




 博客围绕商品图片匹配业务展开,目标是买家发送图片后通过算法找到关联店铺商品url。介绍了框架流程和具体步骤,包括数据库D哈希去重、用sift算子进行特征提取、特征匹配及倒排索引,还提及了基于CNN的改进方案。
博客围绕商品图片匹配业务展开,目标是买家发送图片后通过算法找到关联店铺商品url。介绍了框架流程和具体步骤,包括数据库D哈希去重、用sift算子进行特征提取、特征匹配及倒排索引,还提及了基于CNN的改进方案。
一、业务目标

当买家发送一张商品图片时候期望通过算法找到图片所关联的店铺商品url,从而获取包含的属性,进入下一步的处理
二、框架流程

三、具体步骤
3.1 数据库D哈希去重
#用D哈希对数据库去重
class DHash(object):
@staticmethod
def calculate_hash(image):
"""
计算图片的dHash值
:param image: PIL.Image
:return: dHash值,string类型
"""
difference = DHash.__difference(image)
# 转化为16进制(每个差值为一个bit,每8bit转为一个16进制)
decimal_value = 0
hash_string = ""
for index, value in enumerate(difference):
if value: # value为0, 不用计算, 程序优化
decimal_value += value * (2 ** (index % 8))
if index % 8 == 7: # 每8位的结束
hash_string += str(hex(decimal_value)[2:].rjust(2, "0")) # 不足2位以0填充。0xf=>0x0f
decimal_value = 0
return hash_string
@staticmethod
def hamming_distance(first, second):
"""
计算两张图片的汉明距离(基于dHash算法)
:param first: Image或者dHash值(str)
:param second: Image或者dHash值(str)
:return: hamming distance. 值越大,说明两张图片差别越大,反之,则说明越相似
"""
# A. dHash值计算汉明距离
if isinstance(first, str):
return DHash.__hamming_distance_with_hash(first, second)
# B. image计算汉明距离
hamming_distance = 0
image1_difference = DHash.__difference(first)
image2_difference = DHash.__difference(second)
for index, img1_pix in enumerate(image1_difference):
img2_pix = image2_difference[index]
if img1_pix != img2_pix:
hamming_distance += 1
return hamming_distance
@staticmethod
def __difference(image):
"""
*Private method*
计算image的像素差值
:param image: PIL.Image
:return: 差值数组。0、1组成
"""
resize_width = 9
resize_height = 8
# 1. resize to (9,8)
smaller_image = image.resize((resize_width, resize_height))
# 2. 灰度化 Grayscale
grayscale_image = smaller_image.convert("L")
# 3. 比较相邻像素
pixels = list(grayscale_image.getdata())
difference = []
for row in range(resize_height):
row_start_index = row * resize_width
for col in range(resize_width - 1):
left_pixel_index = row_start_index + col
difference.append(pixels[left_pixel_index] > pixels[left_pixel_index + 1])
return difference
@staticmethod
def __hamming_distance_with_hash(dhash1, dhash2):
"""
*Private method*
根据dHash值计算hamming distance
:param dhash1: str
:param dhash2: str
:return: 汉明距离(int)
"""
difference = (int(dhash1, 16)) ^ (int(dhash2, 16))
return bin(difference).count("1")
#维护一张哈希表去重,哈希值完全相等去除
def filter_database(source_data_dir, des_data_dir):
'''
source_dataset: 原始数据库地址
des_dataset: 去重后数据库地址
'''
database_dict = dict()
image_files = glob.glob(source_data_dir+'*.jpg')
for image_file in image_files:
#print("image_file: ", image_file)
im = Image.open(image_file)
print("im mode: ", im.mode)
hash_string = DHash.calculate_hash(im)
database_dict[hash_string] = image_file
#break
for k, v in database_dict.items():
shutil.copyfile(v, des_data_dir+str(Path(v).name))
return len(database_dict)
3.2 特征提取
sift算子提取
def feature_extract(img):
sift = cv.xfeatures2d.SIFT_create()
kp, des = sift.detectAndCompute(img, None)
return des
3.3 特征匹配
匹配效果:
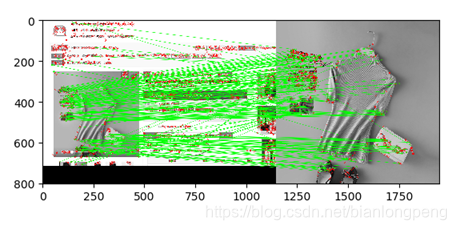
定义metric函数:
distance=match(des1,des2)flann.match(des1,des2)distance={match(des1,des2) \over {flann.match(des1,des2)}}distance=flann.match(des1,des2)match(des1,des2)
des1和des2为提取的检索图片和数据库比对图片的sift特征。即首先通过flann算法粗匹配两幅图片的匹配特征点,进一步的通过比较筛选点的欧氏距离,阈值设为0.7,以此确定匹配的点,P为精细匹配点和粗匹配点的比值
def sift_distance(des1, des2):
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks=50) # or pass empty dictionary
flann = cv.FlannBasedMatcher(index_params,search_params)
matches = flann.knnMatch(des1,des2,k=2)
# Need to draw only good matches, so create a mask
matchesMask = [[0,0] for i in range(len(matches))]
#print(len(matchesMask))
# ratio test as per Lowe's paper
num = 0
for i,(m,n) in enumerate(matches):
if m.distance < 0.7*n.distance:
matchesMask[i]=[1,0]
num += 1
distance = 1 - num*1.0/len(matches)
#该值越大说明距离越远
return distance
3.4 倒排索引
对所有计算出的distance进行排序,输出Top
四、基于CNN的改进方案


















 1076
1076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









