 OpenAI函数调用机制详解
OpenAI函数调用机制详解







文章目录
1、OpenAI 可以在提示词中调用函数吗?
答案是:不能直接在提示词中像调用函数一样执行代码。
但是,OpenAI 提供了更强大、更结构化的方式来实现类似“调用函数”的功能,这主要通过 Function Calling 机制来实现。
2、常见的误解:在提示词中“调用函数”
很多用户会尝试这样写提示词,但这是无效的:
错误示例:
“请总结以下文章的主要内容,然后 calculate_read_time(article_text)计算阅读时间。”
AI 模型会把你写的 calculate_read_time(article_text)也当作自然语言文本来理解,它不会去执行这个函数。它可能会在回复中说:“好的,文章的主要内容是……阅读时间大约是 5 分钟。” 但这个“5分钟”是它猜测的,而不是通过真正执行你的函数计算出来的。
3、 正确的强大工具:Function Calling
准确的说,OpenAI 可以在你提供完备的函数信息这个前提下,协助你做上下文的串联,类似 AI处理-Json 格式结果-仍然由你把Json结果传入函数-函数结果-AI 再处理-输出
3.1、AI 帮你决策是否应调用函数并提供JSON化参数,仍需你解析JSON完成后续调用
这是 OpenAI API 的一个正式功能,允许你描述一系列函数(工具) 给 AI 模型,然后模型可以根据对话上下文,智能地判断是否需要调用函数,并返回一个结构化的 JSON 对象,告诉你应该调用哪个函数以及参数是什么。真正的函数执行是在你的代码中完成的。
工作流程如下:
1)你(开发者):定义好你可供调用的函数列表(包括函数名、描述、参数 schema)。
2)你:将用户请求和函数列表一起发送给 AI 模型(如 gpt-3.5-turbo, gpt-4)。
3)AI 模型:分析用户的请求。如果发现需要调用你提供的函数才能完成请求,它不会执行函数,而是会返回一个结构化的 JSON 响应,其中包含:
function_name: 建议调用的函数名。
arguments: 调用该函数所需的参数(也是一个 JSON 对象)。
4)你(开发者):在你的服务器端代码中接收到这个 JSON 响应,然后根据模型返回的信息,真正地执行你本地定义的函数(比如查询数据库、调用外部 API、进行计算等)。
5)你:将函数执行的结果再次发送给 AI 模型。
6)AI 模型:结合之前的对话历史和函数执行的结果,生成最终的自然语言回复给用户。
3.2、举个例子:假设做一个能查询天气的聊天机器人
from openai import OpenAI
import json
import requests
client = OpenAI(api_key="你的API密钥")
# 第1步:定义可供AI调用的函数工具
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "获取指定城市的当前天气",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市名称,例如:北京",
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "温度单位,摄氏度或华氏度",
},
},
"required": ["location"],
},
},
}
]
# 第2步:将用户请求和工具列表发送给AI
messages = [{"role": "user", "content": "北京今天天气怎么样?"}]
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages,
tools=tools,
tool_choice="auto", # 让模型自己决定是否调用函数
)
response_message = response.choices[0].message
print("AI的初始回复:", response_message)
# 第3步:检查AI是否想要调用函数
if response_message.tool_calls:
# 通常只有一个工具调用,我们取第一个
tool_call = response_message.tool_calls[0]
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments)
# 第4步:在你的代码中执行真正的函数!
if function_name == "get_current_weather":
# 这里模拟一个天气API调用
# 真实场景中,你可能会调用和风天气、OpenWeatherMap等API
weather_data = {
"location": function_args["location"],
"temperature": "22",
"unit": "celsius",
"forecast": ["晴朗", "微风"],
}
print("函数执行结果:", weather_data)
# 第5步:将函数执行结果返回给AI,让它来组织语言回答用户
messages.append(response_message) # 添加AI的上一轮回复(包含工具调用请求)
messages.append(
{
"tool_call_id": tool_call.id,
"role": "tool",
"name": function_name,
"content": json.dumps(weather_data), # 将函数结果作为内容
}
)
# 第6步:将对话历史和函数结果发送给AI,让它生成最终回答
second_response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages,
)
final_reply = second_response.choices[0].message.content
print("\n给用户的最终回答:", final_reply) # 例如:“北京今天天气晴朗,气温22摄氏度,有微风。”
4、GPT 版本的选择
在满足任务要求的前提下,选择最便宜、最快的模型。
能力排名:GPT-4o(原生全模态) > GPT-4 Turbo(支持视觉) > GPT-4(支持视觉) > GPT-3.5-Turbo(纯文本)
成本排名:GPT-3.5-Turbo < GPT-4o < GPT-4 Turbo ≈ GPT-4
| 模型系列 | 核心特点 | 成本(输入/输出,相对比较) | 最佳适用场景(从成本角度) |
|---|---|---|---|
| GPT-4o | 最新旗舰,速度快,能力最强,成本低于GPT-4 Turbo,支持多模态 | 低(输入) / 中(输出)比GPT-4 Turbo更便宜 | 大多数原本计划用GPT-4 Turbo的场景。现在是性能、速度和成本的最佳平衡点,是新项目的默认首选. |
| GPT-4 Turbo | 能力强,知识更新(至2023年底),上下文长(128k) | 中(输入) / 高(输出)比GPT-4便宜 | 需要极强推理能力、复杂指令遵循、或超长上下文的高要求任务。当GPT-4o无法满足要求时考虑。 |
| GPT-4 | 能力强,知识较旧(2021年),速度慢,价格高 | 高(输入) / 高(输出)最昂贵的系列 | 基本被GPT-4 Turbo淘汰。除非有特定兼容性需求,否则不应作为新选择。 |
| GPT-3.5-Turbo | 速度极快,成本极低,但能力相对较弱 | 极低(输入) / 极低(输出)最具成本效益 | 1. 大量、简单的对话和任务(客服机器人、草稿生成)。2. 成本极度敏感的原型测试和大规模应用。 |
4.1. GPT-3.5-Turbo:你的“经济型工作马”
成本定位:极致性价比。它的输入/输出 token 价格通常是 GPT-4 系列的几十分之一。
适用场景:
聊天机器人和客服:处理大量、常见的用户咨询,无需深度推理。
文本摘要和简单内容生成:对质量要求不极高的草稿、邮件、简单文章生成。
概念解释和翻译:不需要最新知识的通用任务。
产品原型开发和测试:在投入大量成本前,用便宜的模型验证想法。
成本控制建议:
首选模型。任何不需要 GPT-4 系列强大推理能力的任务,都应优先使用它。如果你的应用 80% 的任务都能由 GPT-3.5-Turbo 很好地处理,你将节省超过 90% 的成本。
4.2. GPT-4o:新时代的“性价比之王”
成本定位:高性能与低成本的优秀平衡。它的设计目标之一就是提供类似 GPT-4 的能力,但价格更低、速度更快。
适用场景:
需要较强推理的通用助手:替代大部分原本需要使用 GPT-4 Turbo 的场景。
多模态任务(视觉):需要理解图片内容并回答问题。
对响应速度有要求的复杂任务:如需要复杂逻辑的代码生成、数据分析。
成本控制建议:
作为升级版默认选择。当 GPT-3.5-Turbo 无法满足质量要求时,首先尝试 GPT-4o,而不是直接跳到更贵的 GPT-4 Turbo。它通常能以更低成本达到足够好的效果。
4.3. GPT-4 Turbo:特定领域的“专业工具”
成本定位:高端能力,价格不菲。虽然比旧版 GPT-4 便宜,但依然远高于 GPT-4o 和 GPT-3.5-Turbo。
适用场景:
极高要求的复杂推理:如高级数学、物理问题求解,复杂的战略分析。
需要最新知识的任务(知识截止到 2023年4月)。
处理超长文档(128K 上下文):需要模型同时理解和分析整本书、长篇法律文件等。
成本控制建议:
精准使用。仅在任务明确超出 GPT-4o 能力范围时使用。例如,你的应用 95% 的请求由 GPT-3.5-Turbo 处理,4% 由 GPT-4o 处理,只有最顶尖的 1% 复杂请求才交给 GPT-4 Turbo。这是一种“模型级联”的成本优化策略。
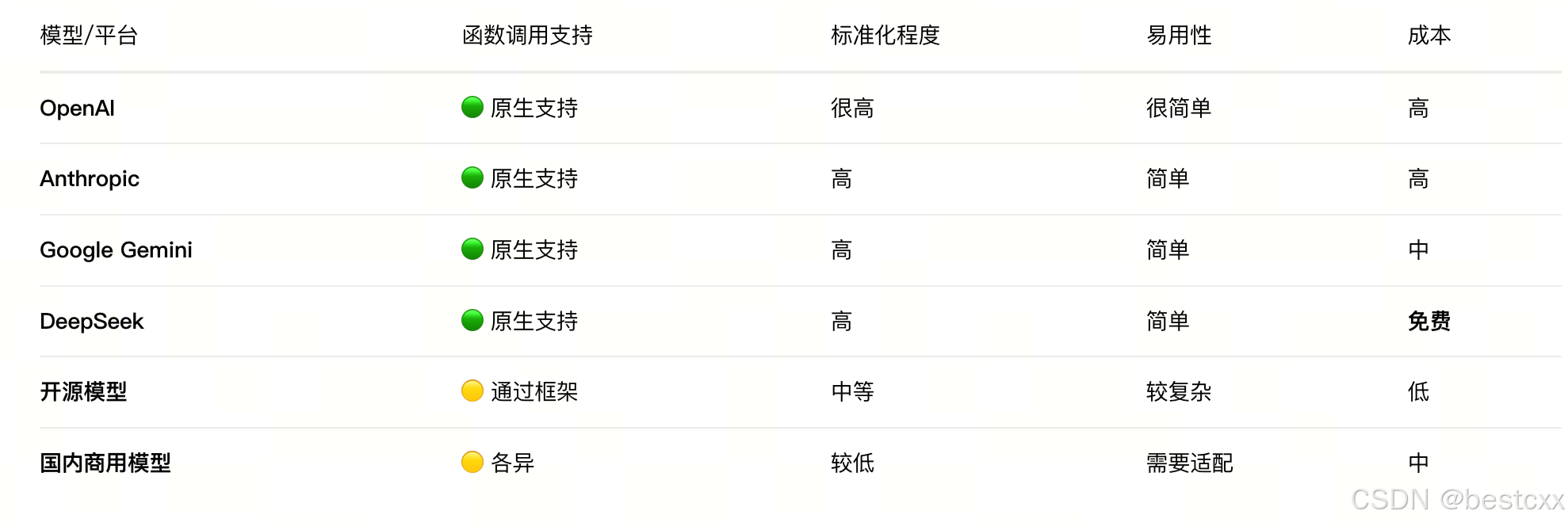
5、其他模型也有类似支持
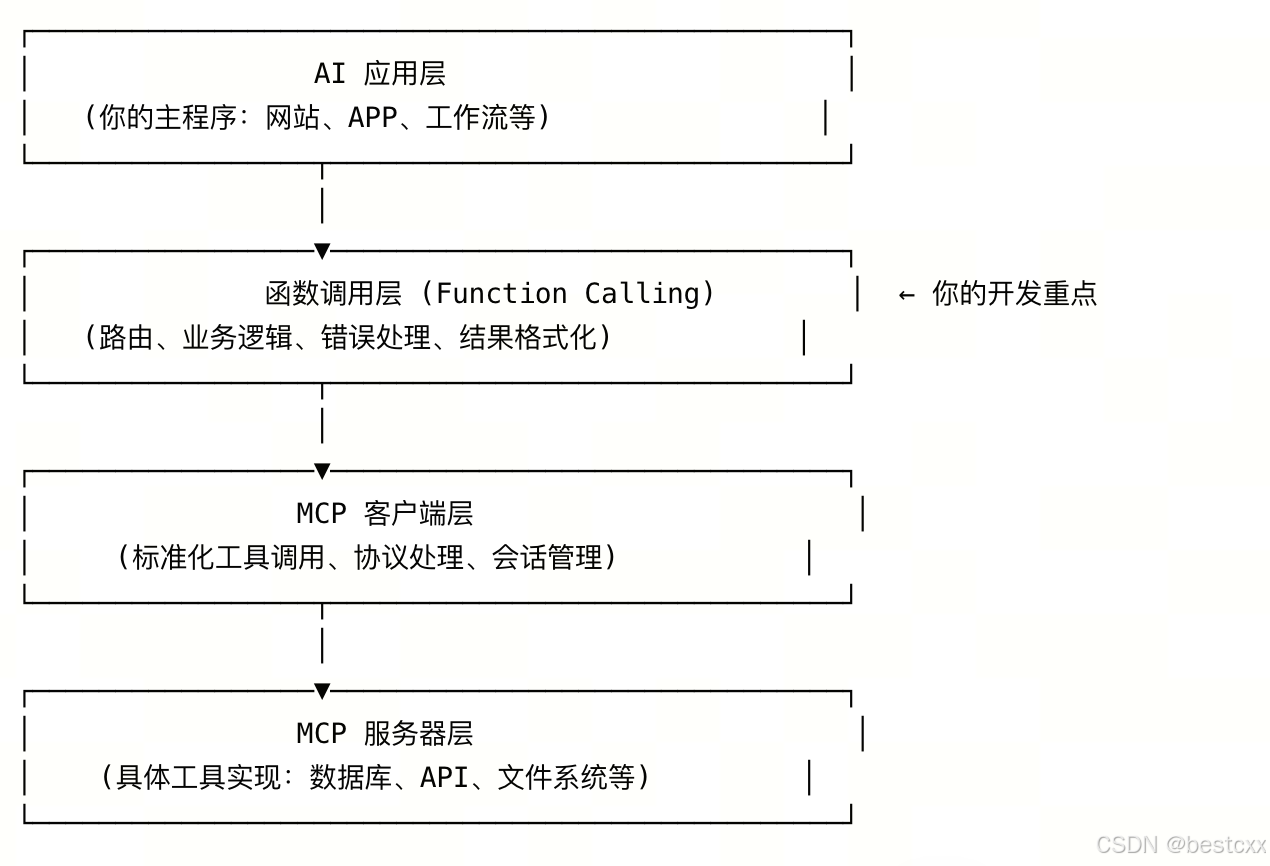
6、(上面提到的)函数和MCP 的组合模式
通常是在函数里封装MCP的能力
# 初期:直接函数调用(简单项目)
def simple_weather_query(city: str) -> str:
return requests.get(f"https://api.weather.com/{city}").json()
# 演进:引入MCP(复杂项目)
def advanced_weather_analysis(city: str, days: int) -> dict:
# 业务逻辑
forecast = mcp_client.call_tool("weather", "get_forecast", {"city": city, "days": days})
# 数据分析
trends = mcp_client.call_tool("analytics", "analyze_trend", forecast)
return format_analysis(trends)
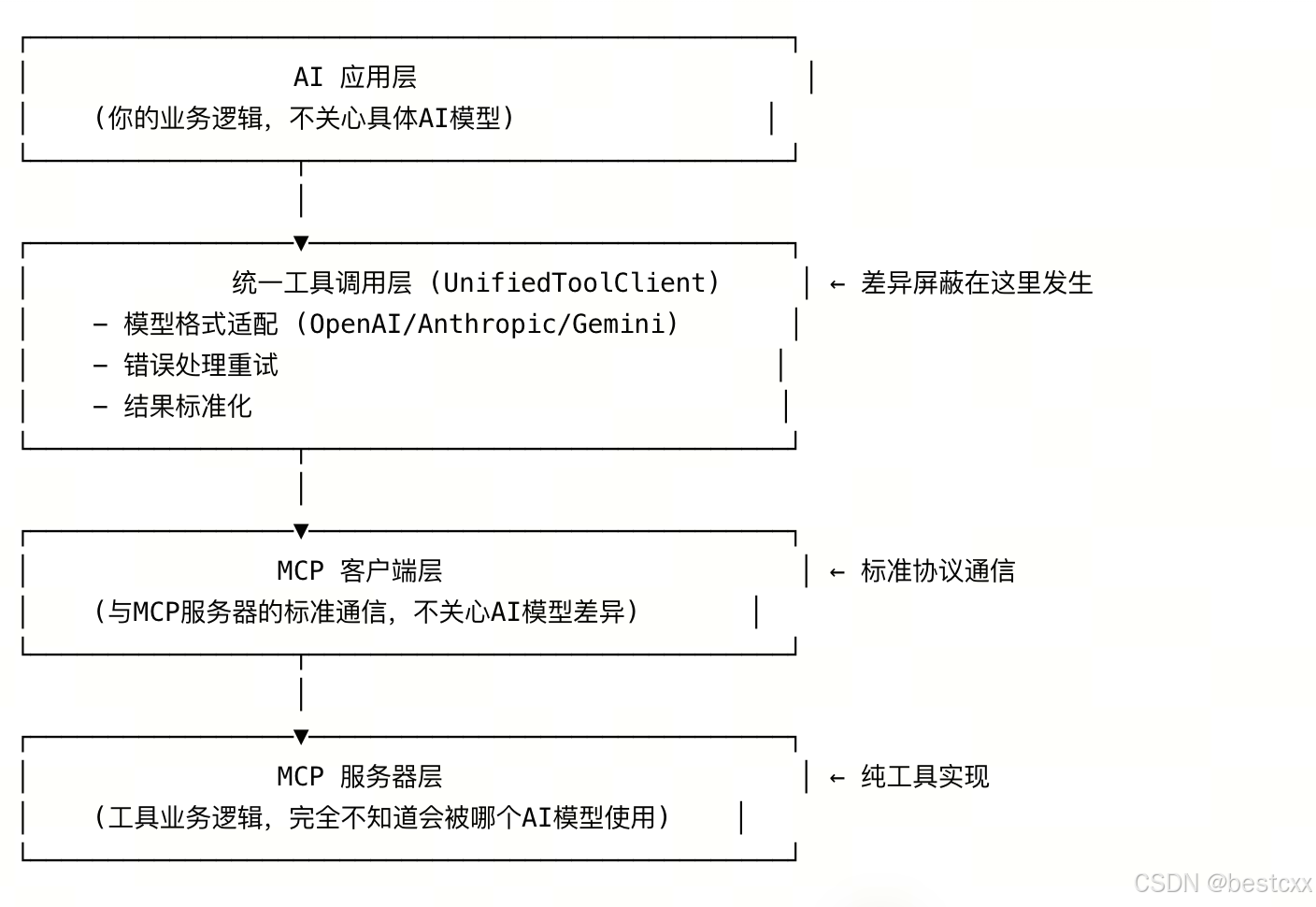
6.1、需要注意
不同模型和 MCP 交互不一样,如果多模型共存,需要考虑屏蔽这一差异
- 错误理解
AI模型1 ──┐
AI模型2 ──┤──▶ MCP服务器 ──▶ 工具实现
AI模型3 ──┘
-
正确理解
AI模型1 ──┐
AI模型2 ──┤──▶ 统一适配层 ──▶ MCP客户端 ──▶ MCP服务器 ──▶ 工具实现
AI模型3 ──┘ -
MCP 服务是唯一的,但是调用前,不同的模型提供的交互出入参数需要做格式适配,就是在函数入参和函数调用MCP服务器之间,做一层封装处理


















 1045
1045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









