



一、MPI 是什么?
1. 并行计算的三种模式
|
模式 |
特点 |
典型工具 |
|---|---|---|
|
共享内存(Shared Memory) |
多线程访问同一内存空间 |
OpenMP, Pthreads |
|
分布式内存(Distributed Memory) |
每个节点有独立内存,通过网络通信 |
MPI |
|
混合模型(Hybrid) |
结合两者优势,节点内用 OpenMP,节点间用 MPI |
MPI + OpenMP/CUDA |
MPI:主要用于分布式内存系统,适合跨多个服务器节点的大规模并行任务。
2. MPI 的设计理念
MPI 是一种标准化的消息传递库接口,定义了进程之间如何发送和接收数据。其核心思想是:
-
每个计算单元是一个独立的进程(process)
-
进程之间不共享内存,必须通过显式调用 MPI_Send / MPI_Recv 来交换信息
-
所有通信操作都基于“通信子”(communicator),最常用的是 MPI_COMM_WORLD
关键优势:
-
可扩展性强:可运行于双核笔记本到百万核超算
-
跨平台兼容:支持Linux、Windows、macOS和各种架构(x86、ARM、GPU)
-
生态成熟:几乎所有科学计算软件底层都依赖 MPI
3. MPI 的应用地位
|
应用领域 |
使用场景 |
是否依赖 MPI |
|---|---|---|
|
气象预报(WRF) |
大气网格划分与同步更新 |
是 |
|
流体力学(OpenFOAM) |
分布式求解 Navier-Stokes 方程 |
是 |
|
分子动力学(LAMMPS) |
粒子间力的并行计算 |
是 |
|
地震波模拟(SPECFEM3D) |
波场传播的域分解 |
是 |
|
AI 数据预处理 |
分布式读取 TFRecord/HDF5 文件 |
可选但高效 |
统计数据:据 Open MPI 官方报告,超过 90% 的 Top500 超算系统默认安装 MPI 实现。
(1) HPC 集群典型架构图
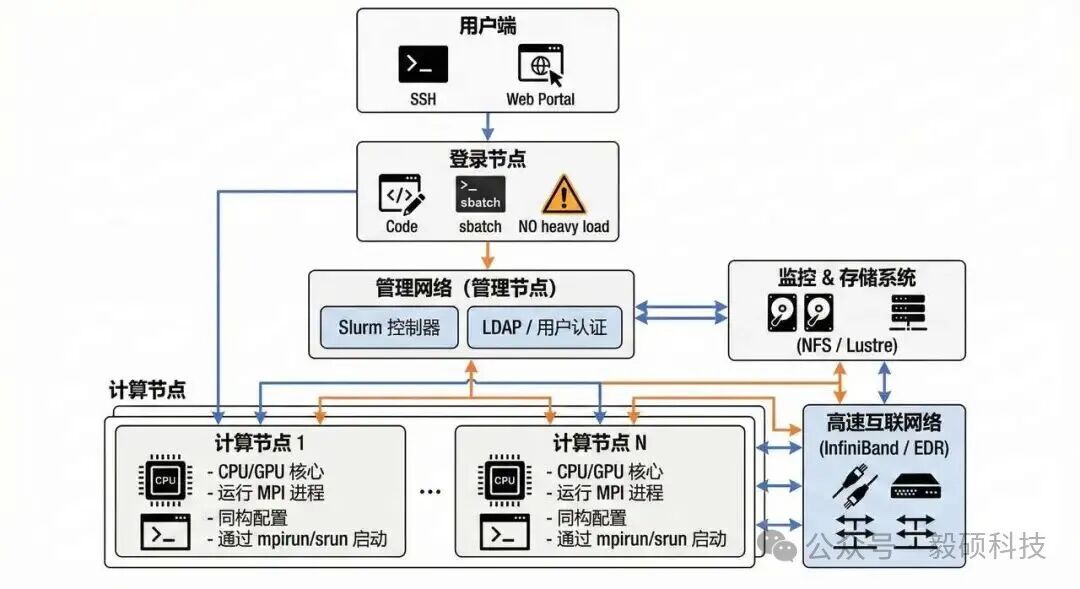
-
橙色线:通常代表管理和控制流程。它连接了管理节点(包含Slurm控制器和LDAP认证)到计算节点和存储系统。这些连线用于传输作业调度指令、用户认证信息、监控数据以及配置管理等控制信号。
-
蓝色线:通常代表数据和用户交互流程。它连接了用户端到登录节点,登录节点到管理节点,以及计算节点到存储系统和高速互联网络。这些连线用于传输用户上传/下载的文件、计算节点读取/写入的数据、以及计算节点之间的高速通信数据(如MPI消息)。
(2) MPI 点对点通信流程图
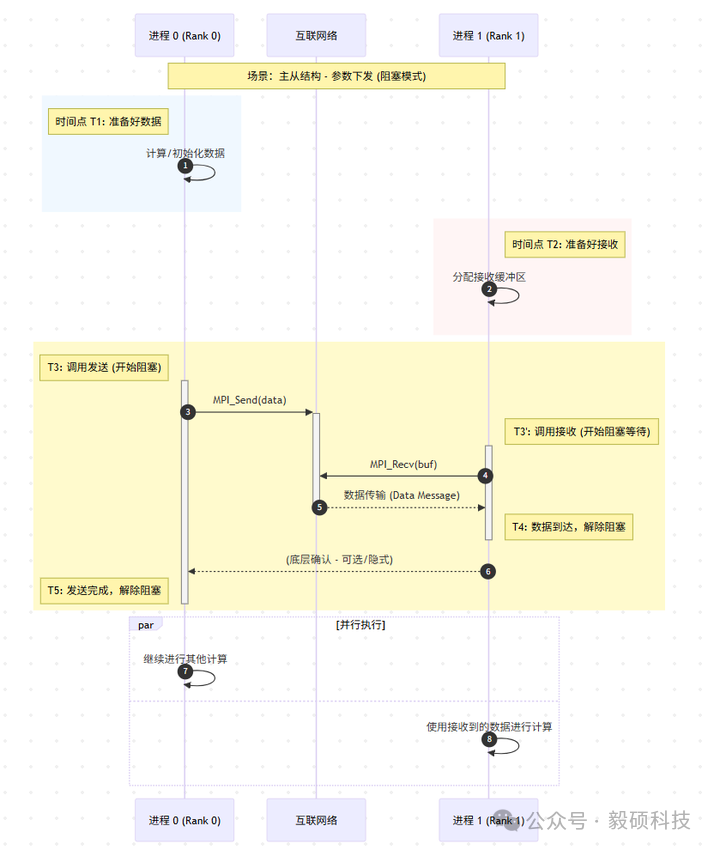
-
方向:单向传输(阻塞模式)
-
用途:主从结构中的参数下发、结果回收
-
阻塞表现:
-
在 Rank 1,进入 MPI_Recv 到 数据到达 之间的时间段,进程处于等待状态,不能做其他事情,这就是阻塞接收。
-
在 Rank 0,进入 MPI_Send 到 发送完成 之间,进程必须确保数据安全发出(通常意味着发送缓冲区可以安全修改了)才能继续,这也是阻塞发送。
-
发送先于接收:虽然两个进程可能在不同时间点调用函数,但数据传输动作本身(斜线箭头)必须始于发送方,终于接收方。Rank 1 即使很早就调用了 Recv,也必须等到 T4 时刻数据真正到达才算完成。
(3) MPI 集合通信 — Allreduce 示例
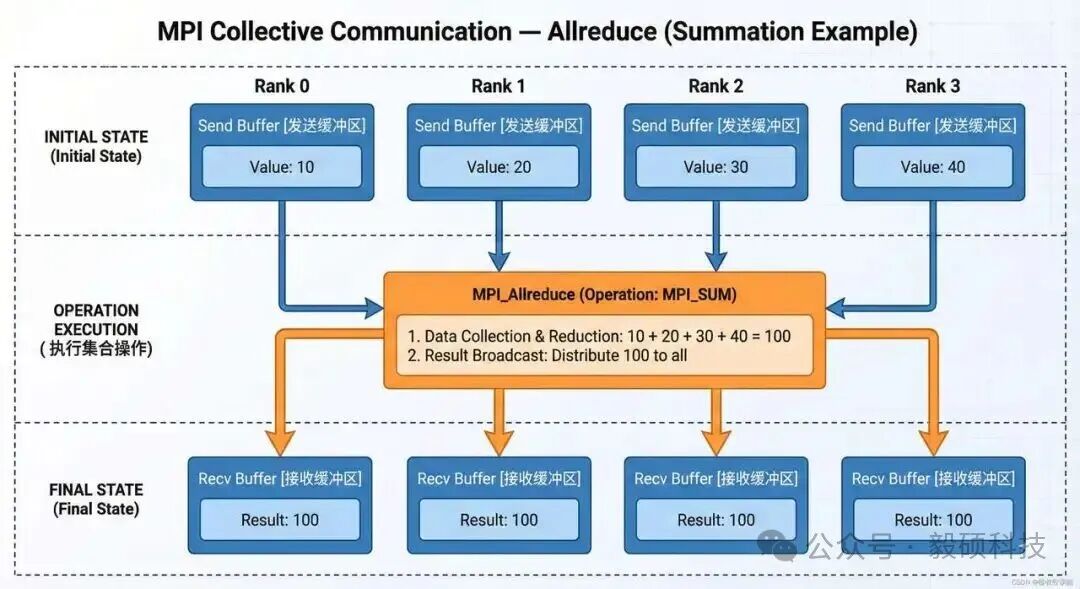
所有进程最终获得相同的结果(如梯度平均),常用于 AI 分布式训练。
二、搭建你的第一个 MPI 开发环境
1. 安装 MPI 实现库(推荐 OpenMPI 或 MPICH)
-
Ubuntu/Debian
sudo apt update
sudo apt install openmpi-bin libopenmpi-dev
-
CentOS/RHEL/Rocky Linux
sudo dnf install openmpi openmpi-devel
CentOS 7推荐安装 openmpi3 ,openmpi 的版本过低:
sudo yum install openmpi3 openmpi3-devel
推荐选择 OpenMPI:社区活跃、文档丰富、支持 GPU 直接通信(CUDA-aware)
2. 编译与运行环境配置
-
加载openmpi模块:
module load mpi/openmpi3-x86_64
如果出现 -bash: module: command not found,使用source /etc/profile.d/modules.sh再加载
-
确保已安装:
-
GCC 编译器(gcc, g++ )
-
mpicc(MPI C 编译器封装脚本,安装openmpi3-devel即默认安装)
-
-
验证安装:
mpirun --version
mpicc --showme
输出应类似:
mpirun (Open MPI) 3.1.3
...
3. 在本地多核机器上测试 MPI 程序
创建测试目录:
mkdir ~/mpi-demo && cd ~/mpi-demo
编写一个简单的 hello.c:
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv) {
MPI_Init(&argc, &argv);
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
printf("Hello from process %d of %d\n", rank, size);
MPI_Finalize();
return 0;
}
编译并运行:
mpicc -o hello hello.c
mpiexec -n 8 ./hello
输出:

如果出现:
[1764820148.412669] [compute01:10228:0] sys.c:618 UCX ERROR shmget(size=2097152 flags=0xfb0) for mm_recv_desc failed: Operation not permitted, please check shared memory limits by 'ipcs -l'
[1764820148.414829] [compute01:10229:0] sys.c:618 UCX ERROR shmget(size=2097152 flags=0xfb0) for mm_recv_desc failed: Operation not permitted, please check shared memory limits by 'ipcs -l'
[1764820148.412682] [compute01:10230:0] sys.c:618 UCX ERROR shmget(size=2097152 flags=0xfb0) for mm_recv_desc failed: Operation not permitted, please check shared memory limits by 'ipcs -l'
[1764820148.414706] [compute01:10233:0] sys.c:618 UCX ERROR shmget(size=2097152 flags=0xfb0) for mm_recv_desc failed: Operation not permitted, please check shared memory limits by 'ipcs -l'
[1764820148.416116] [compute01:10235:0] sys.c:618 UCX ERROR shmget(size=2097152 flags=0xfb0) for mm_recv_desc failed: Operation not permitted, please check shared memory limits by 'ipcs -l'
[1764820148.421206] [compute01:10236:0] sys.c:618 UCX ERROR shmget(size=2097152 flags=0xfb0) for mm_recv_desc failed: Operation not permitted, please check shared memory limits by 'ipcs -l'
[1764820148.421431] [compute01:10237:0] sys.c:618 UCX ERROR shmget(size=2097152 flags=0xfb0) for mm_recv_desc failed: Operation not permitted, please check shared memory limits by 'ipcs -l'
[1764820148.421575] [compute01:10239:0] sys.c:618 UCX ERROR shmget(size=2097152 flags=0xfb0) for mm_recv_desc failed: Operation not permitted, please check shared memory limits by 'ipcs -l'
Hello from process 0 of 8
Hello from process 1 of 8
Hello from process 2 of 8
Hello from process 3 of 8
Hello from process 4 of 8
Hello from process 5 of 8
Hello from process 6 of 8
Hello from process 7 of 8
这是OpenMPI + UCX(Unified Communication X)在 CentOS 7 上因共享内存限制导致的警告:
-
查看当前共享内存限制
ipcs -l
------ Messages Limits --------
max queues system wide = 32000
max size of message (bytes) = 8192
default max size of queue (bytes) = 16384
------ Shared Memory Limits --------
max number of segments = 4096
max seg size (kbytes) = 18014398509465599
max total shared memory (kbytes) = 18014398442373116
min seg size (bytes) = 1
------ Semaphore Limits --------
max number of arrays = 128
max semaphores per array = 250
max semaphores system wide = 32000
max ops per semop call = 32
semaphore max value = 32767
可以看到:max seg size (kbytes) = 18014398509465599,限制已经非常大(接近无限),不用修改
-
检查 /etc/security/limits.conf
nano /etc/security/limits.conf
# 添加如下内容:
# Increase SHM limits for MPI
* soft memlock unlimited
* hard memlock unlimited
* soft nofile 65536
* hard nofile 65536
-
步骤 3:启用 PAM limits
# 确保 SSH 登录时加载 limits。编辑:
sudo nano /etc/ssh/sshd_config
# 确认包含:
UsePAM yes
# 若没有包含,则添加后重启 sshd:
sudo systemctl reload sshd
三、MPI 基础编程入门(C语言为例)
1. 初始化与终止
MPI_Init(&argc, &argv); // 必须第一个调用
// ... 中间写并行逻辑 ...
MPI_Finalize(); // 必须最后一个调用
2. 获取进程身份
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD, &rank); // 当前进程编号(从0开始)
MPI_Comm_size(MPI_COMM_WORLD, &size); // 总共多少个进程
3. 点对点通信:发送与接收
if (rank == 0) {
int data = 100;
MPI_Send(&data, 1, MPI_INT, 1, 0, MPI_COMM_WORLD);
} else if (rank == 1) {
int buf;
MPI_Recv(&buf, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
printf("Received: %d\n", buf);
}
注意:MPI_Recv 必须等待对应 Send 到达才会返回(阻塞式)
4. 集合通信初探
(1) 广播(Broadcast)
int value;
if (rank == 0) value = 42;
MPI_Bcast(&value, 1, MPI_INT, 0, MPI_COMM_WORLD); // 所有进程都得到 value=42
(2) 归约(Reduce)—— 主从结构汇总
int local_sum = rank * 10;
int global_sum;
MPI_Reduce(&local_sum, &global_sum, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD);
if (rank == 0) {
printf("Total sum = %d\n", global_sum);
}
(3) 数据分发与收集
int send_data[4] = {10, 20, 30, 40};
int recv_item;
MPI_Scatter(send_data, 1, MPI_INT, &recv_item, 1, MPI_INT, 0, MPI_COMM_WORLD);
printf("Rank %d received %d\n", rank, recv_item);
输出(假设 n=4):
Rank 0 received 10
Rank 1 received 20
Rank 2 received 30
Rank 3 received 40
四、编译与运行 MPI 程序
1. 编译命令
mpicc -o myprogram myprogram.c # 编译
mpiexec -n 8 ./myprogram # 运行8个进程
2. 本地跨核运行
强制绑定到特定CPU核心(提升缓存效率)
mpiexec --bind-to core -n 4 ./hello
3. 跨节点运行前提
-
所有节点安装相同版本的 MPI
-
配置无密码 SSH 通信
-
使用共享文件系统(NFS/Lustre),保证每个节点都能访问可执行文件
五、在真实 HPC 集群中运行 MPI 作业( Slurm 为例 )
1. HPC 集群典型工作流
[用户] → 编辑代码 → 提交 .job 脚本 → [Slurm 调度器] → 分配资源 → srun 启动 mpiexec → 计算节点运行 → 输出日志
2. 编写 Slurm 批处理脚本
保存为 run_mpi.job:
#!/bin/bash
#SBATCH --job-name=mpi_hello
#SBATCH --nodes=2
#SBATCH --ntasks-per-node=8
#SBATCH --time=00:10:00
#SBATCH --output=hello_%j.out
#SBATCH --error=hello_%j.err
# 加载模块(根据系统调整)
module load openmpi/openmpi3-x86_64
# 编译(可选:也可提前编译好)
mpicc -o hello hello.c
# 启动作业
srun mpiexec -n 16 ./hello
参数说明:
-
--nodes=2:使用2个计算节点
-
--ntasks-per-node=8:每节点启动8个 MPI 进程
-
总共 2×8=16 个进程
3. 提交与监控作业
-
提交
sbatch run_mpi.job
-
查看队列
squeue -u $USER
-
查看已完成作业统计
sacct -j <jobid>
-
查看输出
cat hello_*.out
4. 常见问题与解决方案
|
问题 |
原因 |
建议 |
|---|---|---|
|
Command 'mpicc' not found |
模块未加载 |
添加 module load openmpi |
|
作业长时间 pending |
队列拥塞 |
使用 sinfo 查看可用资源 |
|
运行时报错 “connection closed” |
SSH 或 OFED 驱动异常 |
联系管理员检查 InfiniBand 状态 |
六、进阶主题与最佳实践
1. 非阻塞通信:提升并行效率
MPI_Request req;
MPI_Isend(buffer, count, MPI_DOUBLE, dest, tag, MPI_COMM_WORLD, &req);
// 做其他计算...
do_local_work();
// 等待发送完成
MPI_Wait(&req, MPI_STATUS_IGNORE);
优点:通信与计算重叠,提高资源利用率
2. 性能调优建议
|
技巧 |
说明 |
|---|---|
|
合并小消息 |
减少通信次数,提升带宽利用率 |
|
使用拓扑通信 |
如 Cartesian topology 优化邻域通信 |
|
避免热点进程 |
均衡负载,防止主节点成为瓶颈 |
|
启用 CUDA-aware MPI |
GPU 显存直传,避免主机中转 |
3. 容器化支持:Apptainer/Singularity 中运行 MPI
-
构建包含 MPI 的容器镜像(Singularity definition file)
Bootstrap: docker
From: ubuntu:20.04
%post
apt update
apt install -y openmpi-bin libopenmpi-dev gcc
%runscript
exec mpiexec "$@"
-
构建并运行
singularity build mpi_container.sif Singularity.def
srun singularity run mpi_container.sif -n 16 ./my_mpi_app
优势:环境隔离、可复现、便于部署复杂依赖
七、真实行业案例解析
案例一:OpenFOAM 流体仿真中的 MPI 应用
-
背景:模拟汽车风阻系数
-
方法
-
使用 decomposePar 将网格划分为多个子域
-
每个子域由一个 MPI 进程负责计算
-
边界数据通过 MPI 实时交换
-
-
效果:原本需 72 小时的仿真缩短至 6 小时(使用 128 核)
案例二:天文 N 体模拟(Gadget-2)
-
挑战:百亿粒子间的引力计算
-
MPI 角色
-
Domain Decomposition 划分空间区域
-
All-to-All 通信交换远程粒子信息
-
Tree Algorithm 与 MPI 结合实现长程力计算
-
-
成果:成功模拟宇宙大尺度结构形成
案例三:金融蒙特卡洛期权定价
Python 伪代码(通过 mpi4py)
from mpi4py import MPI
import numpy as np
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
# 每个进程生成 10000 条路径
local_paths = generate_paths(n=10000)
local_price = np.mean(local_paths)
# 全局平均
global_price = comm.reduce(local_price, op=MPI.SUM, root=0)
if rank == 0:
final_price = global_price / size
print(f"期权价格估计: {final_price:.4f}")
本地机器8个进程测试:
mpiexec -n 8 python option_pricing.py
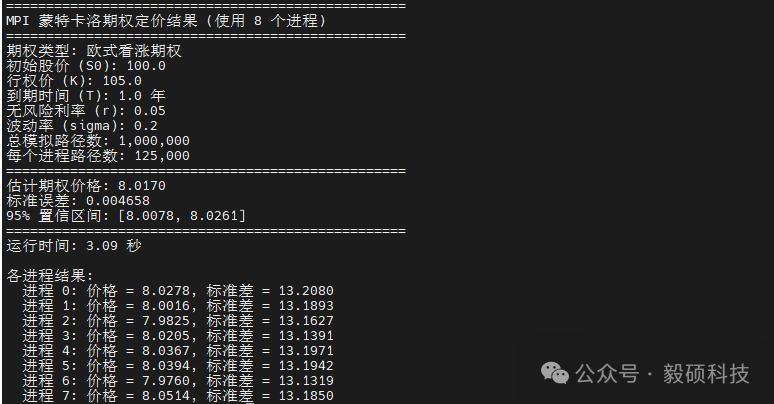
效果:100 万次模拟仅运行3.09秒(使用 8 进程)
八、总结
MPI 不仅仅是一种编程接口,它是连接算法与硬件之间的桥梁,是实现“算得更快、看得更远”的关键技术支撑。 通过本教程的学习,你应该已经能够:
-
理解 MPI 在 HPC 生态系统中的核心地位
-
编写基础的 MPI 程序并进行点对点与集合通信
-
在本地和 HPC 集群上成功编译、运行和调试 MPI 作业
-
理解其在科学计算与工程仿真中的典型应用场景
但这只是起点。随着异构计算(GPU+CPU)、混合编程模型(MPI + OpenMP/CUDA)的发展,MPI 正在与其他并行范式深度融合。

















 5897
5897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









