




前些日子,一些资深Gopher,比如fasthttp[1]的作者Aliaksandr Valialkin[2]因函数迭代器[3]加入Go 1.23版本[4]而抱怨Go的演进走错了方向:朝着增加复杂性和隐式代码执行的方向发展,而没有专注于Go语言的基本设计哲学——简单性、生产力和性能。Valialkin希望Go团队能专注于一些性能打磨和优化的环节,比如使用SIMD提升一些计算场景下Go代码的性能,避免Go的某些领地被以性能和安全性著称的Rust[5]抢去!
无独有偶,在Go项目issues中,我们也能看到很多有关希望Go支持SIMD指令的issue,比如近期的一个proposal[6],就期望Go团队可以在标准库中添加simd包以支持高性能的SIMD计算,就像Rust std::simd那样。当然,早期这类issue也有很多,比如:issue 53171[7]、issue 58610[8]等。
那么什么是SIMD指令?在Go官方尚未支持simd包或SIMD计算的情况下,如何在Go中使用SIMD指令进行计算加速呢?在这篇文章中,我们就来做个入门版介绍,并以一个最简单的矩阵加法的示例来展示一下SIMD指令的加速效果。
1. SIMD指令简介
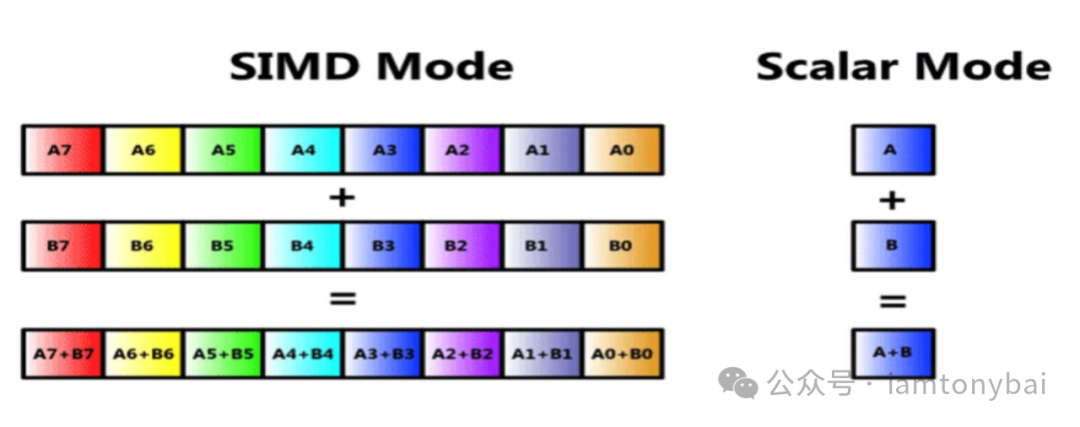
SIMD是“单指令多数据”(Single Instruction Multiple Data)的缩写。与之对应的则是SISD(Single Instruction, Single Data),即“单指令单数据”。
在大学学习汇编时,用于举例的汇编指令通常是SISD指令,比如常见的ADD、MOV、LEA、XCHG等。这些指令每执行一次,仅处理一个数据项。早期的x86架构下,SISD指令处理的数据仅限于8字节(64位)或更小的数据。随着处理器架构的发展,特别是x86-64架构的引入,SISD指令也能处理更大的数据项,使用更大的寄存器。但SISD指令每次仍然只处理一个数据项,即使这个数据项可能比较大。
相反,SIMD指令是一种特殊的指令集,它可以让处理器可以同时处理多个数据项,提高计算效率。我们可以用下面这个更为形象生动的比喻来体会SIMD和SISD的差别。
想象你是一个厨师,需要切100个苹果。普通的方式是一次切一个苹果,这就像普通的SISD处理器指令。而SIMD指令就像是你突然多了几双手,可以同时切4个或8个苹果。显然,多手同时工作会大大提高切苹果的速度。
具体来说,SIMD指令的优势在于以下几点:
并行处理:一条指令可以同时对多个数据进行相同的操作。
数据打包:将多个较小的数据(如32位浮点数)打包到一个较大的寄存器(如256位)中。
提高数据吞吐量:每个时钟周期可以处理更多的数据。
这种并行处理方式特别适合于需要大量重复计算的任务,如图像处理、音频处理、科学计算等。通过使用SIMD指令,可以显著提高这些应用的性能。
主流的x86-64(amd64)和arm系列CPU都有对SIMD指令的支持。以x86-64为例,该CPU体系下支持的SIMD指令就包括MMX(MultiMedia eXtensions)、SSE (Streaming SIMD Extensions)、SSE2、SSE3、SSSE3、SSE4、AVX(Advanced Vector Extensions)、AVX2以及AVX-512等。ARM架构下也有对应的SIMD指令集,包括VFP (Vector Floating Point)、NEON (Advanced SIMD)、SVE (Scalable Vector Extension)、SVE2以及Helium (M-Profile Vector Extension, MVE)等。
注:在Linux上,你可以通过lscpu或cat /proc/cpuinfo来查看当前主机cpu支持的SIMD指令集的种类。注:Go在Go 1.11版本才开始支持AVX-512指令[9]。
每类SIMD指令集都有其特定的优势和应用场景,以x86-64下的SIMD指令集为例:
MMX主要用于早期的多媒体处理;
SSE系列逐步改进了浮点运算和整数运算能力,广泛应用于图形处理和音视频编码;
AVX系列大幅提高了并行处理能力,特别适合科学计算和高性能计算场景。
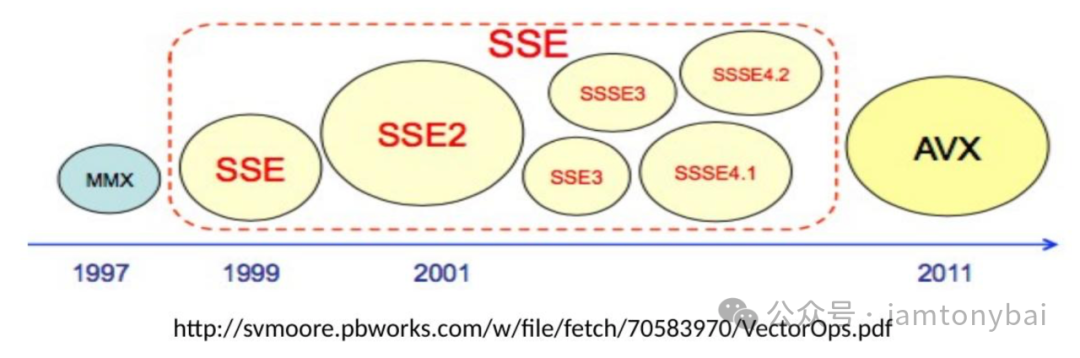
这些指令集的演进反映了处理器技术的发展和应用需求的变化。从支持64位计算的MMX到支持512位计算的AVX-512,SIMD指令的并行处理能力不断提升,更多更大的寄存器加入进来,为各种复杂的计算任务提供了强大的硬件支持。
注:SSE和AVX各自有16个寄存器,SSE的16个寄存器为XMM0-XMM15,XMM是128位寄存器,而YMM是256位寄存器。支持AVX的x86-64处理器包含16个256位大小的寄存器,从YMM0到YMM15。每个YMM寄存器的低128位是相对应的XMM寄存器。大多数AVX指令可以使用任何一个XMM或者YMM寄存器作为SIMD操作数。AVX512将每个AVXSIMD寄存器的大小从256位扩展到512位,称为ZMM寄存器;符合AVX512标准的处理器包含32个ZMM寄存器,从ZMM0~ZMM31。YMM和XMM寄存器分别对应于每个ZMM寄存器的低256位和低128位。
既然SIMD指令这么好,那么在Go中应该如何使用SIMD指令呢?接下来我们就来看看。
2. 在Go中如何使用SIMD指令
Go主要面向的是云计算领域、微服务领域,这些领域中对计算性能的要求相对没那么极致。以至于在一些对性能要求较高的场景,比如高性能计算、 图形学、数字信号处理等领域,很多gopher会遇到对Go计算性能进行优化的需求。
纯计算领域,怎么优化呢?此时此刻,Go官方并没有提供对SIMD提供支持的simd包。
一种想法是使用cgo机制在Go中调用更快的C或C++,但cgo的负担又不能不考虑,cgo不是go[10],很多人不愿意引入cgo。
另外一种想法就是再向下一层,直接上汇编,在汇编中直接利用SIMD指令实现并行计算。但手写汇编难度是很高的,手写Plan9风格、资料甚少的Go汇编难度则更高。那么有什么方法避免直接手搓汇编呢?目前看大致有这么几种(如果有更好的方法,欢迎在评论区提出你的建议):
使用c2goasm[11](https://github.com/minio/c2goasm/)转换
我们可以先用c/c++实现对应的函数功能(可以利用类似intel提供的面向simd的intrisic functions[12]),然后生成汇编代码(基于clang),再用c2goasm转换为go语言汇编。不过目前c2goasm已经public archive了,并且该方法应用受很多因素限制,比如clang版本和特定的编译选项啥的。亲测这种方法上手难度较高。
使用uber工程师Michael McLoughlin开源的avo[13]来生成go汇编
avo(https://github.com/mmcloughlin/avo)是一个go包,它支持以一种相对高级一些的Go语法来编写汇编,至少你可以不必直面那些晦涩难懂的汇编代码。但使用avo编写汇编也不是很容易的事情,你仍然需要大致知道汇编的运作原理和基本的编写规则。此外avo与汇编的能力并非完全等价,其作者声明:avo也还处于实验阶段。
使用goplus/llgo集成c/c++生态
在go中调用c的cgo机制不受待见,llgo[14]反其道而行之,将go、python、c/c++等代码统统转换为llvm中间代码进而通过clang编译和优化为可执行文件。这样就可以直接利用python、c/c++的生态,进而利用高性能的c/c++实现(比如支持SIMD指令)。目前llgo还不成熟,七牛云老板许式伟正在全力开发llgo,等llgo成熟后,这后续
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 565
565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









