




 SlimDB是针对半排序数据的键值存储引擎,通过stepped-merge、blockindex优化和cuckoo-filter等技术提升空间效率和读性能。它适用于推荐系统特征存储、文件系统元数据管理和图基系统。stepped-merge策略减少了写放大的开销,blockindex策略利用三级结构快速定位目标键,而cuckoo-filter提供更精确的键存在检查,优于布隆过滤器。
SlimDB是针对半排序数据的键值存储引擎,通过stepped-merge、blockindex优化和cuckoo-filter等技术提升空间效率和读性能。它适用于推荐系统特征存储、文件系统元数据管理和图基系统。stepped-merge策略减少了写放大的开销,blockindex策略利用三级结构快速定位目标键,而cuckoo-filter提供更精确的键存在检查,优于布隆过滤器。
SlimDB: A Space-Efficient Key-Value Storage Engine For Semi-Sorted Data
REN KAI,CMU
问题起源:很多应用中,key不需要完全有序。而是将key分为prefix和suffix。范围查询只要将共享一个prefix的所有entry iter一遍就可以。经常出现这样的workload叫做semisorted。
应用场景:推荐系统的特征存储,文件系统的元数据管理,基于图的系统。
本文提出的优化措施有三条,依次是stepped-merge,blockindex优化,cuckoofilter。
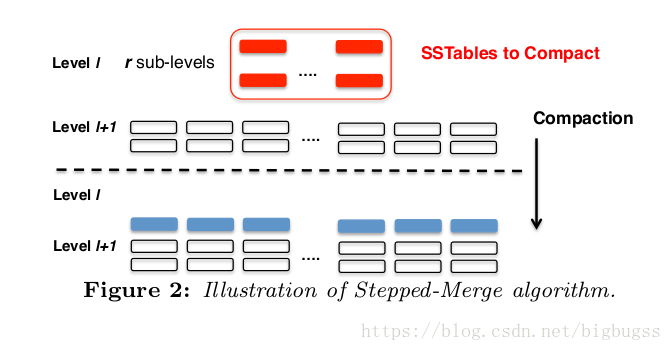
stepped-merge的lsm结构,leveli在compact过程中,会将所有sublevel的sstable合并成leveli+1的一个sublevel,这样不用承担leveli+1层sstable重写的写放大开销,类似的概念出现过很多次。但这样会导致sublevel之间keyrange的交叠。所以作者又提出了提高读性能的两个策略。
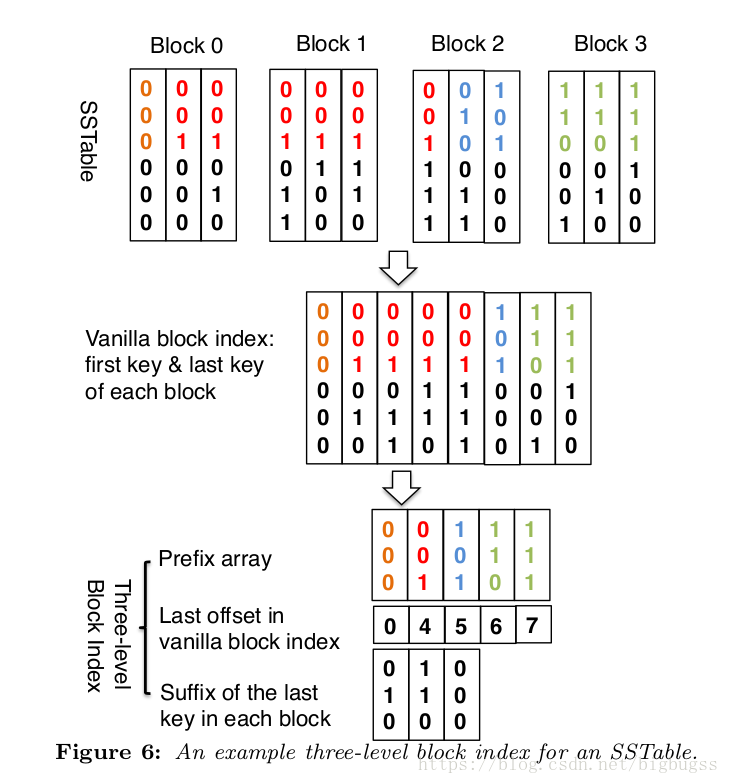
lsm可以在不同级别使用不同的indexblock实现策略。本文在l0-l2使用的是3级的block index策略。第一级保存不同的前缀,第二级保存不同前缀最后一次出现的blockid,比如4,对应的是第三个block的开始的key(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 29万+
29万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









