




动态表是 Flink Table & SQL API的核心概念,用于统一有界和无界数据的处理。
动态表只是一个逻辑概念,因此 Flink 并不拥有数据。相应的,动态表的内容存储在外部系统( 如数据库、键值存储、消息队列 )或文件中。
动态 sources 和动态 sinks 可用于从外部系统读取数据和向外部系统写入数据。在文档中,sources 和 sinks 常在术语连接器 下进行总结。
Flink 为 Kafka、Hive 和不同的文件系统提供了预定义的连接器。有关内置 table sources 和 sinks 的更多信息,请参阅连接器部分
本页重点介绍如何开发自定义的用户定义连接器。
从 Flink v1.16 开始, TableEnvironment 引入了一个用户类加载器,以在 table 程序、SQL Client、SQL Gateway 中保持一致的类加载行为。该类加载器会统一管理所有的用户 jar 包,包括通过ADD JAR或CREATE FUNCTION .. USING JAR ..添加的 jar 资源。 在用户自定义连接器中,应该将Thread.currentThread().getContextClassLoader()替换成该用户类加载器去加载类。否则,可能会发生ClassNotFoundException的异常。该用户类加载器可以通过DynamicTableFactory.Context获得。
概述
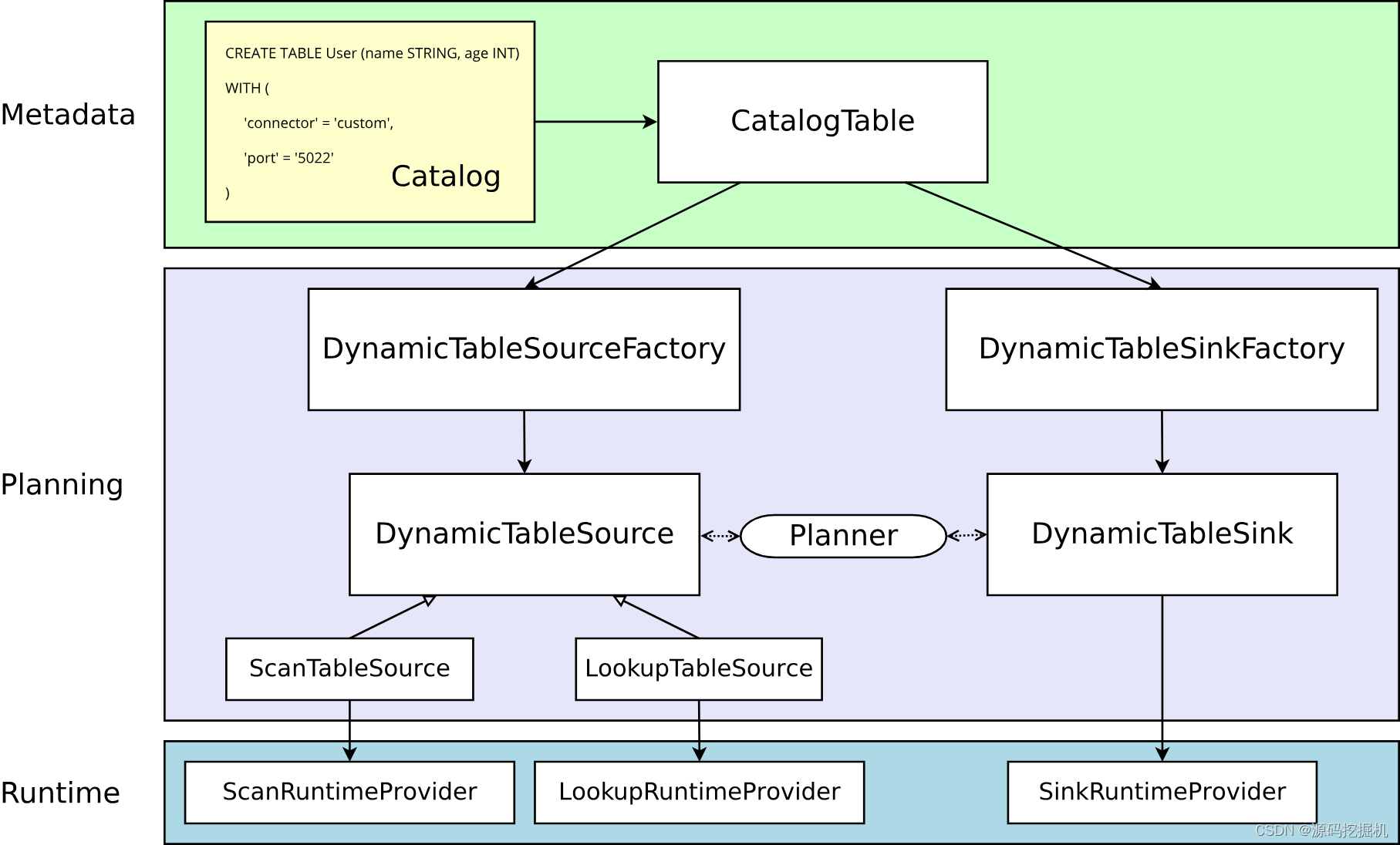
在许多情况下,开发人员不需要从头开始创建新的连接器,而是希望稍微修改现有的连接器或 hook 到现有的 stack。在其他情况下,开发人员希望创建专门的连接器。
本节对这两种用例都有帮助。它解释了表连接器的一般体系结构,从 API 中的纯粹声明到在集群上执行的运行时代码
实心箭头展示了在转换过程中对象如何从一个阶段到下一个阶段转换为其他对象。
元数据
Table API 和 SQL 都是声明式 API。这包括表的声明。因此,执行 CREATE TABLE 语句会导致目标 catalog 中的元数据更新。
对于大多数 catalog 实现,外部系统中的物理数据不会针对此类操作进行修改。特定于连接器的依赖项不必存在于类路径中。在 WITH 子句中声明的选项既不被验证也不被解释。
动态表的元数据( 通过 DDL 创建或由 catalog 提供 )表示为 CatalogTable 的实例。必要时,表名将在内部解析为 CatalogTable。
解析器
在解析和优化以 table 编写的程序时,需要将 CatalogTable 解析为 DynamicTableSource( 用于在 SELECT 查询中读取 )和 DynamicTableSink( 用于在 INSERT INTO 语句中写入 )。
DynamicTableSourceFactory 和 DynamicTableSinkFactory 提供连接器特定的逻辑,用于将 CatalogTable 的元数据转换为 DynamicTableSource 和 DynamicTableSink 的实例。在大多数情况下,以工厂模式设计的目的是验证选项(例如示例中的 'port' = '5022' ),配置编码解码格式( 如果需要 ),并创建表连接器的参数化实例。
默认情况下,DynamicTableSourceFactory 和 DynamicTableSinkFactory 的实例是使用 Java的 [Service Provider Interfaces (SPI)] (https://docs.oracle.com/javase/tutorial/sound/SPI-intro.html) 发现的。 connector 选项(例如示例中的 'connector' = 'custom')必须对应于有效的工厂标识符。
尽管在类命名中可能不明显,但 DynamicTableSource 和 DynamicTableSink 也可以被视为有状态的工厂,它们最终会产生具体的运行时实现来读写实际数据。
规划器使用 source 和 sink 实例来执行连接器特定的双向通信,直到找到最佳逻辑规划。取决于声明可选的接口( 例如 SupportsProjectionPushDown 或 SupportsOverwrite),规划器可能会将更改应用于实例并且改变产生的运行时实现。
运行时的实现
一旦逻辑规划完成,规划器将从表连接器获取 runtime implementation。运行时逻辑在 Flink 的核心连接器接口中实现,例如 InputFormat 或 SourceFunction。
这些接口按另一个抽象级别被分组为 ScanRuntimeProvider、LookupRuntimeProvider 和 SinkRuntimeProvider 的子类。
例如,OutputFormatProvider( 提供 org.apache.flink.api.common.io.OutputFormat )和 SinkFunctionProvider( 提供org.apache.flink.streaming.api.functions.sink.SinkFunction)都是规划器可以处理的 SinkRuntimeProvider 具体实例。
项目配置
如果要实现自定义连接器或自定义格式,通常以下依赖项就足够了:
MavenOpen the pom.xml file in your project directory and add the following in the dependencies block.
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>1.18.1</version>
<scope>provided</scope>
</dependency>Check out Project configuration for more details.Gradle
如果你想开发一个需要与 DataStream API 桥接的连接器( 即:如果你想将 DataStream 连接器适配到 Table API),你需要添加此依赖项:
MavenOpen the pom.xml file in your project directory and add the following in the dependencies block.
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>1.18.1</version>
<scope>provided</scope>
</dependency>Check out Project configuration for more details.Gradle
在开发 connector/format 时,我们建议同时提供 Thin JAR 和 uber JAR,以便用户可以轻松地在 SQL 客户端或 Flink 发行版中加载 uber JAR 并开始使用它。 uber JAR 应该包含连接器的所有第三方依赖,不包括上面列出的表依赖。
你不应该在生产代码中依赖flink-table-planner_2.12。 使用 Flink 1.15 中引入的新模块flink-table-planner-loader,应用程序的类路径将不再直接访问org.apache.flink.table.planner类。 如果你需要org.apache.flink.table.planner的包和子包内部可用的功能,请开启一个 issue。要了解更多信息,请查看 Table 依赖解读。
扩展点
这一部分主要介绍扩展 Flink table connector 时可能用到的接口。
动态表的工厂类
在根据 catalog 与 Flink 运行时上下文信息,为某个外部存储系统配置动态表连接器时,需要用到动态表的工厂类。
比如,通过实现 org.apache.flink.table.factories.DynamicTableSourceFactory 接口完成一个工厂类,来生产 DynamicTableSource 类。
通过实现 org.apache.flink.table.factories.DynamicTableSinkFactory 接口完成一个工厂类,来生产 DynamicTableSink 类。
默认情况下,Java 的 SPI 机制会自动识别这些工厂类,同时将 connector 配置项作为工厂类的”标识符“。
在 JAR 文件中,需要将实现的工厂类路径放入到下面这个配置文件:
META-INF/services/org.apache.flink.table.factories.Factory
Flink 会对工厂类逐个进行检查,确保其“标识符”是全局唯一的,并且按照要求实现了上面提到的接口 (比如 DynamicTableSourceFactory)。
如果必要的话,也可以在实现 catalog 时绕过上述 SPI 机制识别工厂类的过程。即在实现 catalog 接口时,在org.apache.flink.table.catalog.Catalog#getFactory 方法中直接返回工厂类的实例。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1141
1141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









