 Go语言引入Swiss Table重塑map实现
Go语言引入Swiss Table重塑map实现





 请点击上方蓝字TonyBai订阅公众号!
请点击上方蓝字TonyBai订阅公众号!

在2024月11月5日的Go compiler and runtime meeting notes[1]中,我们注意到了一段重要内容,如下图红框所示:
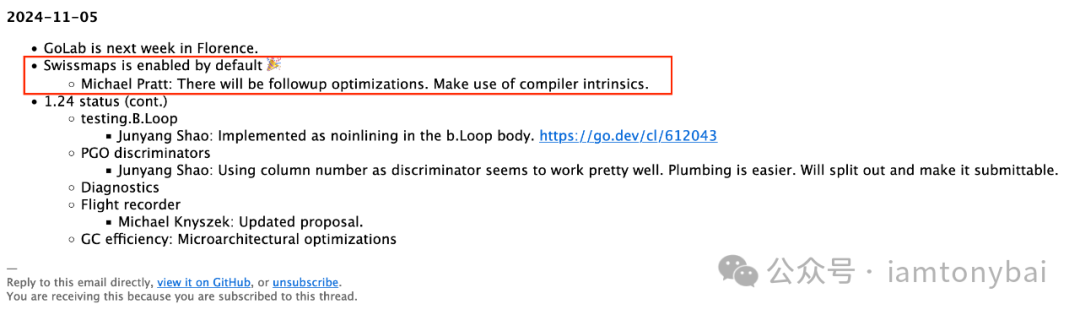
这表明,来自字节的一位工程师在两年多前提出的“使用Swiss table重新实现Go map[2]”的建议即将落地,目前该issue已经被纳入Go 1.24里程碑[3]。
Swiss Table是由Google工程师于2017年开发的一种高效哈希表实现,旨在优化内存使用和提升性能,解决Google内部代码库中广泛使用的std::unordered_map所面临的性能问题。Google工程师Matt Kulukundis在2017年CppCon大会上详细介绍了他们在Swiss Table上的工作[4]:

目前,Swiss Table已被应用于多种编程语言,包括C++ Abseil库的flat_hash_map(可替换std::unordered_map)[5]、Rust标准库Hashmap的默认实现[6]等。
Swiss Table的出色表现是字节工程师提出这一问题的直接原因。字节跳动作为国内使用Go语言较为广泛的大厂。据issue描述,Go map的CPU消耗约占服务总体开销的4%。其中,map的插入(mapassign)和访问(mapaccess)操作的CPU消耗几乎是1:1。大家可千万不能小看4%这个数字,以字节、Google这样大厂的体量,减少1%也意味着真金白银的大幅节省。
Swiss Table被视为解决这一问题的潜在方案。字节工程师初版实现的基准测试结果显示,与原实现相比,Swiss Table在查询、插入和删除操作上均提升了20%至50%的性能,尤其是在处理大hashmap时表现尤为突出;迭代性能提升了10%;内存使用减少了0%至25%,并且不再消耗额外内存。
这些显著的性能提升引起了Go编译器和运行时团队的关注,特别是当时负责该子团队的Austin Clements。在经过两年多的实验和评估后,Go团队成员Michael Pratt[7]基于Swiss Table实现的internal/runtime/maps最终成为Go map的底层默认实现。
在本文中,我们将简单介绍Swiss Table这一高效的哈希表实现算法,并提前看一下Go map的Swiss Table实现。
在进入swiss table工作原理介绍之前,我们先来回顾一下当前Go map的实现(Go 1.23.x)。
1. Go map的当前实现
map,也称为映射,或字典,或哈希表[8],是和数组等一样的最常见的数据结构。实现map有两个关键的考量,一个是哈希函数(hash function),另一个就是碰撞处理(collision handling)。hash函数是数学家的事情,这里不表。对于碰撞处理,在大学数据结构课程中,老师通常会介绍两种常见的处理方案:
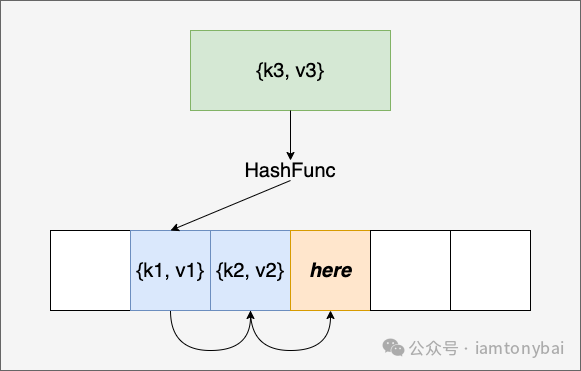
开放寻址法(Open Addressing)
在发生哈希碰撞时,尝试在哈希表中寻找下一个可用的位置,如下图所示k3与k1的哈希值发生碰撞后,算法会尝试从k1的位置开始向后找到一个空闲的位置:
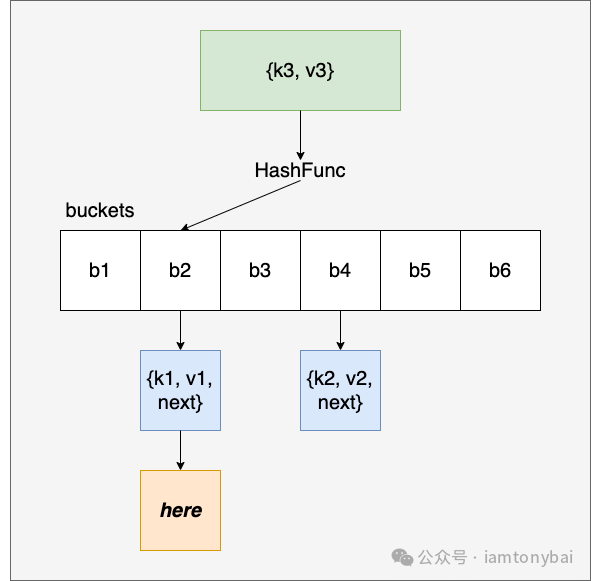
链式哈希法(拉链法, Chaining)
每个哈希桶(bucket)存储一个链表(或其他数据结构),所有哈希值相同的元素(比如k1和k3)都被存储在该链表中。
Go当前的map实现采用的就是链式哈希,当然是经过优化过的了。要了解Go map的实现,关键把握住下面几点:
编译器重写
我们在用户层代码中使用的map操作都会被Go编译器重写为对应的runtime的map操作,就如下面Go团队成员Keith Randall在GopherCon大会上讲解map实现原理[9]的一个截图所示:

链式哈希
前面提过,Go map当前采用的是链式哈希的实现,一个map在内存中的结构大致如下:
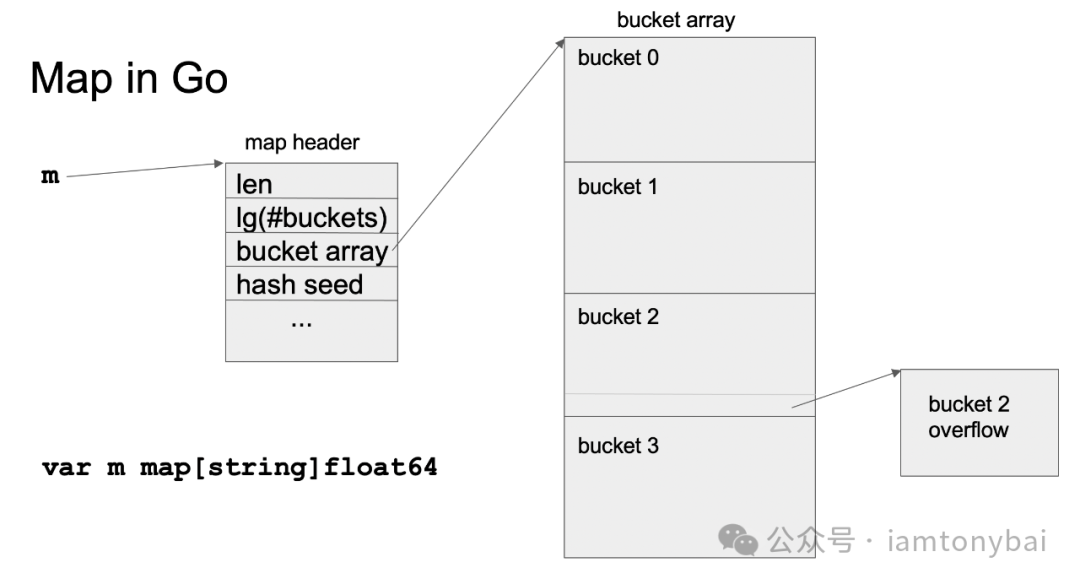
我们看到,一个map Header代表了一个map类型的实例,map header中存储了有关map的元数据(图中字段与当前实现可能有少许差异,毕竟那是几年前的一个片子了),如:
- len: 当前map中键值对的数量。
- bucket array: 存储数据的bucket数组,可以对比前面的链式哈希的原理图进行理解,不过不同的是,Go map中每个bucket本身就可以存储多个键值对,而不是指向一个键值对的链表。
- hash seed: 用于哈希计算的种子,用于分散数据并提高安全性。通常一个bucket可以存储8个键值对,这些键值对是根据键的哈希值分配到对应的bucket中。
注:在《Go语言第一课》[10]专栏中,有关于Go map工作原理的系统说明,感兴趣的童鞋可以看看。
溢出桶(overflow bucket)
每个bucket后面还会有Overflow Bucket。当一个bucket中的数据超出容量时,会创建overflow bucket来存储多余的数据。这样可以避免直接扩展bucket数组,节省内存空间。但如果出现过多的overflow bucket,性能就会下降。
“蚂蚁搬家”式的扩容
当map中出现过多overflow bucket而导致性能下降时,我们就要考虑map bucket扩容的事儿了,以始终保证map的操作性能在一个合理的范围。是否扩容由一个名为load factor的参数所控制。load factor是元素数量与bucket数量的比值,比值越高,map的读写性能越差。目前Go map采用了一个经验值来确定是否要扩容,即load factor = 6.5。当load factor超过这个值时,就会触发扩容。所谓扩容就是增大bucket数量(当前实现为增大一倍数量),减少碰撞,让每个bucket中存放的element数量降下来。
扩容需要对存量element做rehash,在元素数量较多的情况下,“一次性”的完成桶的扩容会造成map操作延迟“突增”,无法满足一些业务场景的要求,因此Go map采用“增量”扩容的方式,即在访问和插入数据时,“蚂蚁搬家”式的做点搬移元素的操作,直到所有元素完成搬移。
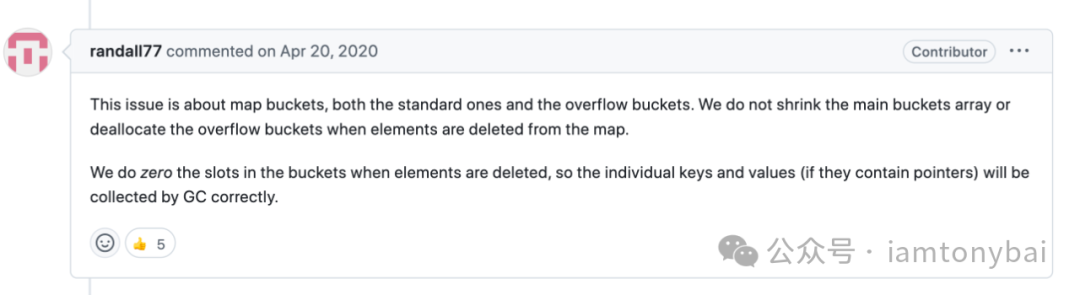
Go map的当前实现应该可以适合大多数的场合,但依然有一些性能和延迟敏感的业务场景觉得Go map不够快,另外一个常被诟病的就是当前实现的桶扩容后就不再缩容(shrink)了[11],这会给内存带来压力。
下
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 505
505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









