



 文章描述了一个利用deeplabv3+模型对图像进行检测和分割,进而自动标注并生成json文件的过程。首先,加载预训练模型进行图像分析;接着,判断分割区域并选择最大连通区域;然后,找到边缘点并依次连接形成边界;最后,提供了一个将生成的json与图片配合labelme工具进行查看的方法。代码可在GitHub上获取。
文章描述了一个利用deeplabv3+模型对图像进行检测和分割,进而自动标注并生成json文件的过程。首先,加载预训练模型进行图像分析;接着,判断分割区域并选择最大连通区域;然后,找到边缘点并依次连接形成边界;最后,提供了一个将生成的json与图片配合labelme工具进行查看的方法。代码可在GitHub上获取。
利用deeplabv3+检测处理的mask结果,自动生成json文件;可以对新的图像样本数据进行自动标注;该代码只适合单个样本标注,如果需要多个样本标注,可以此基础上扩展
步骤:
(1)、加载deeplabv3+训练得到的pb模型,对需要标注的图片进行检测,得到分割区域,seg_map
(2)、判断分割区域的大小,如果小于整幅图像的一定尺寸,则认为没有目标,不进行标注;否则,进入下一步
(3)、利用two-pass寻找各个连同区域,找出最大区域
(4)、寻找最大区域的边缘点
(4)、任选一点作为起始点;以该点为基础,寻找距离该点最近的点;找到最近的点之后,再以此点为基础点,寻找距离最近的点,以此类推;直到最后一个边缘点
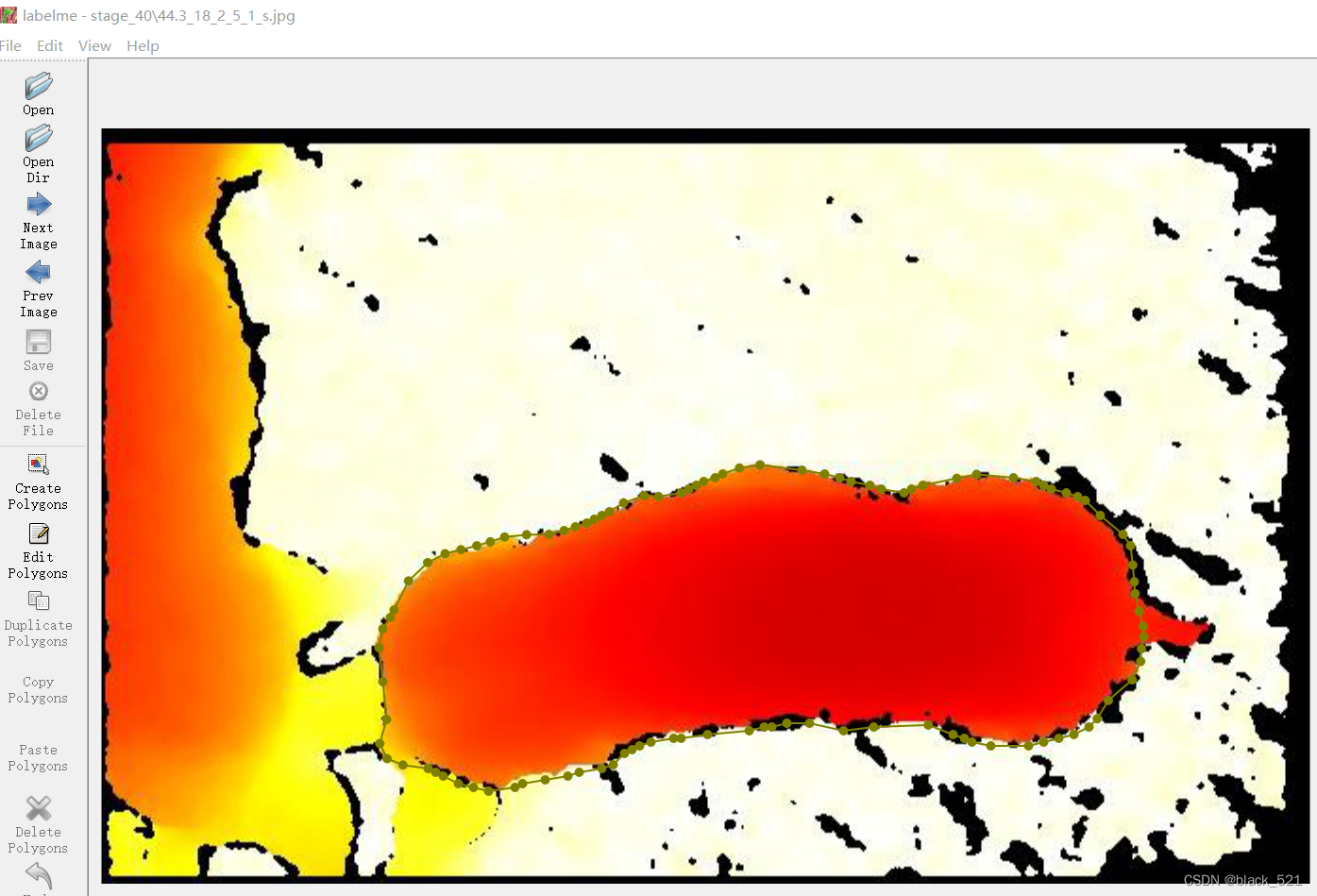
例如:将生成的json文件放到jsons文件夹下,图片放到stage_40文件夹下,运行labelme,如下:
./labelme32.exe stage_40 --output ./jsons_modify --nodata --autosave --labels labels.txt
打开labelme界面,图片上自动标注
具体python代码下载地址:https://github.com/blackshan88/pytorch_deeplab_v3_plus

















 8610
8610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









