




 本文介绍了如何使用RNN(循环神经网络)对时序数据进行建模,包括一对一和多对一模型。重点讨论了简单RNN模型在IMDB影评文本分类任务中的应用,解释了为何需要双曲正切激活函数,并展示了模型的搭建过程、训练和评估。此外,还探讨了简单RNN的优点和局限性,以及参数数量的计算。文章最后提到了通过改变模型结构以利用所有RNN状态来提高模型性能的方法。
本文介绍了如何使用RNN(循环神经网络)对时序数据进行建模,包括一对一和多对一模型。重点讨论了简单RNN模型在IMDB影评文本分类任务中的应用,解释了为何需要双曲正切激活函数,并展示了模型的搭建过程、训练和评估。此外,还探讨了简单RNN的优点和局限性,以及参数数量的计算。文章最后提到了通过改变模型结构以利用所有RNN状态来提高模型性能的方法。
文章目录
一、How to model sequential data?(怎样对时序数据建模)
1.1 one to one模型
one to one模型:一个输入对应一个输出。包括:全连接神经网络和卷积神经网络。
人脑并不需要one to one模型来处理时序数据,并不会把一整段文字直接输入大脑。
- 整体处理一个段落。
- 固定大小的输入(例如图像)。
- 固定大小的输出(例如,预测概率)。
1.2 many to one模型
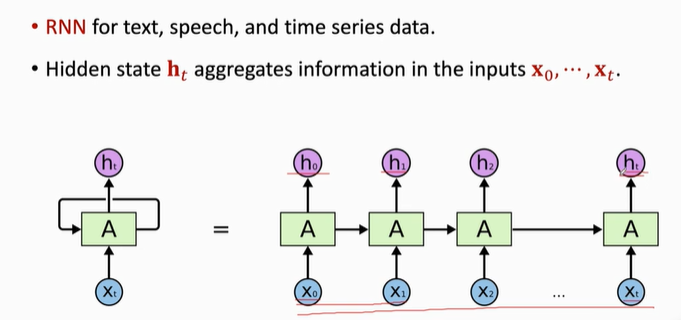
RNNs对于输入和输出的长度都不需要固定
RNNs适合文本,语音,时序序列数据
更新状态向量h的时候,需要参数矩阵A。整个RNNs只有一个参数A,A随机初始化,然后利用训练数据来学习A。
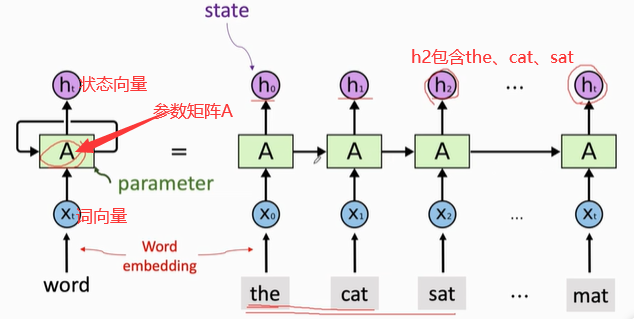
二、Simple RNN Model(简单循环神经网络)
矩阵和向量的乘积是一个向量。
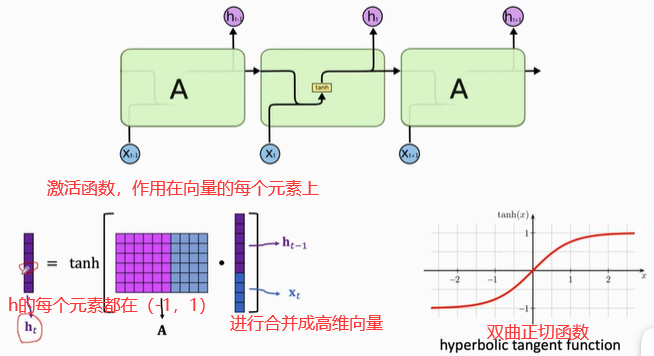
问题:Why do we need the tanh function?(为什么需要双曲正切函数作为激活函数)
答:每次让h恢复到(-1,+1)之间。
训练参数:矩阵A
- A的行:shape(h)
- A的列:shape(h)+shape(x)
- 矩阵A的大小=shape(h)× [ shape(h)+shape(x)]
2.1 Simple RNN for IMDB Review
from keras.models import Sequential
from keras.layers import SimpleRNN,Embedding,Dense
# 设置超参数
vocabulary = 10000 # 词典里面有10000个词汇
embedding_dim=32 # shape(x)=32,词向量x的维度为32
word_num = 500 # 每个电影评论有500个单词,如果超过500个单词,就会被截掉;如果不到500,就会补够。
state_dim =32 # shape(h) = 32,状态向量h的维度为32
# 开始搭建网络
model = Sequential() # 建立Sequential()模型
# 往model里面加层,Embedding层,把词映射成向量
model.add(Embedding(vocabulary,embedding_dim,input_length=word_num))
# 需要指定状态向量h的维度,设置RNN层的return_sequences=False,表示RNN只输出最后一个状态向量h,把之前的状态向量舍去。
model.add(SimpleRNN(state_dim,return_sequences=False))
# 全连接层,输入RNN的最后一个状态h,输出0-1之间的数
model.add(Dense(1, activation="sigmoid"))
model.summary()

from keras import optimizers
# 迭代最大次数
epochs = 3 # Early stopping alleviates overfitting
# 编译模型
# 指定算法为 RMSprop,loss为损失函数,metrics为评价标准
model.compile(optimizer = optimizers.RMSprop(lr=0.001),
loss="binary_crossentropy",metrics=["acc"])
# 用训练数据来拟合模型,
history=model.fit(x_train,y_train,epochs=epochs,
batch_size=32,validation_data=(x_valid,y_valid))

# 用测试数据来评价模型的表现
# 把测试数据作为输入,返回loss 和 acc。
loss_and_acc = model.evaluate(x_test,labels_test)
print("loss = " + str(loss_and_acc[0]))
print("acc = " + str(loss_and_acc[1]))

2.2 改动
刚才搭建模型只使用了RNN的最后一个状态ht ,把之前的状态全部舍去了。
如果返回所有状态,RNN的输出为一个矩阵,矩阵的每一行为一个状态向量h。
如果用所有状态,则需要加一个Flatten层,把状态矩阵变成一个向量。然后把这个向量作为分类器的输入,进行判断。
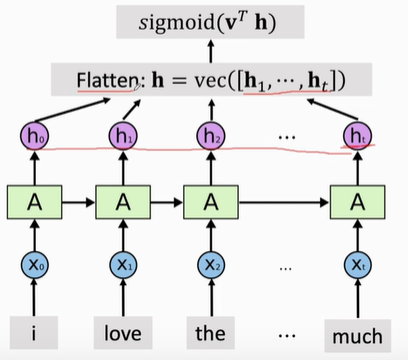
from keras.models import Sequential
from keras.layers import SimpleRNN,Embedding,Dense
# 设置超参数
vocabulary = 10000 # 词典里面有10000个词汇
embedding_dim=32 # shape(x)=32,词向量x的维度为32
word_num = 500 # 每个电影评论有500个单词,如果超过500个单词,就会被截掉;如果不到500,就会补够。
state_dim =32 # shape(h) = 32,状态向量h的维度为32
# 开始搭建网络
model = Sequential() # 建立Sequential()模型
# 往model里面加层,Embedding层,把词映射成向量
model.add(Embedding(vocabulary,embedding_dim,input_length=word_num))
# 需要指定状态向量h的维度,设置RNN层的return_sequences=False,表示RNN输出所有状态
model.add(SimpleRNN(state_dim,return_sequences=True))
model.add(Flatten())
# 全连接层,输入RNN的最后一个状态h,输出0-1之间的数
model.add(Dense(1, activation="sigmoid"))
model.summary()
2.3 优缺点
good of SimpleRNN(优点):
- RNN擅长在短期文本依赖(RNN只需看最近的几个词即可)
Shortcomings of SimpleRNN(缺点):
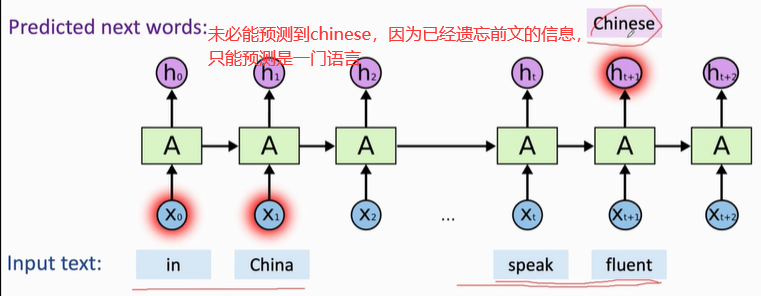
- RNN的记忆较短,会遗忘很久之前的输入X;
- 如果时间序列很长,好几十步,最终的ht 忘记之前的输入X0
2.4 Summary(总结)
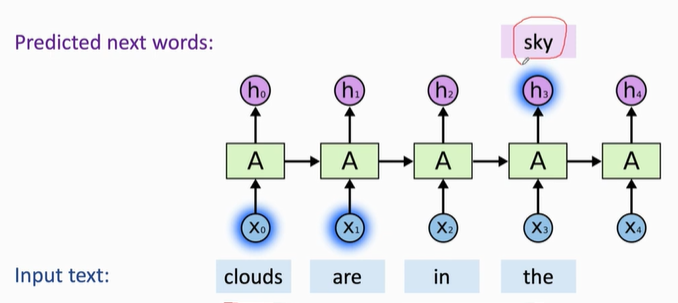
ht 包含了之前所有的输入信息
2.5 Number of Parameters
- SimpleRNN has a parameter matrix (and perhaps an intercept vector).
- Shape of the parameter matrix is
shape(h)× [ shape(h)+shape(x)]
- 参数矩阵一开始随机初始化,然后从训练数据中学习这个参数矩阵A,
训练参数:矩阵A
- A的行:shape(h)
- A的列:shape(h)+shape(x)
说明:简单循环神经网络只有一个参数矩阵A,不论这个序列有多长,所有模块里面的参数都是一样的。


















 660
660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











