




许多科研小白一定也发现,现在的科研路上少不了ChatGPT老师的帮助,那我今天就带大家一起在自己的电脑上部署一下中科院学术专业版ChatGPT吧!
1.下载项目
git clone https://github.com/binary-husky/chatgpt_academic.git
2.创建一个ChatGPT的环境并激活
首先打开自己的Anaconda Prompt,如下图,以我自己为例,我是python==3.11.7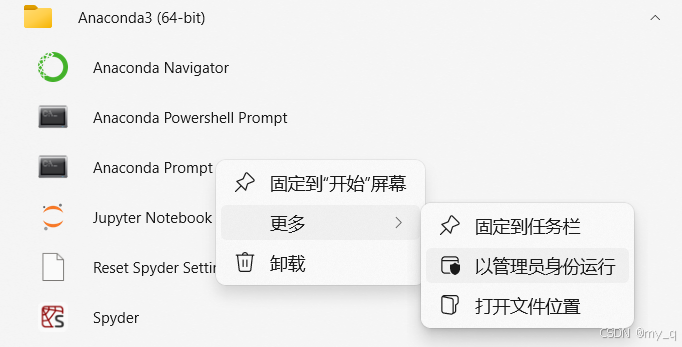
其次,在打开的终端框输入以下代码创建环境:
conda create -n ChatGPT python=3.11.7
过程中可能遇到Proceed([y]/n)?,这时输入
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 266
266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









