







文章目录
1.文件的读写相关操作
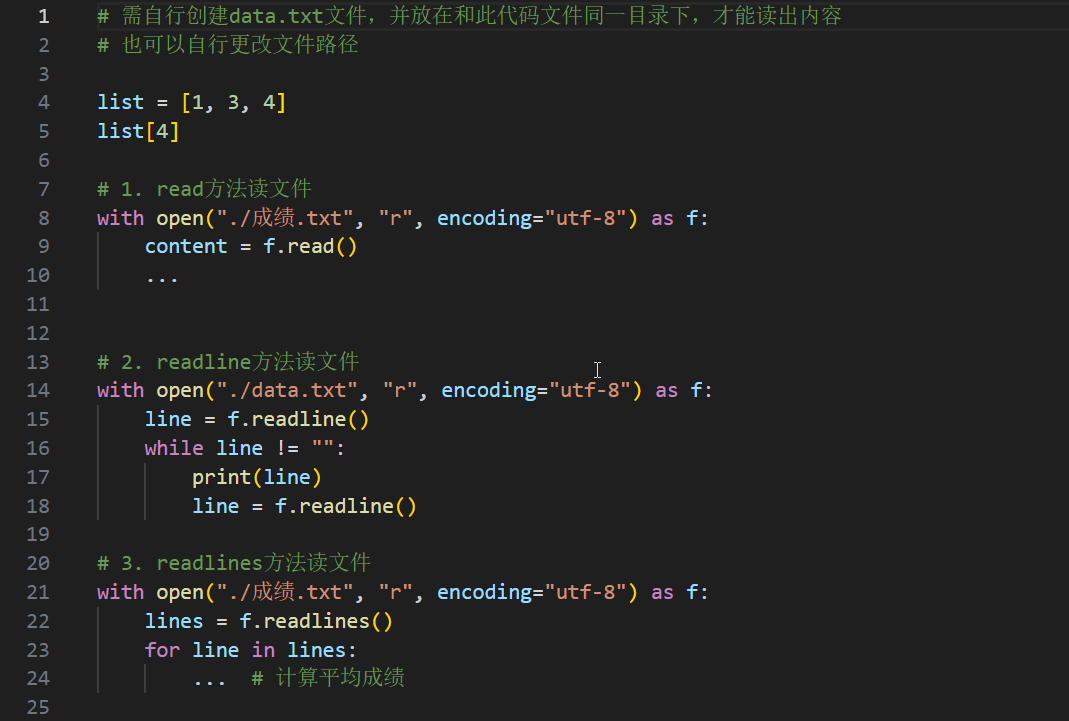
文件的这个读取,其实在我们的数学建模比赛里面用的很多,但是和下面的这个只是还是有区别的,下面的这个展示的是读取文本文件,但是我们数学建模比赛里面主要是读取的这个excel或者是csv之类的,这个是需要我们掌握的,但是下面的这个也可以看一下把,有一些部分还是相同的;
- 例如这个./表示的是当前路径下面(这个涉及到绝对路径和相对路径,不理解可以百度一下);
- r表示的是读取文件的操作,英文就是read操作吗,这个是一样的;
- encoding就是指的这个文件的编码的方式,字符集是utf-8,这个一般是默认的,但是可以写上去
- readline就是读取一行的数据,lines就是读取全部的数据;
上面的这个文件的读取,下面的这个是写入:
write对吧,所以这个和上面基本一致,就是这个r修改成为这个w就可以了,还有一点需要注意的是,我们多次写入的时候可能会出现覆盖的内容,就是第二次的覆盖掉第一次的,所以需要注意不要让他进行覆盖式的写入;
读取文件的时候,这个文件是必需要存在的,但是写入的时候,对应文件不存在也是没问题的,因为这个时候运行起来会自动创建;
刚开始文件里面没内容,直接使用w写入,然后这个时候文件有了内容,我们使用这个a进行文件内容的追加,就是不要让他覆盖式写入,这个是需要我们注意的;

2.异常,测试和高阶函数
关于这个内容,我觉得我们参加数学建模比赛了解这些东西用处不大,异常,测试,这些内容都是我们去写一个项目代码的时候需要考虑的,我们进行这个数学建模比赛时候的这个代码完全不至于到这个程度;
高阶函数就是函数的参数是一个函数,实际上类似于C语言里面的指针,我觉得这个我们比赛的也用不到,所以这个不分我不会展开说明,大家了解就可以了;
3.Numpy数组
这个部分就非常的重要了,这个是你学习数学建模必不可缺的一个步骤,numpy其实很常用,相当于这个99乘法表在数学学习里面的作用,看到这里,你是不是意识到了这个Numpy的重要性了;
numpy创建的是数组,其实这个数组长得和列表很像,但是有下面的两个区别:
- numpy数组里面的所有元素的这个数据类型都是一样的,但是列表没有这个要求;
- numpy数组处理起来的这个效率远远超过我们的这个list列表,这个也是numpy非常出名的一个重要的原因,因此建模里面,numpy经常使用,但是这个list却很少见到;
- 下面的这个就是创建一维数组和二维数组的方法;
- numpy是一个第三方模块,就是我们之前介绍的,模块分为内置的和第三方的,所以这个需要使用pip包管理器进行这个模块的安装,安装之后我们才可以使用;
- 首先我们需要导入这个模块,使用的就是import numpy as np,这个实际上就是对于我们的这个模块进行重新命名的操作,这样的话,我们后面就可以简写,不用谢numpy五个字符,而是简写成np两个字符(没想到吧,程序员就是这么的懒);
- 如何进行区分这个数组维度呢,我们就去看这个打印结果里面的这个数据左边的方括号的个数(不要看圆括号),圆括号表示的是这个数据类型是数组,但是判断这个维度需要使用方括号判断,也就是下面的这个样子;
- 即使是一维数组,我们使用这个np.array把我们的列表转换为数组的时候,打印结果也是会包含这个圆括号的,二维数组也是类似的道理;

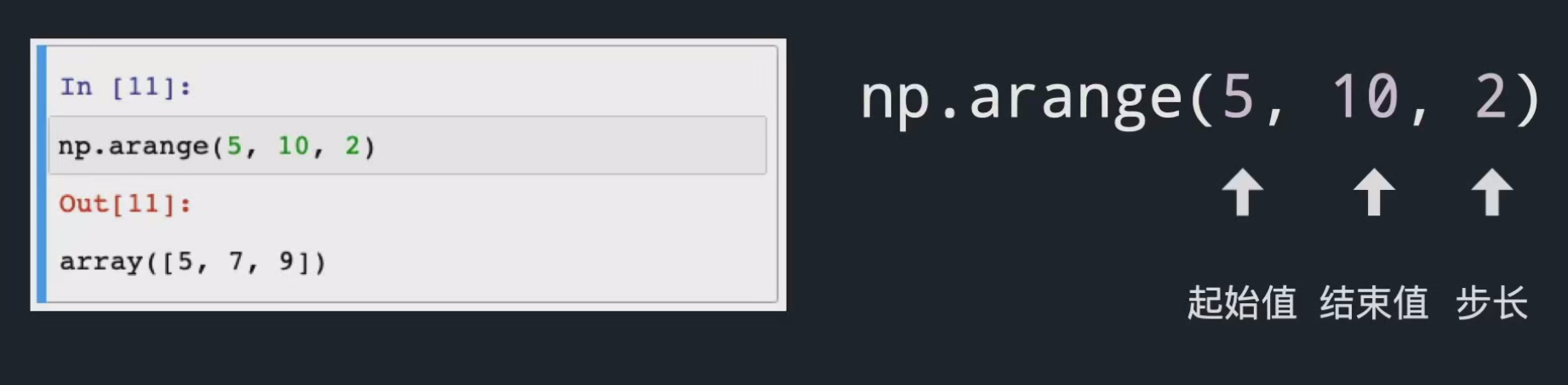
创建序列数组:下面的这个就是使用arange创建数组,这个里面包含了三个参数,分别是起始数字,终止数值和这个对应的步长(其实和matlab里面的这个方法是一致的);
下面的这个是使用concatenate方法进行这个数组直接的拼接组合,参数就是几个需要进行组合的数组

下面的这个也是很常见的一个写法:就是我们的条件筛选;
arr1就是一个数组,如果我们直接筛选,这个时候返回的就是true或者是flase,但是如果吧这个arr1<1作为条件索引进行筛选,这个时候打印的就是这个数组里面的符合条件的数据,这个在我们的数学建模里面还是很常见的我觉得;

如果是上面的这个题目里面的或条件,就是arr1[(arr1<1)|(arr1>3)],这个实际上就是一个逻辑表达式;
4.pandas入门
pandas也是一个第三方的模块,他和numpy很相似,但是他是继承自这个numpy,有自己独特的优势,那么我们下面开始看一下这个pandas的不同之处吧;
4.1Series的创建
导入模块:其实第一步还是安装这个第三方的模块,其次才是进行这个模块的导入,导入的方法和我们的numpy很相似,简写就是pd;
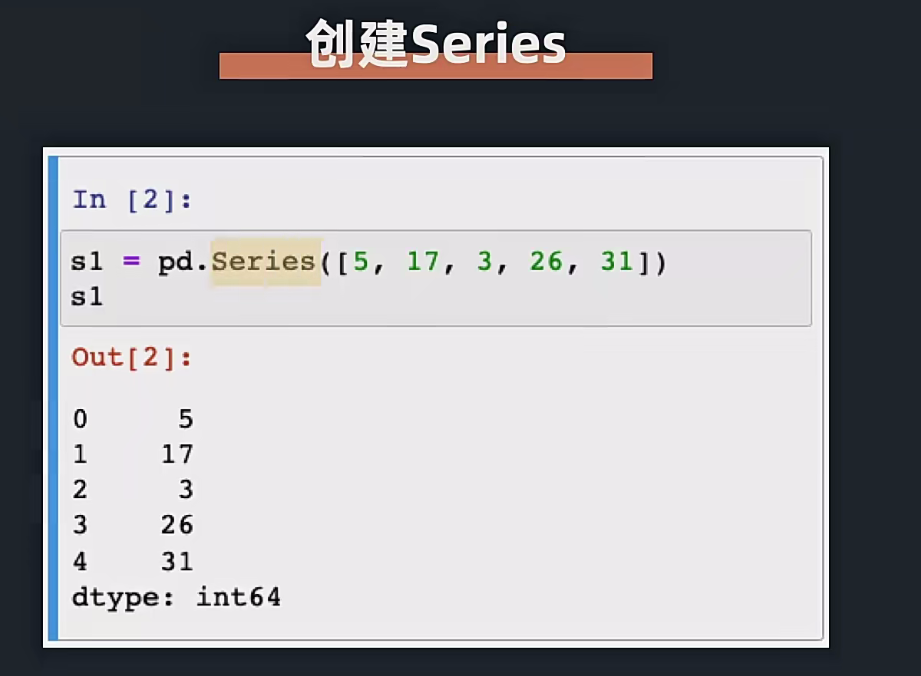
我们引入的这个对应的模块之后,就可以开始使用了:下面的这个就是创建Series的方法,这个Series可以理解为一个数据结构,也就是一类数据,其实就是数据类型,可以这么理解;
我们可以发现这个Series打印的结果,除了这个对应的数组里面的数据,还有这个对应的索引以及这个数据的类型;
4.2单独获取
上面我们直接创建这个Series发现这个打印结果是有两个部分组成的,一个就是values,一个就是对应的索引,因此这个我们可以使用下面的方式单独获取;
单独获取数据,就使用这个values属性;
单独获取索引,就使用这个index属性;

4.3Series里面的索引和切片
这个其实在我们的数组里面也是存在的,所以这个地方只是列取出来,证明我们的这个Series存在这个方法,大家获悉即可;
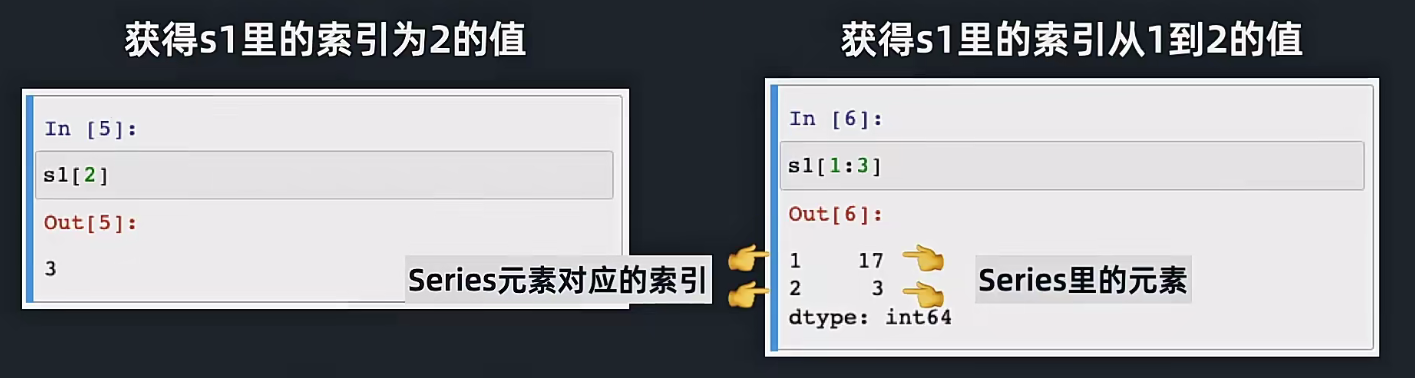
4.4两个索引方式
我们的这个下面的创建Series的时候,除了这个里面的参数,我们传递了这个index,就是这个默认的索引实际上就是0,1,2,3,4这样的,但是我们也是可以自己制定的,下面的这个1,3,5,7,9就是对应的五个元素的索引,这个是一个需要注意的地方;
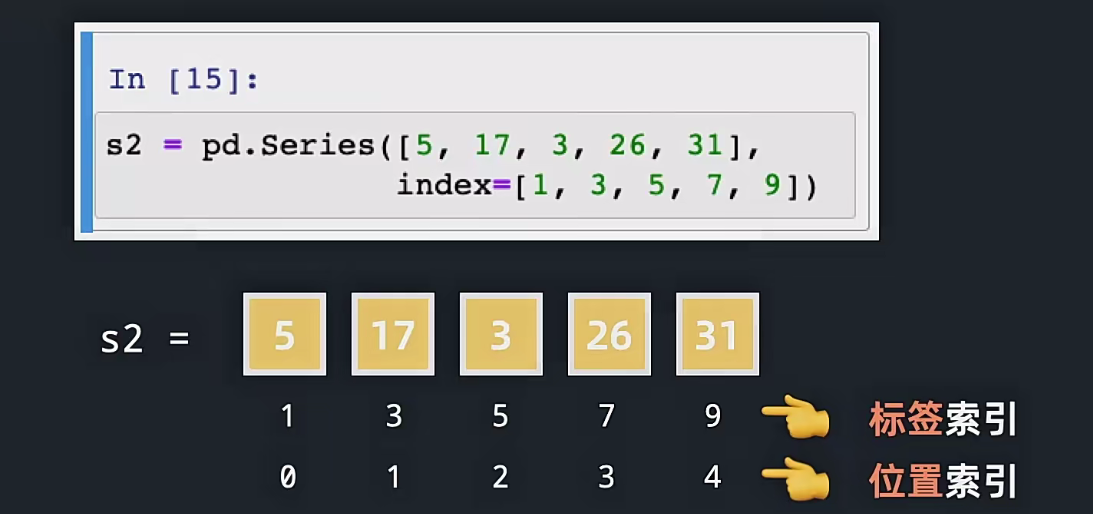
4.5loc和iloc索引
上面介绍了这个两个索引方式,我们可以自己制定,也可以按照这个默认的,但是这样很容易出现混淆,因此出现了这个loc和iloc的方法,这个loc实际上就是location,loc表示的就是按照标签进行索引,也就是我们自定义的标签,iloc就是位置索引,这个就是默认的0,1,2,3,4这样的索引;
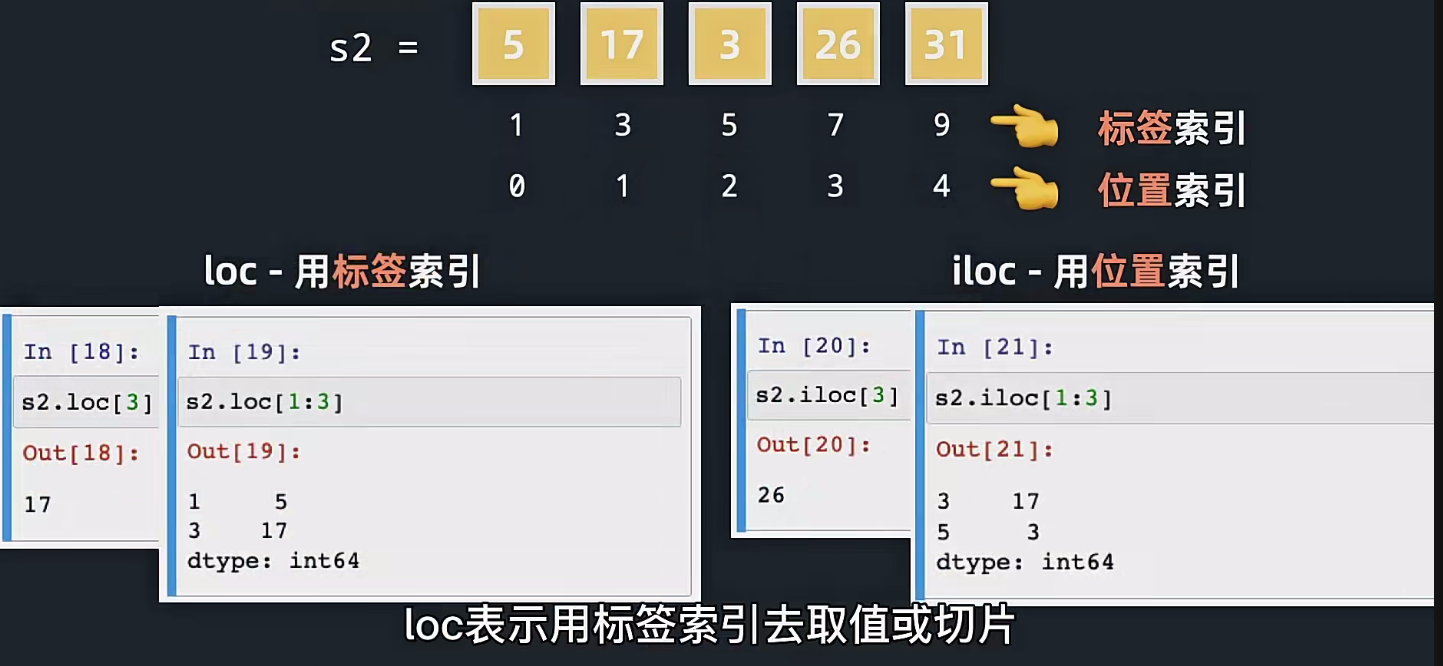
4.5关于开区间和闭区间的问题
就是下面的这个loc实际上就是标签索引,这个5到3实际上就是去打印这个数组里面的5标签这个索引对应的数值和3标签的这个索引对应的数值之间的所有元素;
但是这个loc使用标签索引是右边的闭区间,就是这个3标签对应的数值也会打印显示出来;
我们之前学习切片的时候,使用的就是左闭右开区间,右边的这个对应数值是不会打印出来的;



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









