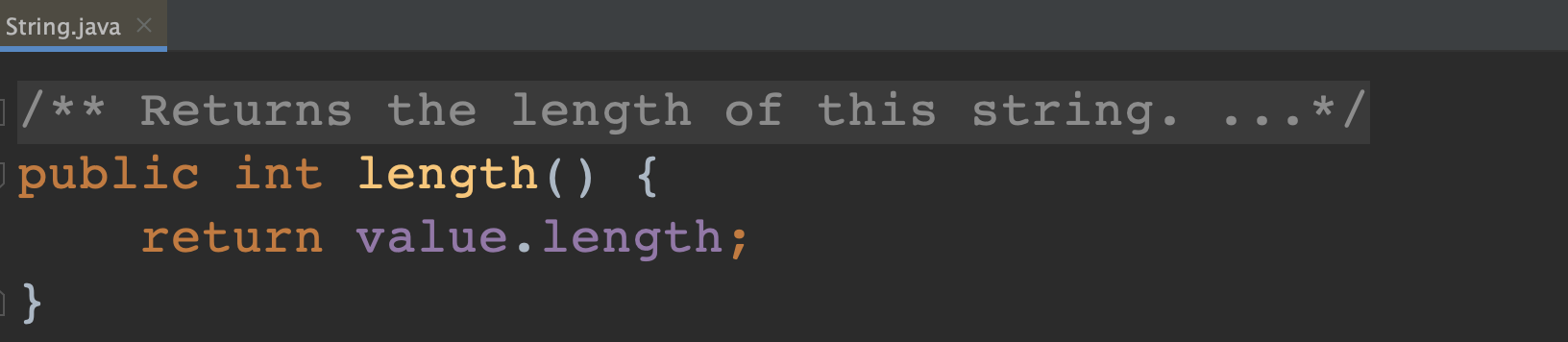
- 受 String 类中 字符串长度 的 数据类型 为 int 的限制。
- 因此,字符串中理论最大 字符个数 为 Integer.MAX_VALUE(231 - 1,约 21 亿个)。
4、运行时的字符串长度限制 – 限制二
- 1、内存限制:创建超长字符串需要连续内存分配。
- 当 JVM 堆内存不足或存在内存碎片时,抛出 OutOfMemoryError: Java heap space 。
- 如:Java 8 的 char[] :每个字符占 2 字节,总内存为 2 * 2^31 ≈ 4 GB 。
- 如:Java 9+ 的 byte[] (Latin-1 编码):总内存为 1 * 2^31 ≈ 2 GB 。
- 2、 JVM 实现限制:部分 JVM 可能对数组长度有额外约束。
- HotSpot 虚拟机对 数组长度 的实际限制为 Integer.MAX_VALUE - 8。
- 某些版本为 Integer.MAX_VALUE - 2。
- 因为,数组对象头(Header)需要占用部分内存。
四、Java9 对 String 类的优化 – Compact Strings(紧凑字符串)
- 优化的目标:
- 减少内存占用 并提升性能,尤其是在处理大量字符串的场景中。
- 优化前后的对比示例:字符串 “Hello” 。
- 在 Java 9+ 中仅占用 5 字节(Latin-1 编码),而 Java 8 需要 10 字节(UTF-16 编码)。
// Java 8 中:[0, 104, 0, 101, 0, 108, 0, 108, 0, 111]
System.out.println(Arrays.toString("hello".getBytes()));
// Java 9 中:[104, 101, 108, 108, 111]
System.out.println(Arrays.toString("hello".getBytes()));
1、Java 8 及之前:
- String 内部用 char[](字符数组)存储数据,每个字符占用 2 字节(UTF-16 编码)。
- 当字符串仅包含单字节字符(如:“Hello”)时,就会存在内存浪费。
2、Java 9+:
- 优化:
- 改用 byte[] (字节数组)存储数据,并引入 coder 标志位(1 字节)标识编码方式。
- 原理:
- 在创建字符串时,自动检测 每个字符编码 。然后,选择合适的编码方式。
- 具体实现:
- 若所有字符均在 Latin-1 范围内( 0x00~0xFF ),使用 Latin-1 编码(即: coder=0 )。
- 如:‘A’、‘a’、‘1’ 等 单字节字符。。
- 若有字符****超出 Latin-1 的范围,就使用 UTF-16 编码(即:coder=1)。
- 如 ‘€’ 、中文、Emoji 等 多字节字符。
- 注意:
- Latin-1 编码,也被称为 ISO-8859-1 编码。
3、带来的问题:
- 在 UTF-16 编码 下,当 char[] 和 byte[] 的底层数组均达到最大长度时。
- char[] 可存储的字符数是 byte[] 的 2 倍。
- 因为,byte[] 需用 2 个元素存储一个 UTF-16 字符,而 char[] 仅需 1 个元素。
五、String 的操作
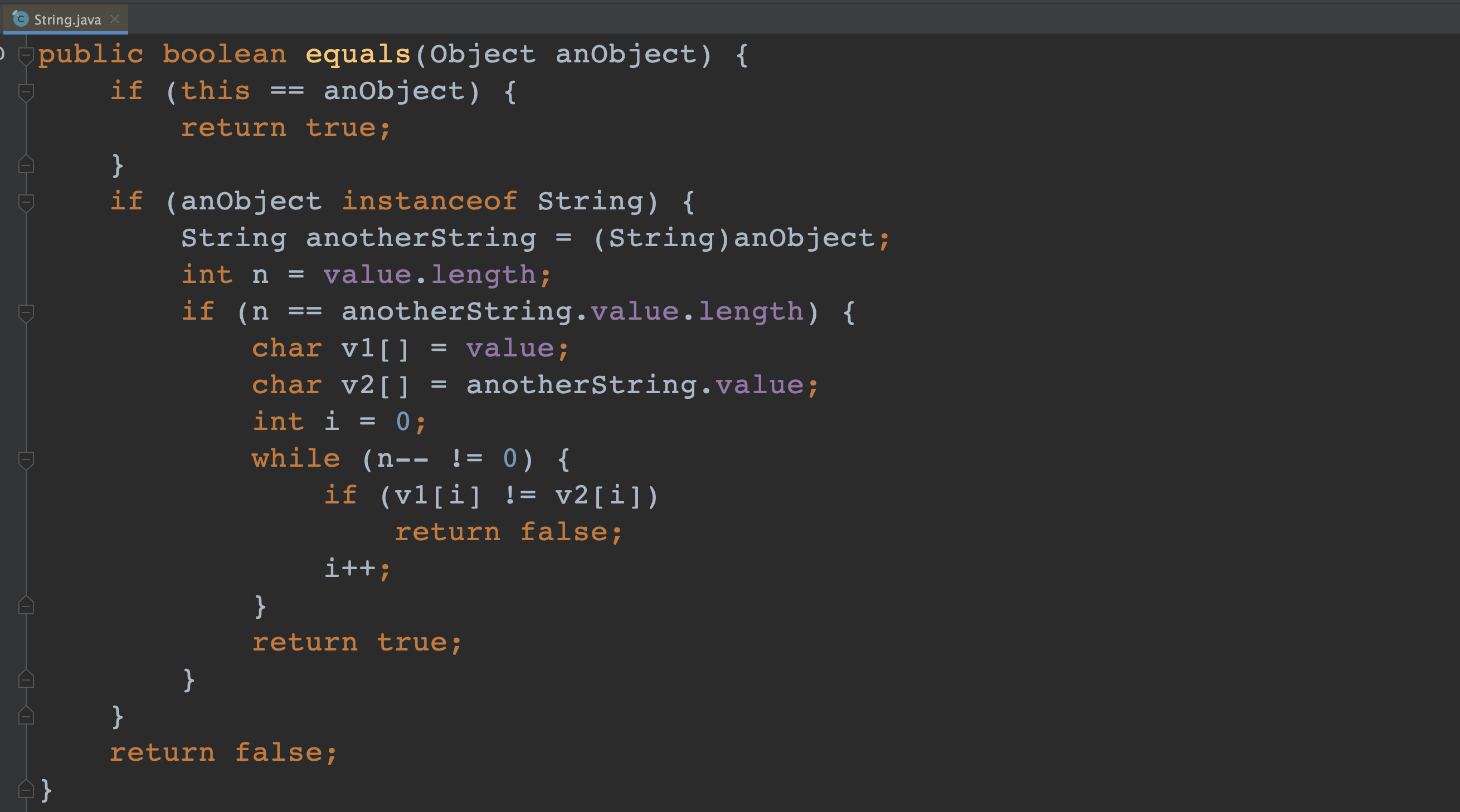
1、String.equals() 与 Object.equals() 的对比
- Object 的 equals 方法:使用的 == 实现的,比较的是两个对象的引用是否相等。

- String 的 equals 方法:
- 1、先使用的 == 比较的是两个对象的引用是否相等。
- 2、当两个对象的引用 不相等时,再比较两个字符串的内容是否相等。
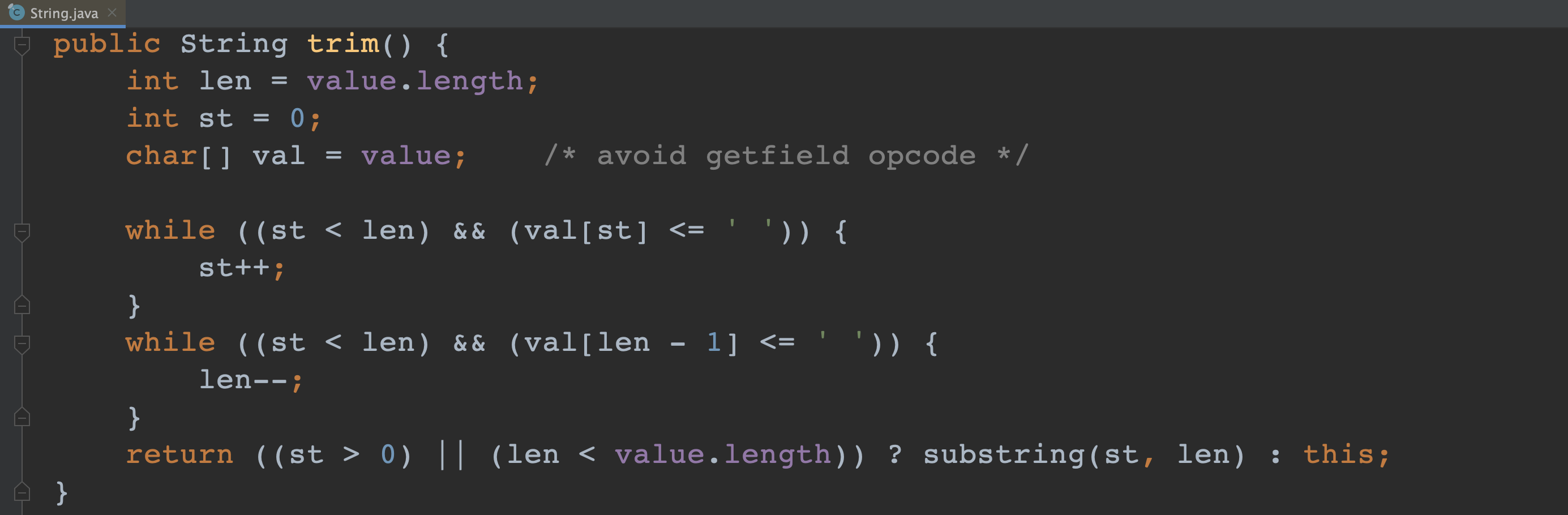
2、String 类的 trim() 方法
- 去除字符串前后两端的空格
3、String 与 byte[] 之间如何转换?
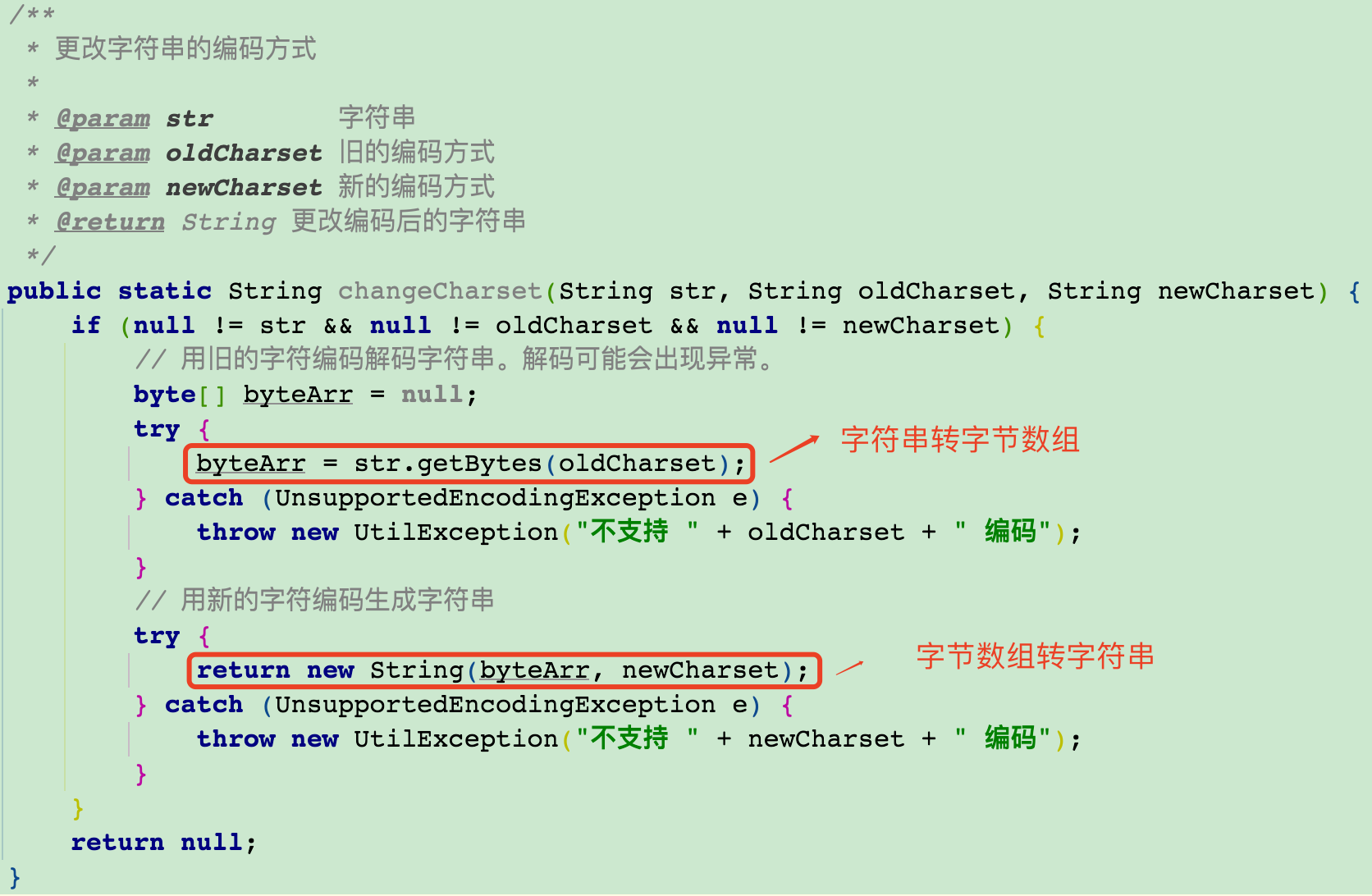
4、String 字符串 的 编码转换
- 方式一:
- 通过 CharsetEncoder 和 CharsetDecoder 实现任意编码间 的转换。
- 如:UTF-8 ↔ GBK 。
package org.rainlotus.materials.javabase.a01_unicode;
import java.nio.ByteBuffer;
import java.nio.CharBuffer;
import java.nio.charset.*;
import java.util.Arrays;
/**
* CharsetEncoder:将字符(CharBuffer)编码为字节(ByteBuffer)。
* CharsetDecoder:将字节(ByteBuffer)解码为字符(CharBuffer)。
* 适用场景:需要精确控制编码/解码过程(如错误处理策略、批量转换)。
*
* @author zhangxw
*/
public class CharsetEncoderAndDecoder {
public static void main(String[] args) throws CharacterCodingException {
// 定义字符集(以 UTF-8 为例)
Charset charset = StandardCharsets.UTF_8;
// 示例字符串(含无法用 ISO-8859-1 编码的中文字符)
String originalText = "Hello 你好 😊";
// ------------------------- 编码示例 -------------------------
// 创建编码器,并设置错误处理策略:替换不可编码字符为 '?'
CharsetEncoder encoder = charset.newEncoder()
.onUnmappableCharacter(CodingErrorAction.REPLACE)
.replaceWith("?".getBytes());
// 将字符串转换为 CharBuffer
CharBuffer charBuffer = CharBuffer.wrap(originalText);
// 编码为 ByteBuffer
ByteBuffer byteBuffer = encoder.encode(charBuffer);
// 提取字节数组
byte[] encodedBytes = new byte[byteBuffer.limit()];
byteBuffer.get(encodedBytes);
// 编码后的字节数组: [72, 101, 108, 108, 111, 32, -28, -67, -96, -27, -91, -67, 32, -16, -97, -104, -118]
System.out.println("编码后的字节数组: " + Arrays.toString(encodedBytes));
// ------------------------- 解码示例 -------------------------
// 创建解码器,并设置错误处理策略:忽略无效字节
CharsetDecoder decoder = charset.newDecoder()
.onMalformedInput(CodingErrorAction.IGNORE)
.onUnmappableCharacter(CodingErrorAction.REPLACE);
// 将字节数组包装为 ByteBuffer
ByteBuffer inputBuffer = ByteBuffer.wrap(encodedBytes);
// 解码为 CharBuffer
CharBuffer decodedBuffer = decoder.decode(inputBuffer);
// 转换为字符串
String decodedText = decodedBuffer.toString();
// 解码后的字符串: Hello 你好 😊
System.out.println("解码后的字符串: " + decodedText);
System.out.println("\n\n");
// 直接编码(无法自定义错误策略)
byte[] bytes = originalText.getBytes(StandardCharsets.UTF_8);
// 编码后的字节数组: [72, 101, 108, 108, 111, 32, -28, -67, -96, -27, -91, -67, 32, -16, -97, -104, -118]
System.out.println("编码后的字节数组: " + Arrays.toString(bytes));
// 直接解码(默认使用 REPLACE 策略)
String text = new String(bytes, StandardCharsets.UTF_8);
// 解码后的字符串: Hello 你好 😊
System.out.println("解码后的字符串: " + text);
}
}
- 方式二:
- 使用 String.getBytes(charset) 和 new String(bytes, charset) 。
- 但无法精细控制错误处理。
new String(str.getBytes(oldCharset), newCharset);
- 默认编码适配:
- System.getProperty(“file.encoding”) 获取平台默认编码。
- 建议显式指定 编码 以增强可移植性。
5、从字符串中提取子串
- 字符串中,字符的位置是从 0 开始编号 的。
1、substring 方法
- 可以从一个较大的字符串提取出一个子串。
String greeting = "Hello";
// 会创建一个由字符 "Hel" 组成的字符串。
String subStr = greeting.substring(0, 3);
// Hel
System.out.println(subStr);
String sub1 = s.substring(1);
// ello
System.out.println(subStr);
- 提取子串时,两个参数构成了一个 左闭右开 的区间。
- 即:子串中的字符,包含字符串中左侧位置编号的字符,但不包含右侧位置编号的字符。
- 如果只有一个参数时,就从参数位置提取到最后一个字符串。区间为:[参数, 字符串长度)。
- 这样做的优点:
- 很容易计算子串的长度(即:第二个参数 减去 第一个参数)。
- 通过 indexOf 和 substring 这两个方法实现字符串分割.
String str = "id1/Riven/12346789999";
// id1
System.out.println(str.substring(0, str.indexOf("/")));
2、charAt 方法
- 通过 charAt 方法实现字符串分割【效率最高】。
String str = "Hello";
char ch = str.charAt(1); // 获取索引为 1 的字符,即 'e'
3、StringTokenizer(在 Java 引入正则表达式之前用)
- 通过 StringTokenizer 对字符串进行分割【效率比使用 正则表达式的 split 更高】
String data = "apple,banana;grape";
// 使用逗号和分号分割
StringTokenizer tokenizer = new StringTokenizer(data, ",;");
while (tokenizer.hasMoreTokens()) {
System.out.println(tokenizer.nextToken());
}
// 输出:apple banana grape
String s = "Hello World";
// "ello World"
String sub1 = s.substring(1);
// "lo W"
String sub2 = s.substring(3, 7);
4、split()
- 通过 java 自带的 split 方法分割字符串【效率与 indexOf 差不多】
String str = "id1/Riven/12346789999";
// [id1, Riven, 12346789999]
System.out.println(Arrays.toString(str.split("/")));
6、String 的拼接
1、字符串拼接符(+)
- Java 语言允许使用 +(字符串拼接符)来 连接/拼接 两个字符串。
String str = "a";
for( int i = 0; i < 10000 ; i++ ) {
str = str + i;
}
return str;
// 编译器优化后的 class 被反编译为:
String str = "a";
for( int i = 0; i < 10000 ; i++ ) {
str = new StringBuilder().append(str).append(i).toString();
}
return str;
- 当将一个字符串与一个非字符串的值进行拼接时,后者会转换成字符串。
- 注意:
- 任何一个 Java 对象都可以转换成字符串 。
int age = 13;
String rating = "PG" + age;
// PG13
System.out.println(rating);
Object obj = new Object();
String ratingObjStr = rating + obj;
// PG13java.lang.Object@7921b0a2
System.out.println(ratingObjStr);
2、concat 方法
- 每次都创建一个跟字符串长度一样的 char 数组。将 char 数组创建一个 String 对象。
// aaabbb
System.out.println("aaa".concat("bbb"));
3、StringBuilder、StringBuffer
- StringBuffer: 是线程安全的;
- StringBuilder:是线程不安全的,性能高点,推荐使 StringBuilder;(jdk1.5 出现)
public String add(String str1, String str2){
StringBuffer buffer = new StringBuffer();
buffer.append(str1).append(str2);
return buffer.toString();
}
- 初始容量 16,当扩容时:新容量 = 原来容量 * 2 + 2 。
public StringBuilder() { super(16); }
public StringBuilder(String str) { super(str.length() + 16); append(str); }
public StringBuffer() { super(16); }
public StringBuffer(String str) { super(str.length() + 16); append(str); }
// 扩容
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}
// 确保内部容量
private void ensureCapacityInternal(int minimumCapacity) {
// overflow-conscious code
if (minimumCapacity - value.length > 0) {
value = Arrays.copyOf(value,
newCapacity(minimumCapacity));
}
}
// 扩容
private int newCapacity(int minCapacity) {
// overflow-conscious code
// 新容量 = 原来容量 * 2 + 2
int newCapacity = (value.length << 1) + 2;
if (newCapacity - minCapacity < 0) {
newCapacity = minCapacity;
}
return (newCapacity <= 0 || MAX_ARRAY_SIZE - newCapacity < 0)
? hugeCapacity(minCapacity)
: newCapacity;
}
4、StringJoiner
- StringJoiner 用于构造由分隔符分隔的字符序列 。
- 并且可以选择以提供的前缀开头并以提供的后缀结尾。
StringJoiner sj = new StringJoiner(":", "[", "]");
sj.add("George").add("Sally").add("Fred");
String desiredString = sj.toString();
// 结果:[George:Sally:Fred]
5、join 方法。
String all = String.join(" / ", "S", "M", "L", "XL");
// S / M / L / XL
System.out.println(all);
6、java 11 中的 repeat 方法
String repeated = "Java".repeat(3);
// JavaJavaJava
System.out.println(repeated);
7、String 字符串如何进行反转?
1、使用 StringBuilder 或 StringBuffer
- StringBuilder 和 StringBuffer 提供了 reverse() 方法,可以直接反转字符串。
- 推荐此方法,因为它简洁高效。
String original = "Hello, World!";
String reversed = new StringBuilder(original).reverse().toString();
System.out.println(reversed); // 输出 "!dlroW ,olleH"
2、手动操作字符数组(双指针法)
- 将字符串转换为字符数组,通过交换首尾字符实现反转。
String original = "Hello";
char[] chars = original.toCharArray();
int left = 0;
int right = chars.length - 1;
while (left < right) {
// 交换首尾字符
char temp = chars[left];
chars[left] = chars[right];
chars[right] = temp;
left++;
right--;
}
String reversed = new String(chars);
System.out.println(reversed); // 输出 "olleH"
3、递归反转
- 通过递归逐层截取末尾字符并拼接(实际不推荐,效率低且可能栈溢出)。
public static String reverseRecursively(String str) {
if (str.isEmpty() || str.length() == 1) {
return str;
}
// 取最后一个字符 + 递归处理剩余部分
return reverseRecursively(str.substring(1)) + str.charAt(0);
}
String reversed = reverseRecursively("Hello");
System.out.println(reversed); // 输出 "olleH"
4、Java 8 流式 API
- 使用 Stream 的 使用 的 collect 和 StringBuilder 反转.
- 复杂但展示函数式编程。
String reversed = original.chars()
.mapToObj(c -> (char) c)
.collect(StringBuilder::new, (sb, c) -> sb.insert(0, c), StringBuilder::append)
.toString();

















 5255
5255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









