



先熟悉Mybatis的构建环境,Mybatis里面的一些语法和api
1.创建一个Maven项目,然后在里面进行环境的配置。
(1)创建一个普通的Maven项目,里面不要选Archetype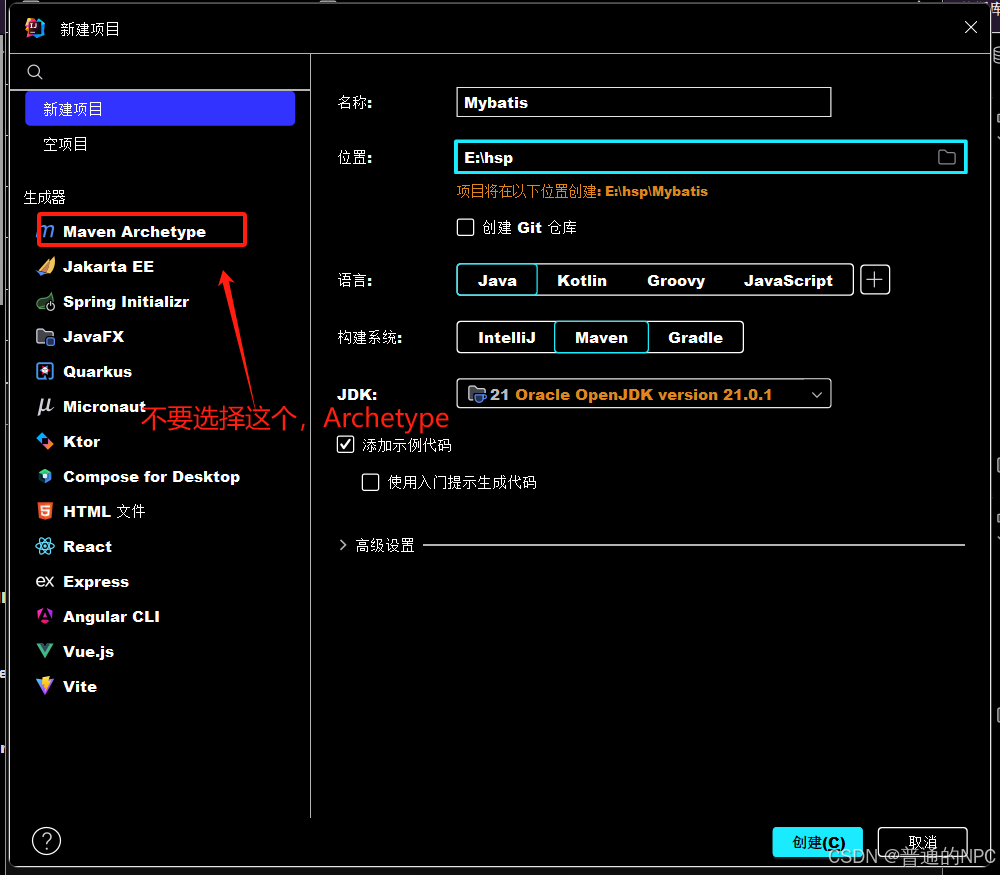
(2)创建好之后更改自己对应的项目坐标,pom.xml文件里面去修改: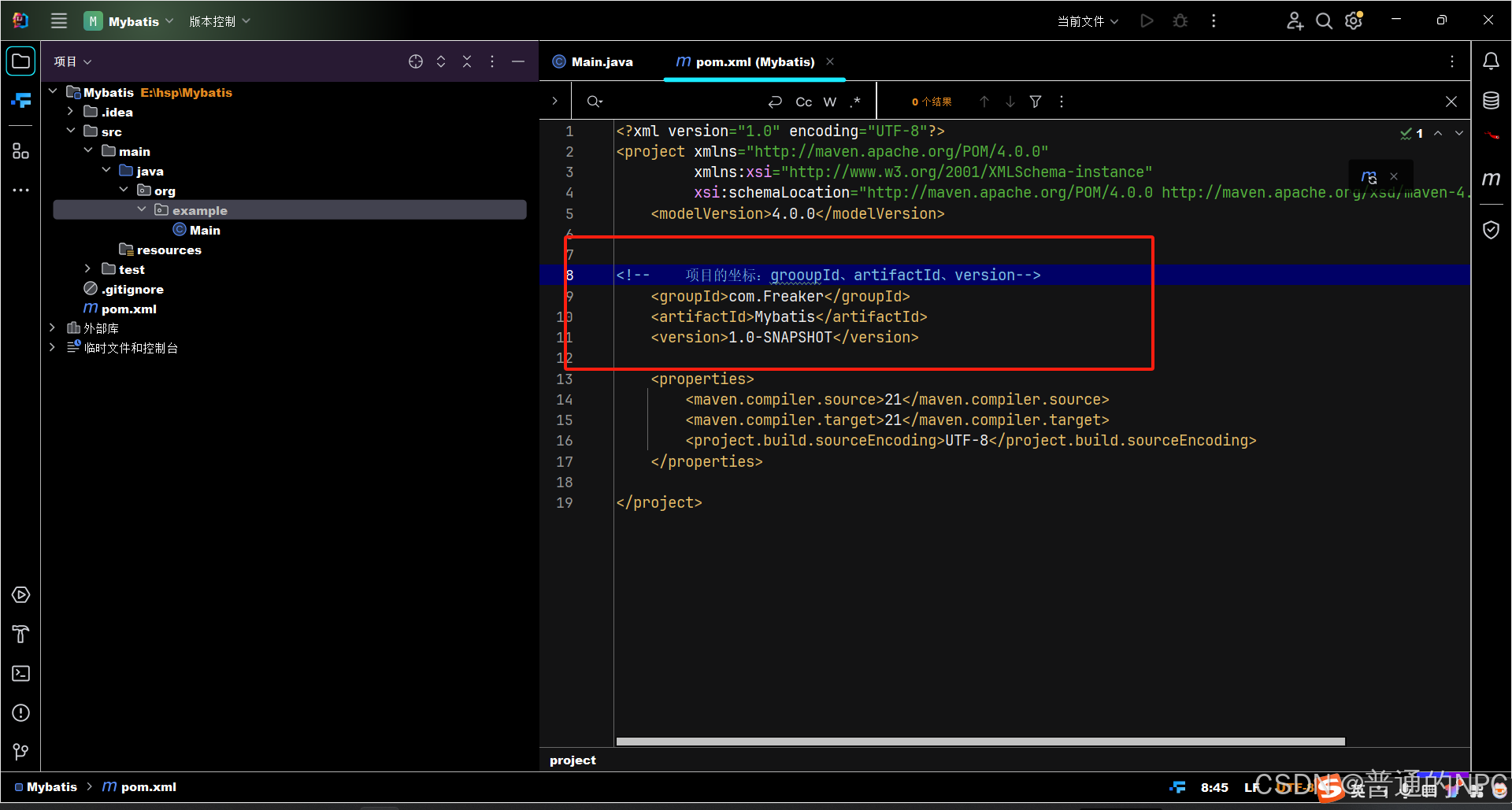
(3)删除src目录,我们要引入“父项目,子项目的概念”: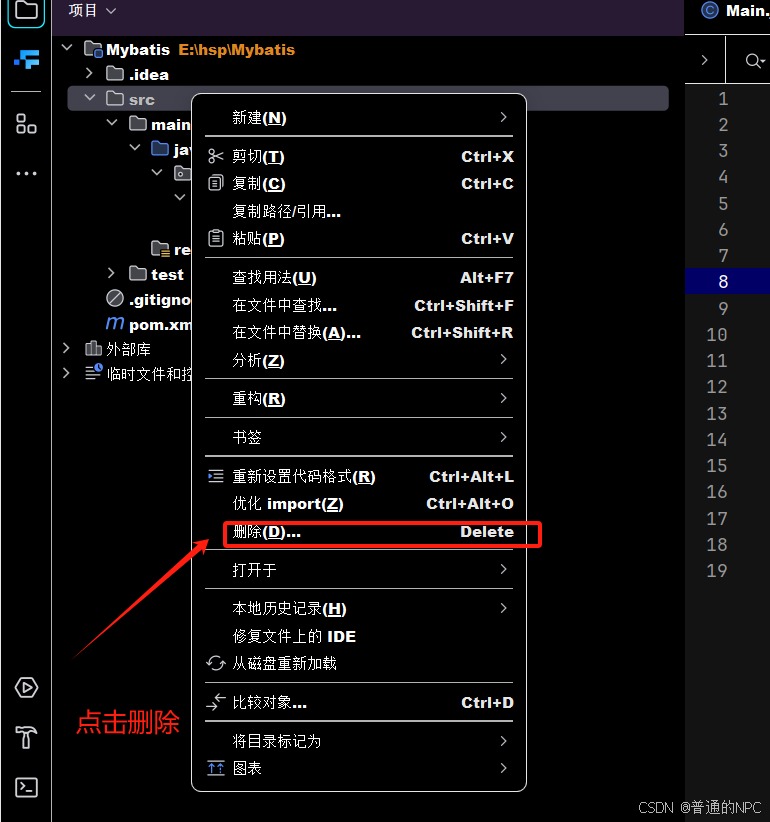
(4)删除后的效果: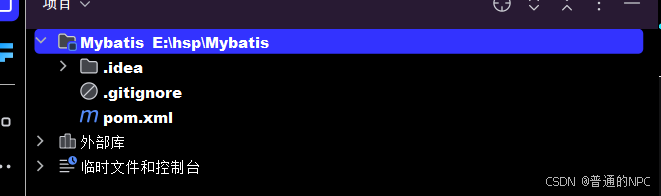
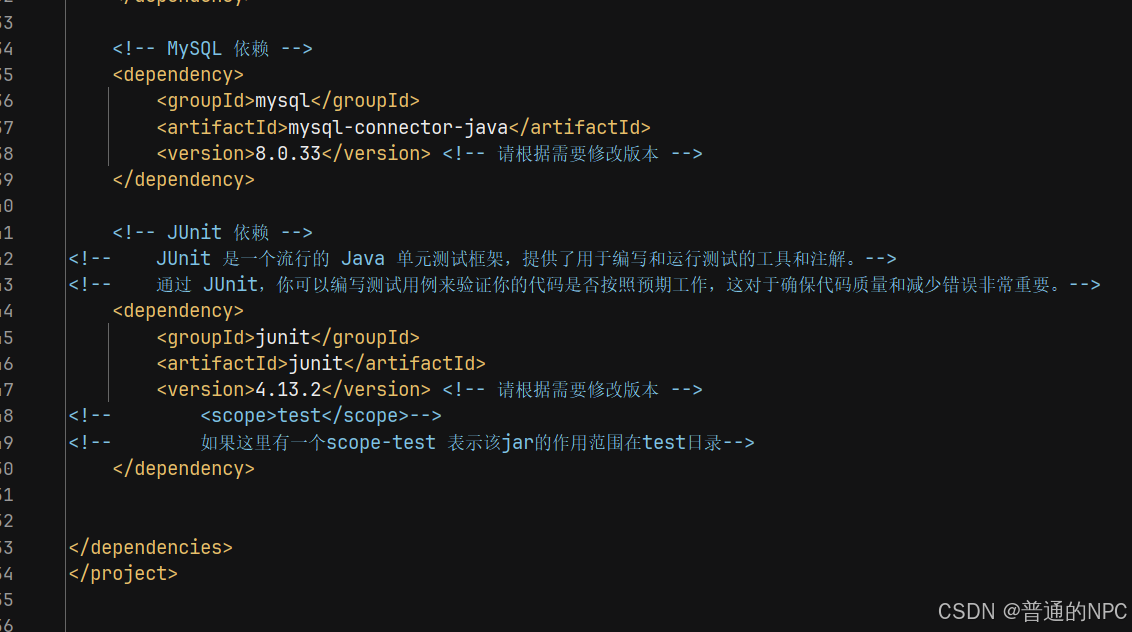
(5)添加上相关的依赖:Mybatis,mysaql,junit依赖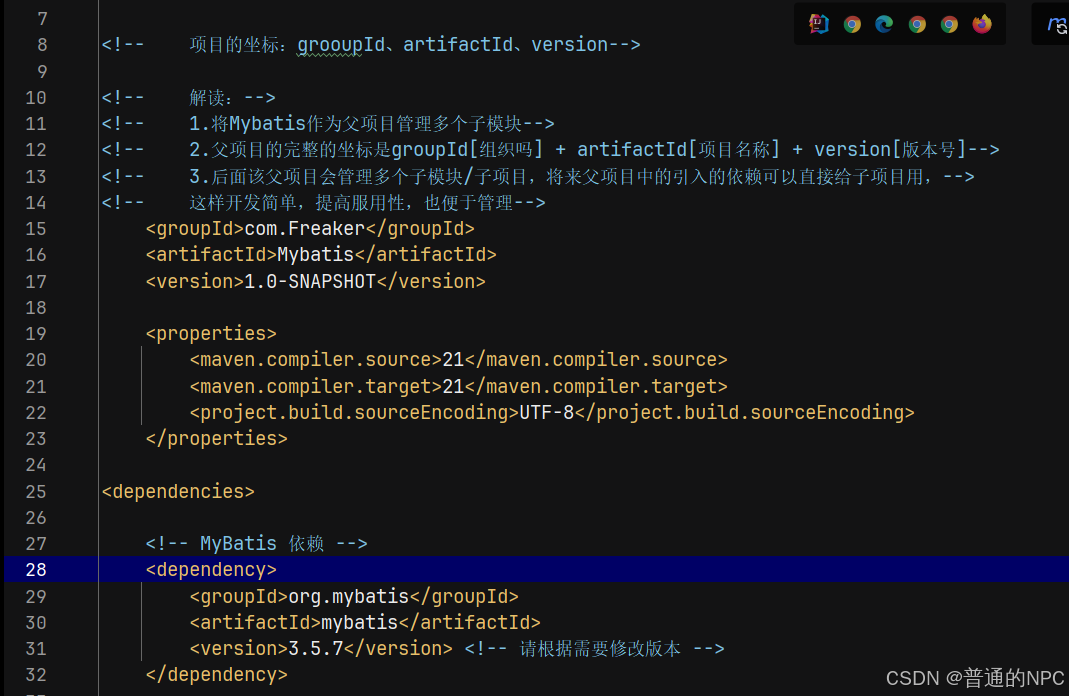
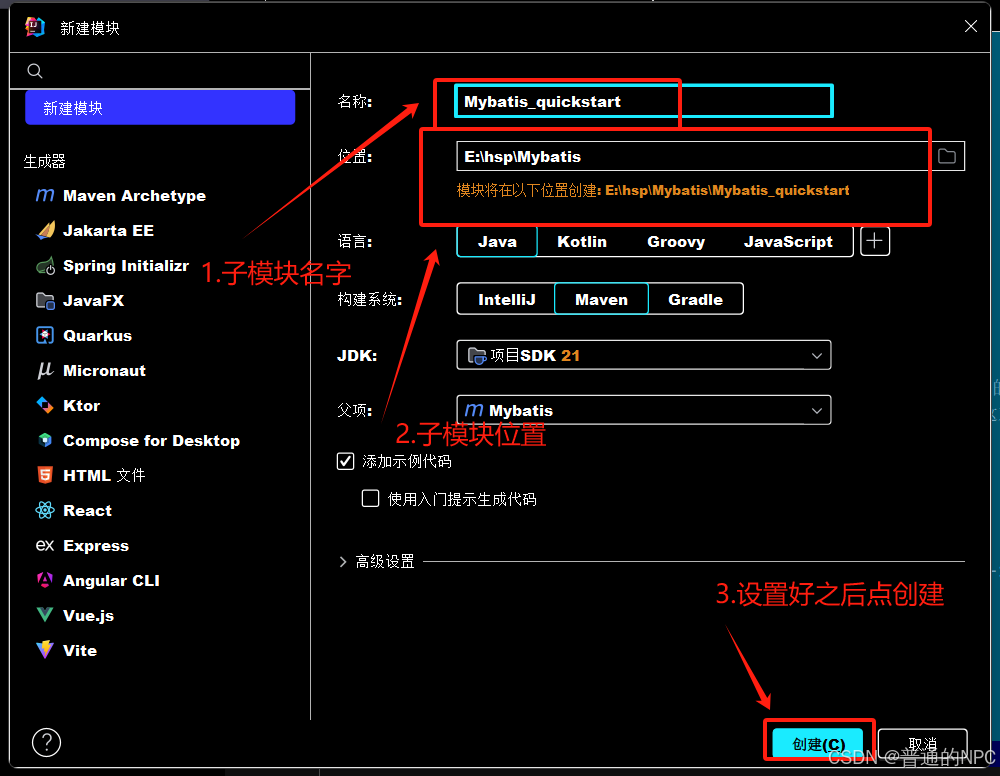
(6)新建子模块:
创建好子模块的效果:
父项目的pom.xml文件显示: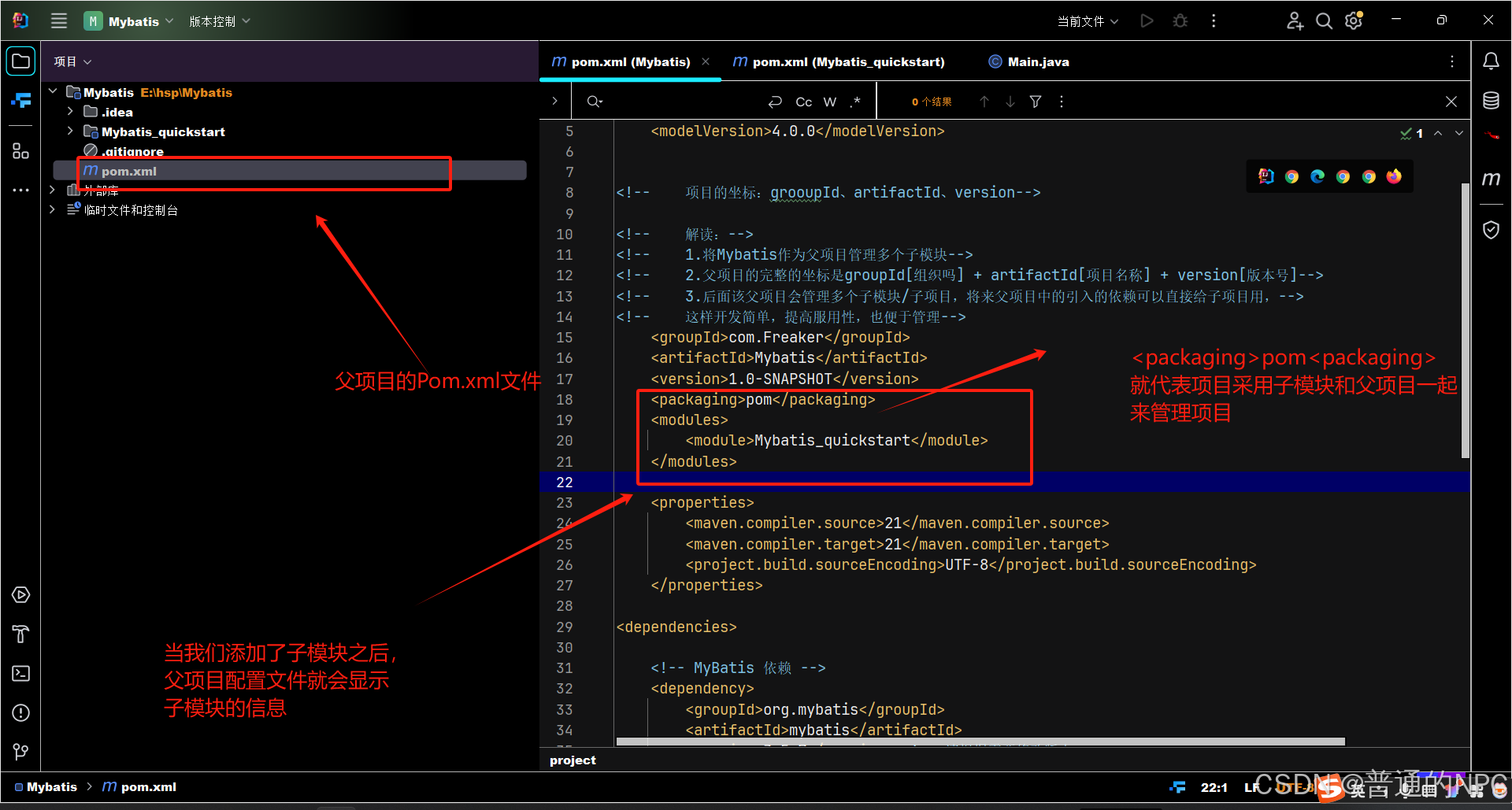 子项目的配置文件显示:
子项目的配置文件显示: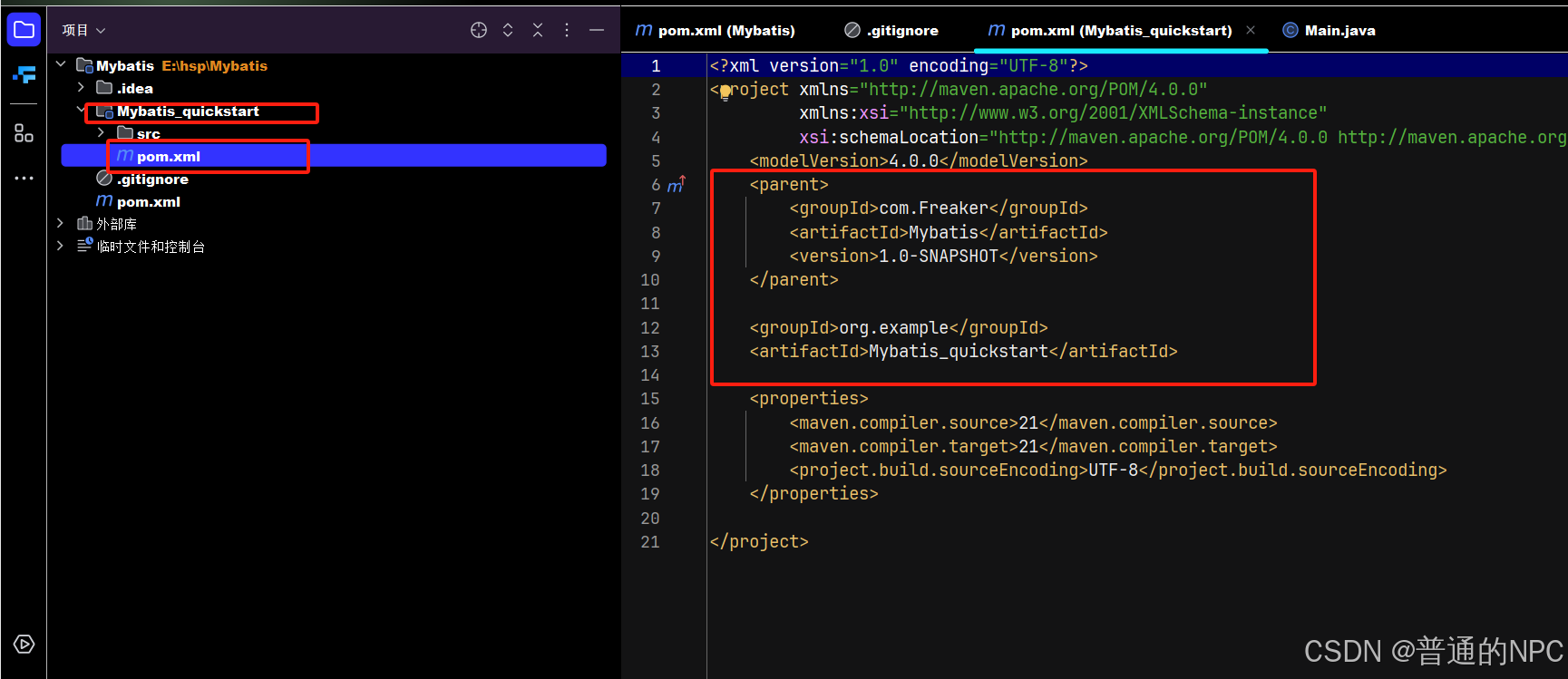
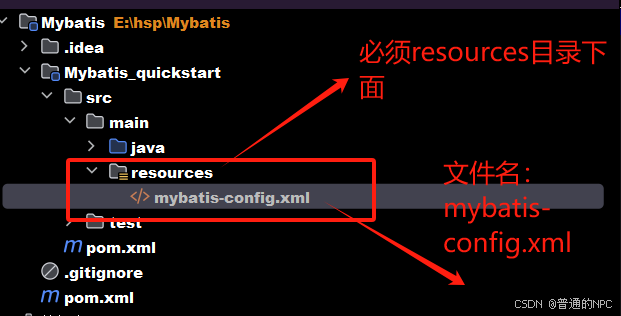
(7)创建子模块的mybatis-config.xml文件,必须放在子模块的resourses目录下面:
提示:mybatis-config.xml(配置文件的名字可以修改,但是约定俗成就是“mybatis-config.xml”)
”
我们的mybatis-config.xml文件最重要的两大作用:
mybatis-config.xml文件的标准代码模版:1.配置数据库连接/数据源 2.管理XXMapper.xml文件
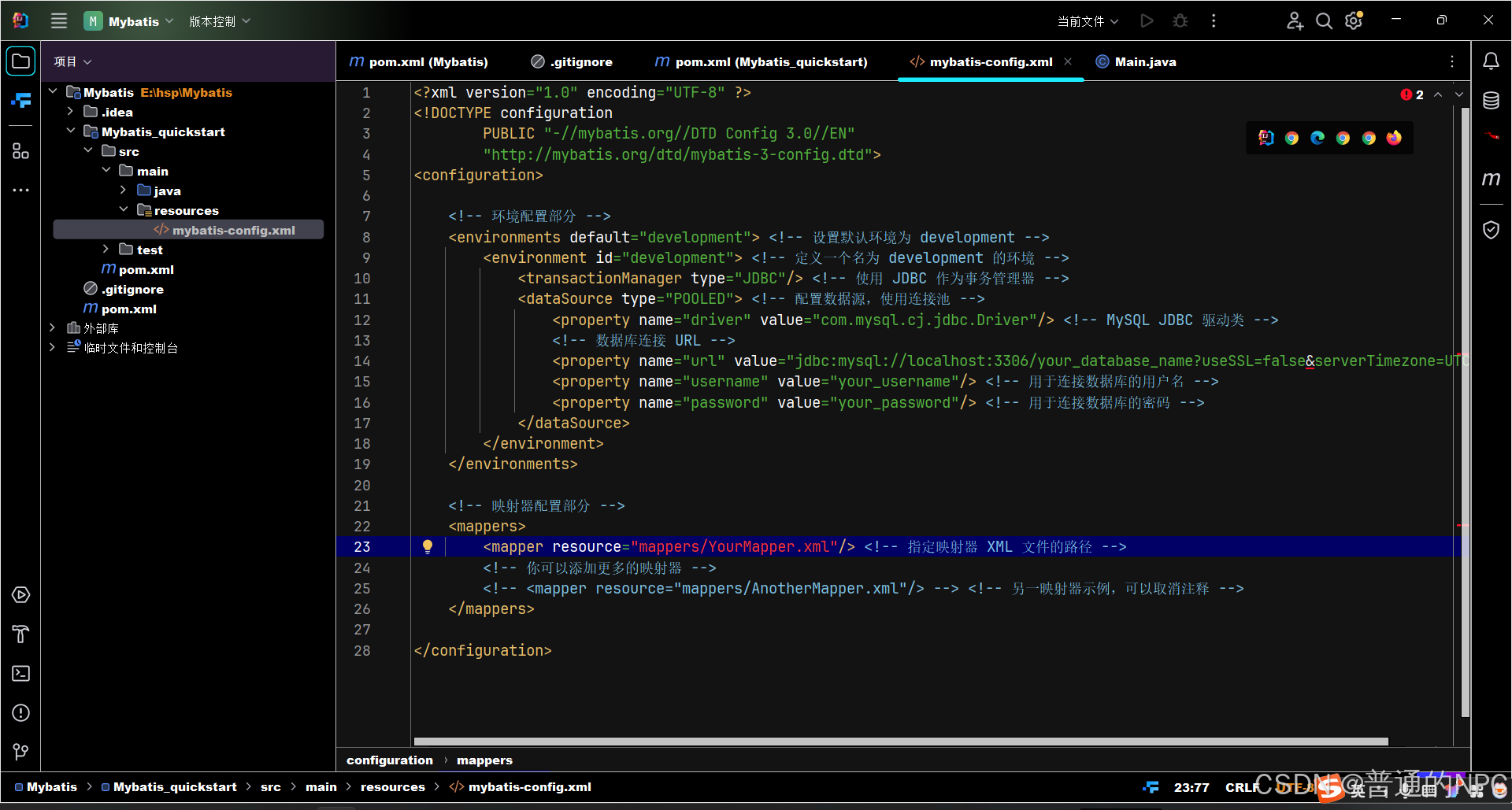 (8)在我们的entity包下面创建一个monster类:
(8)在我们的entity包下面创建一个monster类: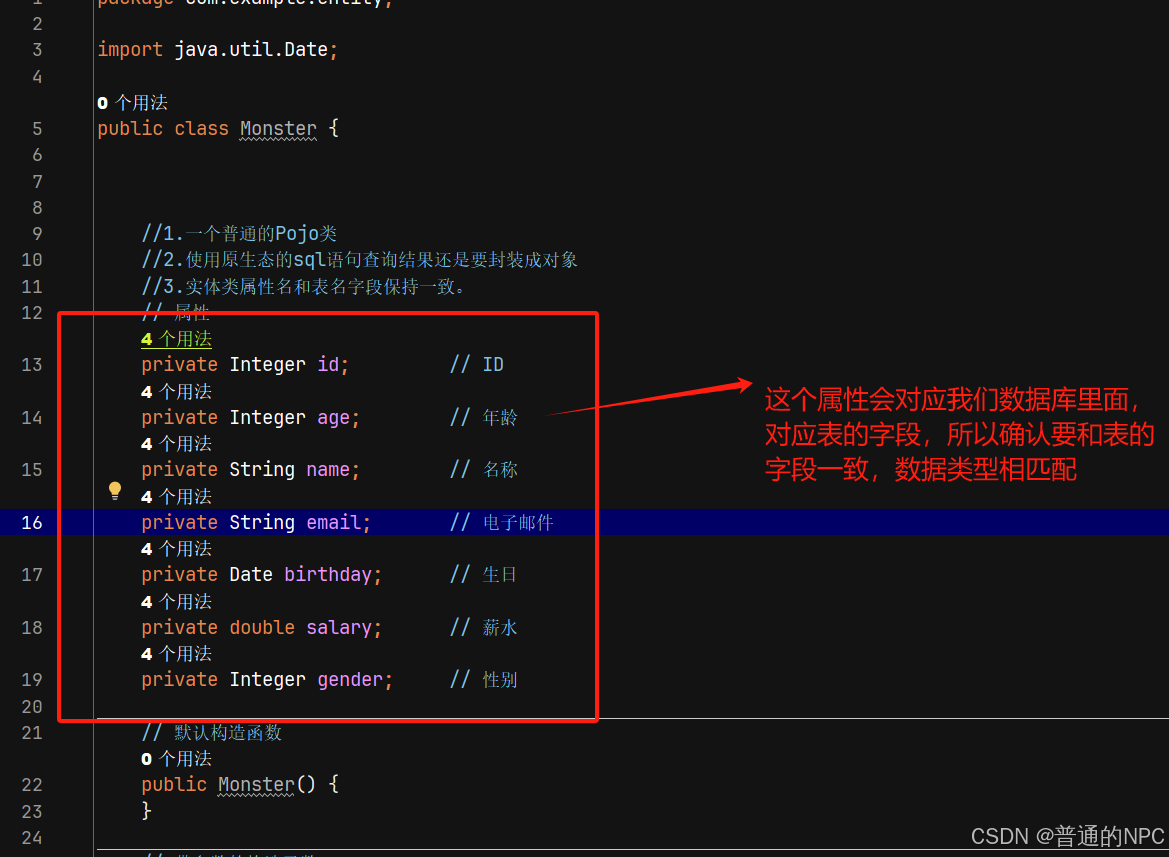
去我们数据库创建对应的表: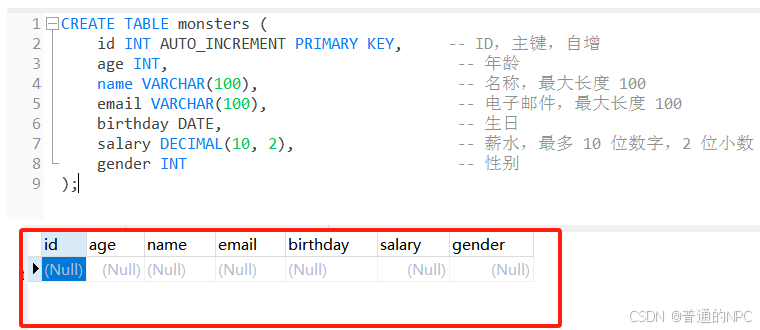
添加我们数据库的数据源: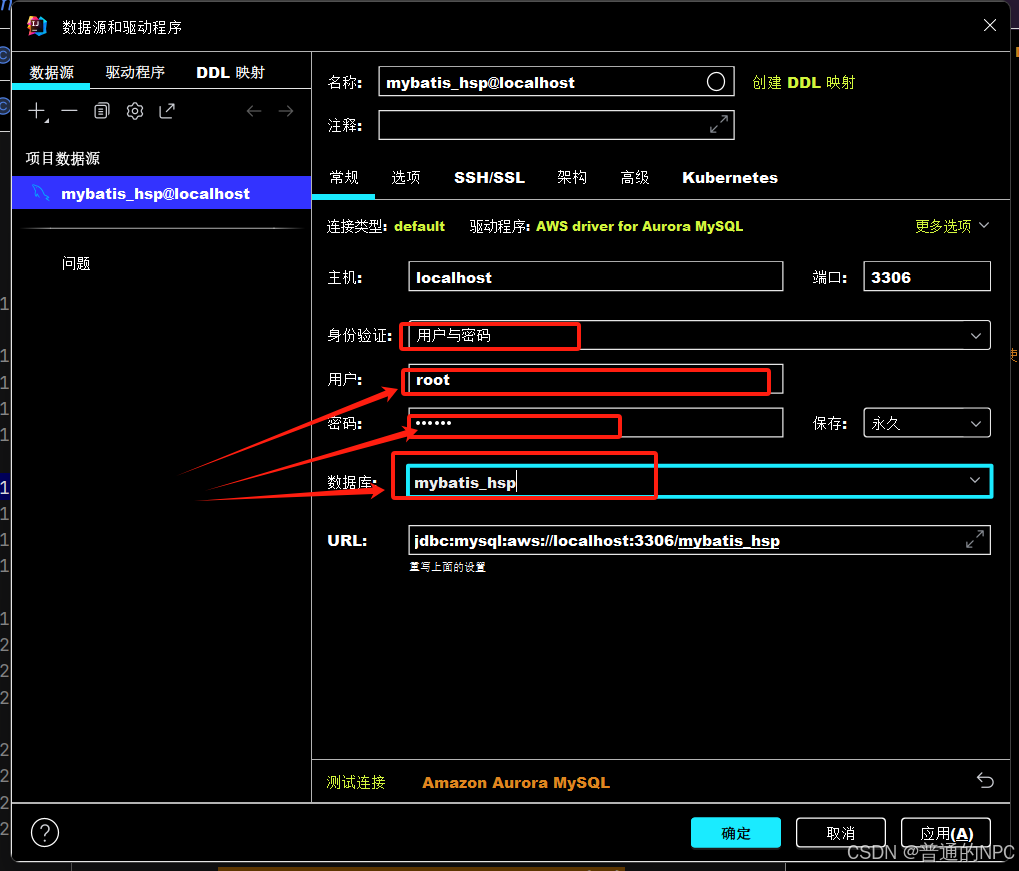
然后去创建我们实体类对应的 mapper代码: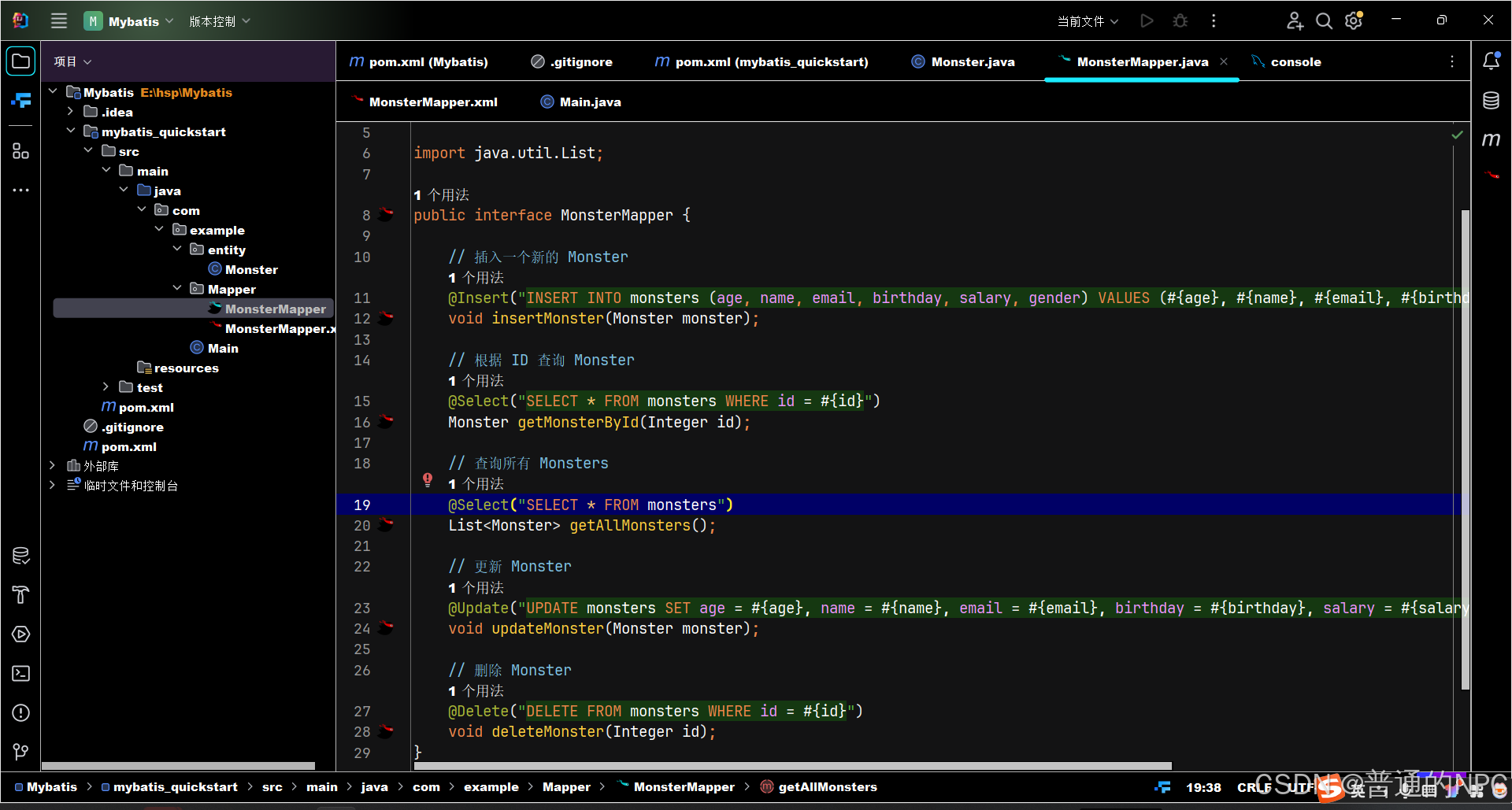
对应文件下面添加一个MonsterMapper.xml文件进行配置SQL语句:
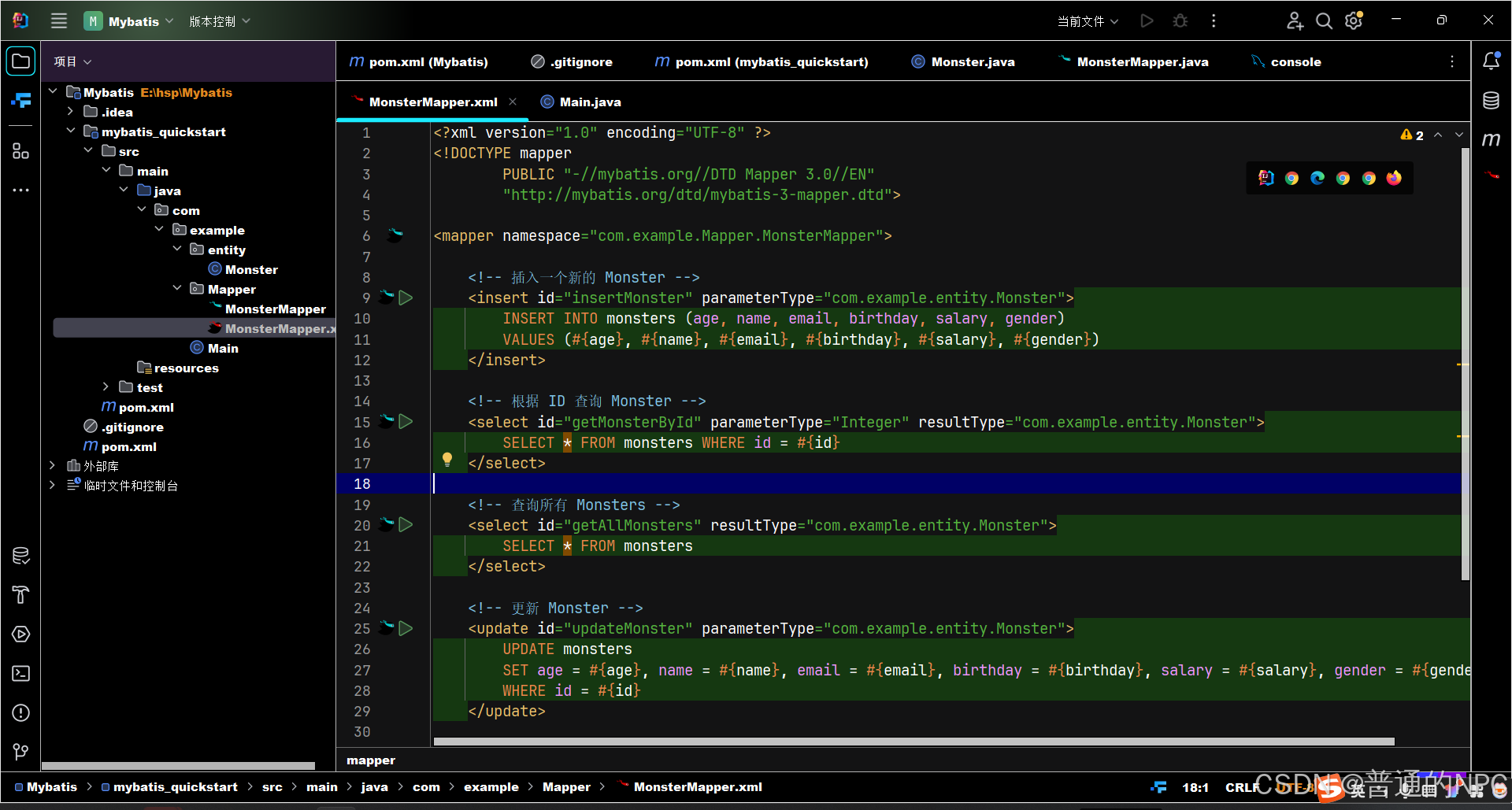 (9)利用我们上面提到的mybatis-config.xml文件去配置我们需要关联的XXMapper.xml文件:
(9)利用我们上面提到的mybatis-config.xml文件去配置我们需要关联的XXMapper.xml文件:
这里复制粘贴源路径的小技巧: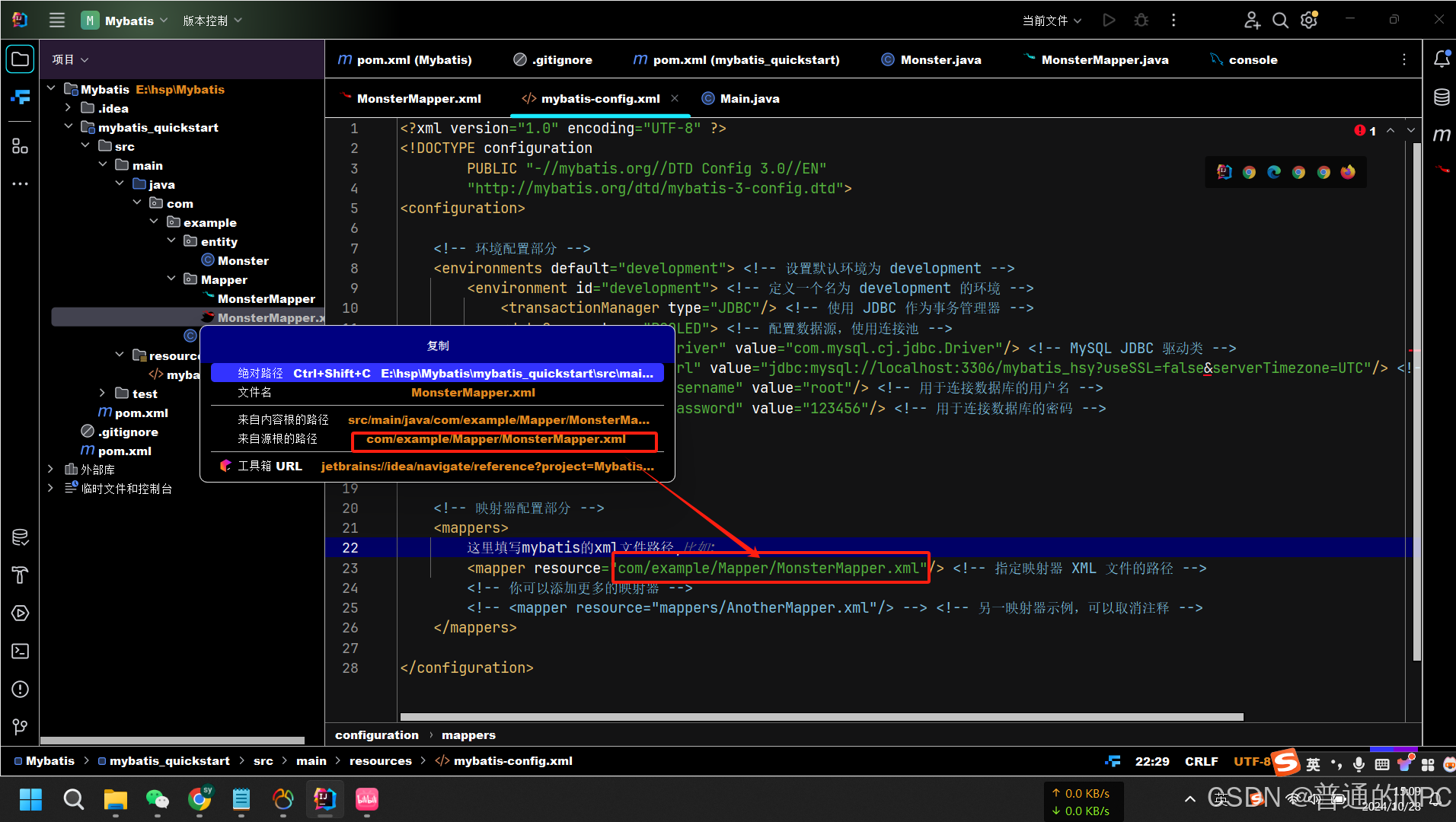
(10)创建连接工具类,java利用Mybatis操作DB,还需要获取 “连接”这个对象,只有获取连接之后,才可以操作对应的Mapper接口进行增删改查,这个获取连接的过程代码比较固定,通常我们写在一个工具类里面: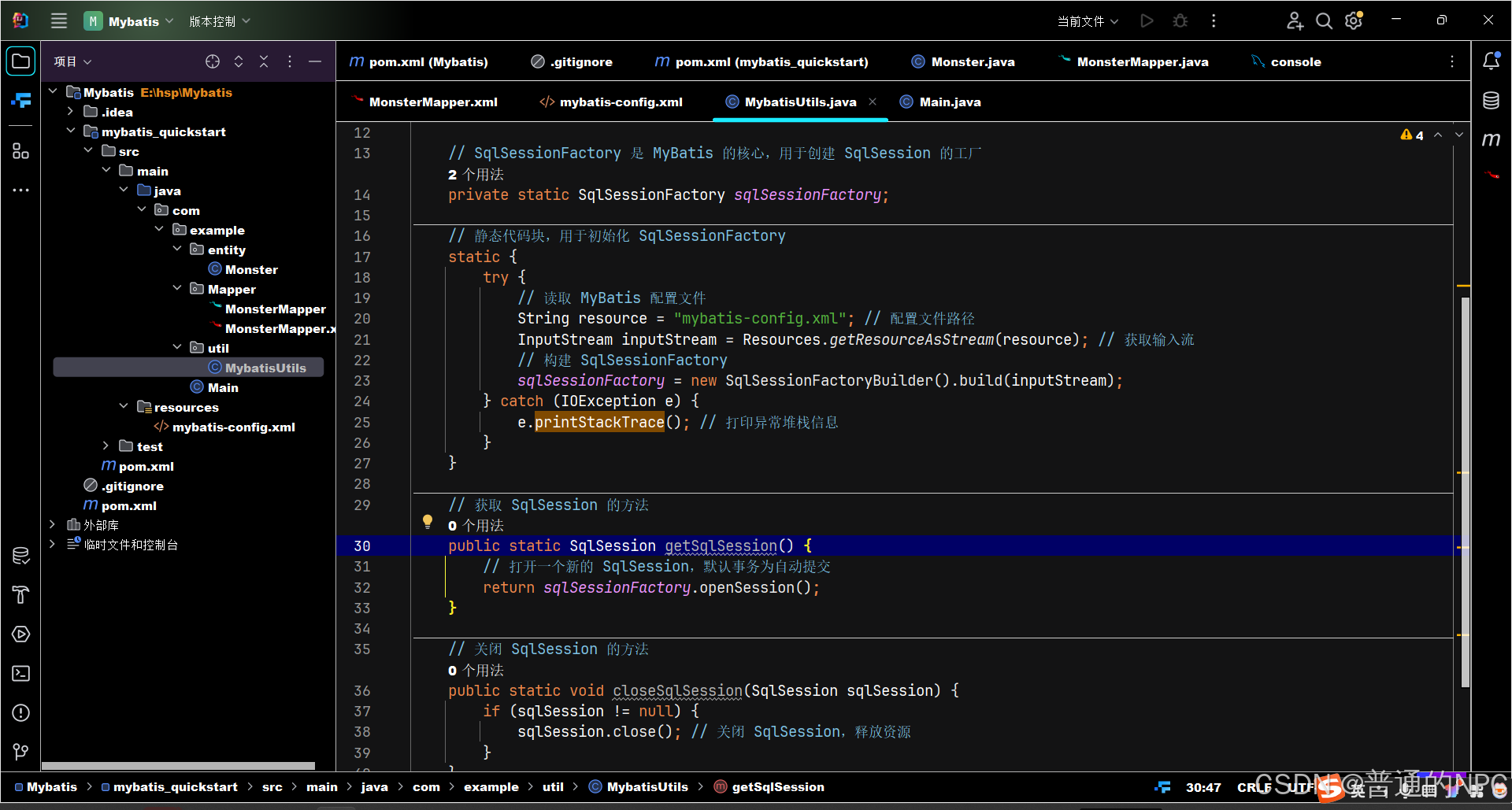
(11) 我这个没有安装标准的Mapper放到Resource目录下面,为了防止报错,手动配置扫描的文件加载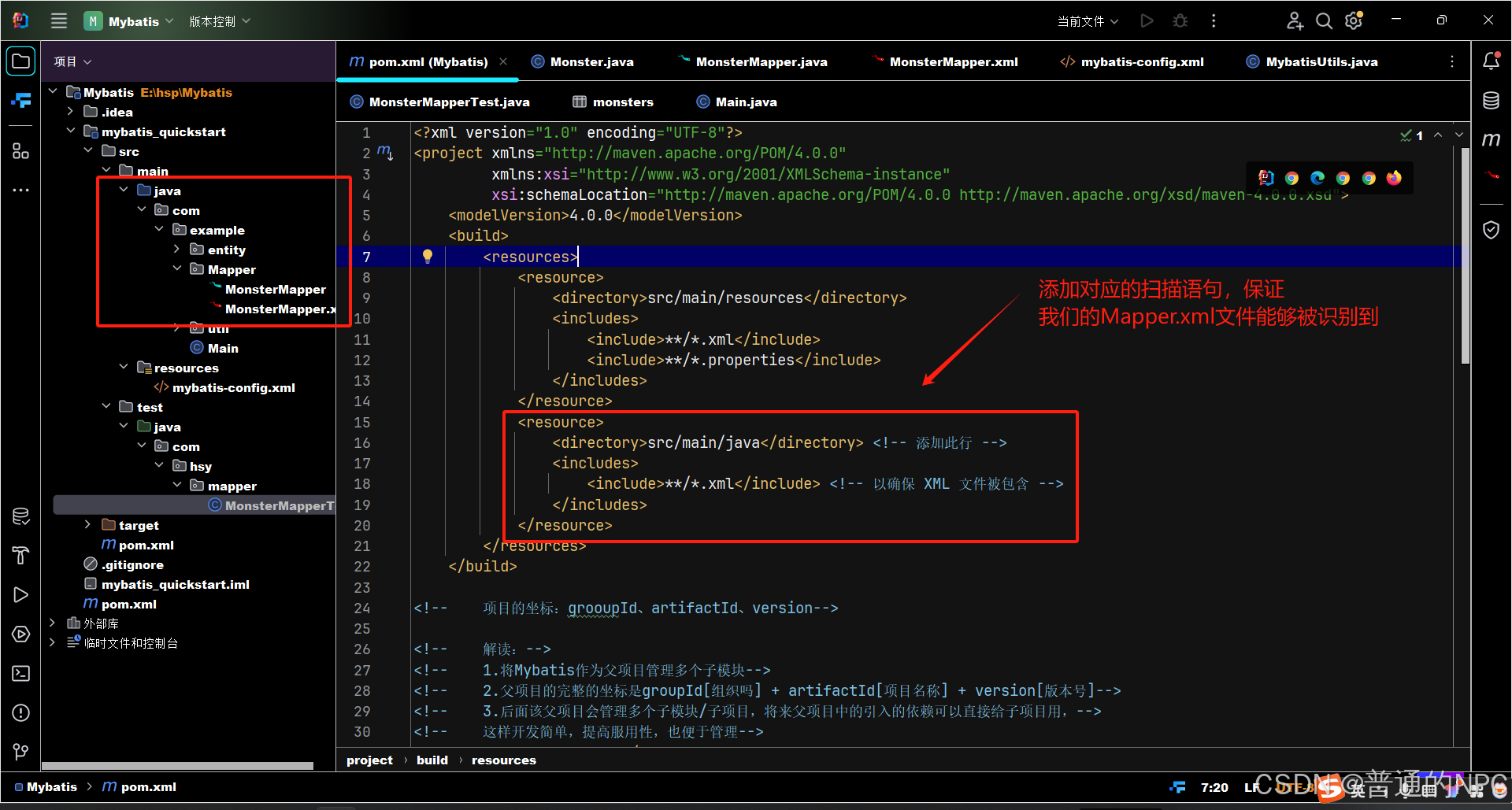
进行插入操作: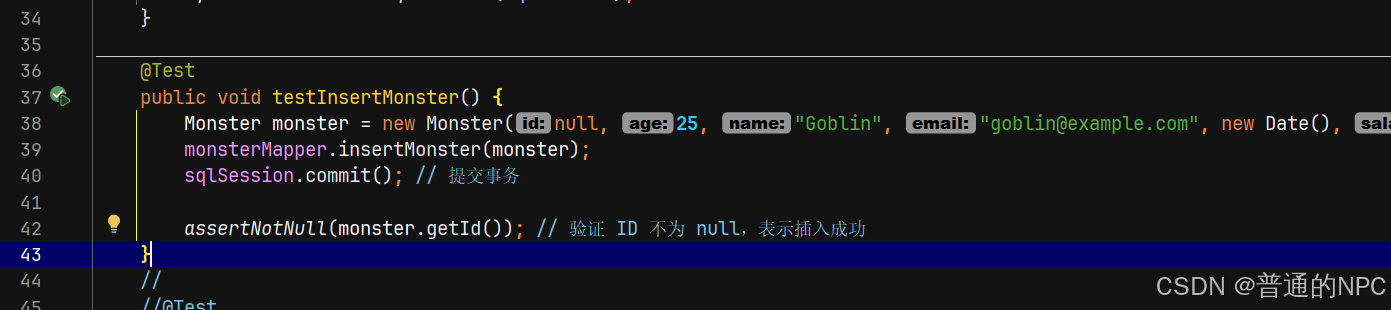
,这里提示:注解和xml文件不能同时使用,否则会报错!
我们用了这个方法assertNotNull,所以SQL语句我们需要回填用户的主键id,
数据库里面也有对应的数据了:
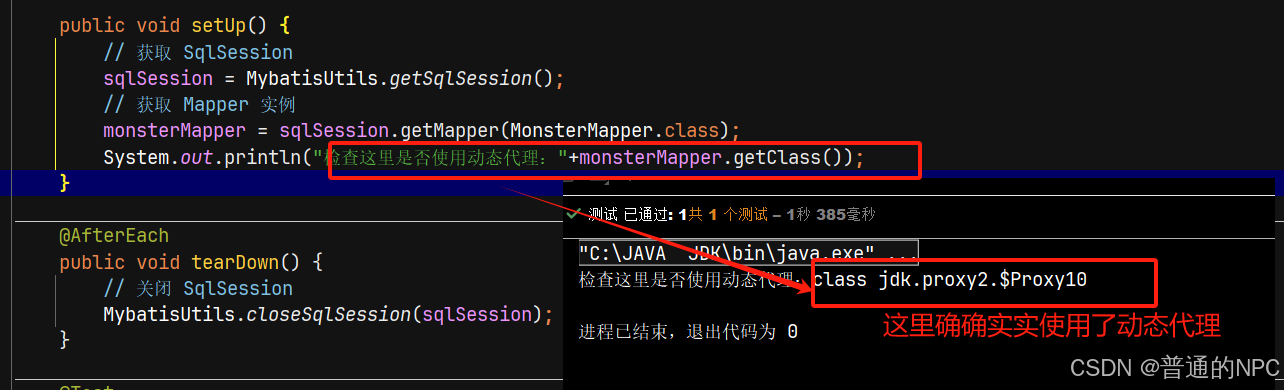
发现:我们使用
monsterMapper = sqlSession.getMapper(MonsterMapper.class);使用了动态代理底层
(12)进行日志的配置:
(13)Mybatis原生API记忆留痕:Mybatis提供利用sqlsession来进行增删改查:类似于
SqlSession sqlSession = MybatisUtils.getSqlSession();
Monster monster = new Monster(null, "Goblin", "goblin@example.com", new Date(), 3000.00, 1);
sqlSession.insert("com.example.Mapper.MonsterMapper.insertMonster", monster);
sqlSession.commit(); // 提交事务
sqlSession.close();
Insert(,)逗号左边的形参可以近似理解成“mapper接口下,对应的方法名字” ,逗号右边则是形参对象。,其余的删改查操作也是类似,只是留一个记忆痕迹。
(14)采用注解的方式操作SQL: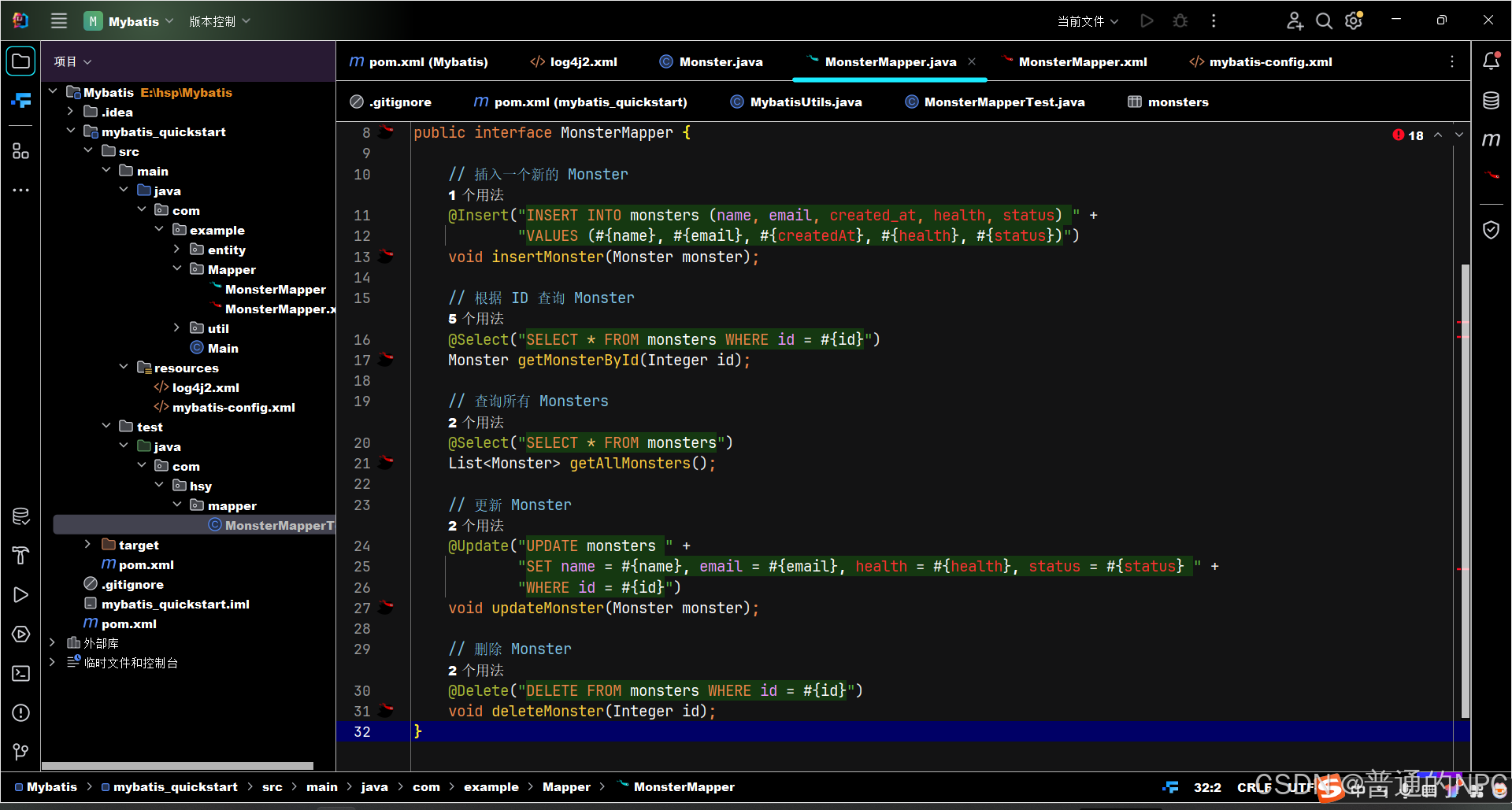
(15)mybatis-config.xml-配置文件详解:
1.引入外部配置文件:
修改配置时无需重新打包应用程序,只需更新外部文件即可,类似于把一个静态参数本质变成一个引用,然后那个引用的实际值就行。
db.url=jdbc:mysql://localhost:3306/mybatis_hsp?useSSL=false&serverTimezone=UTC
db.username=root
db.password=123456
我们需要用到这个外部配置文件里面的key-value值,所以需要在我们用的mybatis-config.xml文件里面引入这个property文件,然后直接${key.value}进行取值就行:
<configuration>
<properties resource="db.properties"/> <!-- 引用外部属性文件 -->
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="${db.url}"/>
<property name="username" value="${db.username}"/>
<property name="password" value="${db.password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="com/example/Mapper/MonsterMapper.xml"/>
</mappers>
</configuration>
注意:通常不需要在 pom.xml 中进行特别的配置来识别 .properties 文件,只要文件放在 src/main/resources 目录下,Maven 默认会处理它。但是如果我们放的properties文件没有放到和这个默认目录下,则必须手动添加扫描这些不是默认位置的properties文件或者xml文件例如:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<build>
<resources>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.xml</include>
<include>**/*.properties</include>
</includes>
</resource>
<resource>
<directory>src/main/java</directory> <!-- 添加此行 -->
<includes>
<include>**/*.xml</include> <!-- 以确保 XML 文件被包含 -->
</includes>
</resource>
</resources>
</build>
2.settings全局参数定义:
2.1. cacheEnabled
- 描述:是否启用二级缓存。
- 默认值:
true - 示例:
<setting name="cacheEnabled" value="true"/>
2.2. lazyLoadingEnabled
- 描述:是否启用懒加载。懒加载会在实际需要数据时才从数据库中加载。
- 默认值:
false - 示例:
<setting name="lazyLoadingEnabled" value="true"/>
2.3. multipleResultSetsEnabled
- 描述:是否允许返回多个结果集。
- 默认值:
true - 示例:
<setting name="multipleResultSetsEnabled" value="true"/>
2.4. useGeneratedKeys
- 描述:是否使用 JDBC 的自动生成键功能。
- 默认值:
false - 示例:
<setting name="useGeneratedKeys" value="true"/>
2.5. defaultExecutorType
- 描述:默认的执行器类型,可以是
SIMPLE、REUSE或BATCH。SIMPLE:每次执行都创建新的 Statement。REUSE:重用已创建的 Statement。BATCH:批量处理。
- 默认值:
SIMPLE - 示例:
<setting name="defaultExecutorType" value="REUSE"/>
2.6. mapUnderscoreToCamelCase
- 描述:将数据库中的下划线命名(如
first_name)映射为驼峰命名(如firstName)。 - 默认值:
false - 示例:
<setting name="mapUnderscoreToCamelCase" value="true"/>
2.7. safeRowBoundsEnabled
- 描述:是否在 RowBounds 中启用安全模式,以防止超出结果集的限制。
- 默认值:
false - 示例:
<setting name="safeRowBoundsEnabled" value="true"/>
2.8完整 示例配置
以下是一个完整的 mybatis-config.xml 示例,展示了如何使用 <settings> 来定义全局参数:
<configuration>
<settings>
<setting name="cacheEnabled" value="true"/>
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="multipleResultSetsEnabled" value="true"/>
<setting name="useGeneratedKeys" value="true"/>
<setting name="defaultExecutorType" value="REUSE"/>
<setting name="mapUnderscoreToCamelCase" value="true"/>
<setting name="safeRowBoundsEnabled" value="true"/>
</settings>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis_hsp?useSSL=false&serverTimezone=UTC"/>
<property name="username" value="root"/>
<property name="password" value="123456"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="com/example/Mapper/MonsterMapper.xml"/>
</mappers>
</configuration>
3.typeAliases 别名处理器
3.1 类的别名:
<typeAliases>
<typeAlias alias="Monster" type="com.example.entity.Monster"/>
<typeAlias alias="User" type="com.example.entity.User"/>
</typeAliases>
3.2 包的别名:<typeAliases> 中指定了一个包名,那么 MyBatis 会为该包下的每个类生成别名,别名为类名的简化形式
<typeAliases>
<package name="com.example.entity"/>
</typeAliases>
4.typeHandlers 类型处理器:
介绍:<typeHandlers> 标签用于定义类型处理器(Type Handlers),它们负责在 Java 数据类型和数据库数据类型之间进行转换。类型处理器提供了一种机制,将数据库中的数据类型映射到 Java 中的相应类型,以及反向转换。
MyBatis 提供了一些默认的类型处理器,支持常见的数据类型映射。例如:
String->VARCHAR/CHARint->INTEGERDate->DATETIME/TIMESTAMPboolean->BIT
当然还有自定义的类型处理器,这里不多介绍留一个记忆留痕就够了。
5.environments 环境标签
5.1. environment
- id:每个环境的标识符,例如
development、production等。可以在应用程序中根据需要选择不同的环境。
5.2. transactionManager
- type:指定事务管理器的类型,常用的类型包括:
JDBC:使用 JDBC 进行事务管理。MANAGED:使用容器管理的事务。
5.3. dataSource
-
type:指定数据源的类型,常用的数据源类型包括:
POOLED:使用连接池。UNPOOLED:不使用连接池,每次请求都创建新的连接。JNDI:通过 JNDI 查找数据源。
-
property:用于配置连接的详细信息,如数据库驱动、URL、用户名和密码。
5.4. 使用示例在 MyBatis 中使用环境配置的一个实际示例:
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis_hsp?useSSL=false&serverTimezone=UTC"/>
<property name="username" value="root"/>
<property name="password" value="123456"/>
</dataSource>
</environment>
<environment id="production">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://prod-db-server:3306/mybatis_hsp"/>
<property name="username" value="prod_user"/>
<property name="password" value="prod_password"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="com/example/Mapper/MonsterMapper.xml"/>
</mappers>
</configuration>
5.5. 总结
<environments>标签允许定义多个数据库连接环境,便于在不同环境间切换。- 每个环境可以独立配置事务管理器和数据源,支持灵活的数据库连接管理。
- 通过设置默认环境,可以简化开发和测试流程,确保在不同环境下能够正确连接到数据库。
(16)xml文件映射器:
16.1.parameterType = map
正常我们的 parameterType = "目标对象的全类路径", 但是当 SQL 语句需要多个参数时,可以使用 Map 来方便地传递。这种方式特别适合于动态查询和不定数量参数的情况。
16.1.1 Mapper 接口
public interface UserMapper {
User selectUser(Map<String, Object> params);
}
16.1.2 XML 映射文件
这里我们的#{id} 和 #{name}一定要知道 就是我们传进来的map集合里面的 key的名字,
#{}操作就是取出来那个Key的值
<mapper namespace="com.example.mapper.UserMapper">
<select id="selectUser" parameterType="map" resultType="com.example.entity.User">
SELECT * FROM users WHERE id = #{id} AND name = #{name}
</select>
</mapper>
16.1.3 调用示例
在调用该方法时,可以创建一个 Map,将所需参数放入其中:
Map<String, Object> params = new HashMap<>();
params.put("id", 1);
params.put("name", "John Doe");
User user = userMapper.selectUser(params);
16.1.4补充:
-
参数传入:您可以将参数以
Map的形式传入 SQL 查询。这要求您在映射文件中指定parameterType="map"。 -
返回结果:
- 返回为 Map:如果您将
resultType设置为map,那么查询结果将以Map的形式返回,其中键是数据库列名,值是相应的列值。 - 返回为 Java 对象:如果您将
resultType指定为某个 Java 类(例如com.example.entity.User),那么查询结果将会自动映射到该 Java 对象的属性中,前提是数据库列名与 Java 对象属性名一致(或通过使用ResultMap进行映射)。
- 返回为 Map:如果您将
返回的是Map:
Map<String, Object> userMap = userMapper.selectUser(params);
System.out.println("User ID: " + userMap.get("id"));
System.out.println("User Name: " + userMap.get("name"));
返回的是java对象:
User user = userMapper.selectUserAsObject(params);
System.out.println("User ID: " + user.getId());
System.out.println("User Name: " + user.getName());
16.2: ResultMap:
16.2.1:我们的SQL语句默认的参数使用的是:resultType = java对象,但是这样的前提是 实体类的属性和数据库表里面的属性 ,字段名是一样的,如果出现不一样,我们就需要手动设置映射关系了,就引入 ResultMap
<mapper namespace="com.example.mapper.UserMapper">
<resultMap id="userResultMap" type="com.example.entity.User">
<id property="id" column="user_id"/>
<result property="name" column="user_name"/>
<result property="email" column="user_email"/>
</resultMap>
<select id="selectUser" resultMap="userResultMap">
SELECT user_id, user_name, user_email FROM users WHERE user_id = #{id}
</select>
</mapper>
代码注释:我们SQL语句原来使用是 resultType, 但是手动设置映射的时候,就不用这个属性了,就得用 resultMap = "上面的 resultMap 标签里面的id 字段“。
16.2.2:除了使用ResultMap进行映射,我们这里还可以使用别名进行映射,只是这个映射只适用于简单的语句:
<select id="selectUser" parameterType="int" resultType="com.example.entity.User">
SELECT user_id AS id, user_name AS name, user_email AS email
FROM users WHERE user_id = #{id}
</select>
如果是MyBatis-Plus 处理就比较简单,可以使用 注解@TableField 来解决实体字段名和表字段名不-致的问题,还可以使用@TableName来解决 实体类名和表名不一致的问题
16.3 动态 SQL 标签
动态 SQL 标签在 MyBatis 中用于根据不同条件动态生成 SQL 语句,增强了 SQL 的灵活性和可维护性。以下是一些常用的动态 SQL 标签的介绍。
16.3.1: <if>
功能:根据条件判断是否生成某个 SQL 片段。
<select id="selectUser" resultType="com.example.entity.User">
SELECT * FROM users
WHERE 1=1
<if test="name != null">
AND user_name = #{name}
</if>
<if test="email != null">
AND user_email = #{email}
</if>
</select>
代码注释:在查询中,只有当 name 或 email 不为 null 时,相关的条件才会被添加到 SQL 语句中。
16.3.2: <choose>、<when> 和 <otherwise>
功能:类似于 Java 的 switch-case 语句,选择一个条件来生成 SQL 片段。
<choose>
<when test="condition1">
SQL 片段1
</when>
<when test="condition2">
SQL 片段2
</when>
<otherwise>
SQL 片段3
</otherwise>
</choose>
<select id="selectUserByType" resultType="com.example.entity.User">
SELECT * FROM users
<where>
<choose>
<when test="type == 'admin'">
WHERE role = 'admin'
</when>
<when test="type == 'user'">
WHERE role = 'user'
</when>
<otherwise>
WHERE role IS NULL
</otherwise>
</choose>
</where>
</select>
代码注释:根据不同的用户类型,动态选择查询条件。
16.3.3: <foreach>
功能:用于遍历集合,生成 SQL 片段,通常用于 IN 子句。
<select id="selectUsersByIds" resultType="com.example.entity.User">
SELECT * FROM users
WHERE user_id IN
<foreach collection="userIds" item="id" open="(" separator="," close=")">
#{id}
</foreach>
</select>
代码注释:通过遍历 userIds 集合,动态生成 IN 子句。
16.3.4: <set>
功能:用于动态构建 UPDATE 语句中的 SET 子句。
<update id="updateUser">
UPDATE users
<set>
<if test="name != null">user_name = #{name},</if>
<if test="email != null">user_email = #{email},</if>
</set>
WHERE user_id = #{id}
</update>
代码注释:在更新操作中,只有当字段不为 null 时,相关的 SET 语句才会被添加。
16.3.5: <where>
功能:自动处理 WHERE 子句的逻辑,去除多余的 AND 或 OR。
<select id="selectUsers" resultType="com.example.entity.User">
SELECT * FROM users
<where>
<if test="name != null">AND user_name = #{name}</if>
<if test="email != null">AND user_email = #{email}</if>
</where>
</select>
代码注释:使用 <where> 标签可以自动处理 SQL 的逻辑,避免手动添加的多余的 AND。
动态SQL总结:
动态 SQL 标签为 MyBatis 提供了灵活的 SQL 生成能力,根据条件动态构建 SQL 语句。使用这些标签可以有效处理复杂的查询和更新操作
16.4 xml文件里面的一对一映射语句:
16.4.1: 一对一映射的基本结构,没有外键依旧可以做级联映射
一对一映射的基本结构在 XML 映射文件中使用 <resultMap> 标签定义。
<mapper namespace="com.example.mapper.OutpatientMapper">
<resultMap id="outpatientResultMap" type="com.example.entity.Outpatient">
<id property="id" column="outpatient_id"/>
<result property="name" column="outpatient_name"/>
<association property="doctor" column="outpatient_id"
select="com.example.mapper.DoctorMapper.selectDoctorByOutpatientId"
javaType="com.example.entity.Doctor"/>
</resultMap>
<select id="selectOutpatient" resultMap="outpatientResultMap">
SELECT outpatient_id, outpatient_name FROM outpatient WHERE outpatient_id = #{id}
</select>
</mapper>
解释:
<resultMap>标签:定义了Outpatient类与outpatient表的映射关系。<id>标签:映射主键属性,property指向 Java 对象的属性,column指向数据库表的列。<result>标签:映射其他属性,确保数据库字段能够正确赋值给 Java 对象的属性。<association>标签:用于定义一对一关系,表示Outpatient类中的doctor属性与Doctor表的关系。通过select属性指定查询方法,MyBatis 会根据外键outpatient_id加载医生信息。直接记住:这个标签用来定义外键的映射的
16.4.2: 使用 select 属性
在 <association> 标签中,select 属性用于指定一个 SQL 查询方法,以便在加载主对象时自动获取关联的子对象。
<association property="doctor" column="outpatient_id"
select="com.example.mapper.DoctorMapper.selectDoctorByOutpatientId"
javaType="com.example.entity.Doctor"/>
解释:
property: 指向主对象中的属性(doctor),表示与医生的关联。column: 通常是外键,指向主对象的属性(在这里是outpatient_id)。select: 指定了查询医生信息的方法,MyBatis 会使用这个方法来获取与该门诊关联的医生对象。javaType: 指定从对象的类型为Doctor,确保在加载时能够正确实例化。
16.4.3:补充:如果是一对一的关系,通常我们都会把 实体类对象当成 属性放到 另外一个类里面,如果 是1对多关系,我们通常是将 一个类的主键放到另外一个类里面当外键。
16.4.4:上面这种使用 <association> 标签就是当场写,就在那个ResultMap里面使用,还有一种可以用ResultMap的id关联复用的,其实本质就是上面那种,只是把那部分代码提出来了:
<resultMap id="userDetailsResultMap" type="com.example.UserDetails">
<result property="address" column="address"/>
<result property="phone" column="phone"/>
</resultMap>
<resultMap id="userResultMap" type="com.example.User">
<id property="id" column="user_id"/>
<result property="name" column="user_name"/>
<association property="userDetails" resultMap="userDetailsResultMap" column="user_id"
select="com.example.mapper.UserDetailsMapper.selectUserDetailsByUserId"/>
</resultMap>
16.5: 注解一对一映射
在 MyBatis 中,采用注解方式实现一对一映射相对直观且简洁。通过注解,您可以直接在 Mapper 接口中定义数据库查询和对象映射关系。以下是关于如何使用注解实现一对一映射的详细介绍。
16.5.1: 一对一映射的基本结构
在一对一映射中,通常涉及两个实体类,例如 Clinic(门诊)和 Doctor(医生)。一个门诊对应一个医生。
public class Clinic {
private Long id; // 门诊 ID
private String name; // 门诊名称
private Doctor doctor; // 一对一关系,门诊对应一个医生
// Getters and Setters
}
public class Doctor {
private Long id; // 医生 ID
private String name; // 医生姓名
// Getters and Setters
}
Mapper 接口:
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.One;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Result;
import org.apache.ibatis.annotations.Results;
import org.apache.ibatis.annotations.Select;
@Mapper
public interface ClinicMapper {
@Select("SELECT * FROM clinics WHERE id = #{id}")
@Results({
@Result(property = "id", column = "id"),
@Result(property = "name", column = "name"),
@Result(property = "doctor",
one = @One(select = "com.example.mapper.DoctorMapper.findById",
column = "doctor_id"))
})
Clinic findClinicWithDoctor(@Param("id") Long id);
}
16.5.2: 使用 @Results 和 @Result
在上面的例子中,@Results 注解用于定义查询结果如何映射到 Clinic 对象的属性。
@Result(property = "doctor", one = @One(...)):property指定了Clinic类中的属性(doctor),表示与Doctor的关联。one = @One(...)表示这是一个一对一的关系,使用@One注解指定了关联的查询方法。select属性指定了查询医生信息的方法,column属性指向Clinic表中的外键(如doctor_id)。
16.5.3:补充:这种注解一对一的映射其实和xml文件里面的格式基本上一模一样,对比着记忆即可,只是换一种方式表达,建议使用xml文件的形式。
16.6:映射关系多对一
16.6.1单向的多对一或者是一对多与之前的一对一的语法没什么区别,我个人感觉都是完全一样的
@Mapper
public interface ClinicMapper {
@Select("SELECT * FROM clinics WHERE id = #{id}")
@Results({
@Result(property = "id", column = "id"),
@Result(property = "name", column = "name"),
@Result(property = "doctor",
one = @One(select = "com.example.mapper.DoctorMapper.findById",
column = "doctor_id")) // 一对一
})
Clinic findClinicWithDoctor(@Param("id") Long id);
}
xml文件:
<resultMap id="ClinicResultMap" type="com.example.model.Clinic">
<id property="id" column="id"/>
<result property="name" column="name"/>
<association property="doctor" javaType="com.example.model.Doctor"
column="doctor_id" select="com.example.mapper.DoctorMapper.findById"/> <!-- 一对一 -->
</resultMap>
<select id="findClinicWithDoctor" resultMap="ClinicResultMap">
SELECT * FROM clinics WHERE id = #{id}
</select>
16.6.2:多对一“双向”映射,当出现了对方集合类型的属性就一定要注意了。
16.5.4<association> 标签
- 用途:用来描述一对一或多对一的关系。
- 场景:
- 当一个对象(如
Clinic)中有一个对另一个对象(如Doctor)的引用时,使用<association>。 - 适用于对象之间的单一关联,即一个对象指向另一个对象的实例。
- 当一个对象(如
16.5.5. <collection> 标签
- 用途:用来描述一对多的关系。
- 场景:
- 当一个对象(如
Doctor)中包含一个对多个对象(如Clinic)的集合时,使用<collection>。 - 适用于对象之间的集合关系,即一个对象指向多个对象的实例
- 当一个对象(如
出现这种集合的类,它的XXXMapper.xml文件就需要使用collection 标签,而不是associon标签, 如果采用的是注解的形式:
如果采用的是注解的形式: 完整代码:
完整代码:
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import org.apache.ibatis.annotations.Result;
import org.apache.ibatis.annotations.Results;
import org.apache.ibatis.annotations.Many;
import java.util.List;
@Mapper
public interface DoctorMapper {
@Select("SELECT * FROM doctors WHERE id = #{id}")
@Results({
@Result(property = "id", column = "id"),
@Result(property = "name", column = "name"),
@Result(property = "clinics",
many = @Many(select = "com.example.mapper.ClinicMapper.findByDoctorId")) // 一对多
})
Doctor findById(@Param("id") Long id);
}
<mapper namespace="com.example.mapper.DoctorMapper">
<resultMap id="DoctorResultMap" type="com.example.model.Doctor">
<id property="id" column="id"/>
<result property="name" column="name"/>
<collection property="clinics" ofType="com.example.model.Clinic"
column="id" select="com.example.mapper.ClinicMapper.findByDoctorId"/>
</resultMap>
</mapper>
补充:双向的里面只是出现了集合属性的那个类使用many或者collection标签,比如上面的门诊和医生,医生类出现了,那么就它使用many或者collection标签,对于门诊类的配置语句或注解正常使用association和one
(17)一级缓存介绍:
17.1.1:一级缓存原理图:
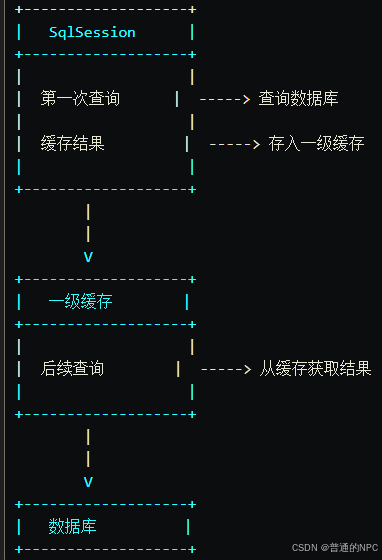
介绍:MyBatis 的一级缓存是 MyBatis 默认启用的缓存机制,它的作用是在同一个 SqlSession 中缓存查询结果,以提高查询性能
17.1.2:一级缓存的工作原理
- 第一次查询:当执行查询时,MyBatis 会将查询结果存入缓存中。
- 后续查询:如果在同一个 SqlSession 中再次执行相同的查询,MyBatis 会直接从缓存中返回结果,而不发起新的数据库查询。
17.1.3:一级缓存失效的情况
一级缓存会在以下情况下失效
-
SqlSession 关闭:当 SqlSession 被关闭时,缓存会被清空。下次创建新的 SqlSession 时会重新加载数据。
-
执行更新操作:如果对数据库执行了插入、更新或删除操作,所有相关的缓存内容会失效。这是因为数据的变化可能会影响到之前缓存的查询结果。
-
不同的 SqlSession:如果在不同的 SqlSession 中执行查询,缓存不会共享。因此,之前 SqlSession 中的缓存内容在新的 SqlSession 中不可用。
-
使用不同的查询参数:如果使用不同的参数执行相同的查询语句,MyBatis 会认为这是一个新的查询,因此会忽略缓存。
-
手动清空缓存:如果调用了
SqlSession.clearCache()方法,当前 SqlSession 的缓存会被清空。
17.1.4:一级缓存结构:

存储结构:一级缓存通常使用一个 HashMap 来存储查询结果。这个 HashMap 的键是 SQL 语句的唯一标识(通常是 SQL 语句和参数的组合),值是查询结果对象。
-
查询操作:
- 当执行查询时,MyBatis 首先会检查
SqlSession中的缓存(HashMap)。 - 如果缓存中存在相应的结果,则直接返回该结果。
- 如果缓存中不存在,则执行 SQL 查询,并将结果存入缓存。
- 当执行查询时,MyBatis 首先会检查
-
缓存失效:
- 当
SqlSession关闭时,缓存会被清空。 - 执行插入、更新或删除操作时,相关的缓存内容会失效。
- 手动调用
SqlSession.clearCache()方法会清空缓存。
- 当
(18)二级缓存:
18.1.1:二级缓存原理图:
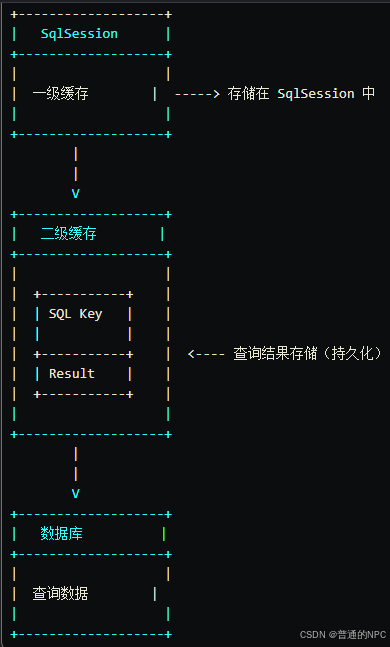
18.1.2:二级缓存的工作原理
-
一级缓存:
- 存储在当前
SqlSession中。 - 当执行查询时,首先检查一级缓存。如果命中,则直接返回结果。
- 存储在当前
-
二级缓存:
- 存储在会话工厂(
SqlSessionFactory)的范围内,可以被多个SqlSession共享。 - 当一级缓存未命中时,MyBatis 会查询二级缓存。
- 如果二级缓存中存在结果,则返回该结果;否则,执行数据库查询,并将结果存入二级缓存。
- 存储在会话工厂(
-
数据库:
- 如果二级缓存也没有结果,则最终查询数据库获取数据。
18.1.3:二级缓存特点:
- 共享:二级缓存可以被多个
SqlSession共享。 - 持久化:缓存的内容可以在不同的会话之间保持有效性,直到被清空或更新。
- 配置:需要在 MyBatis 配置文件中明确启用和设置二级缓存。
18.1.4:二级缓存失效的情况
- 数据更新:执行插入、更新或删除操作时,相关的缓存内容会失效。
- 手动清空缓存:调用
SqlSessionFactory.getConfiguration().getCache("namespace").clear();或使用clearCache()方法。 - 映射文件的变化:修改与缓存相关的映射文件(如 XML 配置文件)。
- 不同的查询参数:在同一 SQL 语句上使用不同的参数进行查询。
- 过期时间:设置了缓存的过期时间。
18.1.5:配置二级缓存
1.在 MyBatis 的 mybatis-config.xml 配置文件中,您需要启用二级缓存。可以使用以下属性::
<configuration>
<settings>
<setting name="cacheEnabled" value="true"/> <!-- 启用二级缓存 -->
</settings>
</configuration>
2. 为每个映射器启用缓存
在每个 Mapper 的 XML 文件中,您需要为特定的映射器启用缓存。使用 <cache> 标签来定义缓存设置。
<mapper namespace="com.example.mapper.YourMapper">
<cache /> <!-- 启用二级缓存 -->
<select id="findById" resultType="com.example.model.YourModel">
SELECT * FROM your_table WHERE id = #{id}
</select>
</mapper>
3. 自定义缓存
<cache type="org.mybatis.caches.ehcache.EhcacheCache" />
4. 使用注解方式
如果您使用注解方式定义 Mapper,可以通过在接口上使用 @CacheNamespace 注解来启用二级缓存:
import org.apache.ibatis.annotations.CacheNamespace;
import org.apache.ibatis.annotations.Mapper;
@Mapper
@CacheNamespace // 启用二级缓存
public interface YourMapper {
// 方法定义
}
5. 配置缓存实现
如果您使用第三方缓存实现(如 Ehcache),您需要在项目中包含相应的依赖,并在缓存配置文件中进行配置。
(18)开源 Java 缓存框架:Ehcache
18.1.1. 基本概念
- 缓存:Ehcache 允许将数据存储在内存中,以减少对数据库或其他持久化存储的访问频率。
- 存储类型:支持多种存储类型,包括内存(Heap)、磁盘(Disk)和分布式缓存。
18.1.2. 主要特性
- 灵活的缓存配置:可以通过 XML 文件或 Java API 进行配置,支持多种缓存策略。
- 多级缓存:支持内存与磁盘的组合缓存,允许将数据存储在内存中,同时也可以在磁盘上持久化数据。
- 淘汰策略:支持多种缓存淘汰策略,如 LRU(Least Recently Used)、LFU(Least Frequently Used)、FIFO(First In, First Out)等。
- 事务支持:可以与 Spring 和其他框架集成,实现事务级别的缓存。
- 分布式缓存:支持与其他分布式缓存的集成,如 Terracotta,以实现集群环境中的缓存共享。
18.1.3. 集成与使用
在 MyBatis 中,Ehcache 可以作为二级缓存的实现。以下是基本的集成步骤:
3.1. 添加依赖
使用 Maven,可以在 pom.xml 中添加 Ehcache 依赖
<dependency>
<groupId>net.sf.ehcache</groupId>
<artifactId>ehcache</artifactId>
<version>2.10.6</version> <!-- 请根据需要选择版本 -->
</dependency>
3.2. 配置 Ehcache
创建 ehcache.xml 配置文件,定义缓存策略和设置:
<ehcache>
<defaultCache
maxEntriesLocalHeap="1000"
eternal="false"
timeToIdleSeconds="120"
timeToLiveSeconds="300"
overflowToDisk="false" />
<cache name="exampleCache"
maxEntriesLocalHeap="10000"
eternal="false"
timeToIdleSeconds="300"
timeToLiveSeconds="600" />
</ehcache>

















 1587
1587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









