




在一个Pod中,可以有多个容器,比如一个主要业务容器和若干辅助业务容器。如果辅助业务容器内程序有问题,导致占用了大量的CPU资源,进而影响了主要业务容器的执行效率,那就需要进行干涉了。本节我们将使用“资源配额”来限制容器的CPU使用。
服务部署
为了让程序更多的消耗CPU,我们对测试代码做了相关改动
# main.py
from http.server import HTTPServer, BaseHTTPRequestHandler
import argparse
import os
import random
import math
def docpu():
random_number_a = random.randint(10000,100000000000)
random_number_b = random.randint(100000000000,10000000000000)
random_number = random_number_a * random_number_b
while random_number > 2:
random_number = math.sqrt(random_number)
return random_number
class Resquest(BaseHTTPRequestHandler):
def do_GET(self):
self.send_response(200)
self.send_header('Content-type', 'application/json')
self.end_headers()
random_number_sum = 0
while True:
random_number = docpu()
if random_number_sum > 1000:
break
else:
random_number_sum += random_number
data = "{0}".format(random_number)
self.wfile.write(data.encode())
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Process some integers.')
parser.add_argument('-port', metavar='N', type=int, help='port of service', required=True)
args = parser.parse_args()
host = ('0.0.0.0', args.port)
server = HTTPServer(host, Resquest)
print("Starting server, listen at: {0}:{1}".format(os.environ.get("POD_IP", ""), args.port))
server.serve_forever()
这段代码内部不停地对随机数开方,用于消耗CPU。
部署
在kubernetes中,1个CPU资源被切分成1000份被分配,每份叫1毫核。这是配额的最小单元了。如下,我们就让容器可以使用100毫核,即0.1个CPU核。
resources:
limits:
cpu: 100m
完整的清单文件如下
# simple_http_deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: simple-http-deployment
spec:
replicas: 2
selector:
matchLabels:
app: simple_http
template:
metadata:
labels:
app: simple_http
spec:
containers:
- name: simple-http-container
image: localhost:32000/simple_http:v4
ports:
- containerPort: 8888
command: ["python","main.py","-port","$(SERVER_PORT)"]
env:
- name: SERVER_PORT
value: "8888"
resources:
limits:
cpu: 100m
---
apiVersion: v1
kind: Service
metadata:
name: simple-http-service
spec:
type: NodePort
selector:
app: simple_http
ports:
- port: 80
targetPort: 8888
nodePort: 30000
在这个清单中,我们创建了一个Deployment用于部署Pod,其中resources指定每个Pod只能使用0.1个CPU(100m)。还创建了一个Service用于接收请求,这些请求将被路由到上述Pod上。
kubectl create -f simple_http_deployment.yaml
deployment.apps/simple-http-deployment created
service/simple-http-service created
使用《研发工程师玩转Kubernetes——启用microk8s的监控面板(dashboard)》中的控制面板,我们可以看到没有请求时两个Pod的CPU利用情况——最低的1毫核。

测试压力
我们使用wrk来做压力测试,如果没有安装它,可以使用sudo apt install wrk来安装。
下面命令让wrk启动10个线程,10个连接,发送120秒。
wrk -t10 -c10 -d120 http://192.168.137.248:30000
运行结束会显示如下结果
10 threads and 10 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 6.61ms 15.40ms 418.80ms 90.63%
Req/Sec 177.20 135.77 772.00 53.58%
77331 requests in 2.00m, 10.45MB read
Socket errors: connect 0, read 77331, write 0, timeout 0
Requests/sec: 643.89
Transfer/sec: 89.13KB
这个结果simple_http服务每秒处理了643个请求,即我们所谓的QPS是643。
我们将压力加倍,启动20个线程,20个连接。
wrk -t20 -c20 -d120 http://192.168.137.248:30000
Running 2m test @ http://192.168.137.248:30000
20 threads and 20 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 6.15ms 17.88ms 455.17ms 92.87%
Req/Sec 120.62 125.10 0.86k 81.23%
77893 requests in 2.00m, 10.53MB read
Socket errors: connect 0, read 77893, write 0, timeout 0
Requests/sec: 648.62
Transfer/sec: 89.79KB
可以看到QPS是648,和之前的QPS(643)相差不大。我们可以认为simple_service已经抗压到极限了。
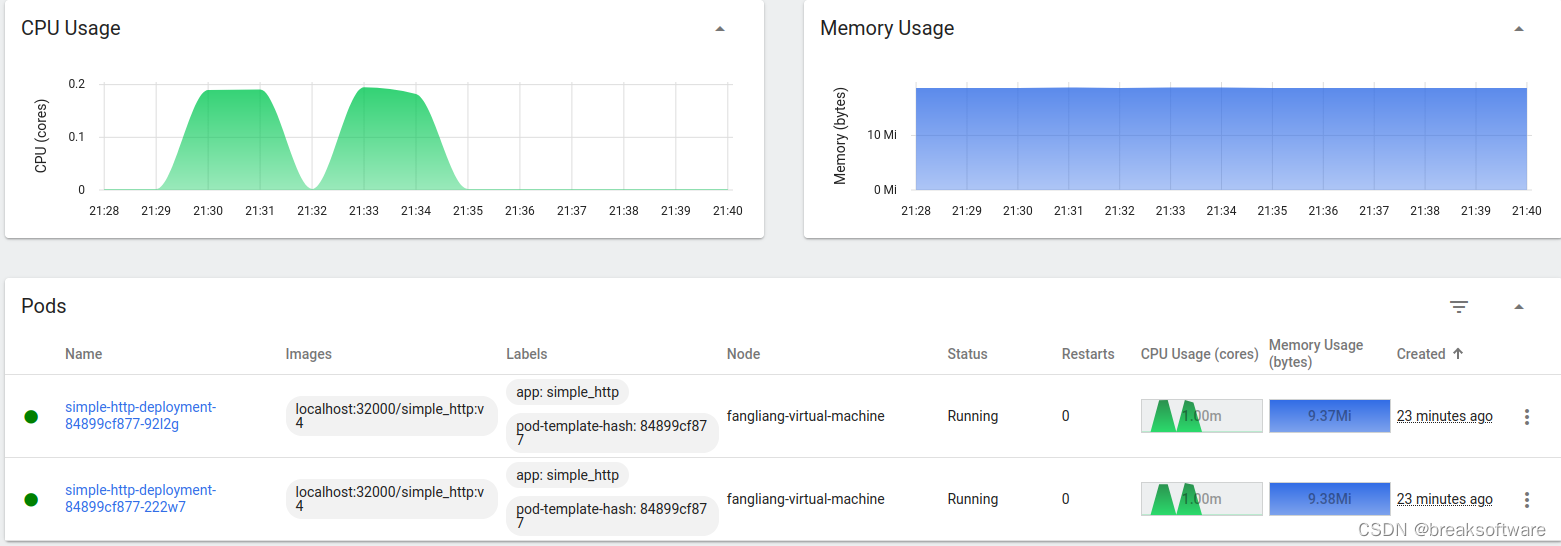
下图是所有Pod的资源使用情况。因为我们每个Pod只有一个容器,每个容器CPU上限是0.1——即我们看到两个Pod的CPU使用最高是0.2。
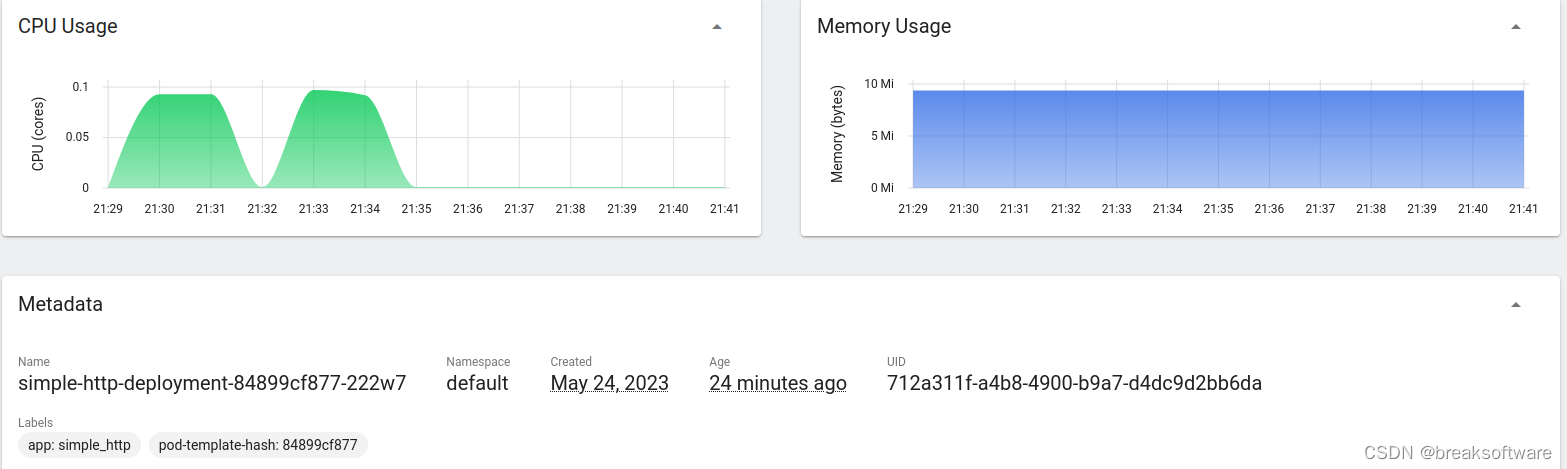
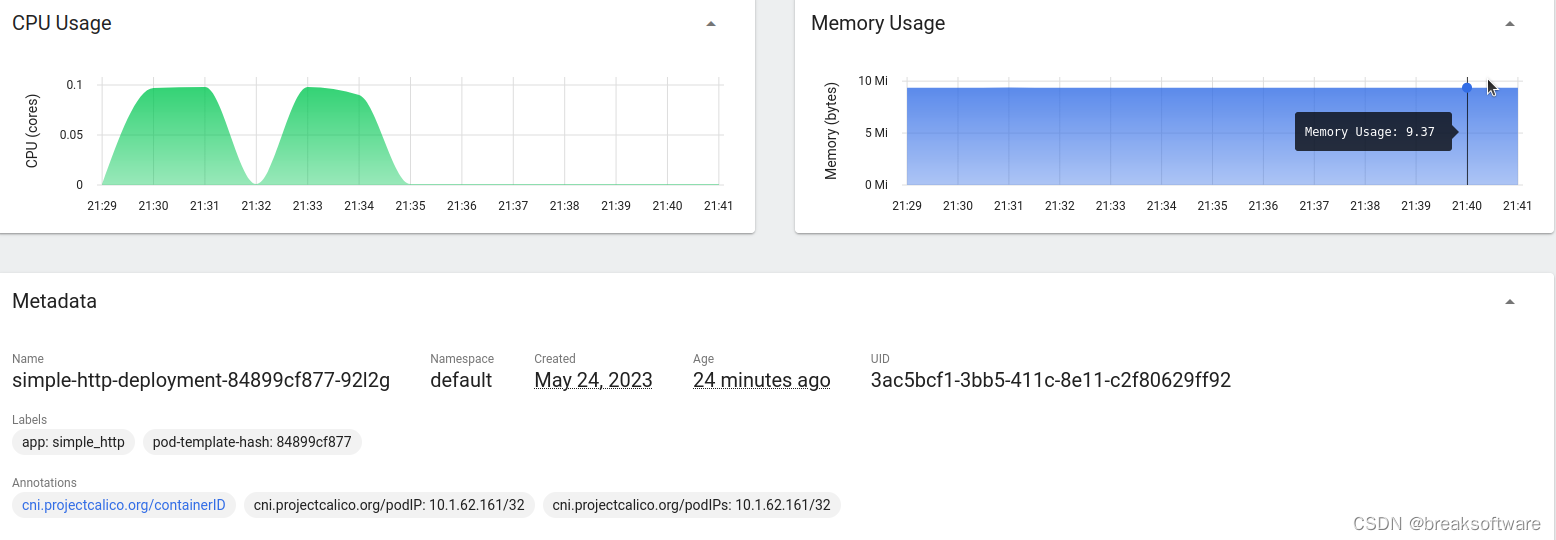
下面两个图是每个Pod的资源使用情况。可以看到每个容器都在0.1个CPU核配额之下运行。
修改配额
我们将CPU配额从100毫核调整到200毫核,看看simple_http_service抗压能力是否有1倍的提升。
# simple_http_deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: simple-http-deployment
spec:
replicas: 2
selector:
matchLabels:
app: simple_http
template:
metadata:
labels:
app: simple_http
spec:
containers:
- name: simple-http-container
image: localhost:32000/simple_http:v4
ports:
- containerPort: 8888
command: ["python","main.py","-port","$(SERVER_PORT)"]
env:
- name: SERVER_PORT
value: "8888"
resources:
limits:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: simple-http-service
spec:
type: NodePort
selector:
app: simple_http
ports:
- port: 80
targetPort: 8888
nodePort: 30000
只做了resources.limit.cpu的修改,然后我们提交这个文件
kubectl apply -f simple_http_deployment.yaml
稍微等一会儿,待新Pod创建完成并运行(老的Pod会被删除)。
然后我们再使用wrk进行压测
wrk -t20 -c20 -d120 http://192.168.137.248:30000
Running 2m test @ http://192.168.137.248:30000
20 threads and 20 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 2.33ms 9.79ms 429.11ms 97.27%
Req/Sec 258.82 299.89 2.02k 76.98%
153609 requests in 2.00m, 20.77MB read
Socket errors: connect 0, read 153609, write 0, timeout 0
Requests/sec: 1279.56
Transfer/sec: 177.13KB
可以看到QPS上升了接近一倍(之前是648)。
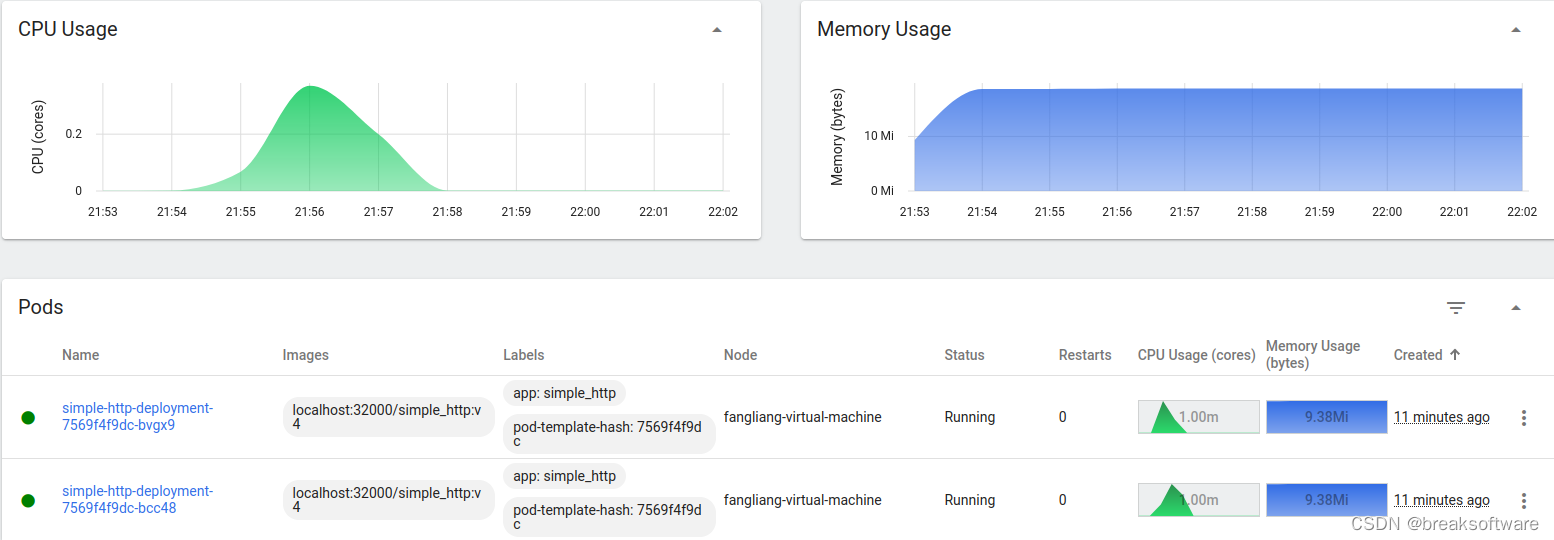



















 1502
1502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











