






EAD-CONFORMER:基于一致性的多任务音频源分离编码器-注意-解码器网络
第一章 语音增强之《EAD-CONFORMER: A CONFORMER-BASED ENCODER-ATTENTION-DECODER-NETWORK FOR MULTI-TASK AUDIO SOURCE SEPARATION》
文章目录
前言
语音新手入门,学习读懂论文。
本文作者机构是快手科技有限公司

一、做了什么
提出了一种基于一致性的网络来提高多任务音频源分离的性能。该网络名为EAD-Conformer,采用Conformer块捕获本地和全局信息,EAD方式鼓励网络基于不同来源执行注意建模。
二、动机
在日常生活中记录的音频信号通常包含各种来源,如语音、音乐和背景噪声。这些声源的纠缠会降低音频质量,并可能损害后续技术的有效性。多任务音频源分离(Multi-task audio source separation, MTASS)自然被提出,其目的是将三种固定类型的声源同时分离成三条音轨。
三、挑战
(1)由于卷积网络的接受域是固定的,基于卷积的模型无法捕获全局依赖关系,特别是在长录音上。基于递归神经网络的模型可以捕获长期依赖关系,但模型复杂性较高。
(2)语音、音乐和噪音具有不同的音频特性。我们认为,仅仅在最后一层上增加一个分类层,不足以对每个源的内部信息和源之间的差异进行建模。
(3) Conformer- css可能不适合直接应用于MTASS。
四、方法
1.模型图
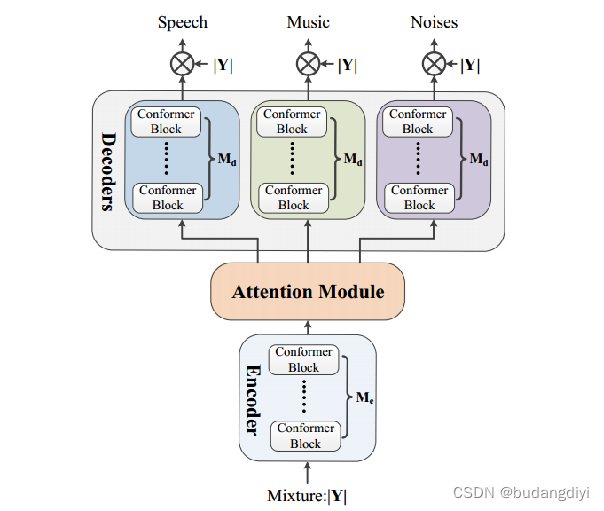
该网络由三个部分组成:(1)编码器处理混合并生成音频表示。(2)注意模块为每条音轨提取有价值的特征,连接编码器和解码器。(3)解码器分别对注意特征进行处理,产生分离的输出。
2.模型输入
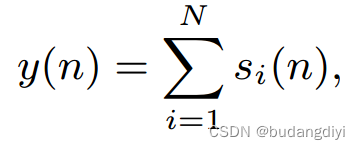
N为源信号个数,本任务中N = 3。我们选择短时傅里叶变换(STFT)频谱幅度作为模型的输入。
1024窗长和256窗移。
3.Conformer block
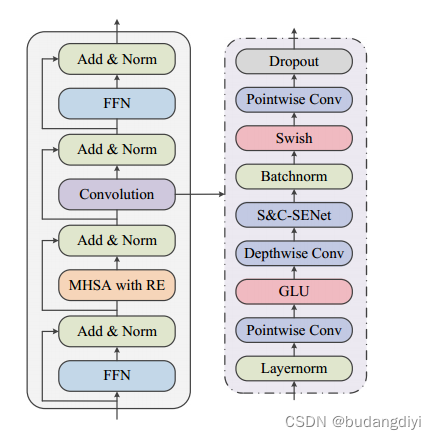
S&C-SENet代表空间和通道挤压激励层(spatial and channel squeeze-excitation layer),用来学习特征映射的重要性,提取有价值的特征,抑制无用的特征。
卷积层依次由层归一、点向卷积层、门控线性单元、一维深度卷积层、批归一层、挤压激励层、Swish激活层和点向卷积组成。
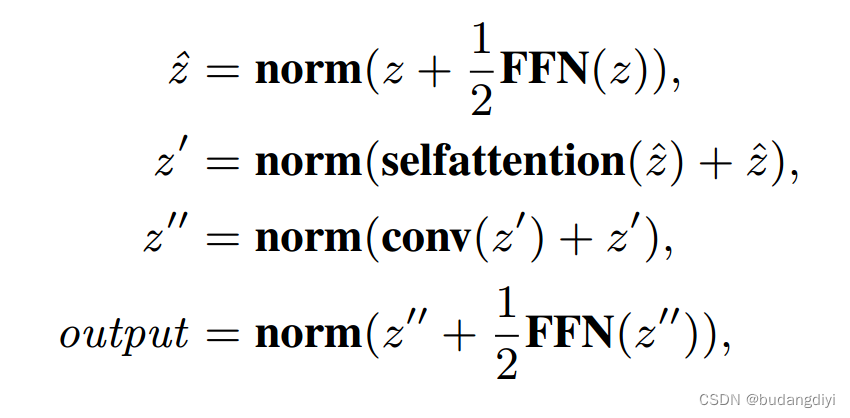
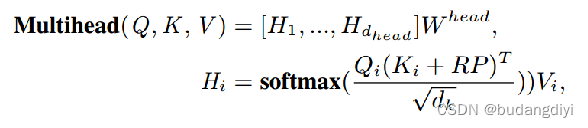
4.EAD-Conformer网络
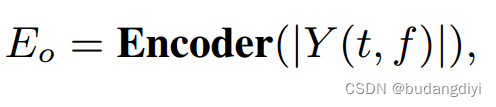
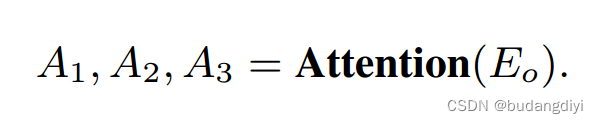
设计了一个注意力模块来动态地关注只对不同轨道有用的特征。
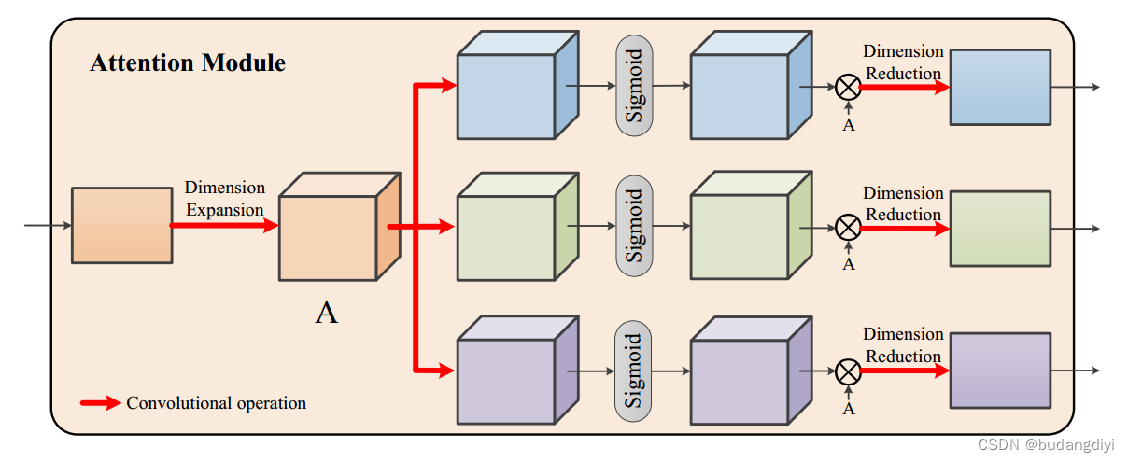
首先对输入进行扩展以获得精细的特征表示。详细地说,输入维度首先通过(1 × 1)卷积展开,从T×F到T×F ×C。
进一步采用三个卷积层进行非线性变换,用来学习每条轨迹的重要性。
然后应用sigmoid层来获得注意图。
得到注意图后,将输入与注意图进行矩阵乘法,得到注意特征。
一个卷积层,用于降维。
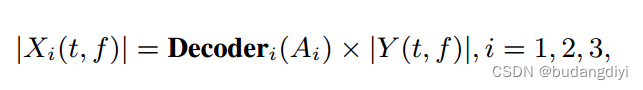
演讲常常有清晰的和声结构。音乐是由有节奏的旋律组成的。噪音更加随机和不规则。
使用三个解码器分别对每个轨道进行建模。
5.模型输出
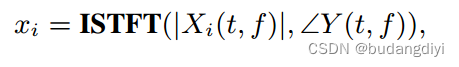
6.loss
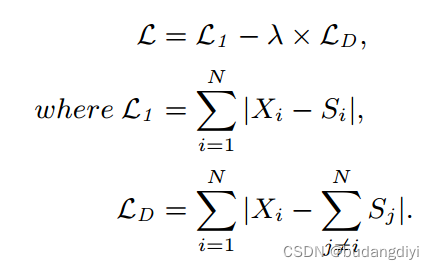
采用了两种损失函数:基于幅度的分离损失和判别分离损失。基于幅度的分离损失基于L1正则化。判别分离损失衡量估计信号与其他信号之间的差异,旨在增强模型的判别能力。
五、实验评价
1.实验设置
编码器由8个Conformer blocks,Conformer块由4个注意头、256个注意维度和前馈层的1024个维度组成。
对于注意力模块,(1;32;1;1), (32;32;3;1), (32;1;1;1)内核。
每个解码器由4个共形块组成。在解码器中,每个Conformer块由8个注意头、256个注意维度和前馈层的512个维度组成
EAD-Conformer使用AdamW优化器进行训练,学习率为1e-4,λ = 0.1。
2.数据集
由2万个训练数据(55.6小时)、1000个验证数据(2.8小时)和1000个测试数据(2.8小时)组成。语音、音乐和噪声分别来自aishell1、DiDiSpeech、DSD100和DNS challenge。
3.消融实验
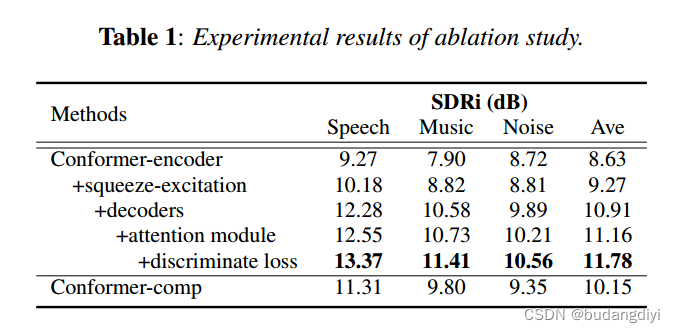
还进行了Conformer-comp的实验,它基于Conformer-CSS-base [18],并且使用了与EAD-Conformer大致相同数量的参数。这样做的目的是在相似的规模下将EAD-Conformer与Conformer-CSS-base [18]进行比较。具体而言,Conformer-comp包含19个Conformer模块。这些模型使用与我们模型相同的数据集进行训练。
4.结果

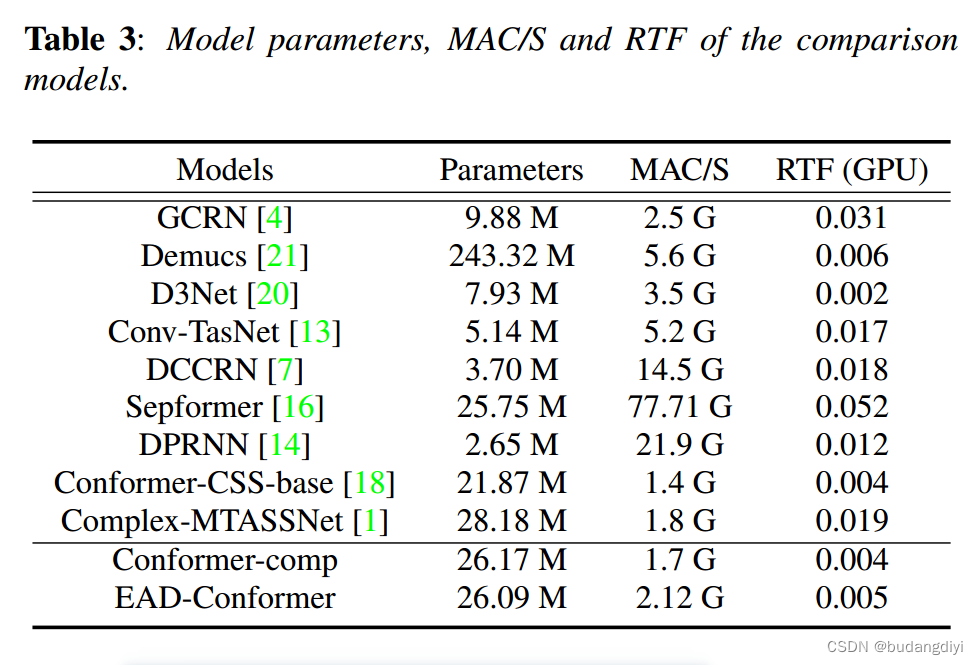
六、结论
实验结果表明,EAD-Conformer能有效分离混合语音。在语音、音乐和噪声轨道上,EAD-Conformer的SDRi分别为13.37 dB、11.41 dB和10.56 dB,优于几种常用方法。在MTASS中,模型不仅需要捕获信号的长期依赖关系,还需要对每个信号的特征和信号之间的差异进行建模。


















 203
203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











