



目前大部分网站是基于HTTP与HTTPS进行网络交互的,在爬虫程序中也是发送网络协议来获取对应的网站信息,所以还是有必要了解网络协议。
HTTP与HTTPS相关概念
HTTP
-
- 超文本传输协议
- 默认端口号:80
HTTPS
-
HTTP+SSL(安全套接字层),即带有安全套接字层的超本文传输协议- 默认端口号:443
HTTPS比HTTP更安全,但是性能更低。
理解HTTP协议
HTTP协议使用了TCP协议,接下来我们使用网络调试助手软件发送HTTP协议并携带hello world数据到浏览器。
软件下载地址:NetAssist(网络调试助手)官方下载_NetAssist(网络调试助手)最新版v4.3.25免费下载_3DM软件
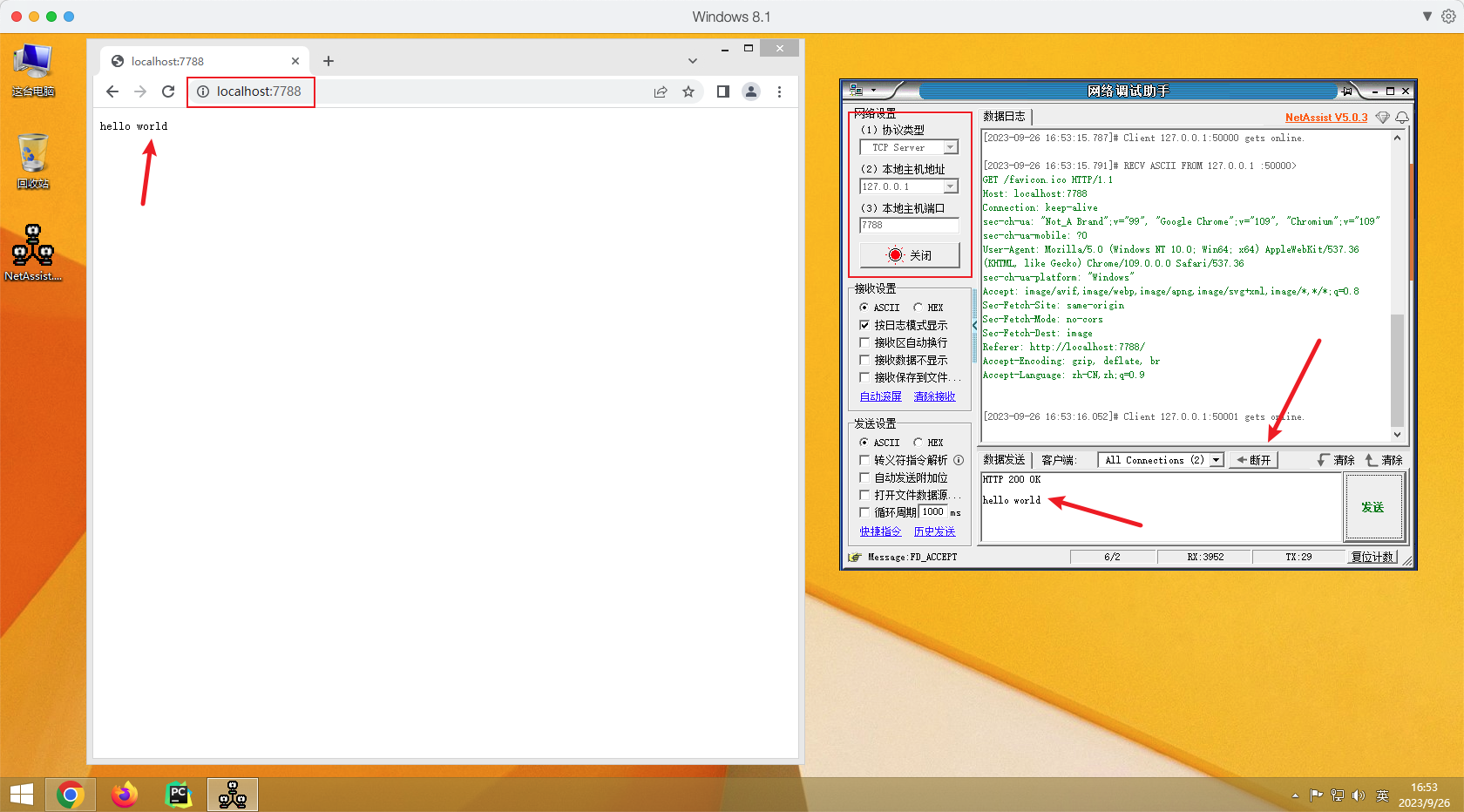
操作步骤:
- 设置网络调试助手为
TCP Server端 - 浏览器链接网络调试助手
- 发送
HTTP协议到浏览器并携带数据 - 断开连接,浏览器显示相应内容
HTTP协议的重要信息
在以上案例中,我们想要给浏览器发送信息并显示,就必须要带上HTTP协议。HTTP协议中有一部分数据对爬虫程序来说非常重要。分别是请求头与响应头。
常见的请求头参数
Host(主机和端口号)Connection(链接类型)Upgrade-Insecure-Requests(升级为HTTPS请求)User-Agent(浏览器名称)Accept(传输文件类型)Referer(页面跳转处)Accept-Encoding(文件编解码格式)Cookie(Cookie信息)x-requested-with :XMLHttpRequest(表示该请求是Ajax异步请求)
响应头参数
Set-Cookie (对方服务器设置cookie到用户浏览器的缓存)
响应状态码
200:成功302:临时转移至新的url(一般会用GET,例如原本是POST则新的请求则是GET)307:临时转移至新的url(原本是POST则新的请求依然是POST)403:无请求权限404:找不到该页面500:服务器内部错误503:服务不可用,一般是被反爬
浏览器发送HTTP请求过程
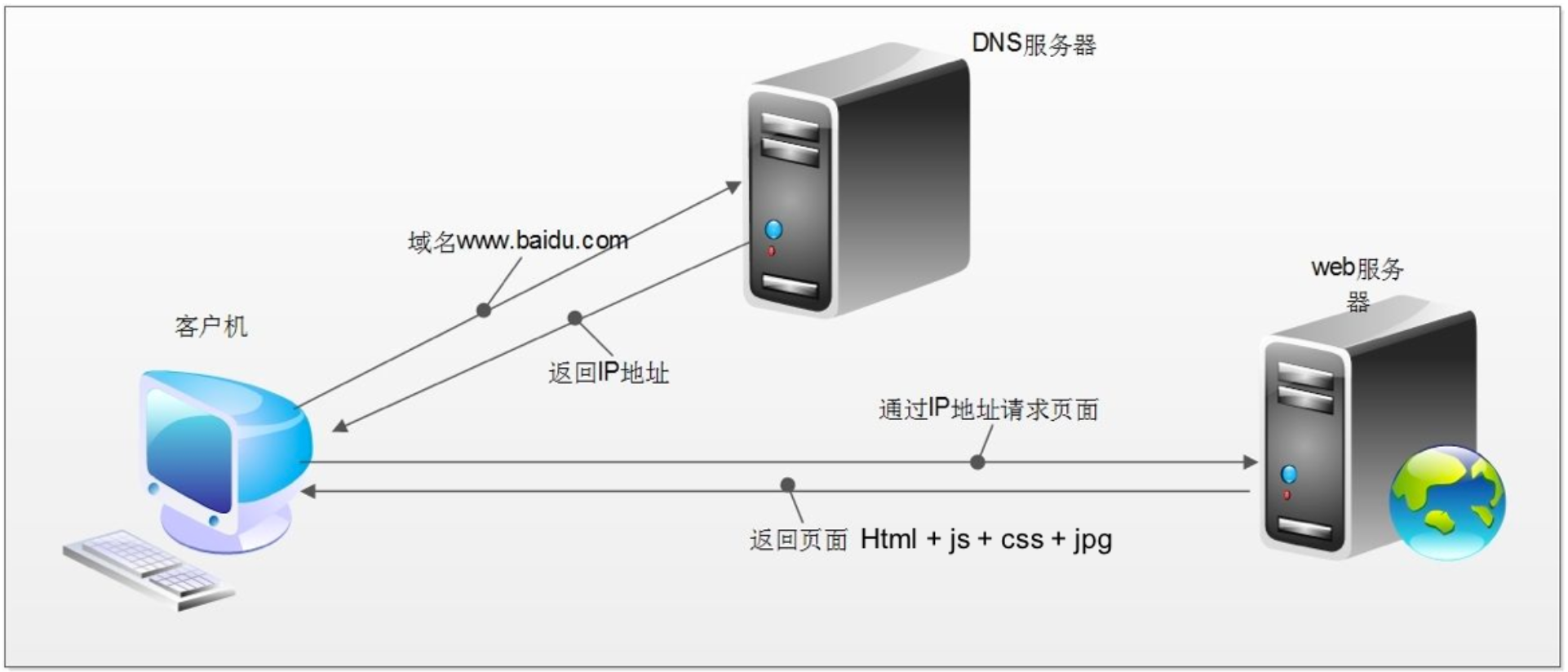
- 客户端发送网站域名到
DNS服务器 DNS服务器返回IP地址到客户端- 客户端根据返回的
IP地址访问网站后端服务器并请求网站资源 - 网站后端服务器返回对应页面资源
rebots协议
网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,但它仅仅是互联网中的约定而已,可以不用遵守。例如:https://www.taobao.com/robots.txt
在后期的Scrapy框架学习中,需要手动关闭Robots协议,现阶段了解即可。
谷歌浏览器插件
- XPath Helper
- Web Scraper
- Toggle JavaScript
- User-Agent Switcher for Chrome
- EditThisCookie
- SwitchySharp
插件下载地址:
请求测试软件
PostMan:Download Postman | Get Started for Free
ApiPost:下载中心-Apipost-中文版接口调试与文档管理工具

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









