




 本文介绍了如何克服智联招聘动态网页和复杂API的挑战,利用selenium和mitmproxy进行数据抓取。通过mitmproxy的安装和配置,配合selenium自动化访问网页,实现数据的批量收集。详细阐述了整个爬虫流程,包括准备工作、mitmproxy的抓包操作、selenium的自动化页面访问以及反爬虫策略。
本文介绍了如何克服智联招聘动态网页和复杂API的挑战,利用selenium和mitmproxy进行数据抓取。通过mitmproxy的安装和配置,配合selenium自动化访问网页,实现数据的批量收集。详细阐述了整个爬虫流程,包括准备工作、mitmproxy的抓包操作、selenium的自动化页面访问以及反爬虫策略。
目录
本文主要是介绍爬取智联招聘岗位信息的方法。目前网络上的爬取以requests库爬取和API接口解析为主,尝试后发现均不可行。本篇文章介绍的方法在2020年6月25日成功爬取相应数据。由于爬虫具有时效性,希望各位在该方法不可用时予以提醒,作者再进行更新。
1 智联招聘数据爬取难点
1.1 动态网页
智联招聘网站目前采用动态网页,即网页源码与页面展示不同。所以目前使用requests库实现爬取的代码均不可用
1.2 复杂的API接口
通过对智联招聘网站分析,发现数据源自于某个API接口,API接口中包含了大量的变量,人工解析基本不可行。目前针对智联招聘通过解析API接口的方式均不可行
1.3 selenium
作者尝试使用selenium爬取,发现该动态网页使用selenium不可行
2 智联招聘数据爬取的简便路径
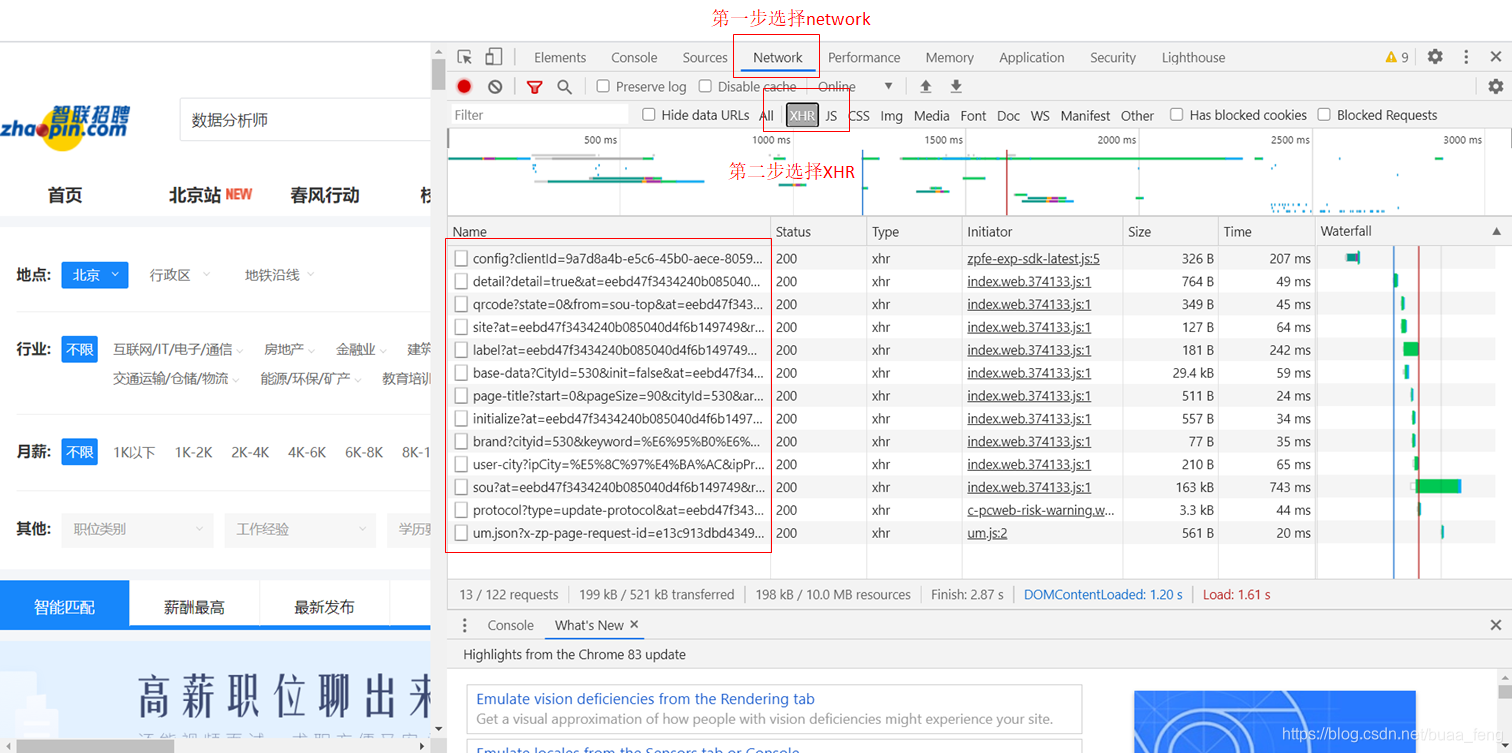
首先需要确定想要爬取的岗位数据,隐藏在数据包中,查看该数据包的方法如下:
- 在智联招聘搜索某个城市某个岗位
- 打开开发者工具
- 切换至网络、选择XHR
- 找到以sou?开头的链接,response中包含想要爬取的数据
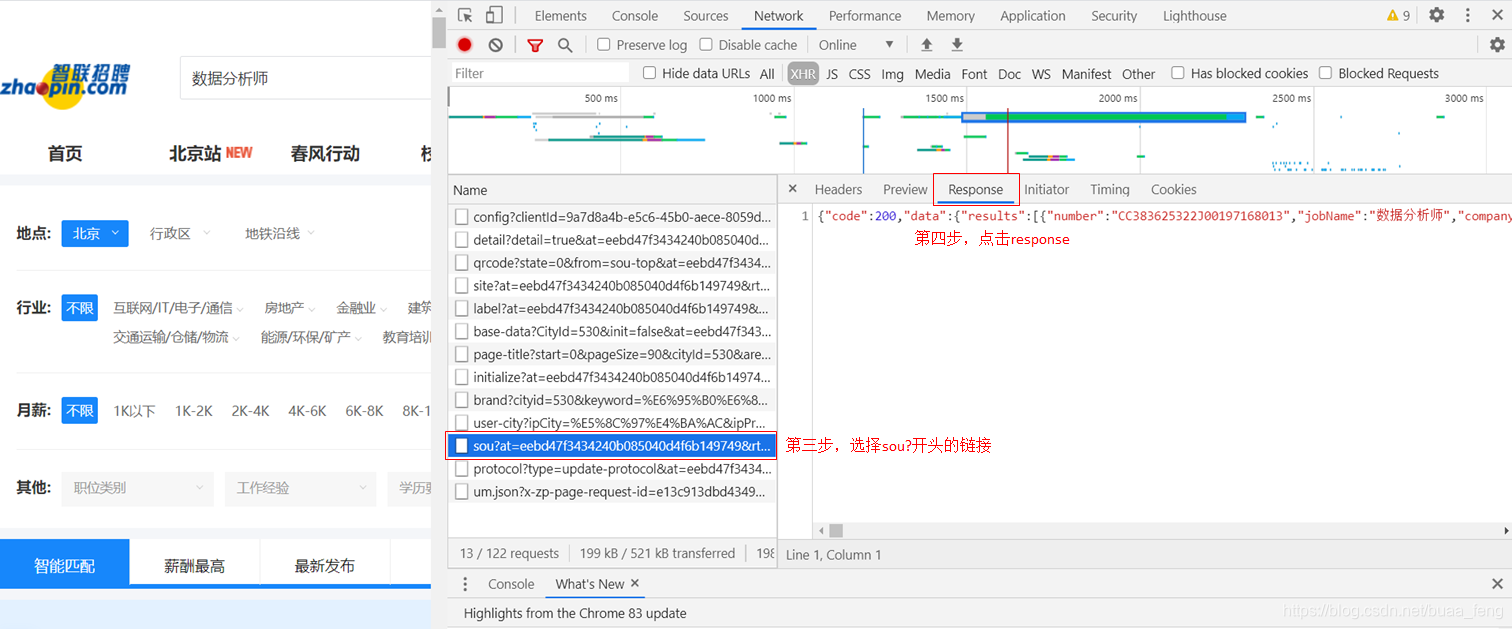
针对response中的数据,可以通过复制粘贴至txt文件实现数据收集。针对某个城市的某个岗位数据,智联招聘提供90*12条数据记录,共12个分页,只需要12次复制粘贴即可采集1080条数据记录。该方法适用于小数据量采集。大批量数据不可行。
3 mitmproxy的抓包操作
首先将赋值粘贴数据包的操作自动化,也就是实现抓吧。mitmproxy的更多介绍参考使用mitmproxy+python做拦截代理
3.1 mitmproxy的安装
系统环境如下:
操作系统:Windows10 家庭中文版 64bit
Python:anaconda、Python3.7.7
mitmproxy的安装比较简单,在Anaconda Prompt中使用
pip install mitmproxy
即可实现安装。安装完成后,使以下代码验证
mitmweb --version
可以看到相应的版本信息
Mitmproxy: 5.1.1
Python: 3.7.7
OpenSSL: OpenSSL 1.1.1g 21 Apr 2020
Platform: Windows-10-10.0.18362-SP0
如果显示
'mitmweb' 不是内部或外部命令,也不是可运行的程序
则需要在mitmproxy官网下载安装mitmproxy软件,按照正常安装exe文件方式进行,并将安装后的软件添加到系统环境变量。再次测试是否安装成功即可。
mitmproxy在Windows系统下可用的是mitmweb和mitmdump,mitmweb以web形式展示各种flow,mitmdump则为静默模式。
3.2 mitmproxy实现数据抓包
使用mitmproxy实现抓包,主要有三步:一是启用mitmproxy实现对浏览器的监听;二是以特定的方式打开谷歌浏览器;三是访问相应的网页。
mitmproxy监听
启用mitmproxy的方式比较容易,在Anaconda Prompt中使用mitmweb即可。但是单纯的监听无法实现数据包抓取,所以需要加载自定义的python代码。
启动代码
mitmweb -s addons.py
addons.py即是自定义的python脚本,实现对数据包的抓取。通过对智联招聘数据包链接的分析,建立了如下的python脚本
import mitmproxy.http
from mitmproxy import ctx
url_paths = '/c/i/sou?_v='
class Jobinfo:
def response(self, flow: mitmproxy.http.HTTPFlow):
if flow.request.path.startswith(url_paths):
text = flow.response.get_text()
file_handle=open('0624.txt',mode='a')
file_handle.write 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3832
3832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









