






 本文详细介绍了Scrapy的安装、项目创建、爬虫文件建立及配置、日志管理和数据输出过程。通过实例展示了如何处理爬虫数据,包括消除Selector、使用pipelines进行数据处理。在遇到问题时,如数据传递错误,文中提供了解决方案,强调了pipelines的启用和配置。最终,成功实现了数据的输出和日志控制。
本文详细介绍了Scrapy的安装、项目创建、爬虫文件建立及配置、日志管理和数据输出过程。通过实例展示了如何处理爬虫数据,包括消除Selector、使用pipelines进行数据处理。在遇到问题时,如数据传递错误,文中提供了解决方案,强调了pipelines的启用和配置。最终,成功实现了数据的输出和日志控制。
1.scrapy的安装
pip install scrapy
2.scrapy项目的创建
1.首先找到要建立项目的位置

在路径前面加上cmd然后回车
2.输入建立scrapy项目的命令
scrapy startproject + 你要起的项目名称
例如:scrapy startproject study

出现这个就说明创建成功了,打开pycharm就可以查看项目的结构
3.建立爬虫项目
1.在cmd命令中输入cd 加刚才的项目名

2.输入创建爬虫文件的命令
scrapy genspider 爬虫名称 爬取范围,要爬网站的起始url
例如: scrapy genspider baidu www.baidu.com
3.配置爬虫文件
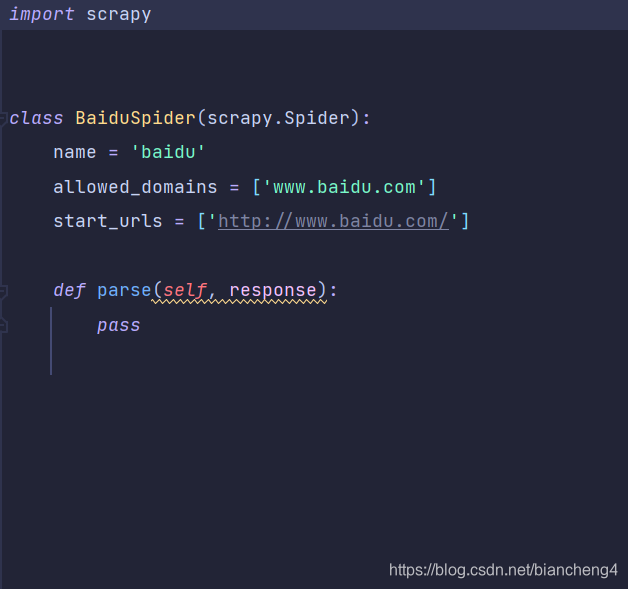
这是建立爬虫文件自带的,起始的url也会自己填进去, 也可以自己进行更改,接下来我们就可以在parse函数里面进行爬虫代码的编写了
4.运行爬虫代码
1.写好爬虫代码
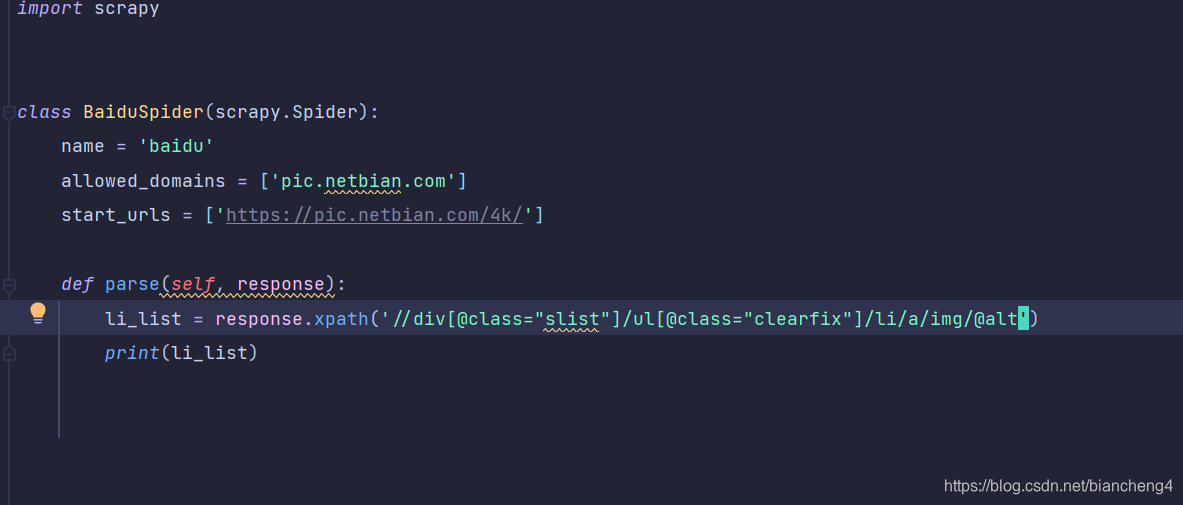
我们以彼岸图网为例
2.打开命令窗口输入如下指令
scrapy crawl 爬虫名称
例如:scrapy crawl baidu
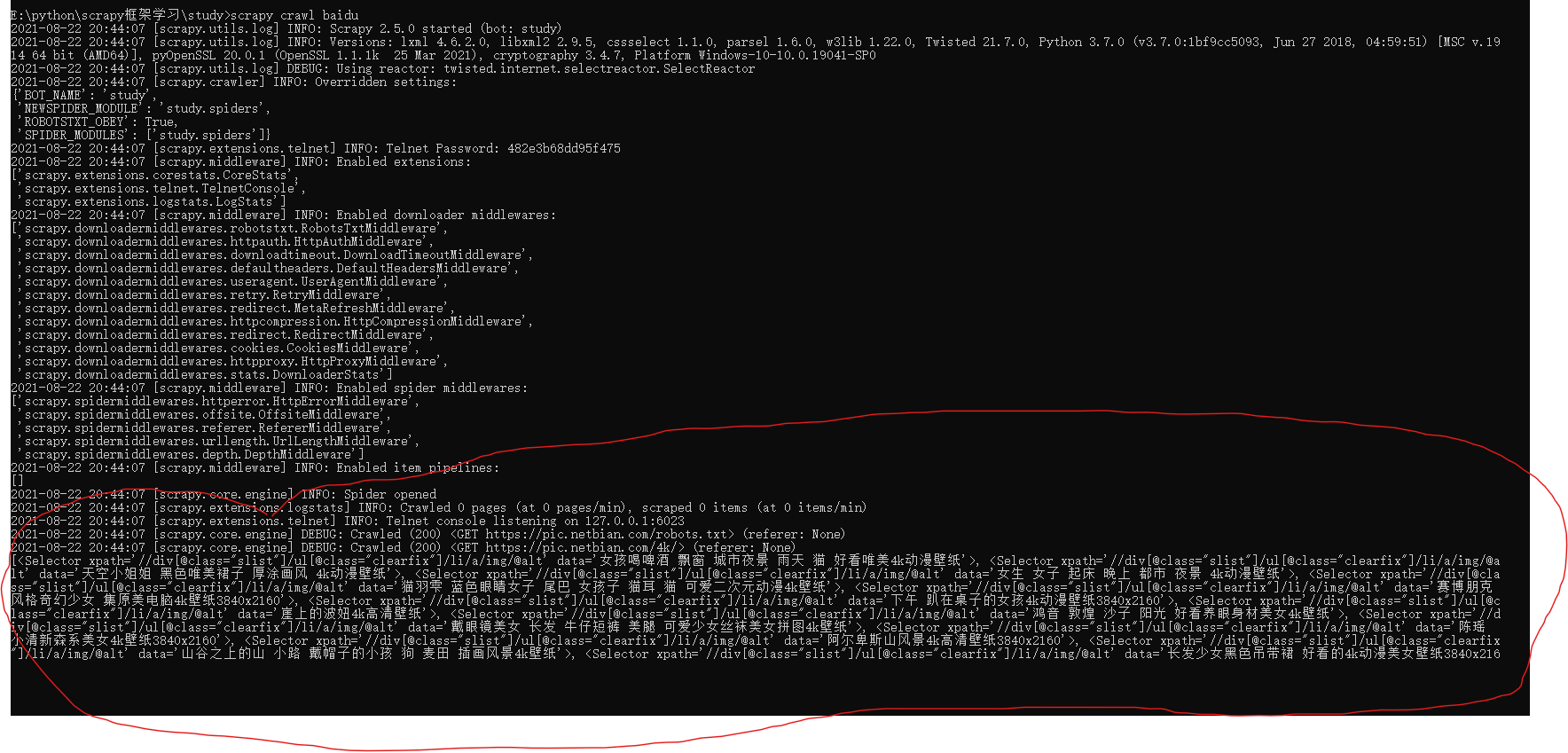 可以看到日志文件非常的多,怎样关闭日志呢。
可以看到日志文件非常的多,怎样关闭日志呢。
3.关闭日志
进入项目文件打开seetings文件
在里面加入如下代码
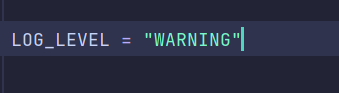
这样只有级别为WARNING的错误才会出现,看看效果

但是这样的数据还是非常的杂乱,每句都有Selector。
4.消除Selector

在我们的语句后面加上.extract()就可以了,看下效果

5.在pipelines输出爬虫数据
1.传递数据到pipelines
使用yield将数据从爬虫文件传入pipelines
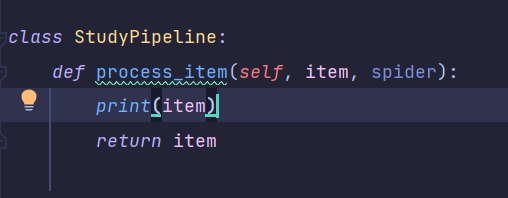
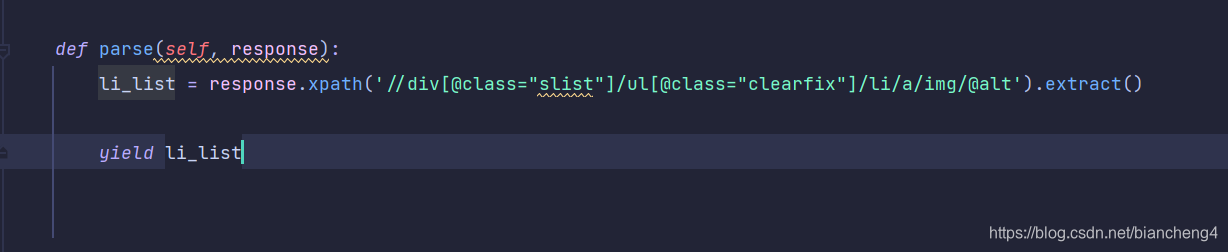 然后再pipelines将数据输出一下
然后再pipelines将数据输出一下

结果运行爬虫的时候报错了, 他说只能传递request对象,字典,或者空,而我们传递的是一个列表
2.修改传递数据
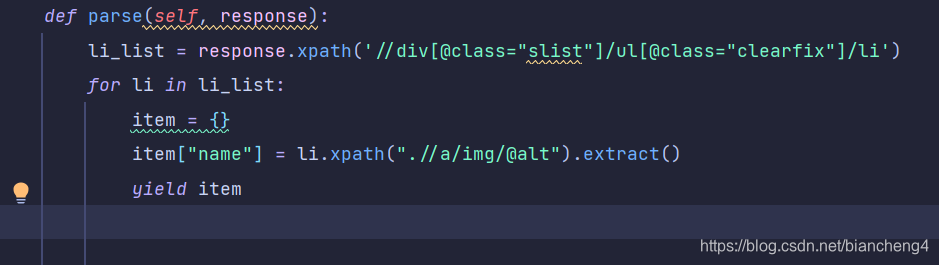
我们把数据变为字典结构再来一次

结果为空直接跳过了,这里发现我们没有开启pipelines
3.在seetings中找到ITEM_PIPELINES去掉他的注释即可
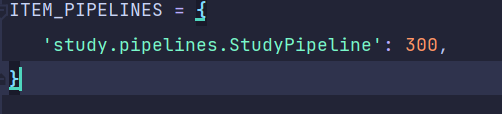
后面的值越小,执行越优先,现在我们执行运行爬虫命令
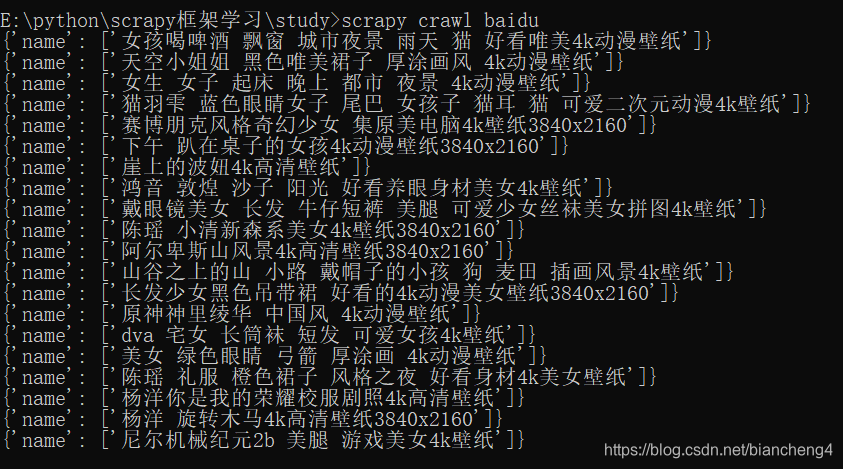
已经可以输出了。
4.解释一下后面的数字
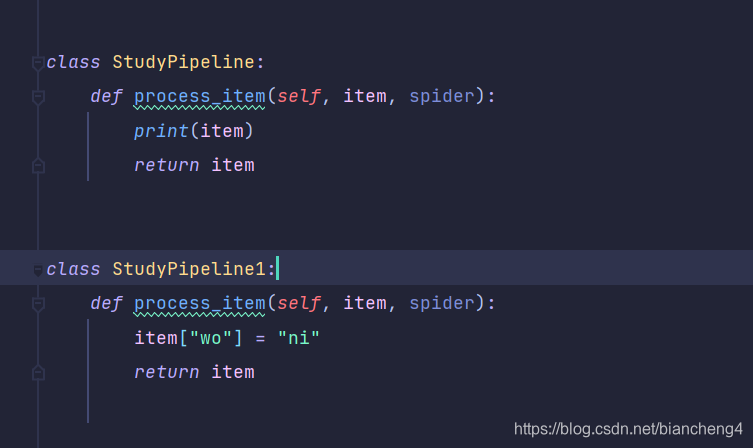
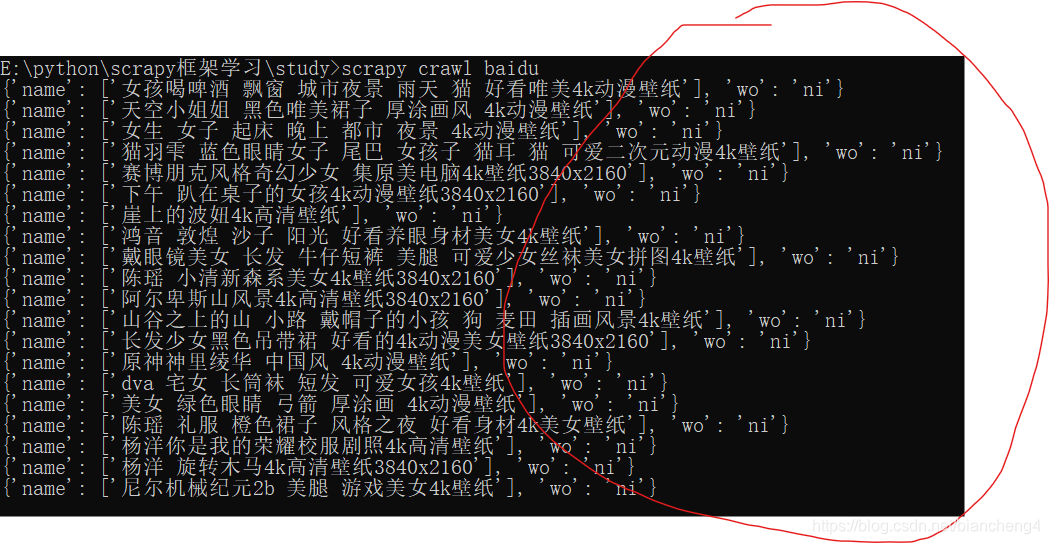
我们在pipelines中再复制一个类, 然后进入settings中,加入新建的类

如果我们输出的结果中出现了wo与ni的那一行字典,说明其先经过了299这个类中


















 64万+
64万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









