 TensorFlow:谷歌的深度学习框架解析
TensorFlow:谷歌的深度学习框架解析





 TensorFlow是谷歌GoogleBrain实验室开发的深度学习框架,始于2015年,支持多平台运行,包括TensorFlowLite针对移动设备。其核心是数据流图,通过构建节点和边来表示计算过程。TensorFlow内置多种深度学习模型,如Keras,并在AlphaGo项目中发挥了关键作用。框架支持CPU和GPU运算,依赖CUDA进行GPU加速。
TensorFlow是谷歌GoogleBrain实验室开发的深度学习框架,始于2015年,支持多平台运行,包括TensorFlowLite针对移动设备。其核心是数据流图,通过构建节点和边来表示计算过程。TensorFlow内置多种深度学习模型,如Keras,并在AlphaGo项目中发挥了关键作用。框架支持CPU和GPU运算,依赖CUDA进行GPU加速。
目录
概述
Tensor Flow是谷歌Google Brain实验室维护开发的,它于2015年11月9日发布第一个初始版本,遵循Apache 2.0开源协议,经过变迁第一个稳定版本是1.12.0在2018年10月9日发布,它支持跨平台能够在WIn、Linux、Unix上稳定运行。Tensor Flow Lite是Tensor Flow的一个分支,它基于Tensor Flow,它的目标是在移动设备、最小单片机设备上运行,所以它被设计的非常简洁,它也被简称为tflite,除了Tensor Flow Lite以外还有TensorFlow Hub、TensorFlow Research Cloud,这些分支都是针对不同的环境研发的。
Tensor Flow强大的地方在于它内置了许多深度学习算法框架模型,比如keras,目前Keras作者已经加入谷歌了,所以Keras目前可以说是谷歌官方API,若我们直接去使用这些开源框框架的话对初学者不是那么友好,使用起来较为复杂,但经过Tensor Flow的一层封装后使得模型统一使用流程图的方式,变得简单了许多,并且它也提供了许多推荐参数,所以大多数的参数我们是不需要自己去设置的。
AlphaGo就是基于Tensor Flow训练的
发展历史
Tensor Flow是谷歌旗下的Google Brain实验室开发的,Google Brain是谷歌旗下专门研发AI算法与框架的实验室,它是由Python、C++、C三款语言开发而成,它目前对Python支持API最全面,最完善,对C++的API接口支持并没有Python完善,同时它也支持Java不过目前仅是实验版本,支持的API接口非常有限。
Google Brain于2015年11月9号发布第一个Bate版本,历经3年左右时间迭代研发在2018年10月9日推出了第一个完整AI生态链的AI框架:1.12.0,Tensor Flow支持CPU与GPU运算,甚至支持可以选用多少核来做训练运算,对GPU的运算使用了CUDA框架,CUDA是NVIDIA(英伟达)开发的一套用于在NVIDIA显卡上进行并行运算的架构,GPU的运算效率要高于CPU,因为它不需要像CPU那样去处理大量的指令集,它只需要去处理运算数据就可以了,因为它的工作仅仅是显示图像,随着计算机的发展GPU的能力已经提升至非常强大了,所以只用来做图像数据的处理显然有点屈GPU了,所以GPU厂商开放了对GPU控制的API接口,用于开发者们来调用GPU做运算,由于Tensor Flow仅支持CUDA加速所以如果想要在GPU上进行Tensor Flow的训练必须要求你的GPU是支持CUDA的。
真正让Tensor Flow闻名的是AlphaGo,谷歌使用Tensor Flow训练了AlphaGo,并在2016年开始向各大围棋高手进行挑战,并取得最终胜利。
数据流图
Tensor Flow从名字就可以看出它的中心思想是什么,tensor:张量(即多维数组),flow :流动,即多维数据流动式的处理,就像水一样从一端起点流向另外一端终点在流动的过程中会每流动一次进行一次运算,其中每次处理都视为一个节点,所以这个流程很像流程图,所以Tensor Flow把这种处理数据的方式称为数据流图,这也是Tensof Flow的核心所在,只要数据能够转化为向量那么Tensor Flow就可以按照数据流的方式对它进行处理。
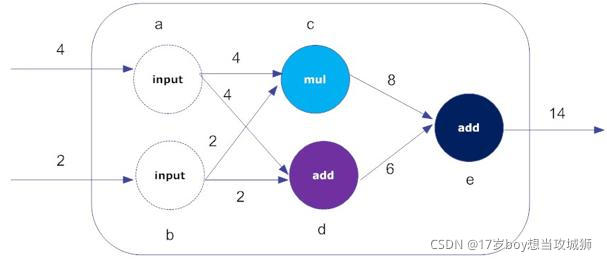
从上图需要理解一个东西叫做:边,边即起始输入数据源,上图的Input A与B都是边,即最外边最开始的视图节点称为边,后续的称为运算节点,一般边就是输入的向量。
从边出发选择流动的方向,如“A”流动到“D”同时也会流动到“C”,最终流动到”E“,B也是如此,这些流动的顺序需要注意在一开始就已经在代码里定好的,是有序的流动,它不是无序的流动。
Tensor Flow会用结构体将每个要处理的向量数据存储到子成员变量中,然后在用类似链表指针的方式指向每个向量数据要处理的下一层要执行的函数,最后开始调用一层一层往下走,需要注意它不是无序的。
你可以把数据流图理解为Tensor Flow执行顺序的一个流程可视化,其次每次的数据传递都会是一个副本!
从上图还可以看到有许多分叉的连接与直线,直线是直接依赖,分叉线是间接依赖,可以看到“D”直接依赖于“B”,间接依赖于“A”,如果其中有一条依赖不满足都不会去执行“D”,这在流程图较大的情况下非常有效,可以有效省去一些不满足依赖的运算,比如我只想执行流程图中“D”节点,只需要满足“D”的依赖就可以了,其它的依赖一律不管,这样Tensor Flow在执行流程图时会自动判断依赖条件,选择性的执行节点。
基本架构
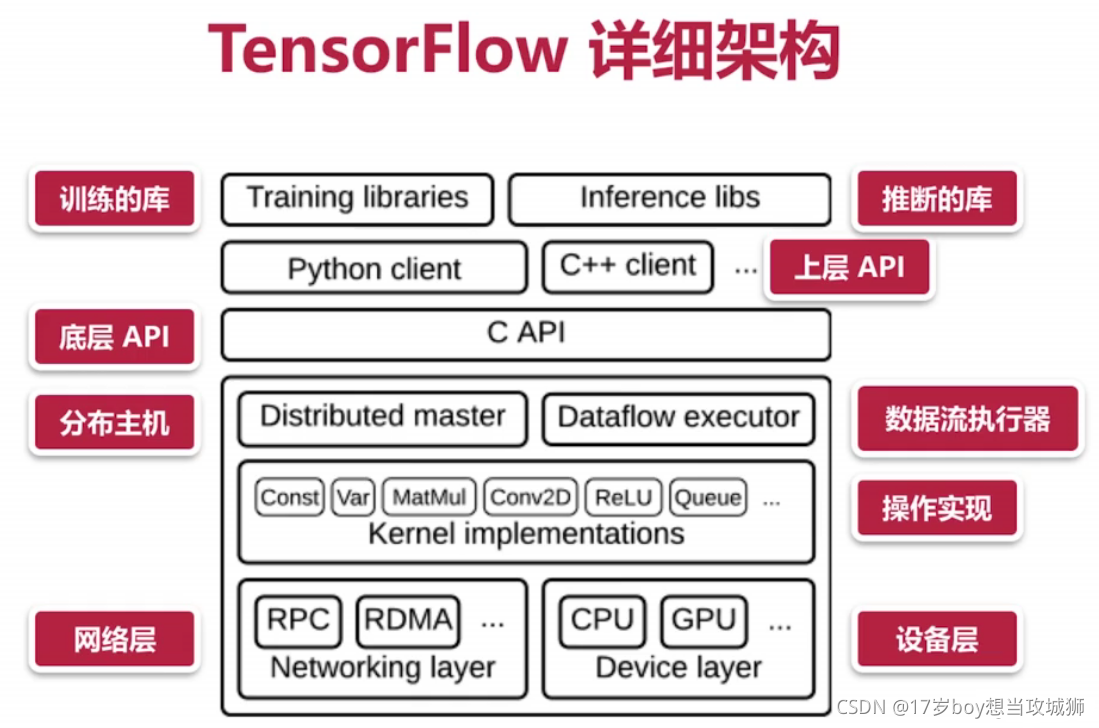
可以看到最底层API是C语言写的,这也代表Tensor Flow的移植性非常高



















 1492
1492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











