




前文回顾
上一篇文章地址:链接
5.方差和标准差
方差(variance)和标准差(standard deviation)是两种常用的统计量,用于衡量数据的分散程度。方差是指数据点与其均值之间的偏离程度的平均值。它通过计算每个数据点与均值的差值的平方,然后取平均得到。方差的公式如下:
方差
=
∑
i
=
1
n
(
x
i
−
x
ˉ
)
2
n
方差 = \frac{\sum_{i = 1}^{n}(x_{i}-\bar{x})^{2}}{n}
方差=n∑i=1n(xi−xˉ)2
其中,
x
i
x_{i}
xi 是第i个数据点,
x
ˉ
\bar{x}
xˉ是所有数据点的均值,n是数据点的总数
标准差是方差的平方根,它表示数据点与均值之间的差异程度。标准差通常用于评估数据的离散程度,数值越大表示数据越分散,数值越小表示数据越接近均值。标准差的公式如下:
标准差
=
方差
标准差 = \sqrt{方差}
标准差=方差
下面通过一个具体案例来说明方差和标准差的计算过程。假设我们有一组数据:2, 4, 6, 8, 10。首先计算均值:
x
ˉ
=
2
+
4
+
6
+
8
+
10
5
=
6
\bar{x} = \frac{2 + 4 + 6 + 8 + 10}{5} = 6
xˉ=52+4+6+8+10=6
然后计算方差,即每个数据点与均值之差的平方的平均:
方差
=
(
2
−
6
)
2
+
(
4
−
6
)
2
+
(
6
−
6
)
2
+
(
8
−
6
)
2
+
(
10
−
6
)
2
5
=
8
方差 = \frac{(2 - 6)^{2} + (4 - 6)^{2} + (6 - 6)^{2} + (8 - 6)^{2} + (10 - 6)^{2}}{5} = 8
方差=5(2−6)2+(4−6)2+(6−6)2+(8−6)2+(10−6)2=8
最后计算标准差,即方差的平方根:
标准差
=
8
≈
2.83
标准差 = \sqrt{8} \approx 2.83
标准差=8≈2.83
因此,这组数据的方差为8,标准差为2.83。方差和标准差的数值表示数据的分散程度,较大的数值意味着数据点相对于均值的离散程度更高
6.正态分布
正态分布(Normal Distribution),也称为高斯分布(Gaussian Distribution),是统计学中最常见的连续概率概率分布之一。它在自然界和许多实际应用中都具有重要性
正态分布的特点如下:
- 对称性:正态分布呈现对称的钟形曲线,均值位于分布的中心,两侧的尾部逐渐趋近于零。
- 唯一标识:正态分布由两个参数完全确定,即均值(μ)和标准差(σ),其中均值决定了分布的位置,标准差决定了分布的形状。
- 中心极限定理:正态分布是许多随机现象的结果,根据中心极限定理,当独立随机变量求和时,其总和的分布趋向于正态分布。
- 68 - 95 - 99.7规则:约有68%的数据落在均值的一个标准差范围内,约有95%的数据落在均值的两个标准差范围内,约有99.7%的数据落在均值的三个标准差范围内。
正态分布在实际应用中具有重要性的原因如下:
- 数据建模:许多实际观测的数据可以近似地服从正态分布。因此,正态分布可用于对这些数据进行建模和分析
- 统计推断:许多经典的统计推断方法,如假设检验和置信区间估计,基于正态分布的性质进行计算
- 预测和控制:正态分布在预测和控制问题中起着重要作用。例如,在质量控制中,正态分布被用来设置规范限和判断过程是否稳定
- 自然现象:许多自然现象和人类行为都可以用正态分布来描述,如身高、体重、IQ分数等
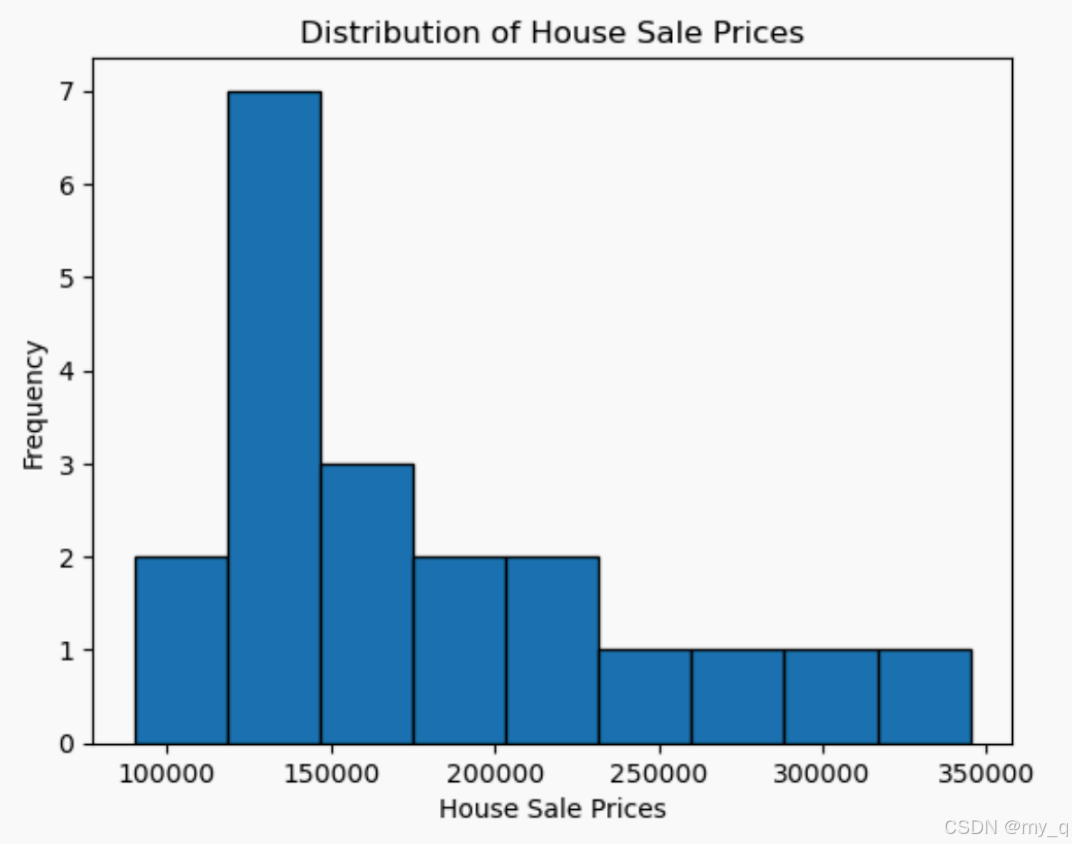
正态分布的重要性在于其具有广泛的适用性和数学性质的良好性质。它在统计学和各个领域的科学研究中扮演着重要角色,并且为我们提供了一种常见的模型来理解数据分布和进行概率推断,以下是一个实际开源的正态分布案例,使用了来自 Kaggle 的“House Prices: Advanced Regression Techniques”数据集中的房屋销售价格数据[208500, 181500, 223500, 140000, 250000, 143000, 307000, 200000, 129900, 118000, 129500, 345000, 144000, 279500, 157000, 132000, 149000, 90000, 159000, 139000]这些数据代表不同房屋的销售价格(以美元为单位)。我们可以对这些数据进行统计分析,计算均值和标准差,并通过绘制直方图或概率密度函数图形来探索它们是否近似于正态分布。可以使用Python的数据分析库(例如matplotlib和numpy)来绘制给定数据的直方图。以下是使用Python生成直方图的示例代码:
import matplotlib.pyplot as plt
import numpy as np
data = [208500, 181500, 223500, 140000, 250000, 143000, 307000, 200000, 129900, 118000, 129500, 345000, 144000, 279500, 157000, 132000, 149000, 90000, 159000, 139000]
# Set the bins and number of intervals for the histogram
bin_edges = np.linspace(min(data), max(data), num=10)
# Plot the histogram
plt.hist(data, bins=bin_edges, edgecolor='black')
# Add labels and title
plt.xlabel('House Sale Prices')
plt.ylabel('Frequency')
plt.title('Distribution of House Sale Prices')
# Show the plot
plt.show()
运行此代码将生成一个直方图,显示了房屋销售价格的分布情况。横轴表示价格区间,纵轴表示频数或计数
7.假设检验
假设检验是统计学中的一种方法,用于验证关于总体参数或数据集特征的假设。它提供了一种科学的方式来判断样本数据是否支持或反驳某个假设,在使用假设检验时,通常有两个假设:零假设(null hypothesis)和备择假设(alternative hypothesis)。零假设表示我们要进行检验的假设,而备择假设则是对零假设的对立或替代假设,假设检验的步骤如下:
- 建立假设:明确零假设和备择假设
- 选择显著性水平:确定接受或拒绝零假设的临界值
- 收集数据:收集与问题相关的数据
- 计算统计量:根据数据计算出适当的统计量
- 计算P值:根据统计量计算出P值,即给定观察到的数据情况下,零假设成立的概率
- 做出决策:将P值与显著性水平进行比较,并基于P值做出接受或拒绝零假设的决策
- 得出结论:根据决策结果得出关于零假设的结论
一个实际的案例是检验一种新药物是否有效。假设我们想要测试新药物对某种疾病的疗效,零假设为“新药物无效”,备择假设为“新药物有效”。我们进行了一项随机对照试验,将患者分为两组,其中一组接受新药物治疗,另一组接受安慰剂。收集得到的数据如下:
- 新药物组平均疗效:82%
- 安慰剂组平均疗效:75%
现在我们需要使用假设检验来验证该新药物是否有效。我们可以采用配对样本t检验,计算出适当的统计量,并计算P值。根据P值与预先确定的显著性水平进行比较,如果P值小于显著性水平(通常为0.05),则我们可以拒绝零假设,得出结论认为新药物是有效的。否则,我们无法拒绝零假设,即没有足够的证据支持新药物的疗效,但是请注意,实际的假设检验涉及更复杂的统计方法和假设情景,但这个案例提供了一个简化的示例来说明假设检验的概念和使用方法
8.统计抽样和抽样分布
统计抽样是指从一个总体中选择一部分个体作为样本的过程。通过对样本进行研究和分析,我们可以推断出有关总体的特征、参数或关系的信息,抽样分布是指在重复从总体中抽取样本,并计算某个统计量(例如均值、比例等)的情况下,该统计量的分布。抽样分布可以帮助我们了解样本统计量的变异性以及与总体参数之间的关系,中心极限定理(Central Limit Theorem, CLT)是统计学中的一个重要理论。它指出,当从任何总体中抽取足够大的样本时,样本平均值的分布会近似于正态分布,无论总体分布形态如何,具体而言,中心极限定理包含以下关键观点:
- 抽样分布的均值接近于总体均值
- 抽样分布的标准差接近于总体标准差除以样本大小的平方根
- 抽样分布呈现出对称的钟形曲线
中心极限定理对统计学有着重要的影响,因为它使得我们能够在不知道总体分布的情况下进行推断和假设检验。通过从总体中抽取样本,无论总体分布如何,我们可以利用抽样分布近似于正态分布的特点,应用基于正态分布的统计方法来做出推断。这使得统计学成为了现代科学、工程和社会科学中不可或缺的一部分
9.置信区间和假设检验的P值
置信区间(Confidence Interval)是一个用于估计总体参数的范围。它提供了一个区间,我们可以合理地认为总体参数在该区间内。置信区间通常以特定的置信水平表示,例如95%或99%。具体而言:
- 在给定的置信水平下,置信区间是样本统计量的上下界限,使得在重复抽样中有一定比例的区间包含真实的总体参数值
- 如果我们使用不同的样本进行重复实验,并计算出置信区间,有限个实验中有约95%的置信区间将包含总体参数
p值(p-value)是假设检验中的一个度量,表示观察到的数据或更极端情况出现的概率,假设零假设为真。具体而言:
- p值表示在零假设成立的条件下,观察到的样本结果或更极端结果出现的概率
- 通过与预先选定的显著性水平进行比较,可以根据p值来判断是否拒绝零假设
- 如果p值小于显著性水平(通常为0.05),则我们有足够的证据拒绝零假设;否则,我们无法拒绝零假设
在统计推断中,置信区间和p值都用于对总体参数进行推断和假设检验:
- 置信区间提供了一个区间范围,我们可以合理地认为总体参数在其中。它用于估计总体参数的不确定性,并给出一个范围的估计
- p值则用于评估样本数据与零假设一致的程度。它提供了一个基于观察数据的量化指标,以帮助我们决定是否拒绝或接受零假设
这两个概念在统计学中是常用的工具,用于推断总体参数、比较组之间的差异,并从数据中得出可靠的结论



















 1001
1001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









