



这是二十几年前在上交大饮水思源BBS上关于数组处理优化的一次讨论。下面都是原帖,没有修改过。
【 原文由 MICROZC 所发表 】
标题: [转载] 一个关于循环的问题 下面两个过程,那个更加优化,为什么
int i,j;
for ( i=0; i<10000; i++)
for ( j=0; j<50; j++)
p[i][j] = 5*p[i][j];
int i,j;
for ( j=0; j<50; j++)
for ( i=0; i<10000; i++)
p[i][j] = 5*p[i][j];
【 在 beepbug 的大作中提到: 】
没实际试过。但是我想,具体试一种C编译器或许不能完整回答问题。从根本上看,似乎取决于C编译器是如何处理数组的。是行优先呢,还是列优先?如果全世界的C编译器全是一个德性,那无疑有唯一答案。如果两种都有,那答案便因编译器而异了。
【 在 rainycat 的大作中提到: 】
这个应该是固定的
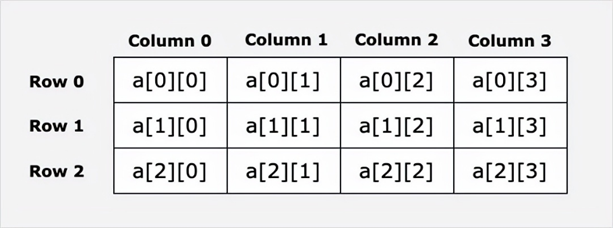
例如:int a[3][4]是作为由3个4元数组构成的数组来处理的,这样a[3][0]和a[3][1]自然是相邻的。
我不记得这叫行优先还是列优先,总之跟fortran相反
【 在 beepbug 的大作中提到: 】
如果a[3][0]和a[3][1]是相邻的,便是列优先。反之,若a[1][2]和a[2][2]相邻,便是行优先。对于前者,应将行处理放在外循环,将列处理放在里面。对于后者,则相反。这样效率才高。
【 在 blueskyer 的大作中提到: 】
恩 这个倒是的确 不过不论是什么优先 总要有一个规律 可能最终的结论因编译器的实现而定 但是 具体遵循什么样的规律 还是有一定讨论的意义的
【 在 beepbug 的大作中提到: 】
可能是我没讲清这个道理。我说的就是规律。是因编译器的实现而异。确切地说,就是取决于所用的C编译器对数组的处理(物理存储结构)是行优先还是列优先。
(其中很多人跟帖,都表示要实际试一下。省略。)
【 在 beepbug 的大作中提到: 】
我很赞同哪位同学亲手做实验。只是想提醒一下,只在一种机器上的一种编译器上做实验,结果不能算是普遍真理。还有,在负荷很重的多用户UNIX主机上做要注意:由于O.S.的Nondeterminacy,结果会很搞笑。我曾在C-1小巨型机上重复做过类似题目。结果是个别几次竟然是相反结论。
【 在 phiobos 的大作中提到: 】
其实这个问题更多的取决于操作系统和CPU的内存操作策略而不是编译器
【 在 beepbug 的大作中提到: 】
你的数组不是O.S.管的。C编译器的linker为你的数组向O.S.申请一块空间。O.S.只管提供要求字节数的空间,而不管linker用作什么以及怎么用。O.S.也管数组,但那是它自己内部的数组。CPU的指令系统对数组的处理效率倒是有最大的影响。但是与这个问题的本义无关(这里是讨论哪一种快)。linker拿到空间后,便按这种C编译器的思路建立你的数组的物理存储结构。要么是行优先,要么是列优先。你顺着它做,效率就高。逆水行舟就费力。
这个问题值得讨论。因为它涉及到好多方面。软、硬皆有:数据结构的物理存储结构、存储空间的使用、编译器及其与O.S.的关系、O.S.的不确定性、指令系统、实验与结论的关系等等。
【 在 lippman 的大作中提到: 】
恩 数组不是系统管的 没错 但这个问题不是数组的问题了 主要是cache 命中率的问题还有内存分配的问题 这都是编译器无法染指的地方
【 在 beepbug 的大作中提到: 】
cache命中率不会改变快慢结果。它有影响,但是只是使快的更快,慢的更慢。没影响所讨论问题的结论。内存怎样分配对这个问题没关系。有关系的只是分配来的内存怎么使用。
当数组非常庞大时,数组的处理速度就影响程序的运行速度。这问题不仅仅是在C/C++里存在,在其它编程语言里也存在。要提高处理速度,光有数据结构和算法知识还不够,要了解你的数组的物理存储结构。
后来在水木清华BBS及XX部技术论坛上转贴过,用户名都是beepbug。

















 1544
1544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









