




 本文介绍了如何从初识WordCount开始学习Flink,包括代码结构、源码分析,重点讲解了source算子、转换算子(如map和sum)和sink算子(如Print)的底层实现。
本文介绍了如何从初识WordCount开始学习Flink,包括代码结构、源码分析,重点讲解了source算子、转换算子(如map和sum)和sink算子(如Print)的底层实现。
1.初识WordCount
近几年实时数据处理和流式数据处理的框架Flink越来越火热,特别是这两年从Flink 1.13开始Flink做成了流批一体,他的火热程度就更不言而喻了。而我们学习Flink都是从WordCount开始的,WordCount对于现在的我们来说可能来说非常简单,但对初学者来说当时可能是我们噩梦的开始,特别是Flink的API名字相对来说都比较长,对于初学者的我们来说很容易把我们给烦死,于是我发明了这款防烦恼辅助器,设计非常的银杏,感到烦恼的小伙伴们可以对自己头上来一下就再也不会感到烦恼了(哈哈.....最近抖音刷多了,开个小玩笑)。

下面我们再简单回顾一下WordCount的代码:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> text = env.readTextFile("E:\\tmp\\hudi_flink\\src\\main\\resources\\a.txt");
SingleOutputStreamOperator<Tuple2<String, Integer>> sumDS = text.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
return new Tuple2<>(value, 1);
}
}).keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
}).sum(1);
sumDS.print();
env.execute();
可以看到代码大概分为三部分:
1.第一部分是我们创建了一个StreamExecutionEnvironment,这个是flink的执行环境。
2.第二部分就是我们写的业务代码从env.readTextFlie到sumDS.print。
3.第三部分是env.execute方法
这三部分我们都耳熟能祥了,所有的flink代码基本也是由着三部分组成的,相信了解过Flink的兄弟们都知道Flink的算子分为,分为:source算子,转换算子,sink算子。
2.Source算子源码分析
source算子也有挺多种类例如:
env.readTextFile()
env.sockerTextStream()
env.fromCollection()
env.addSource()
看似很多,其实底层调用的都是env.addSource,所以我们自定义数据源的时候可以直接使用env.addSource,下面我们简单看一下env.readTextFile()底层的源码是如何调用的
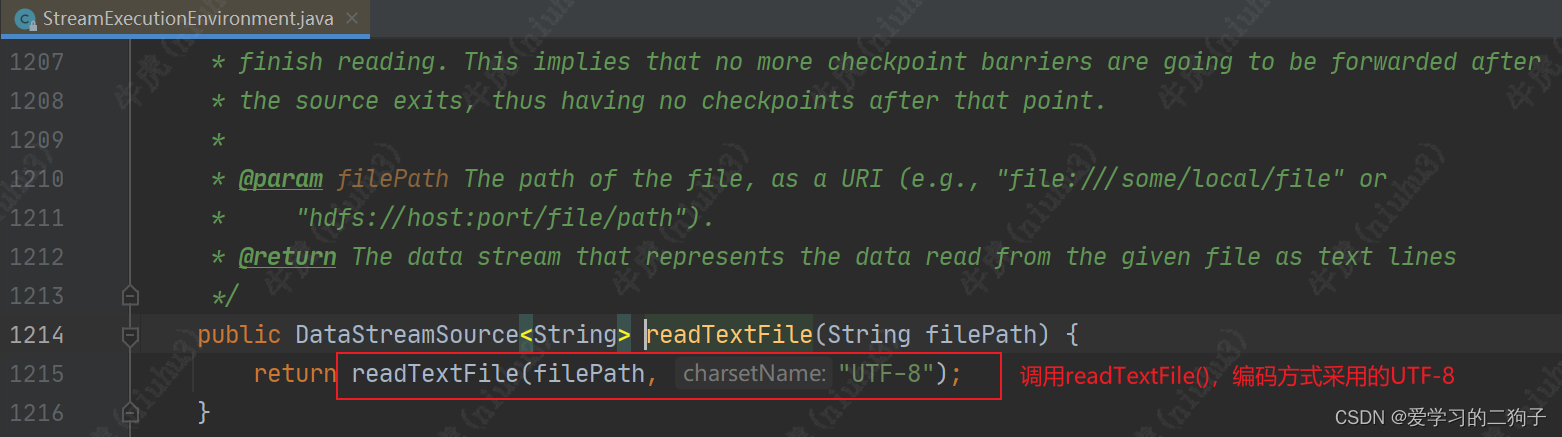
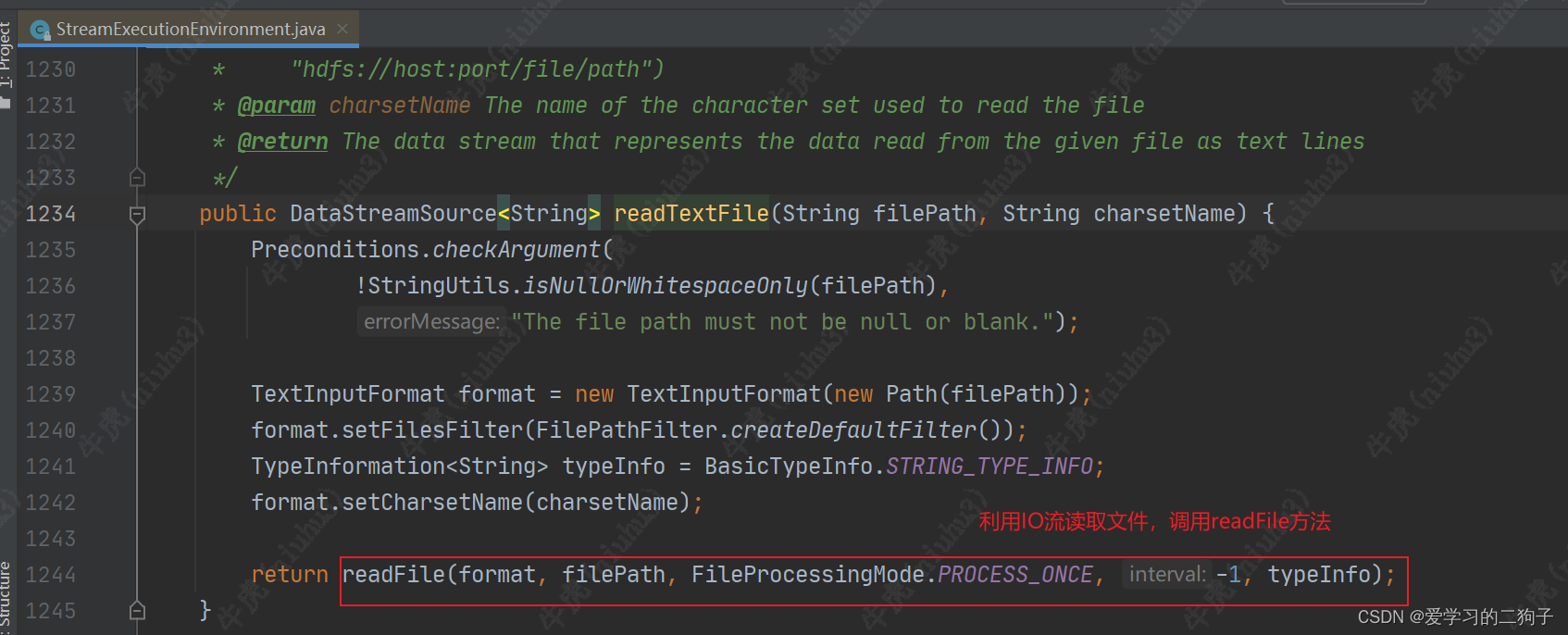
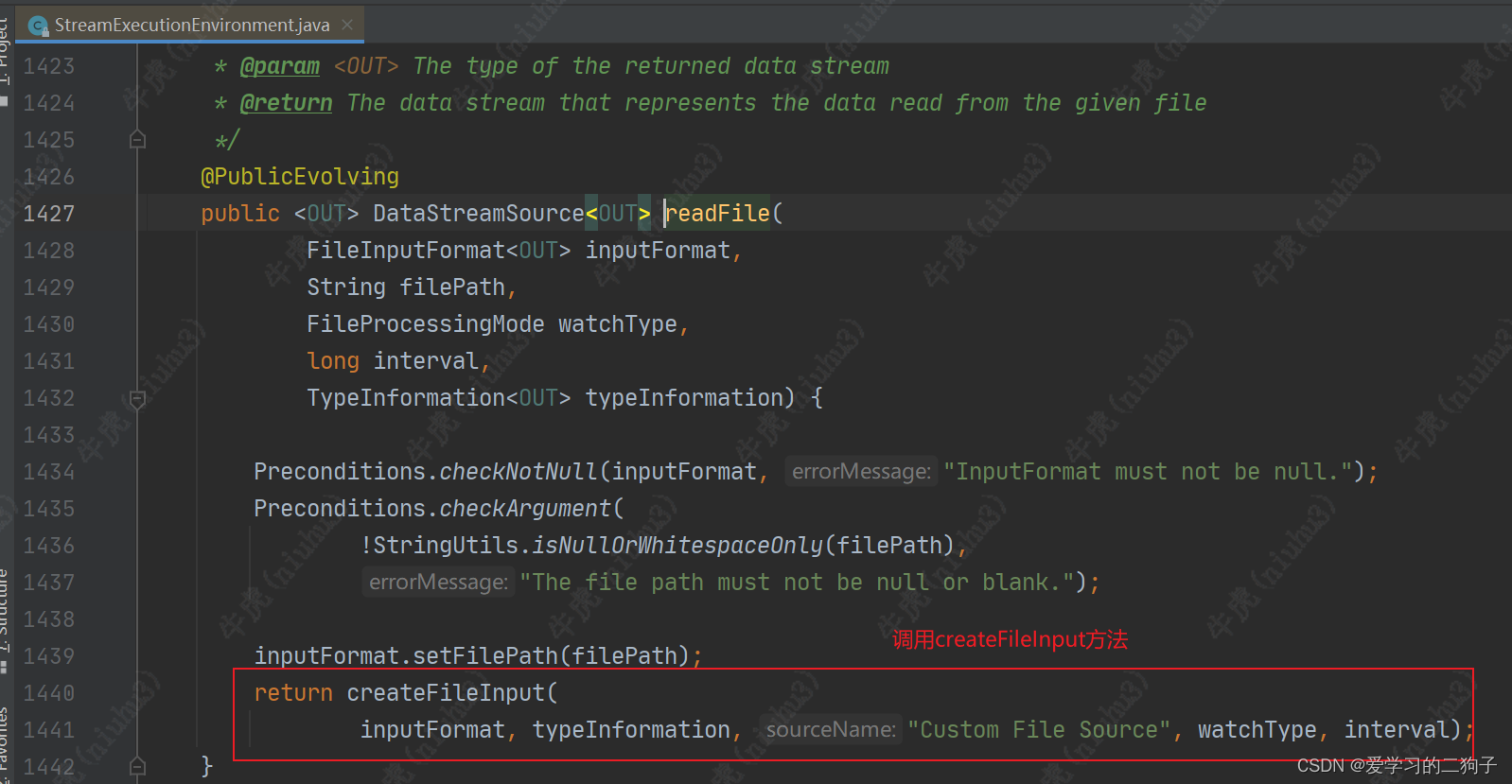
由于下面这个代码比较长,我们直接粘贴过来,可以看到里面除了校验参数,然后就是创建了一个监控函数,一个连续读文件算子的工厂,监控模式,最后调用了add.source方法。
private <OUT> DataStreamSource<OUT> createFileInput(
FileInputFormat<OUT> inputFormat,
TypeInformation<OUT> typeInfo,
String sourceName,
FileProcessingMode monitoringMode,
long interval) {
Preconditions.checkNotNull(inputFormat, "Unspecified file input format.");
Preconditions.checkNotNull(typeInfo, "Unspecified output type information.");
Preconditions.checkNotNull(sourceName, "Unspecified name for the source.");
Preconditions.checkNotNull(monitoringMode, "Unspecified monitoring mode.");
Preconditions.checkArgument(
monitoringMode.equals(FileProcessingMode.PROCESS_ONCE)
|| interval >= ContinuousFileMonitoringFunction.MIN_MONITORING_INTERVAL,
"The path monitoring interval cannot be less than "
+ ContinuousFileMonitoringFunction.MIN_MONITORING_INTERVAL
+ " ms.");
ContinuousFileMonitoringFunction<OUT> monitoringFunction =
new ContinuousFileMonitoringFunction<>(
inputFormat, monitoringMode, getParallelism(), interval);
ContinuousFileReaderOperatorFactory<OUT, TimestampedFileInputSplit> factory =
new ContinuousFileReaderOperatorFactory<>(inputFormat);
final Boundedness boundedness =
monitoringMode == FileProcessingMode.PROCESS_ONCE
? Boundedness.BOUNDED
: Boundedness.CONTINUOUS_UNBOUNDED;
SingleOutputStreamOperator<OUT> source =
addSource(monitoringFunction, sourceName, null, boundedness)
.transform("Split Reader: " + sourceName, typeInfo, factory);
return new DataStreamSource<>(source);
}
3.转换算子源码分析
转换算子的种类非常丰富,像我们这个案例中我们就用到了map,sum算子。虽然我们flink也写了很多代码,但是我们有没有详细观察过这些算子底层是调用了那些方法,今天我们就一起来看看他的底层调用是怎么样的。
1.Map算子
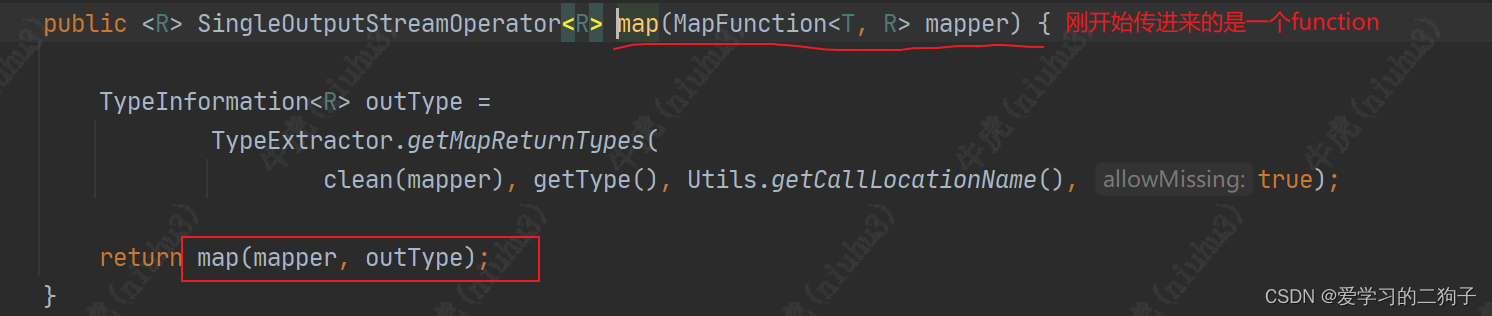

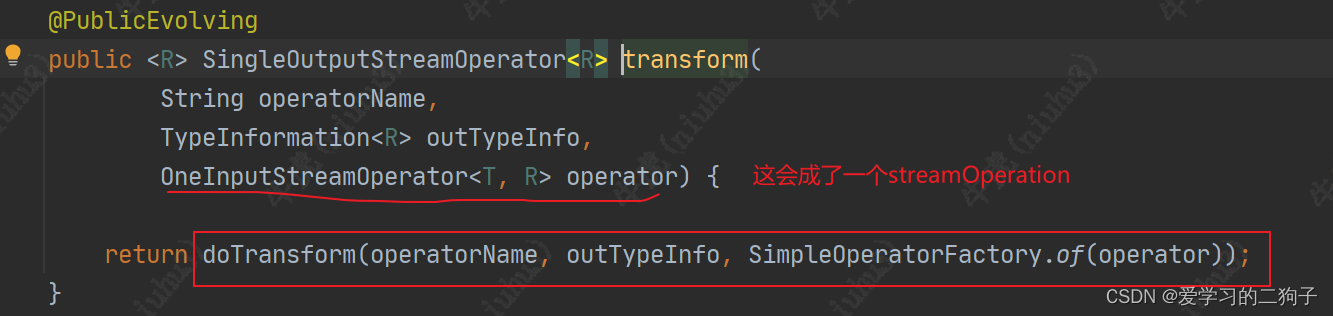
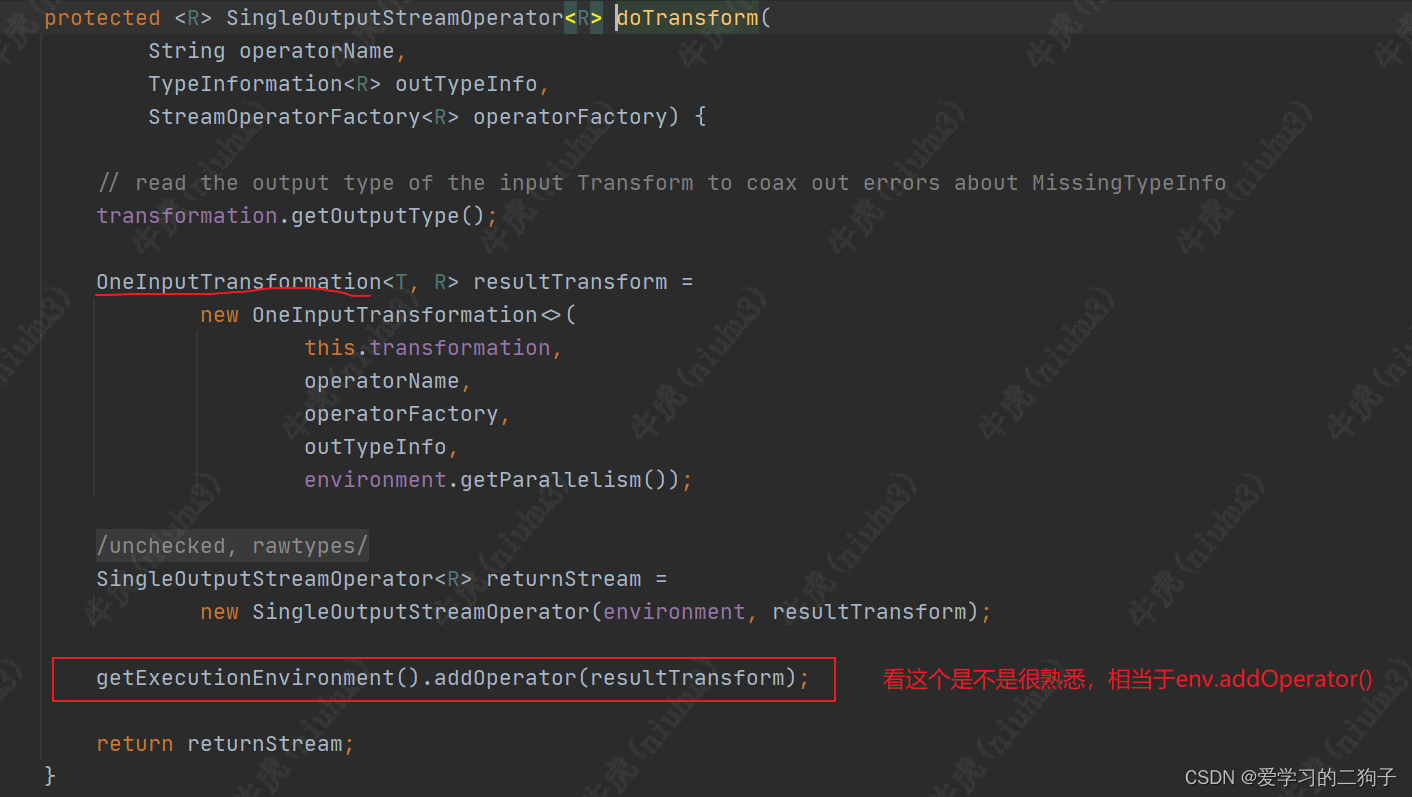
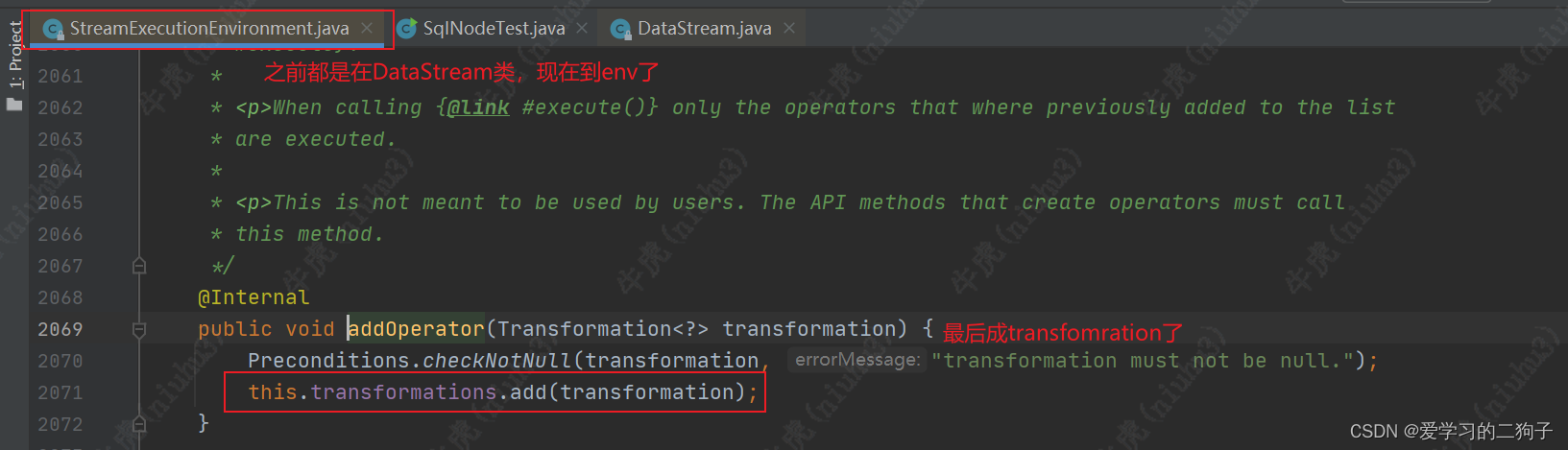
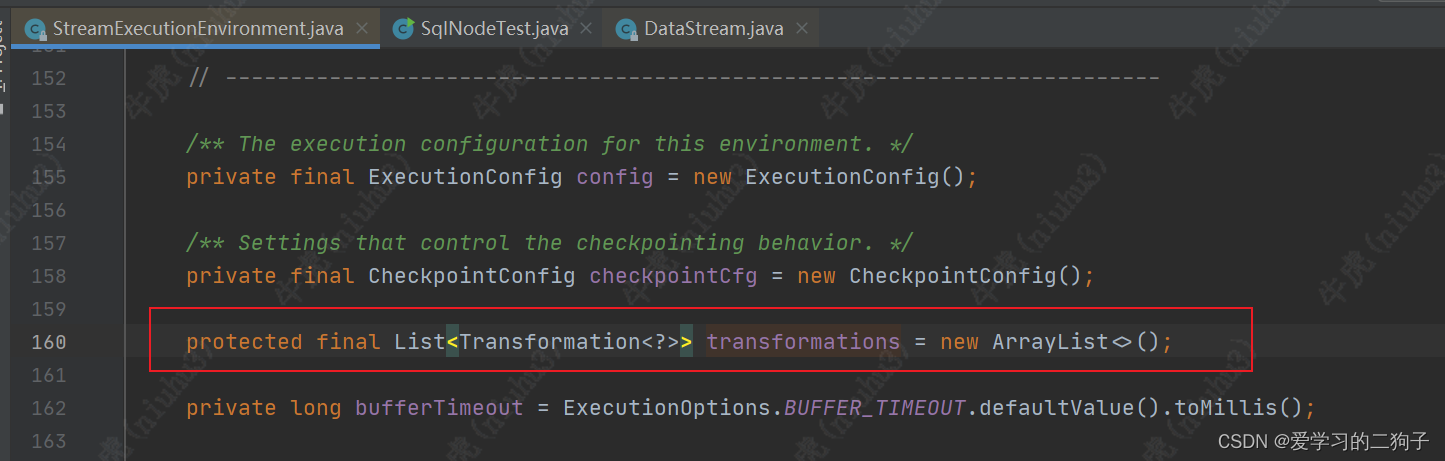
从上面我们可以看到 map方法经过一系列的调用最终从function-->streamOperator-->transformation了,最终调用transformations.add方法。transformations是env的一个成员变量,是一个list集合,专门用来放transformation,至于他的作用我们后面再说。
2.sum算子
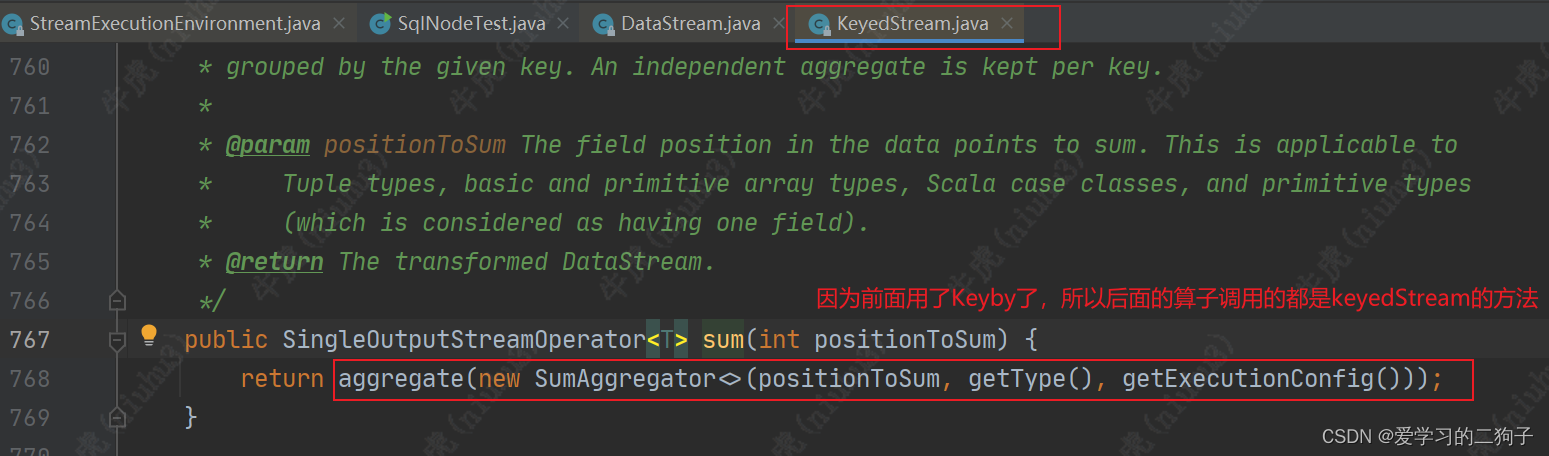

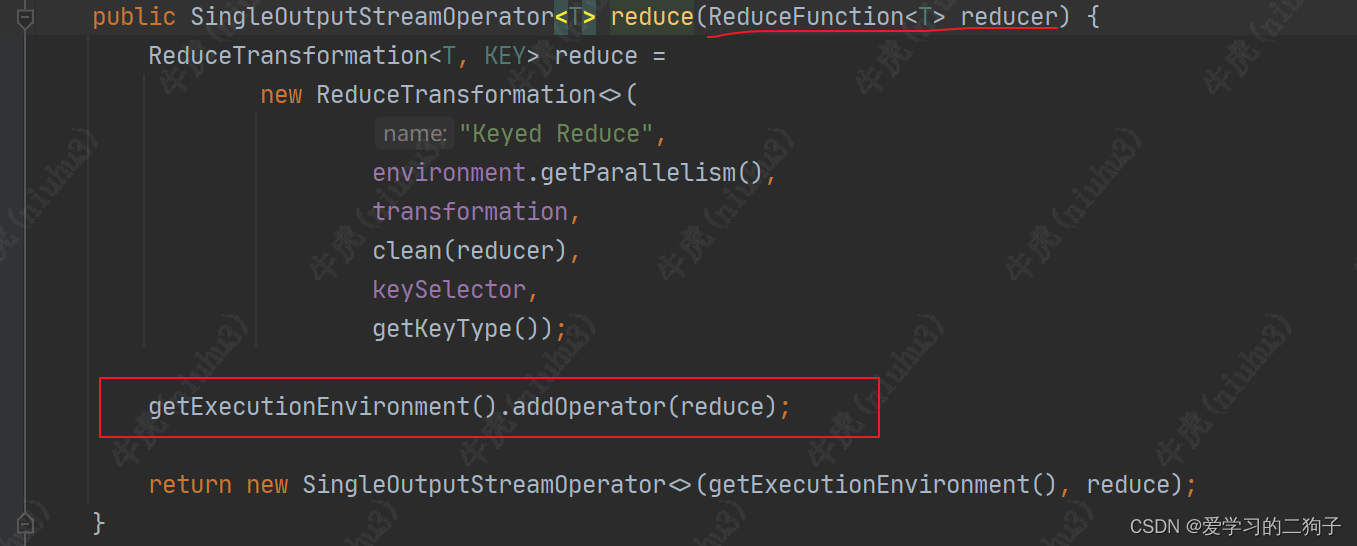

sum算子从aggregate function --> reduce function --> transformation,最终还是调用transformations.add方法,其他算子我这边就不举例了,所有transform算子最终都是调用transformations.add方法,这样flink才可以从env中拿到我们作业的血缘依赖。
3.sink算子源码分析
1.Print算子
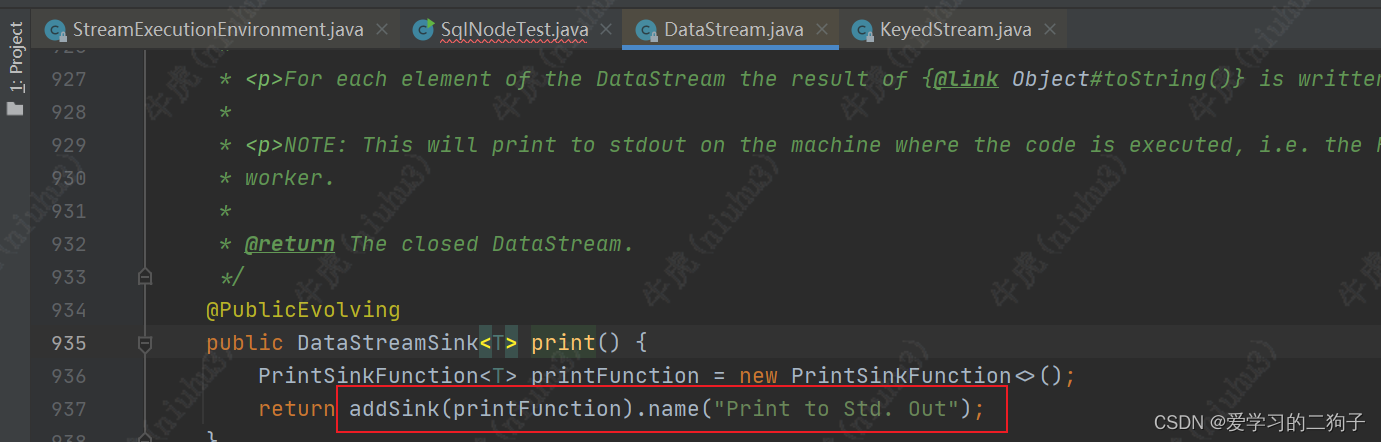
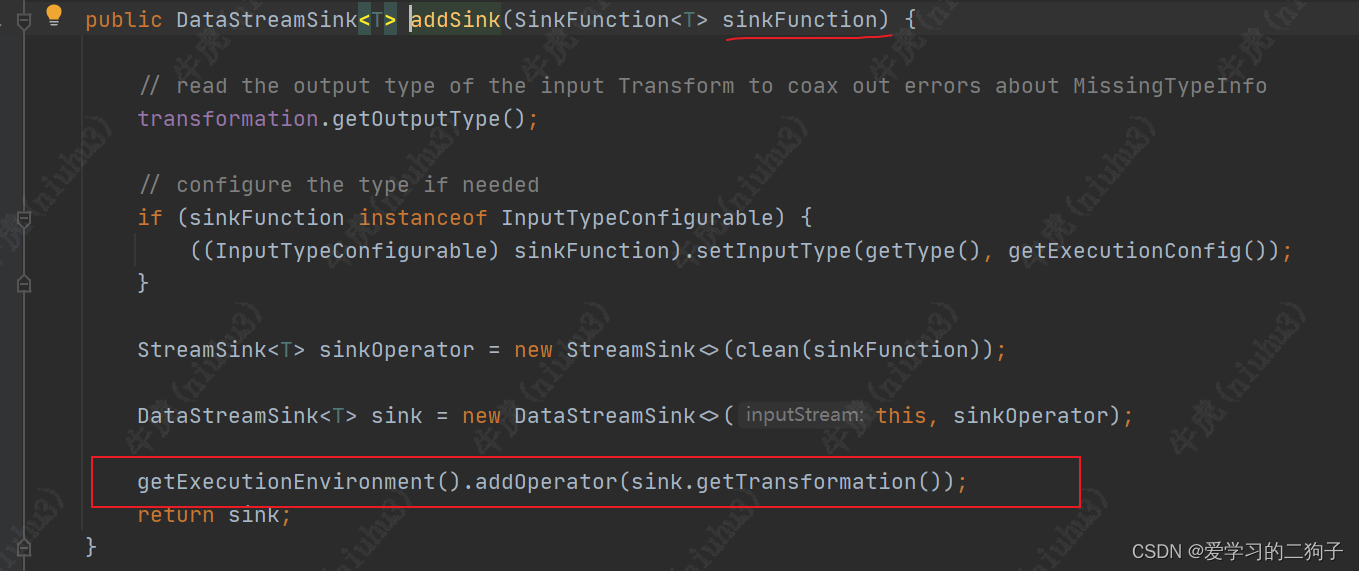
 print算子通过调用addSink --> addOperator -->add 方法,最终也加入到了transformation中
print算子通过调用addSink --> addOperator -->add 方法,最终也加入到了transformation中
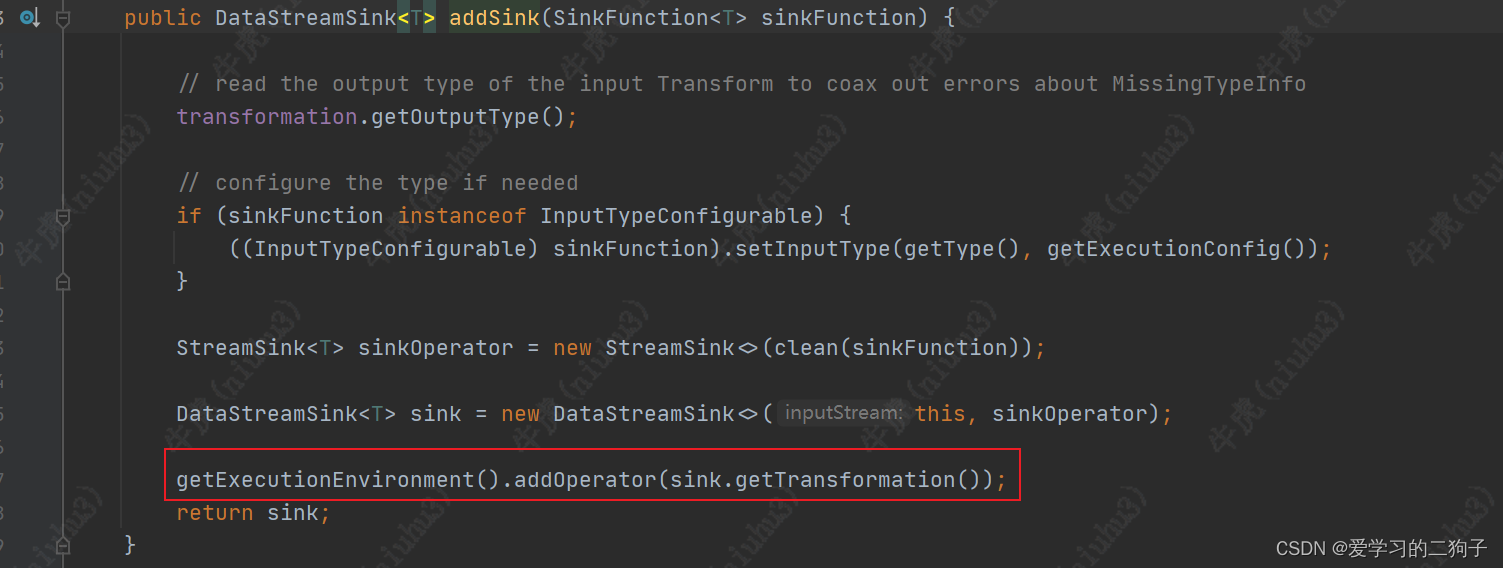
2.addSink算子
没想到addSink算子更简单,直接一步到位..![]()
好辣,今天就写这么多吧,明天继续写transformations获取到这些作业的血缘依赖该怎么处理把他交给flink来变成我们非常熟悉的streamGraph.

















 2089
2089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









