




 本文详细介绍了SQLAlchemy ORM框架的使用,包括如何创建连接、定义基类和实体类,以及如何进行数据操作如增加、查询、修改和删除。重点讲解了复杂查询的实现,如where条件、排序、分页、聚合方法和关联查询,并探讨了数据库状态管理和枚举字段的处理。
本文详细介绍了SQLAlchemy ORM框架的使用,包括如何创建连接、定义基类和实体类,以及如何进行数据操作如增加、查询、修改和删除。重点讲解了复杂查询的实现,如where条件、排序、分页、聚合方法和关联查询,并探讨了数据库状态管理和枚举字段的处理。
文章目录
1 ORM
Object-Relational Mapping,把关系数据库的表结构映射到对象上。使用面向对象的方式来操作数据库。
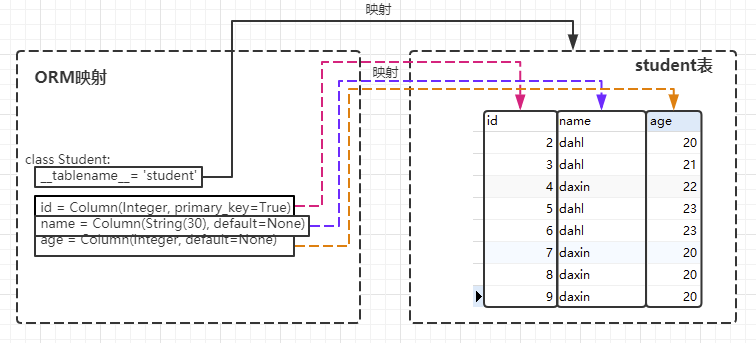
下面是一个关系模型与Python对象之间的映射关系:
- table --> class : 表映射为类
- row --> object : 行映射为实例
- column --> property : 字段映射为属性
2 sqlalchemy
SQLAlchemy是一个ORM框架。内部是使用了连接池来管理数据库连接。要使用sqlalchemy,那么需要先进行安装:
pip3 install sqlalchemy
查看版本
In [1]: import sqlalchemy
In [2]: print(sqlalchemy.__version__)
1.3.1
3 基本使用
先来总结一下使用sqlalchemy框架操作数据库的一般流程:
创建引擎(不同类型数据库使用不同的连接方式)创建基类(类对象要继承,因为基类会利用元编程为我们的子类绑定关于表的其他属性信息)创建实体类(用来对应数据库中的表)编写实体类属性(用来对应表中的字段/属性)创建表(如果表不存在,则需要执行语句在数据库中创建出对应的表)实例化(具体的一条record记录)创建会话session(用于执行sql语句的连接)使用会话执行SQL语句关闭会话
3.1 创建连接
sqlalchemy 使用引擎管理数据库连接(DATABASE URLS),连接的一般格式为:
dialect+driver://username:password@host:port/database
dialect:表示什么数据库(比如,mysql,sqlite,oracle等)driver:用于连接数据库的模块(比如pymysql,mysqldb等)username:连接数据库的用户名password:连接数据库的密码host: 数据库的主机地址port: 数据库的端口database: 要连接的数据库名称
pymysql模块是较长用于连接mysql的模块,使用pymysql的连接的语句为:
mysql+pymysql://dahl:123456@10.0.0.13:3306/test
创建引擎用于进行数据库的连接:create_engine(urls)
import sqlalchemy
db_url = 'mysql+pymysql://dahl:123456@10.0.0.13:3306/test'
engine = sqlalchemy.create_engine(db_url,echo=True)
- echo:引擎是否打印执行的sql语句,等于True时,表示打印,便于调试
特别注意:创建引擎并不会马上连接数据库,直到让数据库执行任务是才连接。
3.2 创建基类
使用: sqlalchemy.ext.declarative.declarative_base 来构造声明性类定义的基类。因为sqlalchemy内部大量使用了元编程,为实例化的子类注入映射所需的属性,所以我们定义的映射要继承自它(必须继承)
一般只需要一个这样的基类
Base = sqlalchemy.ext.declarative.declarative_base()
# 或者
from sqlalchemy.ext import declarative
Base = declarative.declarative_base()
3.3 创建实体类
现数据库存在如下表
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(30) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4;
创建对应的实体类:
import sqlalchemy
from sqlalchemy.ext import declarative
from sqlalchemy import Column, String, Integer
db_url = 'mysql+pymysql://dahl:123456@10.0.0.13:3306/test'
engine = sqlalchemy.create_engine(db_url, echo=True)
Base = declarative.declarative_base()
class Student(Base):
__tablename__ = 'student'
id = Column(Integer, primary_key=True, nullable=False, autoincrement=True)
name = Column(String, default='Null')
age = Column(Integer, default='Null')
print(Student.__dict__)
# Table('student', MetaData(bind=None), 这里没有绑定engine,所以是None
# Column('id', Integer(), table=<student>, primary_key=True, nullable=False),
# Column('name', String(), table=<student>, default=ColumnDefault('Null')),
# Column('age', Integer(), table=<student>, default=ColumnDefault('Null')), schema=None),
- __tablename__: 表明,如果表已存在,则必须指定正确的表名
- Column: 用于构建一个列对象,它的参数一般都和数据库中的列属性是对应的,主要有:
- name: 数据库中表示的此列的名称
type:字段类型(比如String、Integer,这里是sqlalchemy包装的类型,对应的是数据库的varchar、int等),来自TypeEngine的子类autoincrement:是否自增- default:默认值,可以是值,可调用对象或者类,当写入数据该字段没有指定时,调用。
- doc:字段说明信息
- key: 一个可选的字符串标识符,用于标识表上的此Column对象。
- index: 是否启用索引
nullable: 是否可以为空- onupdate: 如果在更新语句的SET子句中不存在此列,则将在更新时调用该值
primary_key: 主键- server_default:它的值是 FetchedValue实例、字符串、Unicode 或者 text()实例,用作DDL语句中该列的default值
注意:Column和String、Integer等都来自于sqlalchemy下的方法,要么直接导入,要么就使用sqlalchemy.String来引用。
3.4 实例化
通过我们构建的类,来实例化的对象,在将来就是数据库中的一条条记录。
student = Student()
student.name = 'daxin'
student.id = 1
student.age = 20
print(student) # <1 daxin 20>
3.5 创建表
我们自己写的类都是继承自Base,每继承一次Base类,在Base类的metadata属性中就会记录当前子类,metadata提供了方法用于删除/创建表。如果数据库中已经存在对应的表,那么将不会继续创建
- drop_all(bind=None, tables=None, checkfirst=True):删除metadata中记录的所有表
- create_all(bind=None, tables=None, checkfirst=True):创建metadata中记录的所有表
Base.metadata.create_all(bind=engine) # 需要通过引擎去执行
# 下面是engine的echo为true时的输出信息
# 2019-03-16 16:53:45,922 INFO sqlalchemy.engine.base.Engine
# CREATE TABLE hello (
# id INTEGER NOT NULL AUTO_INCREMENT,
# name VARCHAR(24),
# age INTEGER,
# PRIMARY KEY (id)
# )
#
#
# 2019-03-16 16:53:45,922 INFO sqlalchemy.engine.base.Engine {}
# 2019-03-16 16:53:45,926 INFO sqlalchemy.engine.base.Engine COMMIT
# 2019-03-16 16:53:45,927 INFO sqlalchemy.engine.base.Engine
# CREATE TABLE world (
# id INTEGER NOT NULL AUTO_INCREMENT,
# name VARCHAR(24),
# age INTEGER,
# PRIMARY KEY (id)
# )
#
#
# 2019-03-16 16:53:45,927 INFO sqlalchemy.engine.base.Engine {}
# 2019-03-16 16:53:45,928 INFO sqlalchemy.engine.base.Engine COMMIT
- 生产环境很少这样创建表,都是系统上线的时候由脚本生成。
- 生产环境很少删除表,宁可废除都不能删除。
3.6 创建会话Session
在一个会话中操作数据库,绘画建立在连接上,连接被引擎管理,当第一次使用数据库时,从引擎维护的连接池中取出一个连接使用。
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
session = Session() # 实例化一个session对象
- session对象线程不安全。所以不同线程应该使用不同的session对象
- Session类和engine有一个就行了。
scoped_session是sqlalchemy提供的线程安全的session,利用的是ThreadLocal实现的。
3.7 数据操作
3.7.1 增加数据
| 方法 | 含义 |
|---|---|
| add() | 增加一个对象 |
| add_all() | 增加多个对象,类型为可迭代 |
import sqlalchemy
from sqlalchemy.ext import declarative
from sqlalchemy import Column, String, Integer
from sqlalchemy.orm import sessionmaker
db_url = 'mysql+pymysql://dahl:123456@10.0.0.13:3306/test'
engine = sqlalchemy.create_engine(db_url, echo=True)
Base = declarative.declarative_base()
DBSession = sessionmaker(bind=engine)
session = DBSession()
class Student(Base):
__tablename__ = 'student'
id = Column(Integer, primary_key=True, nullable=False, autoincrement=True)
name = Column(String(24), default='Null')
age = Column(Integer, default='Null')
def __repr__(self):
return '<{} {} {}>'.format(
self.id, self.name, self.age
)
daxin = Student(id=12, name='daxin', age=20)
session.add(daxin)
dachenzi = Student(id=13,name='dachenzi', age=21)
xiaobai = Student(id=14,name='xiaobai', age=22)
session.add_all((dachenzi,xiaobai))  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1109
1109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









