




在《Go 1.23新特性前瞻》[1]一文中,我们提到了Go 1.23中增加的一个主要的语法特性就是支持了用户自定义iterator,即range over func试验特性[2]的正式转正。为此,Go 1.23还在标准库中增加了iter包[3],这个包对什么是Go自定义iterator做了诠释:
An iterator is a function that passes successive elements of a sequence to a callback function, conventionally named yield. The function stops either when the sequence is finished or when yield returns false, indicating to stop the iteration early.
迭代器是一个函数,它将一个序列中的连续元素传递给一个回调函数,通常称为"yield"。迭代器函数会在序列结束或者yield回调函数返回false(表示提前停止迭代)时停止。除此之外,iter包还定义了标准的iterator泛型类型、给出了有关iterator的命名惯例以及在迭代中修改序列中元素的方法等,这些我们稍后会细说。
不过就在Go 1.23还有两个月就要发布之际,Go社区却出现了对Go iterator的质疑之声。
先是知名开源项目fasthttp[4]作者、时序数据库[5]VictoriaMetrics贡献者Aliaksandr Valialkin[6]撰文谈及Go iterator引入给Go带来复杂性的同时,还破坏了Go的显式哲学,并且并未真的带来额外的好处,甚至觉得Go正朝着错误的方向演进[7],希望Go团队能revert Go 1.23中与iterator有关的代码。
注:第319期GoTime播客[8]也在聊“Is Go evolving in the wrong direction?”这个话题,感兴趣的Gopher可以听一下。
之后,Odin语言的设计者站在局外人的角度,从语言设计层面谈到了为什么人们憎恨Go 1.23的iterator[9],该文章更是在Hacker News上引发热议[10]。
那么到底Go 1.23中的自定义iterator和iter包带给Go社区的是强大的功能特性和表达力的提升,还是花哨不实用的复杂性呢?这里我也不好轻易下结论,我打算通过这篇文章,和大家一起全面地认识一下Go iterator。最终对iterator的是非曲直的判断还是由各位读者自行得出。
1. 开端
能找到的与最终Go iterator相关的最早的issue来自Go团队成员Michael Knyszek[11]在2021年发起的issue:Proposal: Function values as iterators[12]。
之后,2022年8月,Ian Lance Taylor发起了名为["standard iterator interface"的discussion](https://github.com/golang/go/discussions/54245 ""standard iterator interface"的discussion")作为Michael Knyszek发起的issue的后续。
最后,Go团队技术负责人Russ Cox在2022年10月份发起了针对iterator的最后一次讨论[13],在这次讨论中,Go团队初步完成了iterator的设计思路。此外,在该讨论的开场白处,Russ Cox还概述了Go为什么要增加对用户自定义iterator的支持:

总结下来就是Russ发现Go标准库中有很多库(如上截图)中都有迭代器的实现,但形式不统一,没有标准的“实现路径”,各自为战。这与Go面向工程的目标有悖,现状阻碍了大型Go代码库中的代码迁移。因此,Go团队希望给大家带来一致的迭代器形式,具体来说就是允许for range支持对一定类型函数值(function value)进行迭代,即range over func。
2024年2月,iterator以试验特性被Go 1.22版本引入[14],通过GOEXPERIMENT=rangefunc可以开启range-over-func特性以及使用iter包。
在golang.org/x/exp下面,Go团队还提议维护一个xiter包[15],这个包内提供了用于组合iterator的基本适配器(adapter),不过目前该xiter包依旧处于proposal状态,尚未落地。
2024年8月,iterator将伴随Go 1.23版本正式落地,现在我们可以通过Go playground[16]在线体验iterator,当然你也可以安装Go tip版本或Go 1.23的rc版[17]在本地体验。
注:关于Go tip的安装方法以及Go playground在线体验的详细说明,这里就不赘述了,《Go语言第一课》[18]专栏的“03|配好环境:选择一种最适合你的Go安装方法[19]”有系统全面的讲解,欢迎订阅阅读。
2. 形式
在Go tip版的Go spec[20]中,我们可以看到下面for range的语法形式,其中下面红框中的三行是for range接自定义iterator的形式:
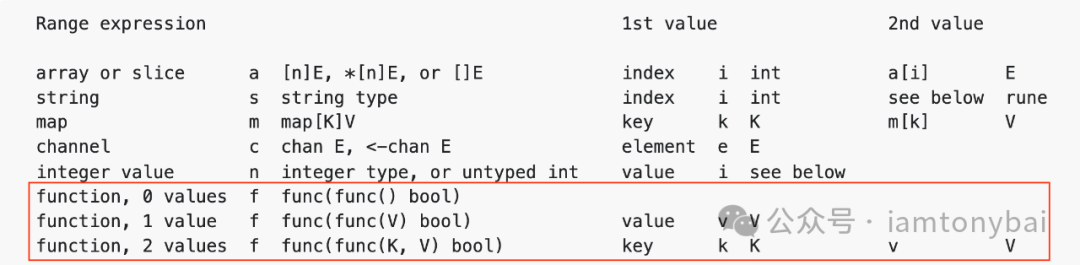
如果f是一个自定义迭代器,那么上图中红框中的三种情况分别对应的是下面的三类for range语句形式:
第一类:function, 0 values, f的签名为func(func() bool)
for range f { ... }
第二类:function, 1 value,f的签名为func(func(V) bool)
for x := range f { ... }
第三类:function, 2 values,f的签名为func(func(K, V) bool)
for x, y := range f { ... }
for x, _ := range f { ... }
for _, y := range f { ... }我们可以看一个实际的应用上述三类迭代器的示例:
// go-iterator/iterator_spec.go
// https://go.dev/play/p/ffxygzIdmCB?v=gotip
package main
import (
"fmt"
"slices"
)
type Seq0 func(yield func() bool)
func iter0[Slice ~[]E, E any](s Slice "Slice ~[]E, E any") Seq0 {
return func(yield func() bool) {
for range s {
if !yield() {
return
}
}
}
}
var sl = []int{1, 2, 3, 4, 5, 6, 7, 8, 9}
func main() {
// 1. for range f {...}
count := 0
for range iter0(sl) {
count++
}
fmt.Printf("total count = %d ", count)
fmt.Printf("\n\n")
// 2. for x := range f {...}
fmt.Println("all values:")
for v := range slices.Values(sl) {
fmt.Printf("%d ", v)
}
fmt.Printf("\n\n")
// 3. for x, y := range f{...}
fmt.Println("backward values:")
for _, v := range slices.Backward(sl) {
fmt.Printf("%d ", v)
}
}在这个示例中,我在slices包中找到了Values和Backward两个函数,它们分别返回的是第二类和第三类的迭代器。针对第一类迭代器,在Russ Cox最初的设计中是有对应的,即一个名为Seq0的类型,但后续在iter包中,该类型并未落地。于是我们在上面示例中自己定义了这个类型,并定义了一个iter0的函数用于返回Seq0类型的迭代器。不过实际想来,使用到Seq0这个形式的迭代器的场景似乎极少。
运行上述示例,我们将得到如下结果:
total count = 9
all values:
1 2 3 4 5 6 7 8 9
backward values:
9 8 7 6 5 4 3 2 1我们看到,在使用层面,通过for range+函数iterator来迭代像切片这样的集合类型中的元素还是蛮简单的,并且该方案并未引入新关键字或预定义标识符(像any[21]、new这种)。
不过,在这样简洁的使用界面之下,for range对Go迭代器的支持究竟是如何实现的呢?接下来,我们就来简单看看其实现原理。
3. 原理
在《Go语言精进之路vol1》[22]一书中,我曾引述了Go语言之父Rob Pike的一句话:“Go语言实际上是复杂的,但只是让大家感觉很简单”。Go iterator也是这样,“简单”外表的背后是Go语言自身实现层面的复杂,而这些复杂性被Go语言的设计者“隐藏”起来了。或者说,Go团队把复杂性留给了语言自身的设计和实现,留给了Go团队自身。
3.1 自定义迭代器、yield函数与迭代器创建API
下面我们先以slices的Backward函数为例,用下图说明一下自定义迭代器从实现到使用过程中涉及的各个方面:
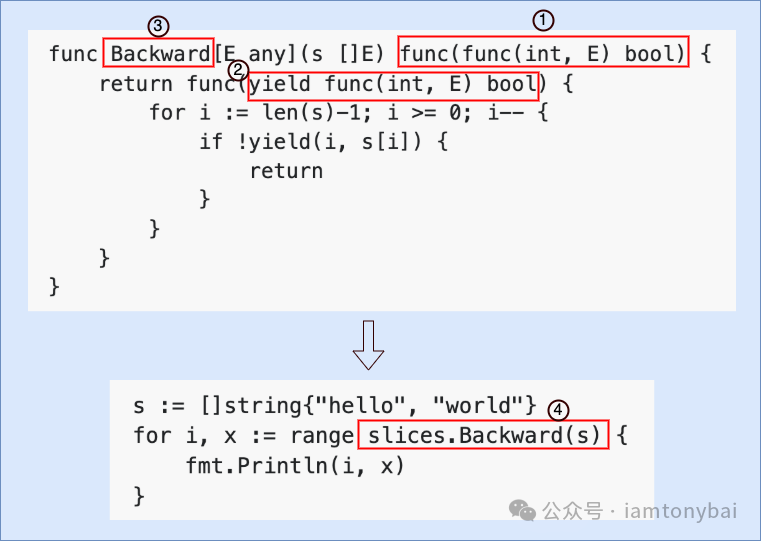
我们先来看上图中最下面for range与函数结合一起使用的代码,这里的红框④中的函数slices.Backward并非是iterator,而是slices包中的一个创建iterator的API函数。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 245
245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









