




文章目录
前言
文章细分了各个知识点,可在目录中快速跳转。
手机端用户在查看代码块时建议点击代码右上角放大查看,每一段代码均有完整注释。
本文将介绍链表的概念和分类,并重点拆解单链表的实现。
一、链表的定义与结构
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。本质为由节点组成的链状存储结构。节点是内部成员为数据和指针两部分的结构体。

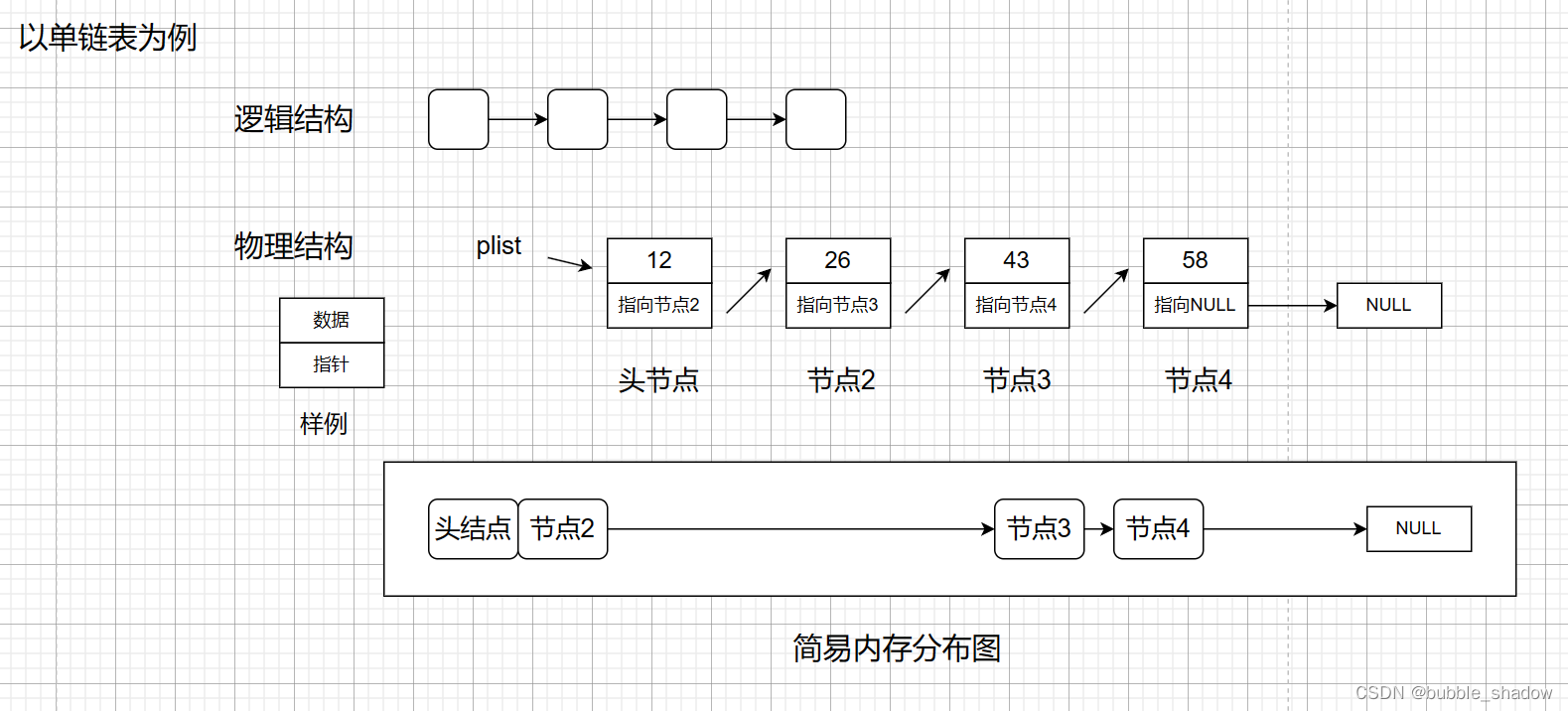
- 逻辑结构是人为想象出来的希望链表达到这种目的结构,我们后续做题分析时一般为了简便而画逻辑结构图
- 物理结构是链表的真实结构,由于物理空间不连续,我们需要在节点中放置一个指针,指向下一个节点,这样访问一个节点的时候才能链接到下一个节点。尾节点的指针指向NULL。
- 参考内存分布图我们可以知道各个节点之间的空间关系是不确定的,两个节点之间可以紧挨着连续,也可以相隔很远,也可以间隔一点距离。
- plist 为结构体类型的指针,我们用来指向头结点,叫做头指针
二、链表的分类
实际中链表的结构非常多样,以下情况组合起来就有8种链表结构,我们简要了解一下。


- 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
- 带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了,等下篇文章博主再拆解介绍,本文以单链表拆解为主。
三、接口实现 - 无头单向不循环链表
0.声明
typedef int SLNDataType; //注释1
typedef struct SListNode
{
SLNDataType val;
struct SListNode* next;
}SLNode; //注释2
注释:
-
由于后期我们可能会改变链表存储数据的类型,而一但更改,我们需要对每一个调用该类型的地方进行修改,十分麻烦,使用typedef对数据的类型进行重命名,这样以后要更换类型只需要更改此处就可以达到全文替换的目的。
-
重命名简便后续输入,注意我们为什么不直接命名简便一点呢?每个命名都是基于英文单词的释义,这样可以增加在多人协作,以及后续维护代码时的可读性。
1.创建新节点
SLNode* CreateNode(SLNDataType x)
{
SLNode* newnode = (SLNode*)malloc(sizeof(SLNode));
//检测是否开辟成功
if (newnode == NULL)
{
perror("malloc fail");
exit(-1);
}
newnode->val = x; //新节点存储的数据
newnode->next = NULL; //新节点还未链接到其他节点,先置空
return newnode; //返回新节点的地址
}
2.销毁
void SLTDestroy(SLNode** pphead)
{
assert(pphead);
SLNode* cur = *pphead;
while (cur)
{
SLNode* next = cur->next;
free(cur);
cur = next;
}
*pphead = NULL;
}
3.尾插
void SLTPushBack(SLNode** pphead, SLNDataType x)
{
SLNode* newnode = CreateNode(x);
//分为链表为空,不为空 两类
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
//找尾
SLNode* tail = *pphead;
while (tail->next != NULL) //尾节点中的指针指向NULL,
//当该指针=NULL时循环停下,也就找到了尾节点
{
tail = tail->next;
}
tail->next = newnode; //将新节点插入尾节点后面
}
}
- 链表为空时,没有节点,直接将新创建的节点作为头结点
- 链表不为空时,我们并不想改变头结点指向,否则后面就找不到链表头结点,故创造一个指针tail,让其从头往后找,找到尾节点,然后就可以插入新节点了。
4.头插
void SLTPushFront(SLNode** pphead, SLNDataType x)
{
SLNode* newnode = CreateNode(x); //创建新节点
newnode->next = *pphead; //链接新节点
*pphead = newnode; //更新头指针
}
5.尾删
- 方法1
//方法1
void SLTPopBack(SLNode** pphead)
{
assert(*pphead); //头指针为空时,说明链表为空,不能再删除节点了,直接断言上保险
//一个节点
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
//一个以上节点
else
{
//找尾
SLNode* prev = NULL; //找到尾节点的前一个节点
SLNode* tail = *pphead;
//tail找到尾节点时,prev找到尾节点前一个节点
while (tail->next != NULL)
{
prev = tail;
tail = tail->next;
}
//尾删,并置空
free(tail);
tail = NULL;
prev->next = NULL; //前一个节点变为尾节点,里面的指针也要置空
}
}
- 方法2
void SLTPopBack(SLNode** pphead)
{
assert(*pphead); //头指针为空时,说明链表为空,不能再删除节点了,直接断言上保险
//一个节点
if ((*pphead)->next == NULL)
{
free(*pphead); //直接删除并置空
*pphead = NULL;
}
//一个以上节点
else
{
SLNode* tail = *pphead;
//找尾节点的 前一个节点
while (tail->next->next != NULL)
{
tail = tail->next;
}
free(tail->next); //删除尾节点并置空
tail->next = NULL;
}
}
两个方法本质是一样的,方法2连续访问next,看起来比较简洁,实际上代码效率跟方法1是一样的
6.头删
void SLTPopFront(SLNode** pphead)
{
assert(*pphead);
SLNode* tmp = *pphead; //tmp保存头指针
*pphead = (*pphead)->next; //头指针指向第二个节点
free(tmp); //free头结点
}
7.查找
void SLTFind(SLNode* phead, SLNDataType x)
{
SLNode* cur = phead;
while (cur) //遍历整个链表,cur找到NULL说明找完了链表
{
if (cur->val == x)
{
return cur; //找到就返回
}
else
{
cur = cur->next; //没找到,后移一个节点继续找
}
}
return NULL; //遍历完链表还没找到,说明不存在对应值的节点
}
8.指定节点前插入
//在pos位置对应节点前 插入
void SLTInsert(SLNode** pphead, SLNode* pos, SLNDataType x)
{
assert(pphead);
assert(pos);
assert(*pphead);
if (*pphead == pos)
{
//头插
SLTPushFront(pphead, x);
}
else
{
//类似于尾插,先找pos位置的前一个节点
SLNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
//创建新节点,进行链接
SLNode* newnode = CreateNode(x);
prev->next = newnode;
newnode->next = pos;
}
}
9.指定节点删除
void SLTErase(SLNode** pphead, SLNode* pos)
{
assert(pphead);
assert(*pphead);
assert(pos);
if (*pphead == pos)
{
//头删
SLTPopFront(pphead);
}
else
{
//类似于尾删,先找pos位置的前一个节点
SLNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
//将pos位置前后的节点进行链接,删除pos节点并置空
prev->next = pos->next;
free(pos);
pos = NULL;
}
}
10.指定节点后插入
void SLTInsertAfter(SLNode* pos, SLNDataType x)
{
assert(pos);
SLNode* newnode = CreateNode(x); //创建新节点
newnode->next = pos->next; //链接新节点
pos->next = newnode;
}
11.指定节点后删除
void SLTEraseAfter(SLNode* pos)
{
assert(pos);
assert(pos->next); //尾结点后已经没有节点,不能执行删除
SLNode* tmp = pos->next; //保存pos后的节点
pos->next = pos->next->next; //链接pos
free(tmp);
tmp = NULL;
}
四、单链表的优缺点
-
优点(对比顺序表)
物理空间不连续,空间利用率高,不会造成空间浪费
-
缺点
- 物理空间不连续,无法通过下标随机访问节点,除了已知头结点地址,其他节点地址都需要查找,导致尾插尾删等部分接口实现的时间复杂度高,效率低下
- 只能找到下一个节点地址,无法找上一个节点地址
对于单链表的缺点,我们后续还会学习带头双向循环链表可以解决单链表中查找节点费劲的问题,感兴趣的读者可以关注一下博主,我们将在下篇文章进行拆解分析。
五、深入理解
1.传参使用一级指针还是二级指针?
- 直接上结论:需要改变头指针的传二级指针,不需要的可以传一级指针。如果搞不清楚传什么,传二级就对了。
我们在C语言中学习时了解到,指针指向的是对象的地址,通过地址我们才能找到这个对象,达成对其的修改。同理,二级指针指向的是一级指针的地址,我们在给接口函数传参时,如果想要修改头指针,就必须将头指针的地址传给函数。因此我们使用二级指针传参,再对二级指针进行解引用,就修改头指针本身了。值得注意的是,部分接口如尾插时,当链表为空时,需要对头指针进行修改,我们因此需要传二级指针,而链表不为空时,我们不需要修改头指针,但由于必须对链表为空的情况进行判断,我们只能传二级指针。
2.断言什么?
- 结论 : pphead必须断言,其他按设计理念断言,理念不唯一,故断言也不唯一。
pphead作为二级指针,保存的是头指针的地址,我们要认识到指针指向NULL,它本身也具有地址,只要一个东西存在,它就存在地址。
设计理念不唯一。
如指定位置前插入,我在代码中assert(*pphead)和assert(pos)。实际*pphead 和 pos 同时为空和同时不为空也是可以的,即写成assert(( !pos && !(*pphead)) || (pos && *pphead))
同时为空时,意思是链表为空,在头指针NULL前插入,相当于进行头插;
同时不为空,就是正常插入。
我们要认识到如果这样写,代码就会有点绕,一不小心就会写错,而且头插的功能我们有专门的头插接口进行实现,有没有必要非要用其他接口在这绕圈折磨自己?博主的设计理念是该接口不支持头插,直接断言三个干脆利落,省时省力,不容易出bug。如果有人说,我的这个接口就支持头插,两个人的代码都是没有问题的,是要看设计者怎么想的。就像C语言中的库函数只定义了函数的功能,并没有标准进行统一实现,库函数的具体实现根据不同编译器的不同编写者,可能会有所差异。
总结
本文介绍了链表的概念和结构,以及常见的链表分类,拆分讲解了无头单向不循环链表的接口实现,以及帮助读者复习了C语言一级指针和二级指针的问题。本文的每一段代码都带有注释,对于难懂点使用格外标注以及图表方式辅助理解,如果对你有所帮助,还望点赞收藏支持博主。
文章中有什么不对的丶可改正的丶可优化的地方,欢迎各位来评论区指点交流,博主看到后会一一回复。


















 310
310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









