




最近用了Dinky之后,感觉Dinky功能真的很强大,特别是近几年平台开发越来越火,作为一位没有做过平台开发的攻城狮,总感觉差点意思,但是看了Dinky之后,这个平台比朋友公司的实时平台差不了多少,甚至还更优,所以打算花点时间好好看看这个平台的功能和代码逻辑。
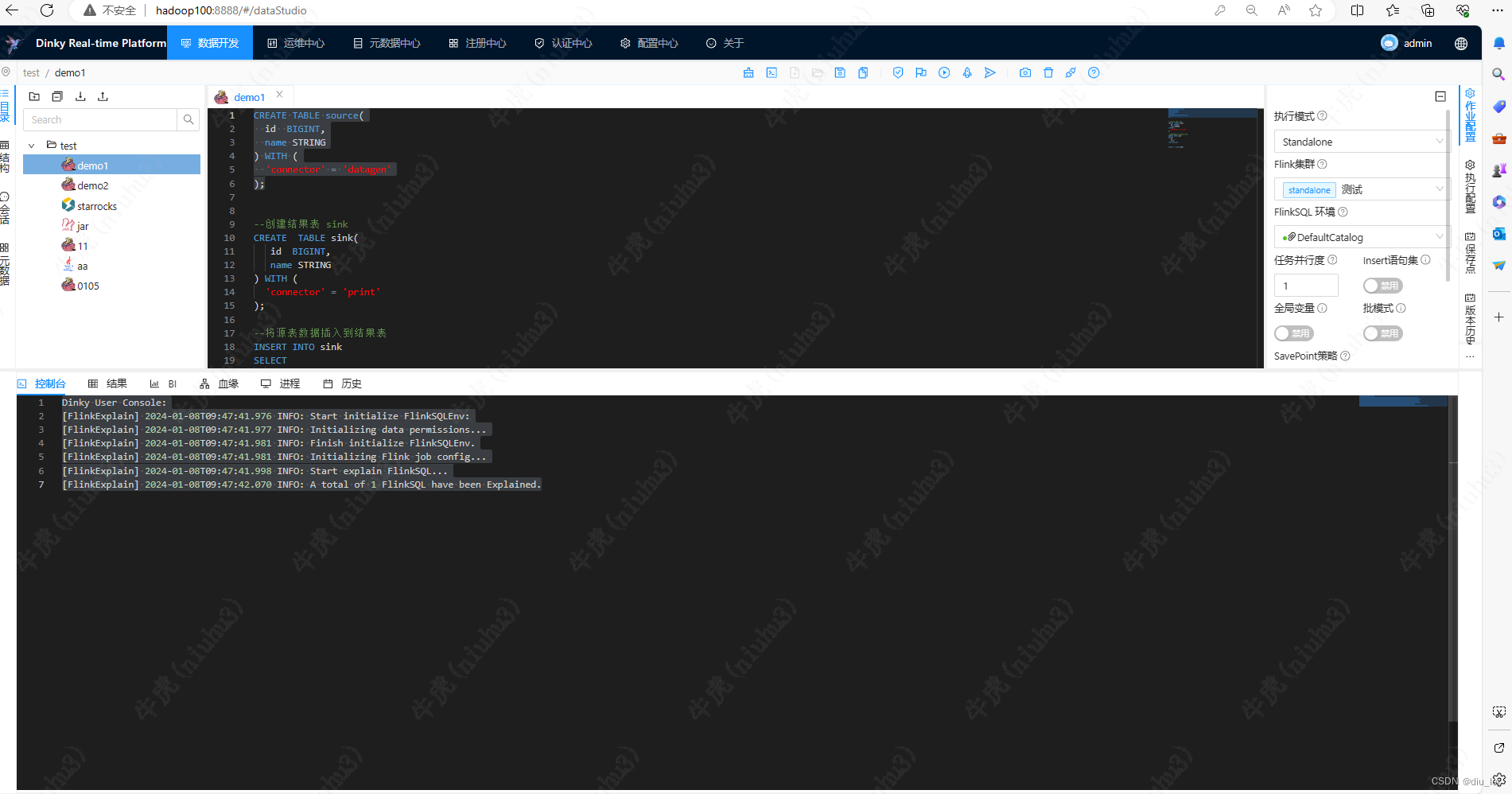
我们先看看Dinky的页面:
数据开发:主要是创建作业的交互页面,还可以看到作业之中的血缘
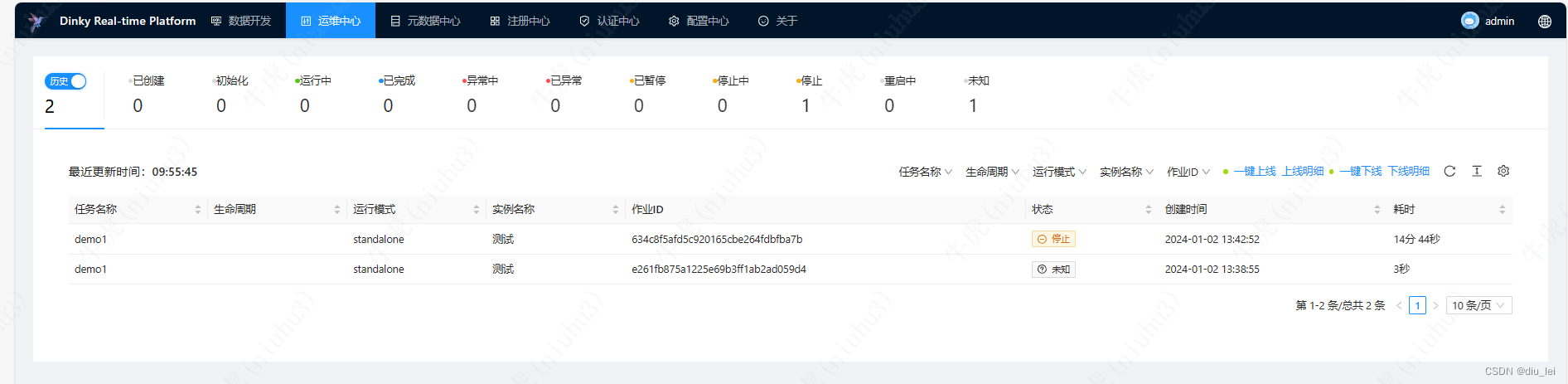
运维中心 :主要管理作业的上下线,查看作业明细
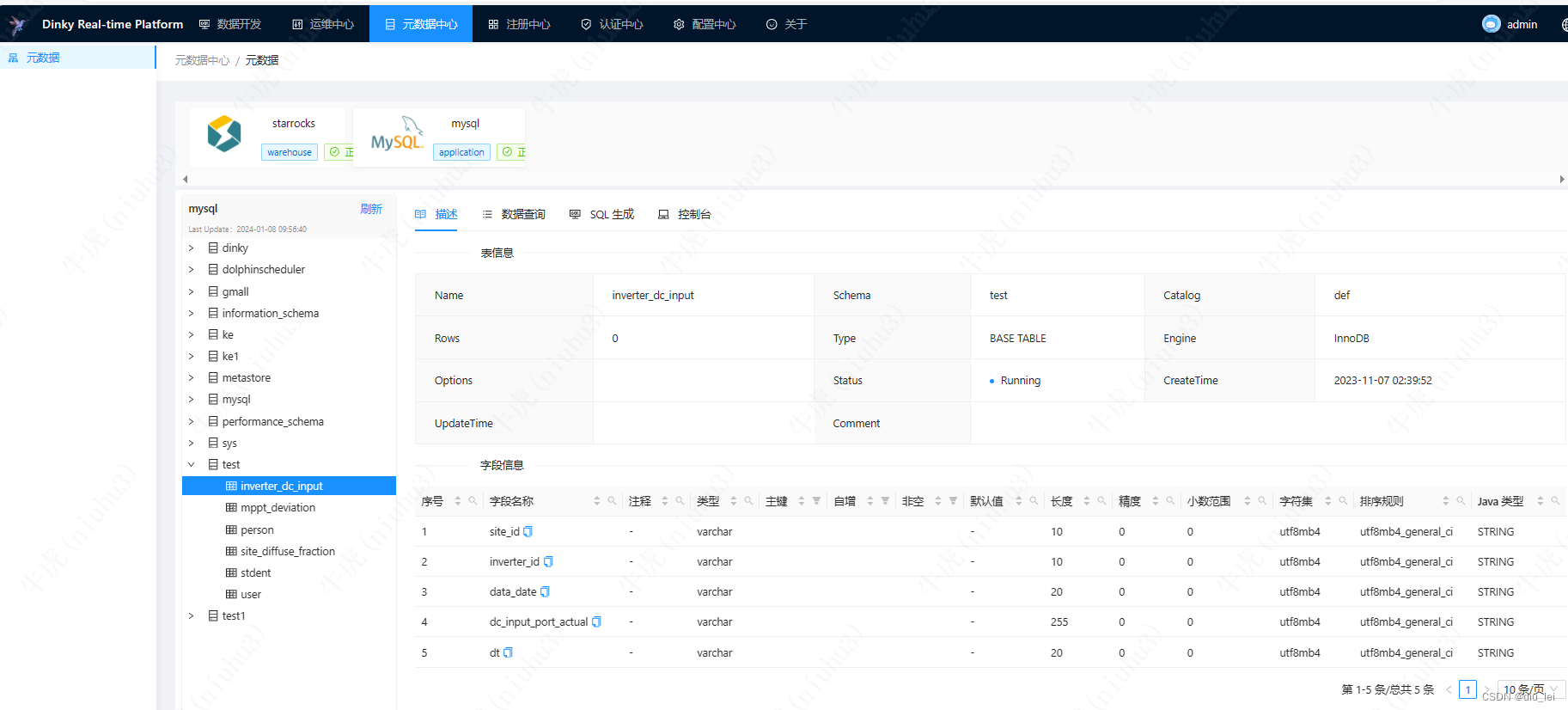
元数据中心:主要管理各种数据库的各种表和元数据
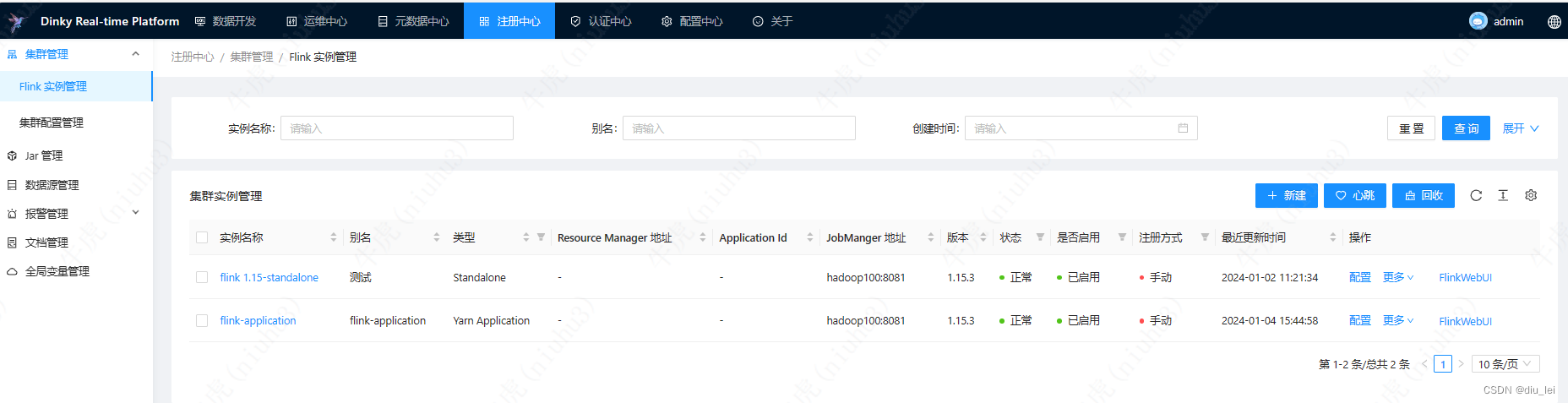
注册中心:主要做Flink集群的管理,jar包管理,数据源管理,报警管理等
认证中心:主要做角色管理和权限管理
上面就是Dinky比较重要的功能模块和其主要作用
1.Dinky作业类型
下面为Dinky的作业类型
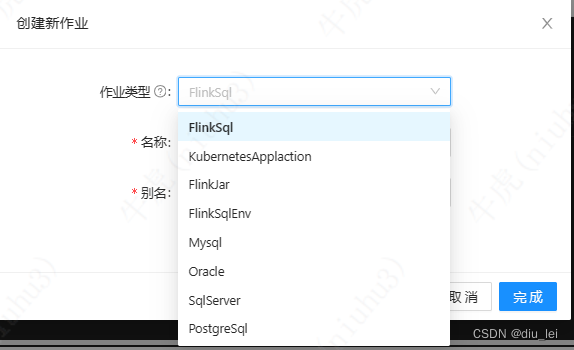
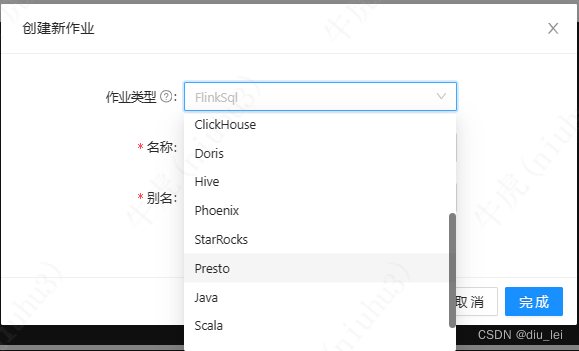
其中有很多我们常见的数据库,里面有一个FlinkSqlEnv,他主要是用来做表和库的初始化,如果你有一些库和表经常要用,可以把他放在FlinkSqlEnv,写flink sql作业时选择对应的环境即可完成对应表的初始化
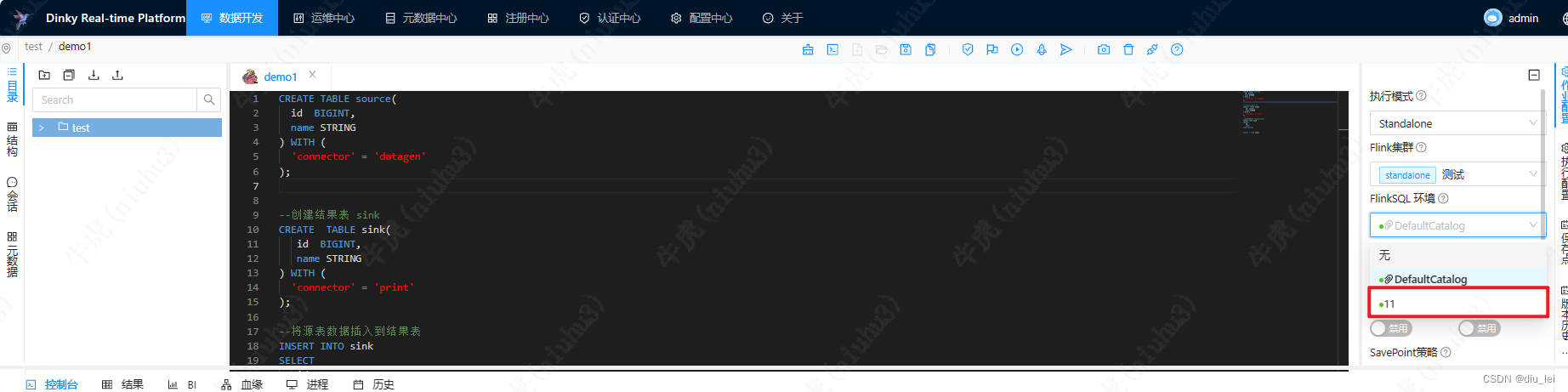
我这里创建了一个11的FlinkSqlEnv ,里面就放了一个源表的初始化SQL

然后dinky作业还支持,scala,java,python作业,这三个主要是给我们用来写UDF和UDTF时使用的
2.Dinky源码作业类型划分和提交作业源码深入讲解
上一节我们大致看了一下提交作业的源码,这一节我们详细看下,我们从TaskServiceImpl#submitTask方法开始看起
@Override
public JobResult submitTask(Integer id) {
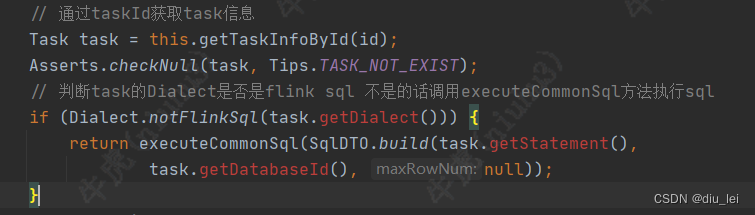
// 通过taskId获取task信息
Task task = this.getTaskInfoById(id);
Asserts.checkNull(task, Tips.TASK_NOT_EXIST);
// 判断task的Dialect是否是flink sql 不是的话调用executeCommonSql方法执行sql
if (Dialect.notFlinkSql(task.getDialect())) {
return executeCommonSql(SqlDTO.build(task.getStatement(),
task.getDatabaseId(), null));
}
ProcessEntity process = null;
// 获取进程实例 ProcessEntity
if (StpUtil.isLogin()) {
process = ProcessContextHolder.registerProcess(
ProcessEntity.init(ProcessType.FLINKSUBMIT, StpUtil.getLoginIdAsInt()));
} else {
process = ProcessEntity.NULL_PROCESS;
}
process.info("Initializing Flink job config...");
JobConfig config = buildJobConfig(task);
// 如果GatewayType是k8s appplication,加载容器
if (GatewayType.KUBERNETES_APPLICATION.equalsValue(config.getType())) {
loadDocker(id, config.getClusterConfigurationId(), config.getGatewayConfig());
}
// 创建jobmanager
JobManager jobManager = JobManager.build(config);
process.start();
// 判断配置的是否是jarTask,是的话调用jobManager.executeJar(),不是的话调用jobManager.executeSql
if (!config.isJarTask()) {
JobResult jobResult = jobManager.executeSql(task.getStatement());
process.finish("Submit Flink SQL finished.");
return jobResult;
} else {
JobResult jobResult = jobManager.executeJar();
process.finish("Submit Flink Jar finished.");
return jobResult;
}
}我们来看第一小节代码:根据taskId获取task信息,然后根据task的dialect判断是否是flink sql,不是的话执行executeCommonSql方法,所以dinky sql作业只会分类两类flink sql和common sql,hive,starrocks,clickhouse都属于common sql 了
然后我们看看他是怎么通过taskId获取到task信息的
@Override
public Task getTaskInfoById(Integer id) {
//获取task
Task task = this.getById(id);
if (task != null) {
task.parseConfig();
//获取statement,statement中存储的我们写的sql
Statement statement = statementService.getById(id);
if (task.getClusterId() != null) {
Cluster cluster = clusterService.getById(task.getClusterId());
if (cluster != null) {
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









