



 本文详细介绍了如何在Android应用中注册并获取百度地图API密钥,设置SHA1校验,配置开发包,添加权限,初始化地图,实现定位功能以及生命周期管理。适合iOS开发者快速入门Baidu Maps SDK。
本文详细介绍了如何在Android应用中注册并获取百度地图API密钥,设置SHA1校验,配置开发包,添加权限,初始化地图,实现定位功能以及生命周期管理。适合iOS开发者快速入门Baidu Maps SDK。
注册和获取密钥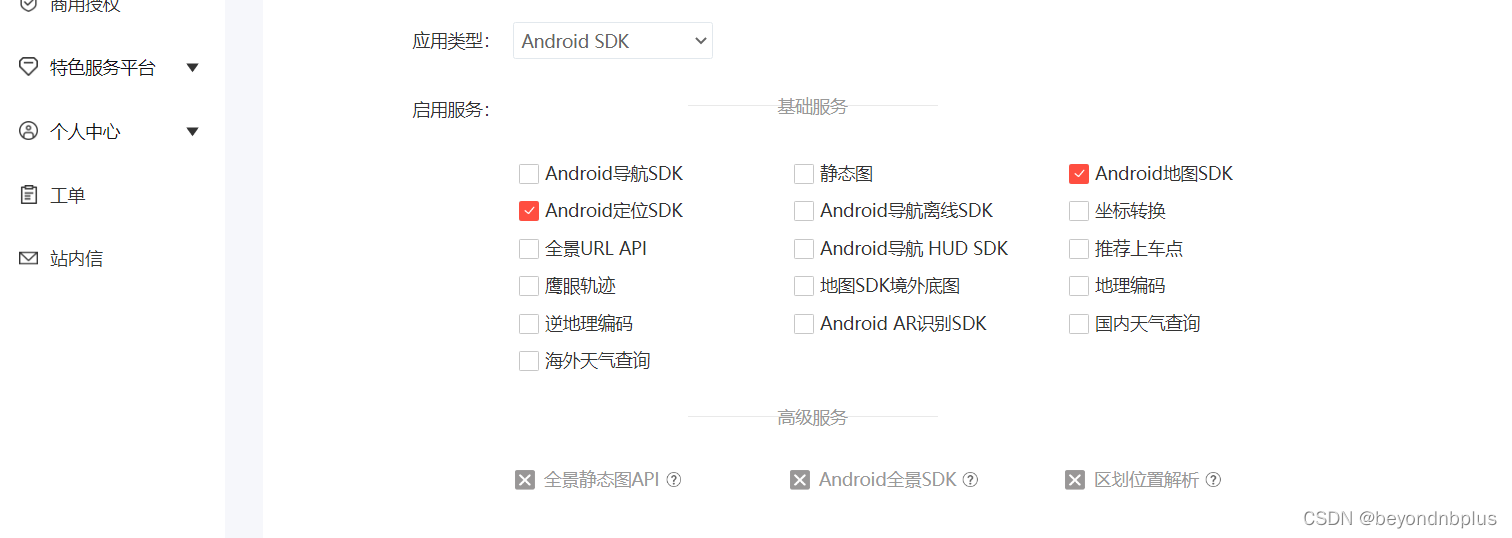
获取SHA1

包名
![]()
应用AK

2fH1CVufwzjs1gVUgXiQG6DlhX6qoXGX
下载开发包
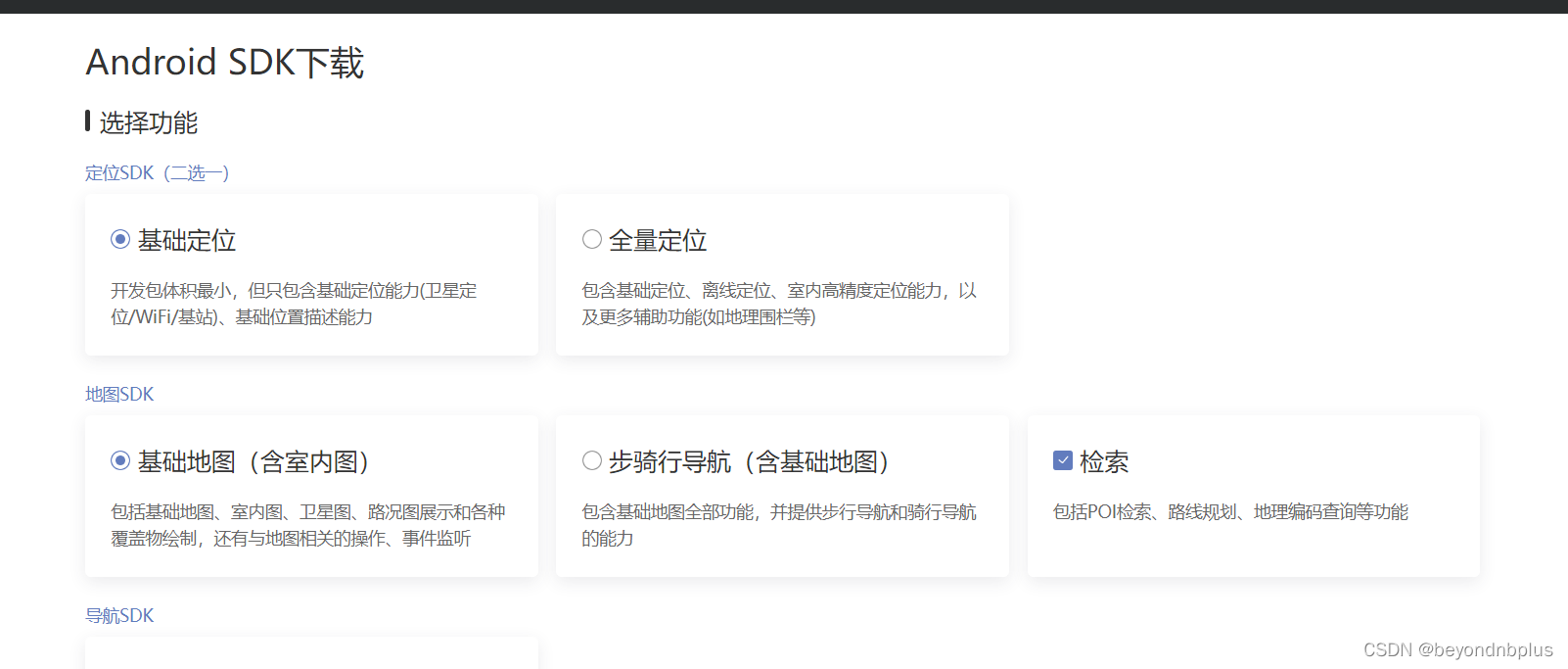
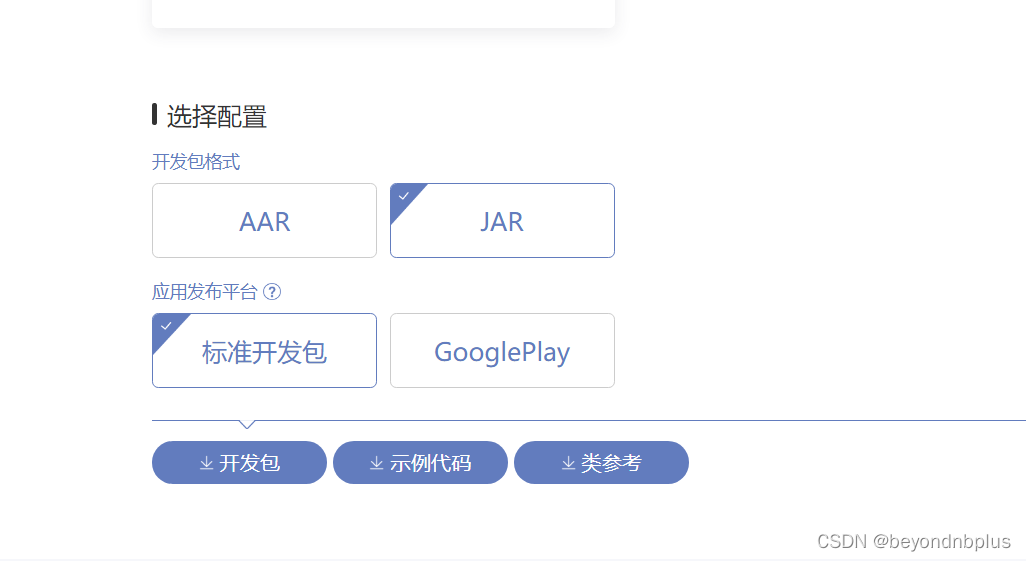 将开发包文件复制到app下面的libs文件中
将开发包文件复制到app下面的libs文件中
在<application>中加入如下代码配置开发密钥
<meta-data
android:name="com.baidu.lbsapi.API_KEY"
android:value="2fH1CVufwzjs1gVUgXiQG6DlhX6qoXGX" />设置权限
<!-- 访问网络,进行地图相关业务数据请求,包括地图数据,路线规划,POI检索等 -->
<uses-permission android:name="android.permission.INTERNET" />
<!-- 获取网络状态,根据网络状态切换进行数据请求网络转换 -->
<uses-permission android:name="android.permission.ACCESS_NETWORK_STATE" />
<!-- 读取外置存储。如果开发者使用了so动态加载功能并且把so文件放在了外置存储区域,则需要申请该权限,否则不需要 -->
<uses-permission android:name="android.permission.READ_EXTERNAL_STORAGE" />
<!-- 写外置存储。如果开发者使用了离线地图,并且数据写在外置存储区域,则需要申请该权限 -->
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE" />
<!-- 这个权限用于进行网络定位 -->
<uses-permission android:name="android.permission.ACCESS_COARSE_LOCATION" />
<!-- 这个权限用于访问GPS定位 -->
<uses-permission android:name="android.permission.ACCESS_FINE_LOCATION" />在Application标签中声明定位的service组件
<service android:name="com.baidu.location.f"
android:enabled="true"
android:process=":remote"/>地图初始化
package com.example.lbs;
import android.app.Application;
import com.baidu.mapapi.CoordType;
import com.baidu.mapapi.SDKInitializer;
public class MyLBS extends Application {
public void onCreate() {
super.onCreate();
//在使用SDK各组件之前初始化context信息,传入ApplicationContext
SDKInitializer.initialize(this);
//自4.3.0起,百度地图SDK所有接口均支持百度坐标和国测局坐标,用此方法设置您使用的坐标类型.
//包括BD09LL和GCJ02两种坐标,默认是BD09LL坐标。
SDKInitializer.setCoordType(CoordType.BD09LL);
}
}
构造地图数据
public class MyLocationListener extends BDAbstractLocationListener {
@Override
public void onReceiveLocation(BDLocation location) {
if (location == null || mapView == null){
return;
}
LatLng ll = new LatLng(location.getLatitude(), location.getLongitude());
if (isFirstLocate) {
isFirstLocate = false;
//给地图设置状态
baiduMap.animateMapStatus(MapStatusUpdateFactory.newLatLng(ll));
}
MyLocationData locData = new MyLocationData.Builder()
.accuracy(location.getRadius())
// 此处设置开发者获取到的方向信息,顺时针0-360
.direction(location.getDirection()).latitude(location.getLatitude())
.longitude(location.getLongitude()).build();
baiduMap.setMyLocationData(locData);
}
}通过LocationClient发起定位
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
mapView=findViewById(R.id.bmapView);
mapView.getMap().setMapType(BaiduMap.MAP_TYPE_SATELLITE);
baiduMap = mapView.getMap();
baiduMap.setMyLocationEnabled(true);
//定位初始化
locationClient = new LocationClient(this);
//通过LocationClientOption设置LocationClient相关参数
LocationClientOption option = new LocationClientOption();
option.setOpenGps(true); // 打开gps
option.setCoorType("bd09ll"); // 设置坐标类型
option.setScanSpan(1000);
//设置locationClientOption
locationClient.setLocOption(option);
//注册LocationListener监听器
MyLocationListener myLocationListener = new MyLocationListener();
locationClient.registerLocationListener(myLocationListener);
//开启地图定位图层
locationClient.start();
}各部分的生命周期
@Override
protected void onResume() {
mapView.onResume();
super.onResume();
}
@Override
protected void onPause() {
mapView.onPause();
super.onPause();
}
@Override
protected void onDestroy() {
locationClient.stop();
baiduMap.setMyLocationEnabled(false);
mapView.onDestroy();
mapView = null;
super.onDestroy();
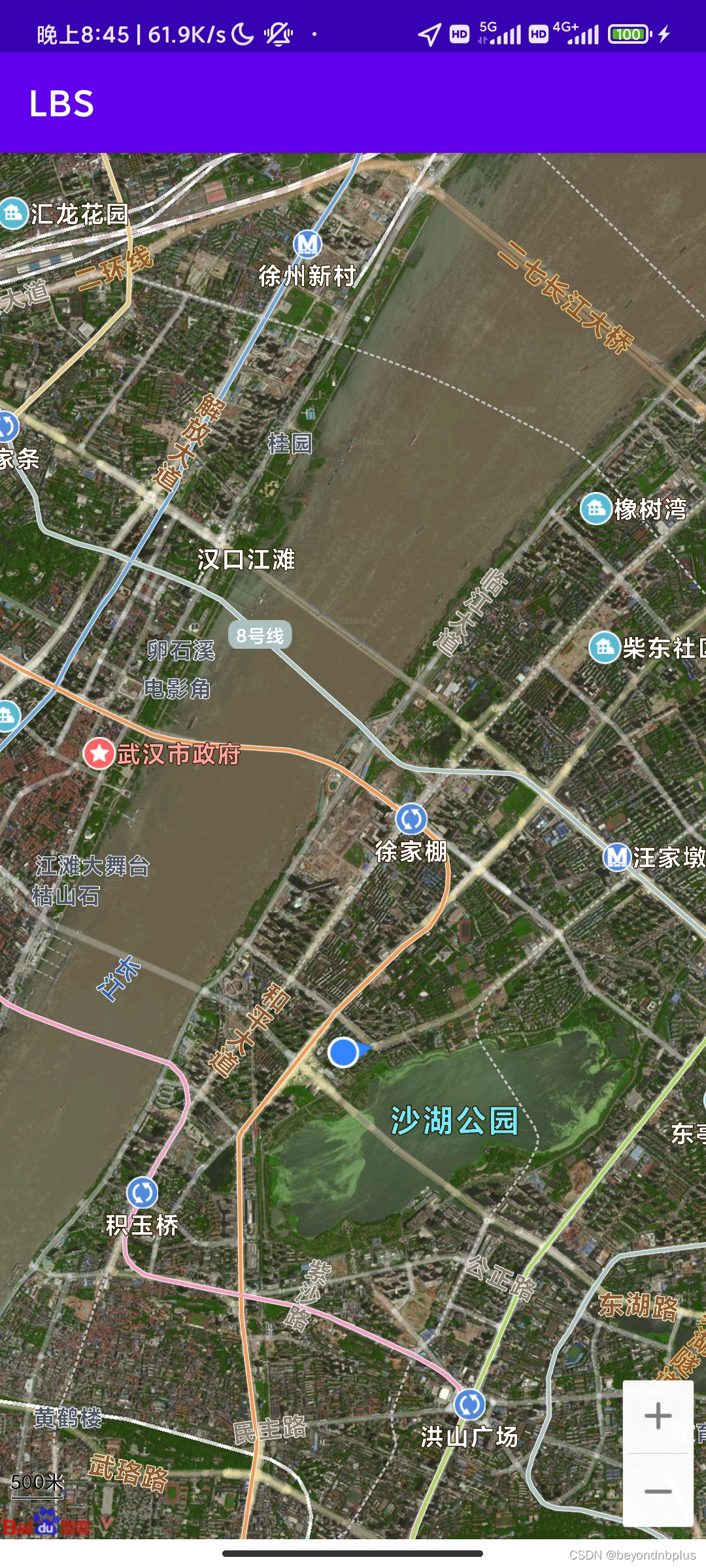
}在虚拟机上发现定位不在中国,应该是虚拟机的问题,于是将手机连接到电脑,使用手机发现定位正确
源码仓库地址

















 305
305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









