



聚焦爬虫代码执行流程
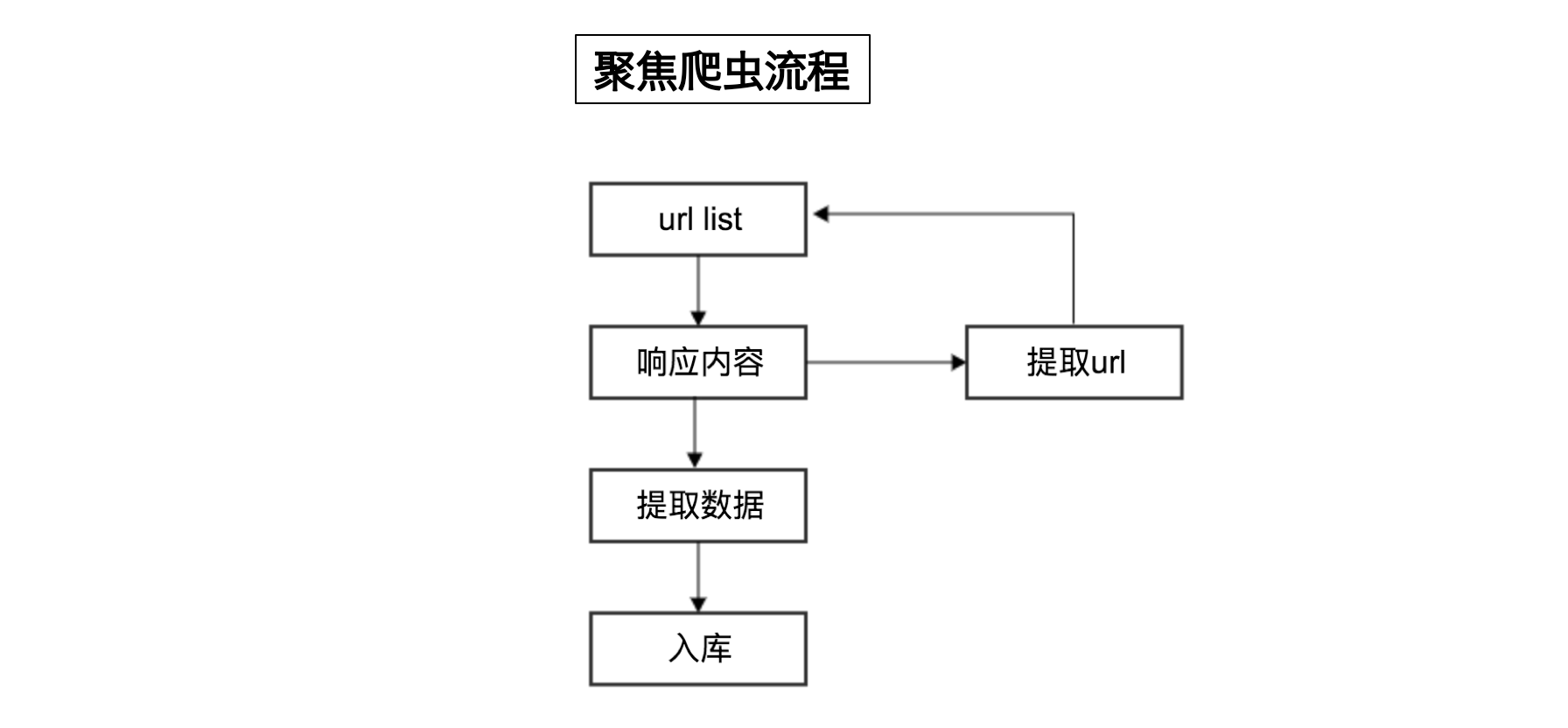
流程说明
- 向起始地址发送请求,并获取响应
- 对响应结果进行数据提取
- 如果获取的数据是新的网站地址则继续发送请求并获取响应
- 如果获取的数据为页面需要的数据则完成数据保存
案例:斗鱼图片
目标
- 练习分析素材并提取素材地址的能力
- 手动下载素材
过程记录
斗鱼-颜值URL:颜值直播_颜值视频_斗鱼直播
分析出图片的URL:https://rpic.douyucdn.cn/live-cover/roomCover/2023/09/02/003a4fd060deae496bab910340b6a165_big.png
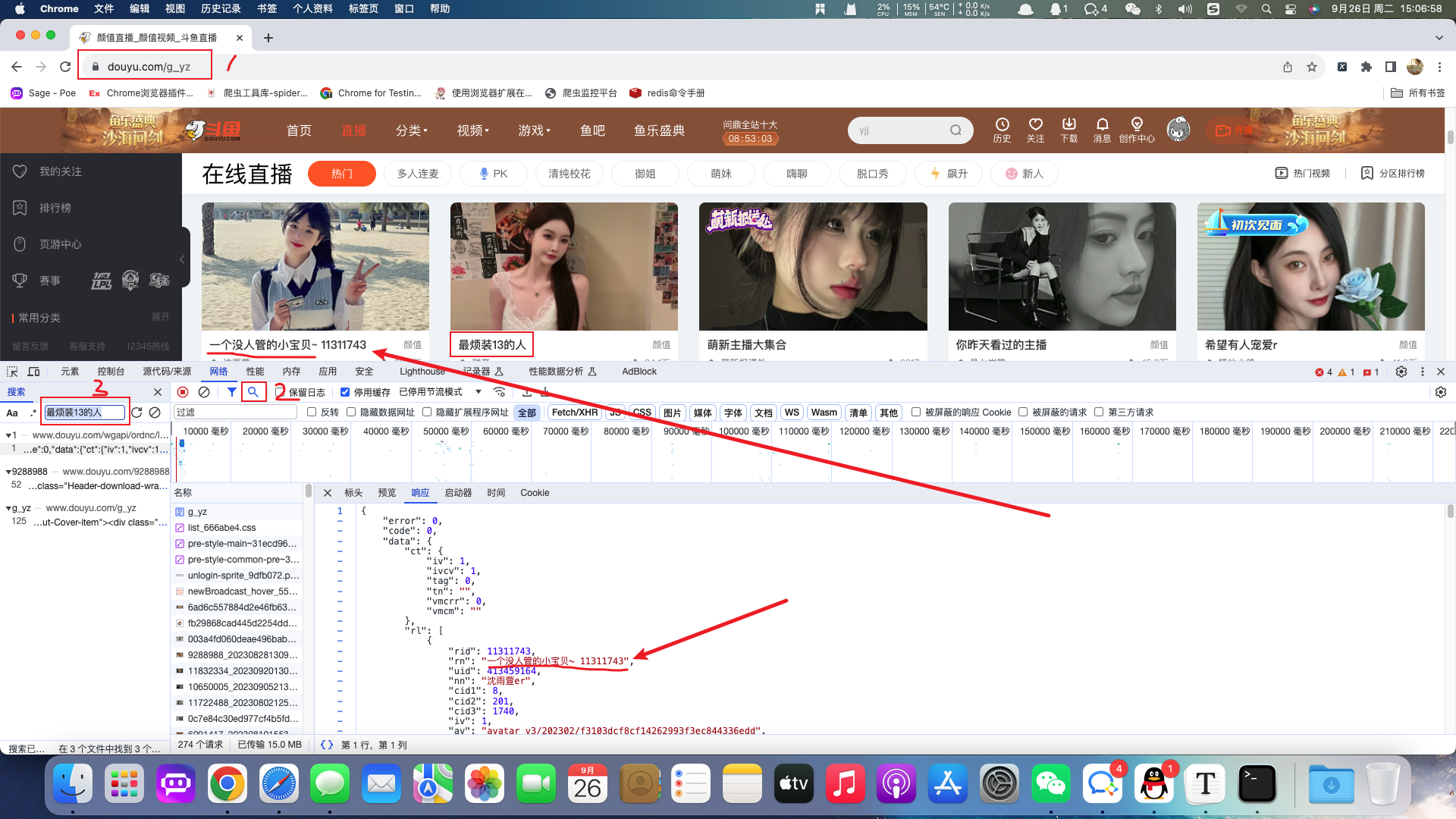
在一般的网站中,图片地址都是在html代码的img标签中的,例如百度图片。但是斗鱼网站进过分析之后我们发现,图片并不在html代码当中。像这种网站的资源都是动态加载过来的,所以需要善于利用浏览器开发者工具进行网络抓包。基于抓包我们发现当前图片等动态信息位于:https://www.douyu.com/wgapi/ordnc/live/web/room/yzList/1
当前api返回的数据为json数据,在json数据中包含了主播封面图片地址。
案例:抖音视频
要求:获取抖音原视频地址
分析地址:https://www.douyin.com/channel/300206
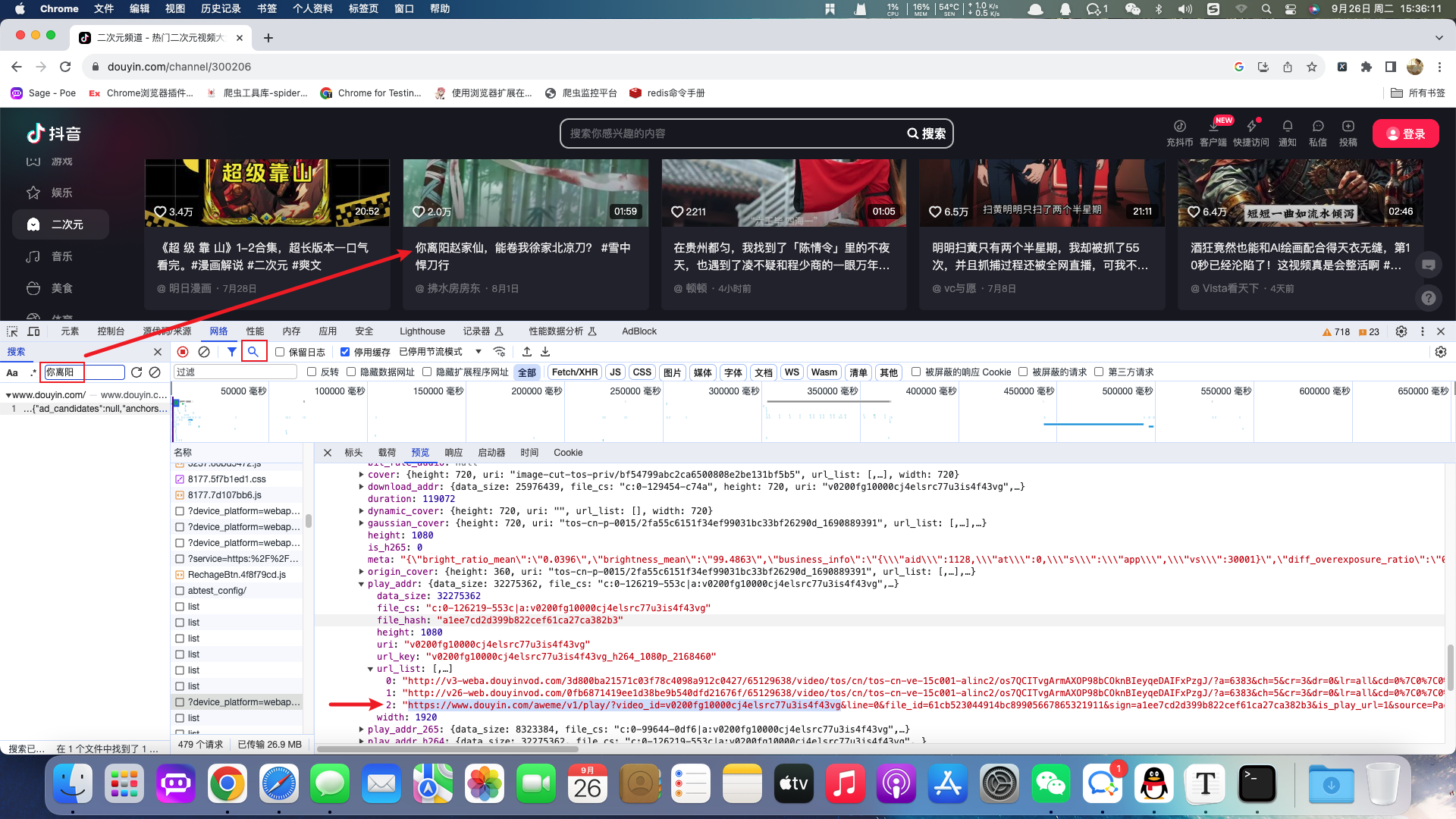
根据抓包分析出当前视频的api接口并返回json数据。在json数据中包含视频的播放地址,位于当前api的url_list节点。
案例:淘宝评论
要求:获取商家评论信息
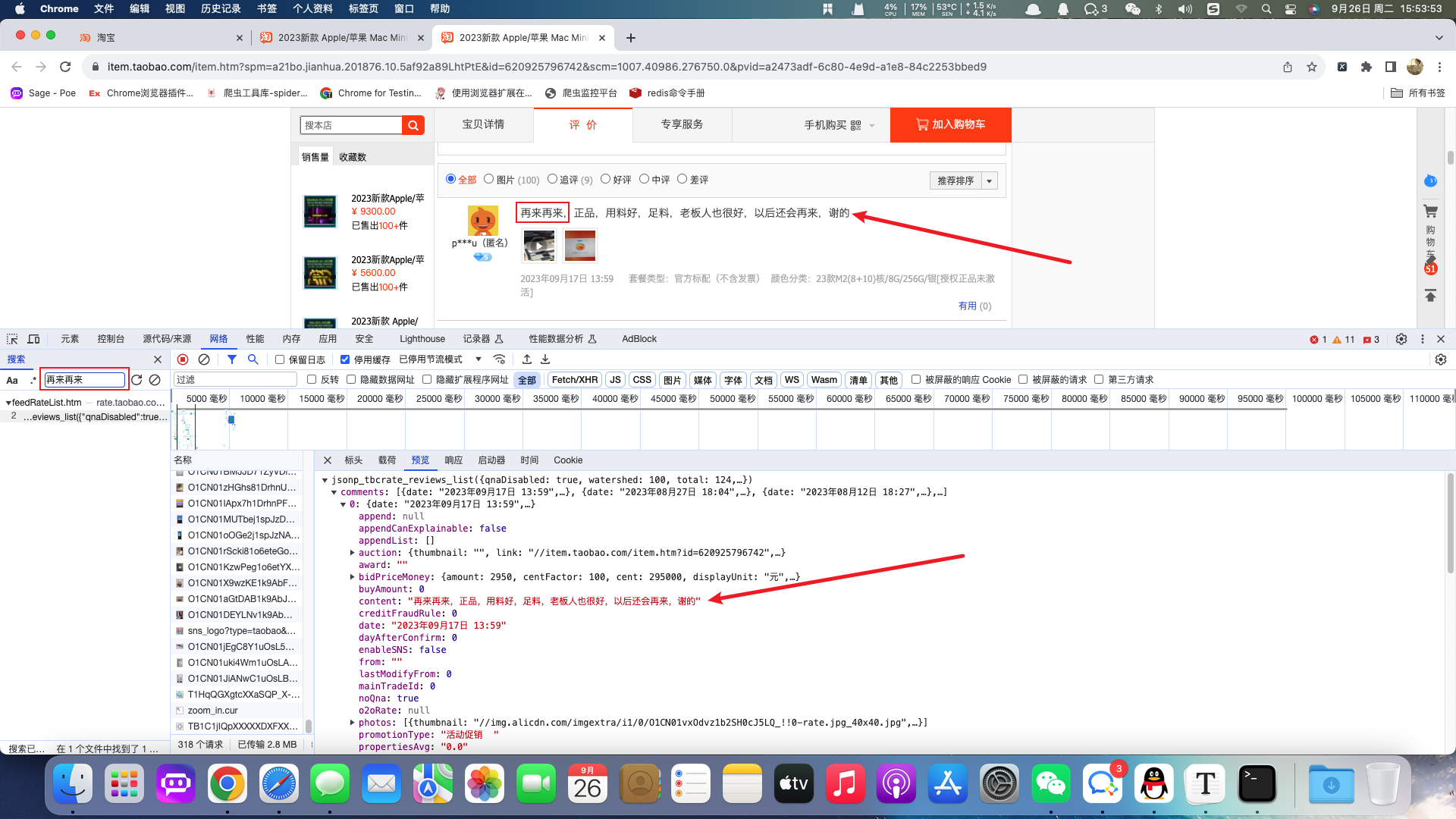
根据浏览器抓包工具获取对应的评论api并获取响应的json数据。

















 986
986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}