






第一章 语音增强之《REAL-TIME SPEECH ENHANCEMENT WITH DYNAMIC ATTENTION SPAN》
实时语音增强和动态注意力跨度
文章目录
前言
语音新手入门,学习读懂论文。
本文作者机构是中国传媒大学和微软亚洲研究院

一、做了什么
提出了一种根据输入信号自适应改变接收野的方法。具体而言,在编解码器框架中,在所有注意模块中引入了动态注意广度机制,以控制用于处理当前帧的历史内容的大小。
二、动机
实时SE要求因果关系、有限的内存使用和较低的计算复杂度。由于麦克风记录的音频信号的时变特性限制了系统只能从有限的历史信息中捕捉时变特征,因此对实时SE来说,时变特性是一个严峻的挑战。
三、挑战
以往的模型不能明确地捕获时变特征,包括环境干扰和语音相关特征。
四、方法
1.模型图
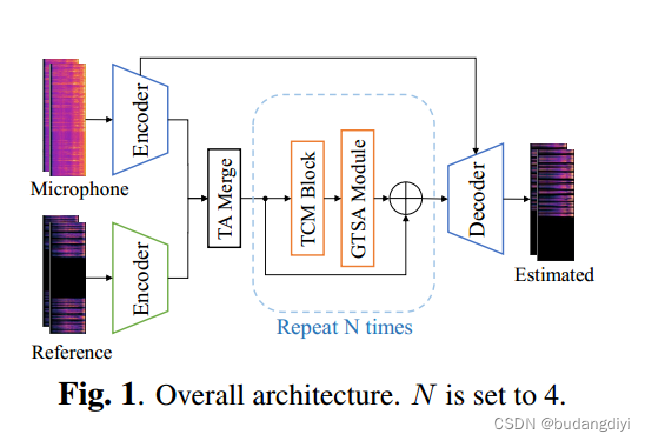
每个编码器包含四个二维因果卷积层。
解码器由四个门控块组成,但最后具有因果卷积和一个额外的二维因果卷积层。除解码器的最后一层外,其余所有卷积层后面都是BN和PReLU。
时间卷积模块(TCM)是一种在时域上进行卷积操作的模块,常用于处理时间序列数据。
2.DKG模块
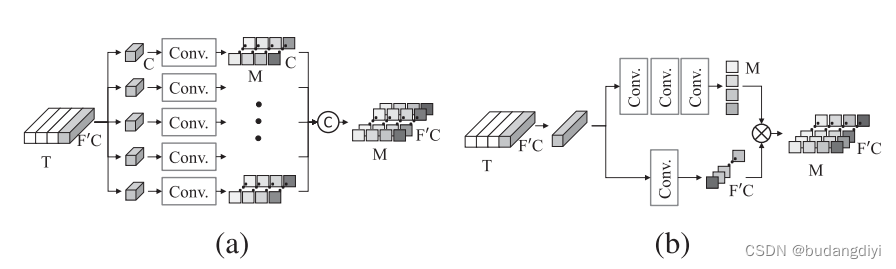
不可分离的DKG,内核直接由一个映射生成,将输入特征TxF’C,分成F个集合, 使用一维卷积核,卷积为MxC,最后串联起来,得到核K。
可分离DKG,内核是使用两个分离的映射生成的,其中一个映射生成通道共享过滤器K0,另一个映射生成与通道相关的权重k,然后按元素乘以K0。
3. Problem Formulation问题公式化
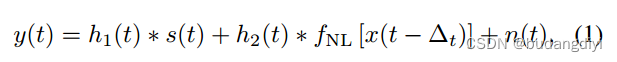
时变麦克风信号y(t),近端语音信号s(t)由传声器经声路h1(t)记录。近端扬声器播放的参考信号x(t)得到非线性失真fNL,例如扬声器和可能的处理失真,并通过声回波路径h2(t)记录。∗表示卷积,∆t是参考信号和麦克风信号之间的时变延迟,h1(t)和h2(t)为房间脉冲响应(RIR),n(t)为加性噪声。
在本文中,NS任务的目标是去除n(t), AEC任务的目标是去除x(t)产生的回波,去噪任务的目标是去除h1(t)产生的早反射和晚反射。
4.TA合并模块
由于参考信号和麦克风信号之间的时间偏差,引入了两个信号之间的时间注意(TA)来明确捕获它们之间的相互关系,并将来自双路径的特征合并为一个。
5.重复模块
重复模块包含定义的TCM和定义的GTSA模块
TCM模块是时间卷积模块
GTSA模块根据当前的输入音频片段和其上下文信息,计算注意力权重,以决定哪些部分对于生成增强声音更重要。动态调整注意力跨度可以使模型更好地适应不同长度的噪声和语音段落,从而提高增强效果。
6.DAS Mechanism(DAS机制)
在所有注意模块(TA合并和GTSA)中引入DAS机制
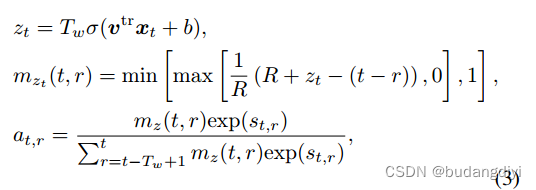
Xt是前一个重复模块的输出特征。
Tw设置为100。
R是一个超参数,用于控制软化程度,超参数R设置为2。
mz(t,r);t≥r为DAS注意值。
st,r表示Q向量在第t帧处与K向量在第r帧处的相似度得分。
at,r为Softmax操作后的注意力得分。
五、实验评价
1.数据集
合成了1166.7小时的音频样本用于训练,9.7小时用于验证,使用Interspeech 2021 DNS挑战赛的语音和噪声以及Interspeech 2021 AEC挑战赛的rir。
对于AEC任务,我们使用消融研究的合成测试集[13]和AEC挑战赛ICASSP 2022[18]的真实记录盲测集。对于NS任务,使用了来自DNS挑战赛ICASSP 2022的Track-1非个性化DNS盲测集的738个标记为“Primary”的片段。
3.客观评价
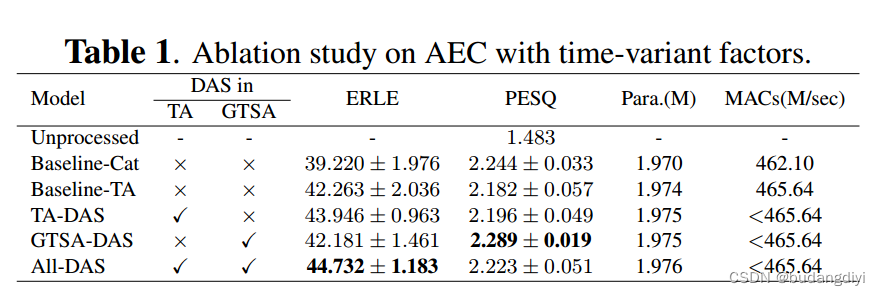
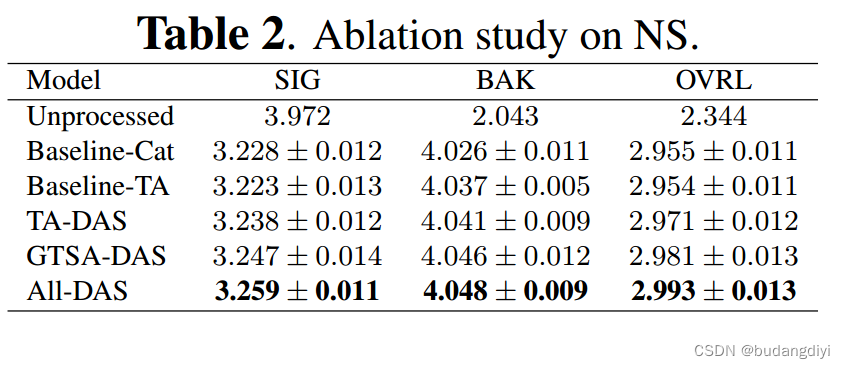
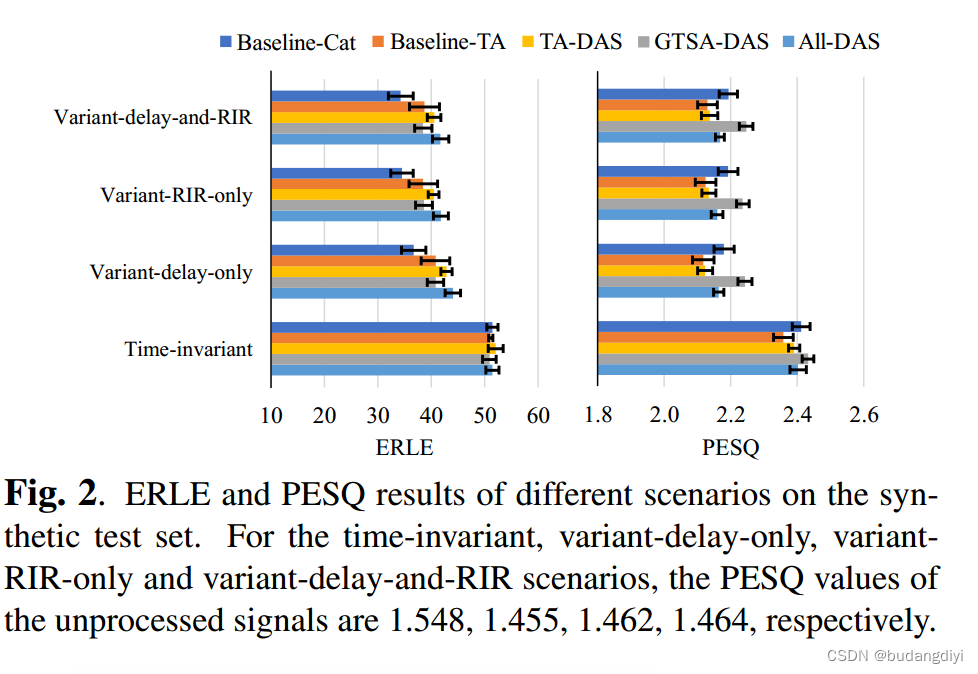
(1) 在所有时变情况下,Baseline-TA在ERLE度量上都显著优于Baseline-Cat,表明TA合并模块有助于模型更好地去除时变回波。
(2) 在Baseline-TA的基础上,将DAS引入TA合并模块会略微提高ERLE和PESQ。
(3) GTSA-DAS模型在ERLE上保持了基线- ta的稳定改进,并显示出更好的PESQ。
(4) 在所有模型中,all - dasx模型在所有情况下的ERLE都最大,而PESQ较GTSA-DAS模型有所下降。这些结果表明,同时将DAS引入TA和GTSA可以显著改善回声消除,但简单地将DASenabled TA和GTSA级联可能无法达到各自在AEC任务中保持语音质量的优势。
GTSA-DAS可以自动调节不同通道的感受野。
六、结论
基于DAS的模型能够更好地跟踪时变因素,并从输入音频中捕获语音相关特征,有利于消除干扰和保持语音质量。
DAS改进了TA合并模块,以准确捕获参考信号和麦克风信号之间的时变相关性,特别是在AEC任务上具有更好的鲁棒性。
输入自适应接受域使GTSA模块能够动态地并行捕获长/短期依赖项
七、知识小结
加性噪声(Additive Noise)是指在信号传输或处理过程中,被添加到原始信号中的随机干扰。这种干扰又被称为增益噪声或外部噪声,是由于外部环境因素或传输导致的信号损失和失真造成的。
ERLE评价指标,(回波回波损失增益)通常用于评估语音信号处理中的回声消除效果。
音频信号的时变特性,是信号在时间上的动态变化。这些变化可能是短期的,例如在语音信号中,由于说话者的口腔和喉咙的运动,声波产生了瞬时的频率和幅度变化。这些变化通常以数百到数千赫兹的频率进行,称为“短期谐波结构”。


















 8331
8331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











