




 本文详细介绍了Zookeeper客户端的常用命令,包括查看节点、创建节点(持久和临时、顺序)、获取和修改节点内容、监听值变化和子节点变化,以及删除和查看节点状态。
本文详细介绍了Zookeeper客户端的常用命令,包括查看节点、创建节点(持久和临时、顺序)、获取和修改节点内容、监听值变化和子节点变化,以及删除和查看节点状态。
Zookeeper 客户端的命令行操作
我们已经搭建好了 Zookeeper 集群,接下来就是启动客户端,在里面输入增删改查相关的命令,然后发送给服务端执行,就类似于 Redis 一样。
# 输入 zkCli.sh 即可启动
# 会自动连接本地的 zookeeper 服务端
# 如果想连接其它节点的端,那么需要加上 -server 参数
# 比如 zkCli.sh -server ip:2181
[root@satori ~]# zkCli.sh
回车之后,客户端便可连接至 Leader 节点。

然后来看看命令都有哪些?
1.显示某个路径下的所有节点:ls
2.显示某个路径下的所有节点,以及当前节点的详细信息:ls2
但是该参数已经废弃,推荐使用 ls -s。
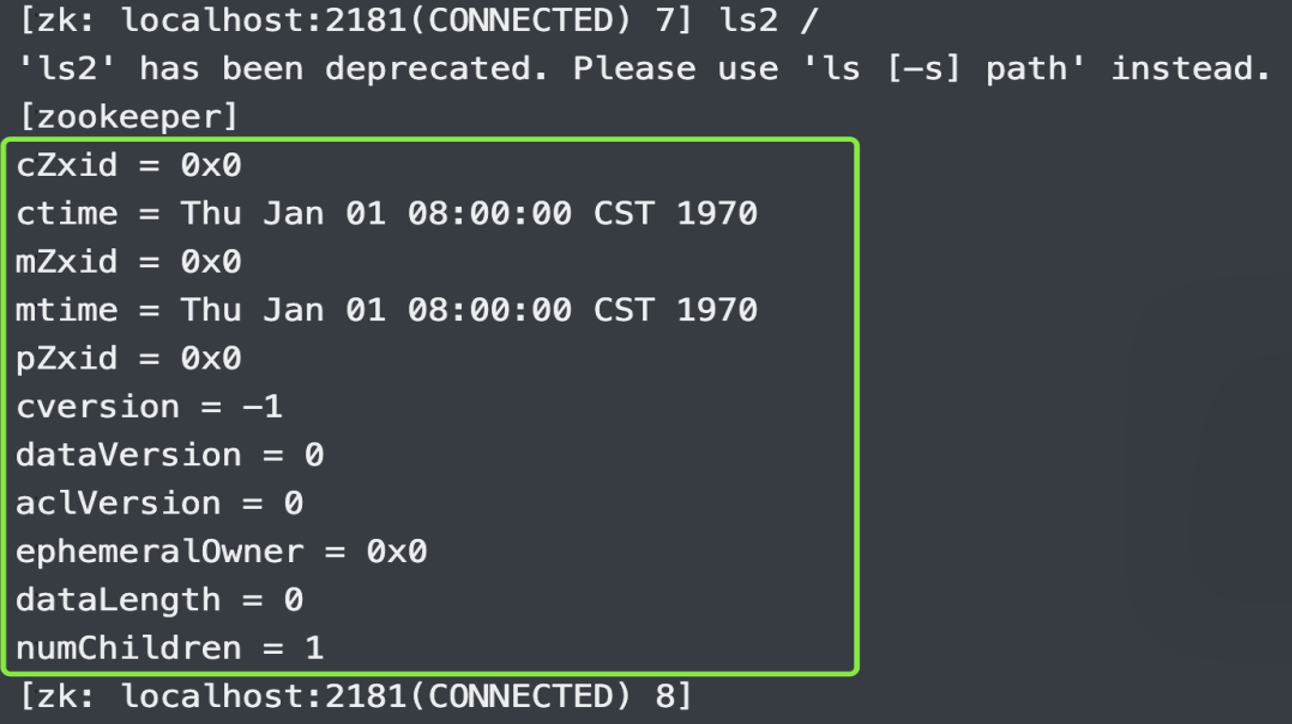
不但显示根节点下面的所有节点,还显示了当前根节点的详细信息,就是绿色框框内的部分。那么它们都代表啥含义呢,来解释一下。
cZxid:创建节点时的事务 ID,每次向 Zookeeper 写入或者修改数据时都会产生一个事务 ID。它是 Zookeeper 中所有修改的次序,如果zxid1小于zxid2,那么zxid1对应的修改操作在zxid2之前发生。ctime:当前节点的创建时间,时间戳形式,单位毫秒。mZxid:当前节点最后一次更新的事务 ID。mtime:当前节点最后一次更新的时间,时间戳形式,单位毫秒。pZxid:当前节点的子节点最后一次更新的事务 ID。cversion:当前节点的子节点变化了多少次。dataVersion:当前节点的数据变化了多少次。aclVersion:当前节点访问控制列表多少次。ephemeralOwner:如果节点是临时节点,则表示节点拥有的 Session ID,如果不是则为 0 0 0。dataLength:节点可以存储数据,所以它表示数据的长度。numChildren:当前节点的子节点数量。
3.创建节点:create
比如 / 下面只有 Zookeeper 这一个节点,我们再创建一个新的。

因为节点是用来存储数据的,所以创建节点的时候也应该指定相应的值,正如 Redis 在 set 一个 key 的时候也要指定 value 一样。当然不指定也可以,只不过不指定的话相当于值为 null。
通过 create 创建的节点默认是持久节点,那么什么是持久节点呢?首先 Zookeeper 的节点是有类型的,可以分为持久节点和临时节点:
- 持久节点(
persistent):客户端和服务端断开连接之后,创建的节点不删除,也就意味着节点上的数据会保留。 - 临时节点(
ephemeral):客户端和服务端断开连接之后,创建的节点会自动删除,数据不会被保留。
此外节点还可以带编号和不带编号,如果带编号的话,Zookeeper 会自动在节点的末尾加上一串数字。比如上面的 /ow,它默认是不带编号的,如果我们创建的是带编号的,那么节点创建之后就会变成 /ow001。
编号会依次递增,因此带编号的节点也叫做 顺序节点。
因此组合起来,Zookeeper 的节点类型总共有 4 4 4 种。其中使用 Zookeeper 作为分布式锁,便是基于 临时顺序节点 实现的。多个客户端同时往 Zookeeper 上面创建临时顺序节点,谁的编号最小,那么谁就先创建成功,我们就认为它拿到了分布式锁。
当客户端操作完共享数据需要释放锁的时候,只需要断开连接即可,这样该客户端创建的临时节点就会自动删除。一旦节点删除,那么它的下一个顺序节点就成了编号最小的节点,从而拿到分布式锁,因此这个机制就避免了因客户端挂掉而导致的死锁问题。
顺序节点 非常有用,特别是在分布式系统中,编号可以用于为所有事件进行全局排序,这样客户端通过顺序号就能推断事件的顺序。
使用 create 创建的节点默认是 持久非顺序 节点,那么其它类型的节点怎么创建呢?
4.创建临时节点:create -e
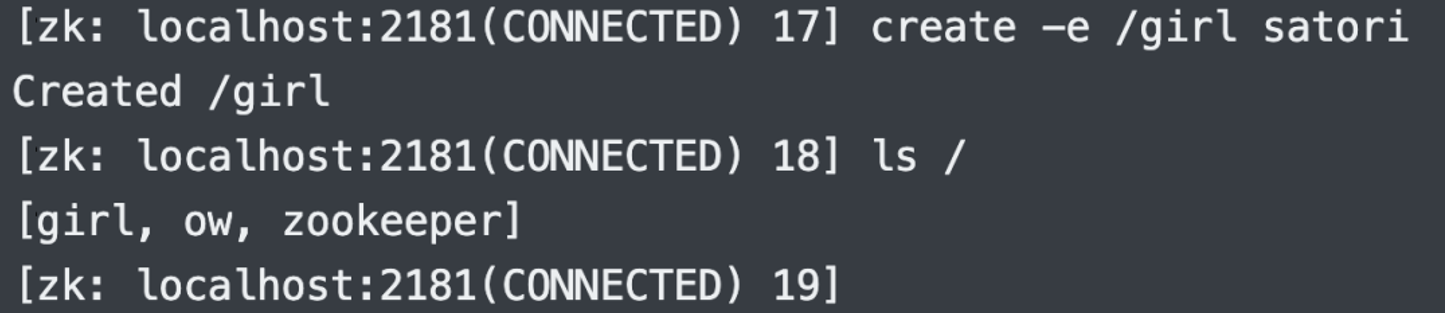
临时节点创建完毕,如果此时客户端断开连接,临时节点就会被删除。

我们重启客户端,再次查看,发现临时节点已经被删除了。
5.创建顺序(带编号)节点:create -s
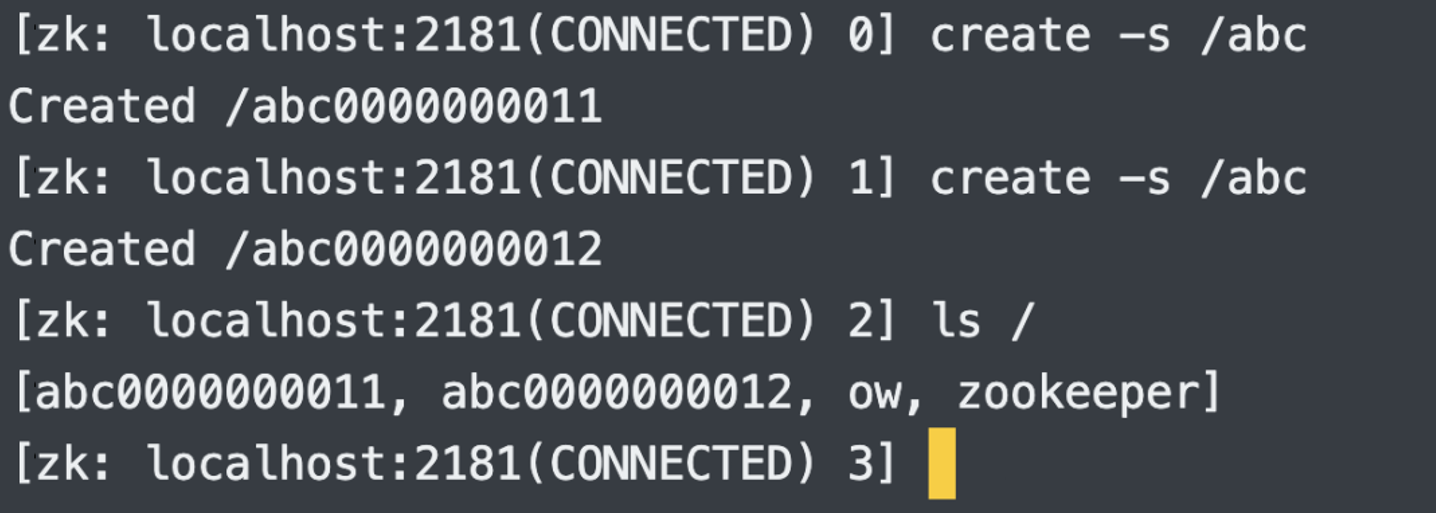
创建的时候,自动在结尾加上编号。我这里之前创建过几个,现在编号是从
11
11
11 开始,总之顺序节点的编号是递增的,只会增大,不会减小。
所以 -e 表示临时节点,-s 表示顺序节点,那如果创建 临时顺序节点 呢?很简单,两个参数一块指定即可。

客户端退出之后,这个临时节点就会消失。
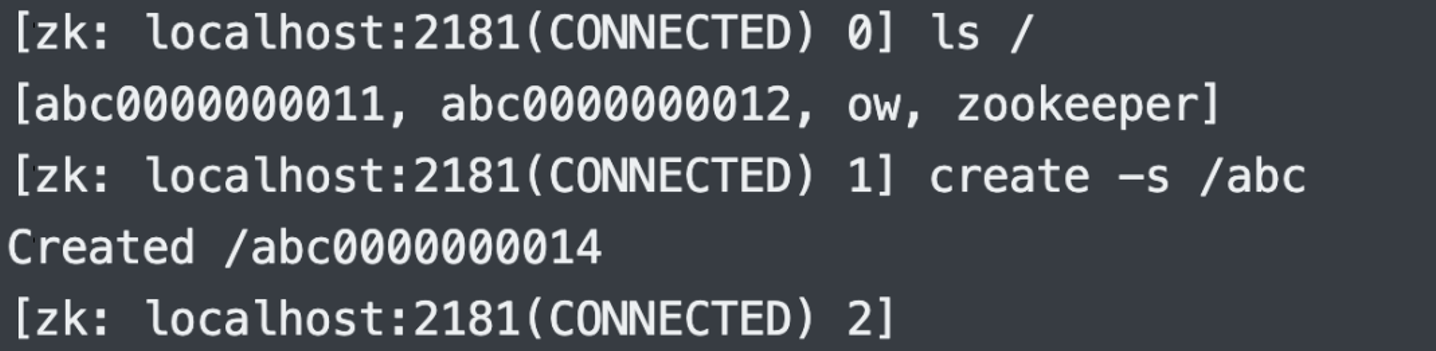
然后再次创建,发现编号从
14
14
14 开始,因为顺序节点的编号只会依次增加。
6.获取节点内容:get
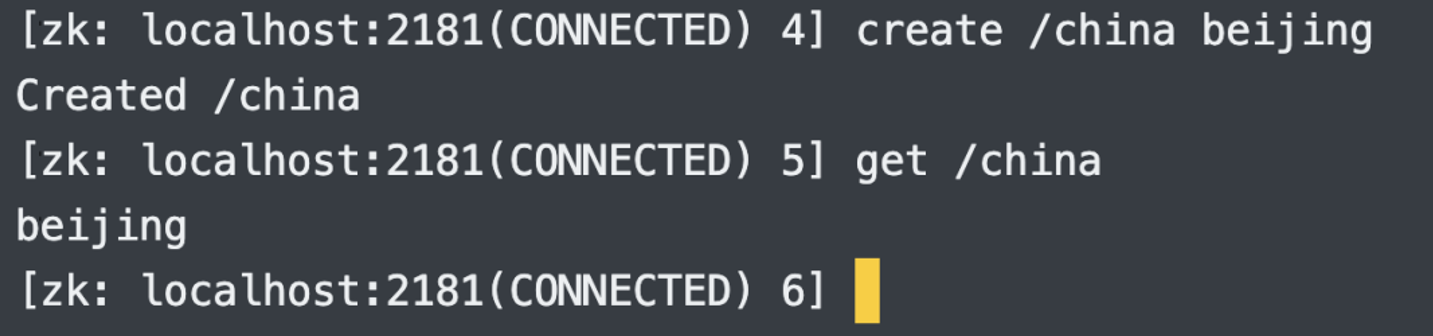
如果加上 -s 参数,还可以获取节点的详细信息。
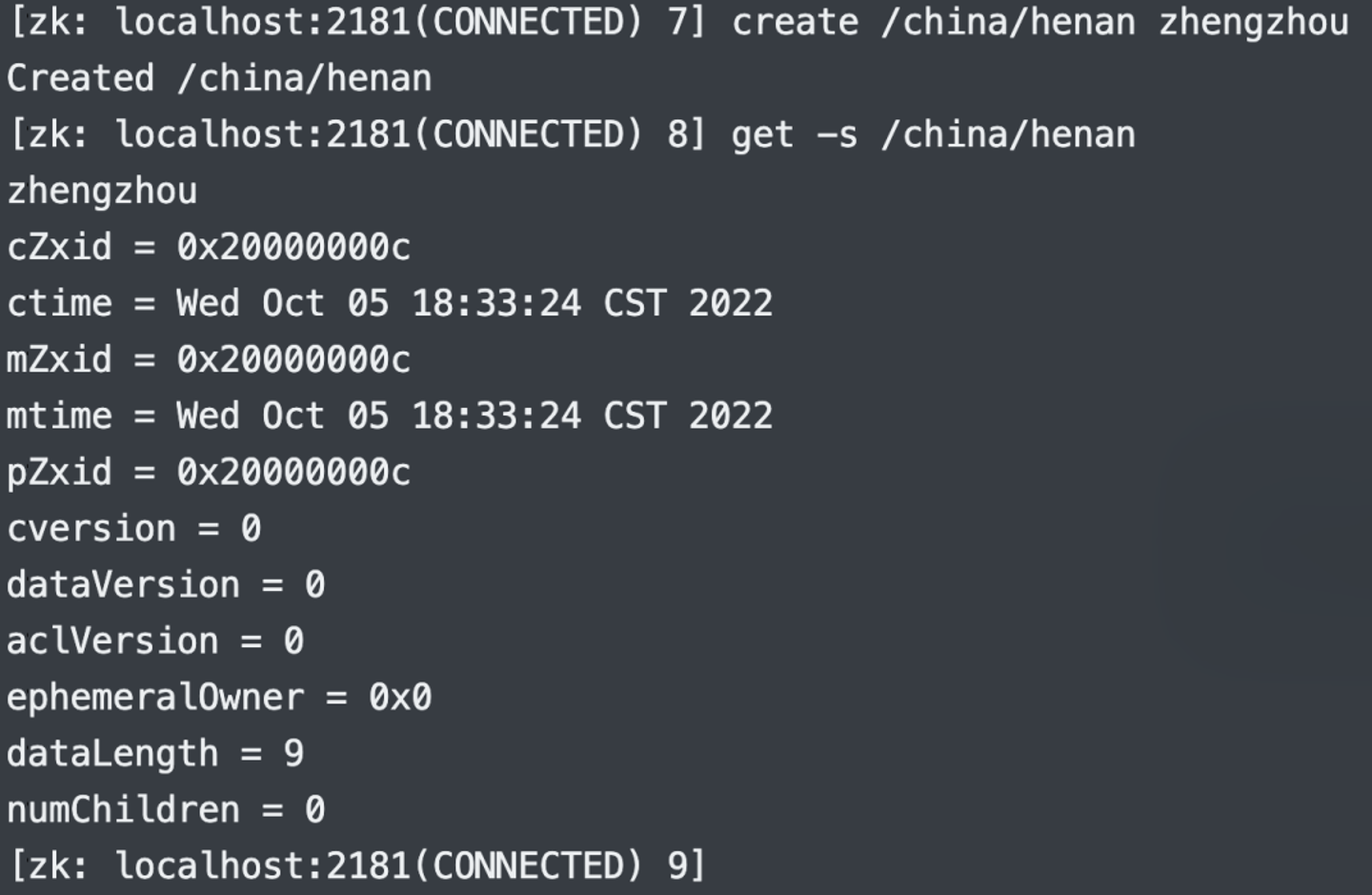
/china 节点存储的值是 beijing,/china/henan 节点存储的值是 zhengzhou。所以 Zookeeper 的数据结构就类似一个树,树上的每一个节点都可以存储具体的值,并且节点之间具有父子关系。
7.修改节点内容:set
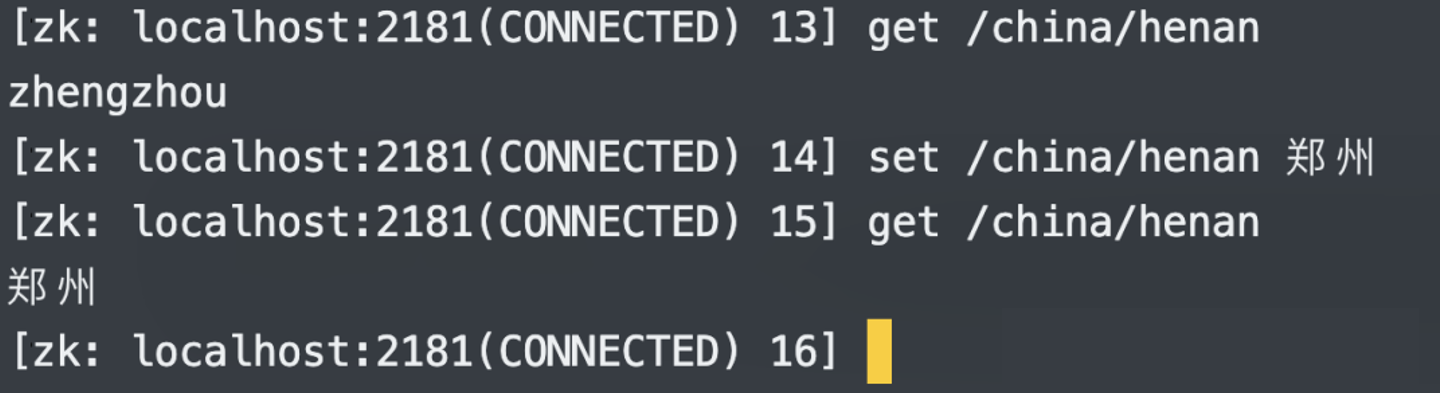
create 表示创建一个新的节点,每个节点会存储一个值,get 表示获取节点存储的值,set 表示修改节点存储的值。
需要注意的是,节点不能重复,所以我们不能这么做:

因为 /china/henan 这个节点已经存在了,我们不能重复 create,所以要修改节点的值的话,应该使用 set。
8.监听某个节点的值的变化:get -w
假设现在有两个客户端同时连接至 Zookeeper 集群,客户端 A 执行 get -w /china 就表示监听 /china 这个节点。然后在客户端 B 上面对 /china 这个节点进行 set,那么 A 机器上就会收到提示,提示我们监听的节点被修改了。
在 satori 节点上执行 get -w /china,然后返回节点的值,看起来和 get /china 没有什么区别。

在 koishi 节点上执行 set /china 北京,将节点的值给改掉。

再来查看 satori 节点,发现有额外输出。
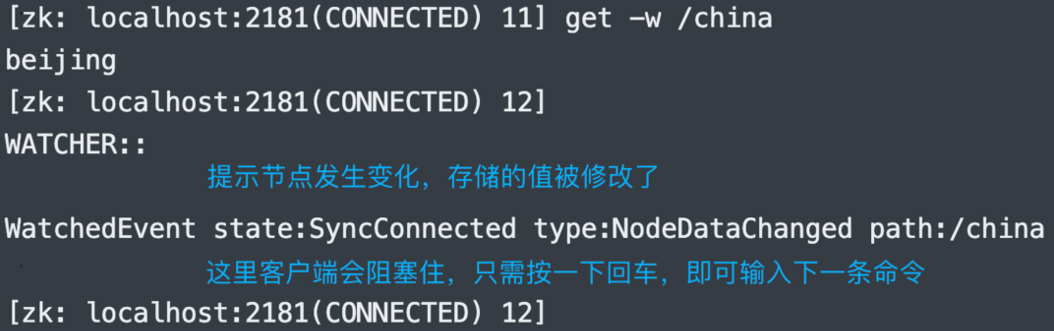
注意:监听是一次性的,如果再次 set 的话,那么 A 机器就不会再提示了,除非再次 watch。另外除了节点的值被修改之外会提示,当节点被删除时也会提示。
那么这背后的原理是怎么实现的呢?首先监听的时候,客户端会创建两个子线程,一个负责网络通信(connector),另一个负责监听(listener)。通过 connector 将注册的监听事件发送给服务端,服务端将注册的监听事件添加进注册监听器列表中。
当服务端监听到有数据变化,就会将这个消息发送给 listener 线程,然后 listener 线程将消息输出出来。
9.监听某个节点的子节点变化:ls -w
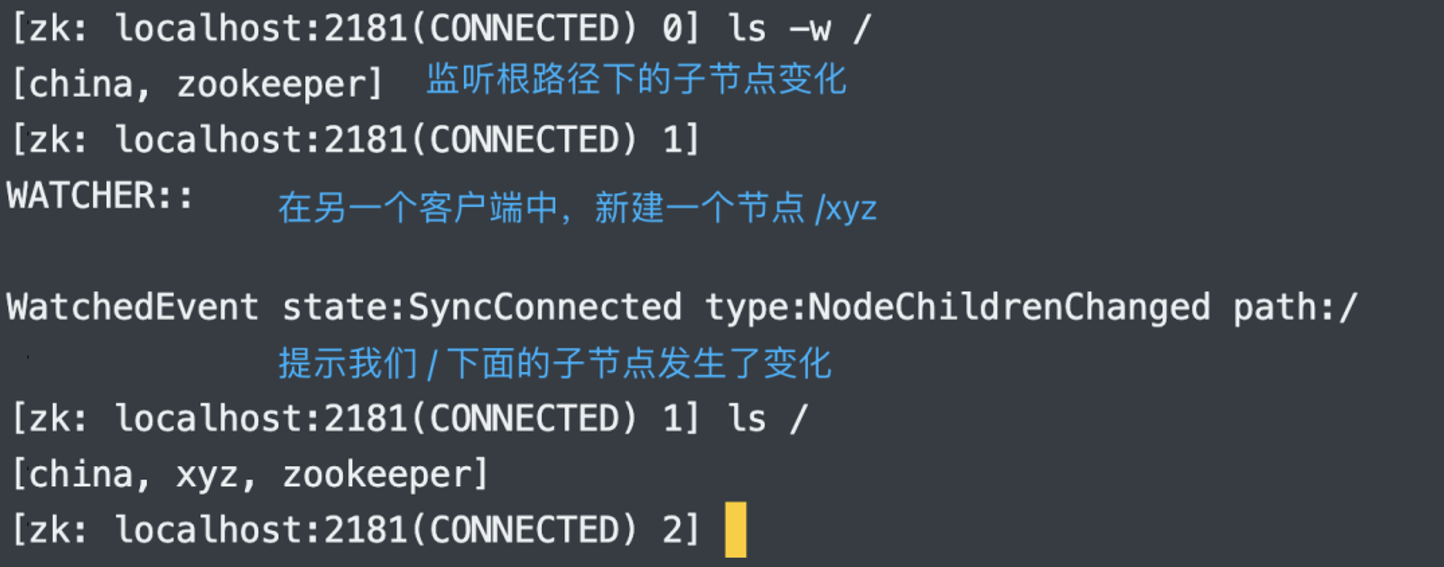
当新建一个子节点、或者删除一个子节点的时候,就会收到提示,但是修改不会,所以这里监听的变化指的是 子节点数量 的变化。
注:这里只监听子节点的变化,子节点的子节点则不在范围之内。至于实现原理,和 get -w 相同,并且执行 ls -w 之后也只会监听一次。
10.删除节点:delete
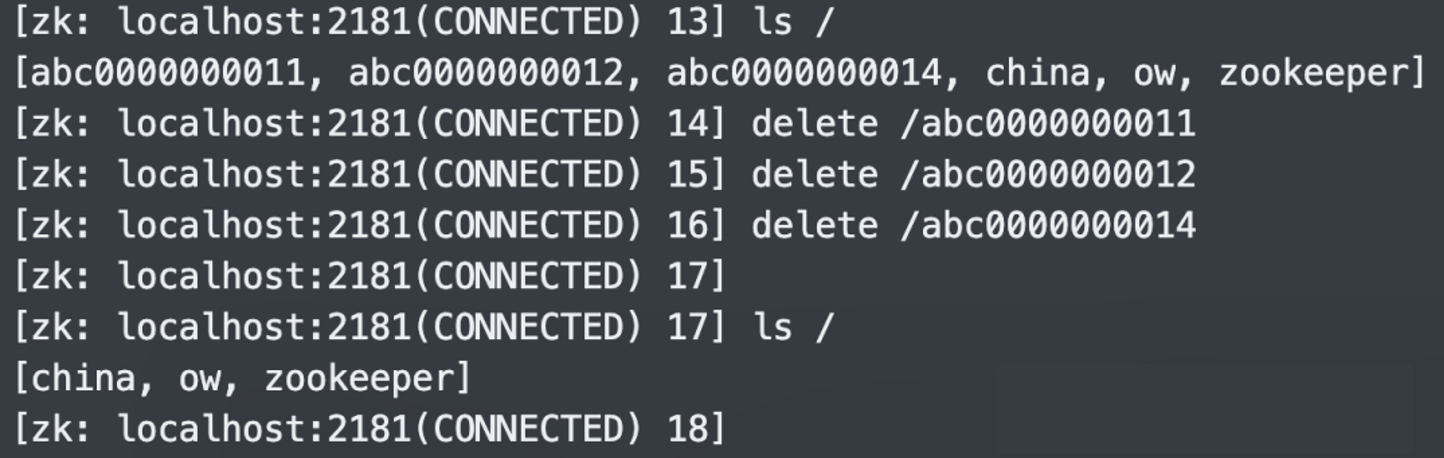
注意:delete 只能删除叶子节点,而非叶子节点、比如这里的 /china 就无法删除。
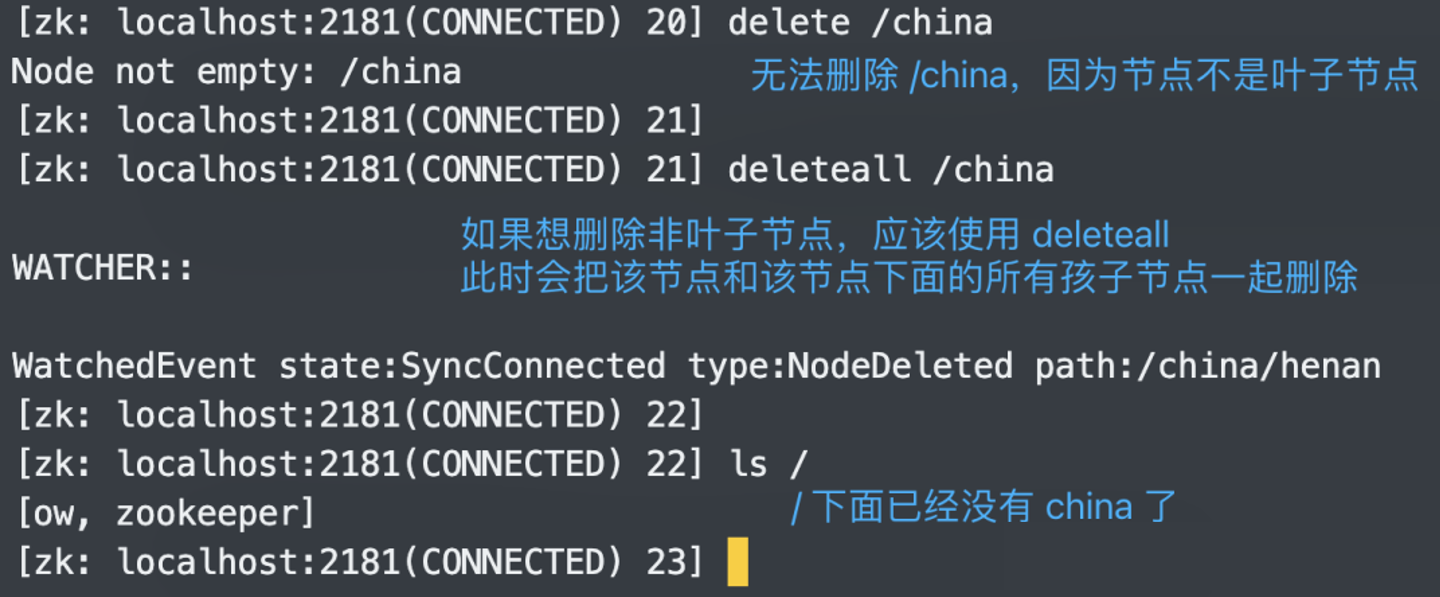
在 3.5.0 之前删除非叶子节点使用的命令是 rmr,当然现在也可以使用,只不过废弃了。

11.查看节点状态:stat
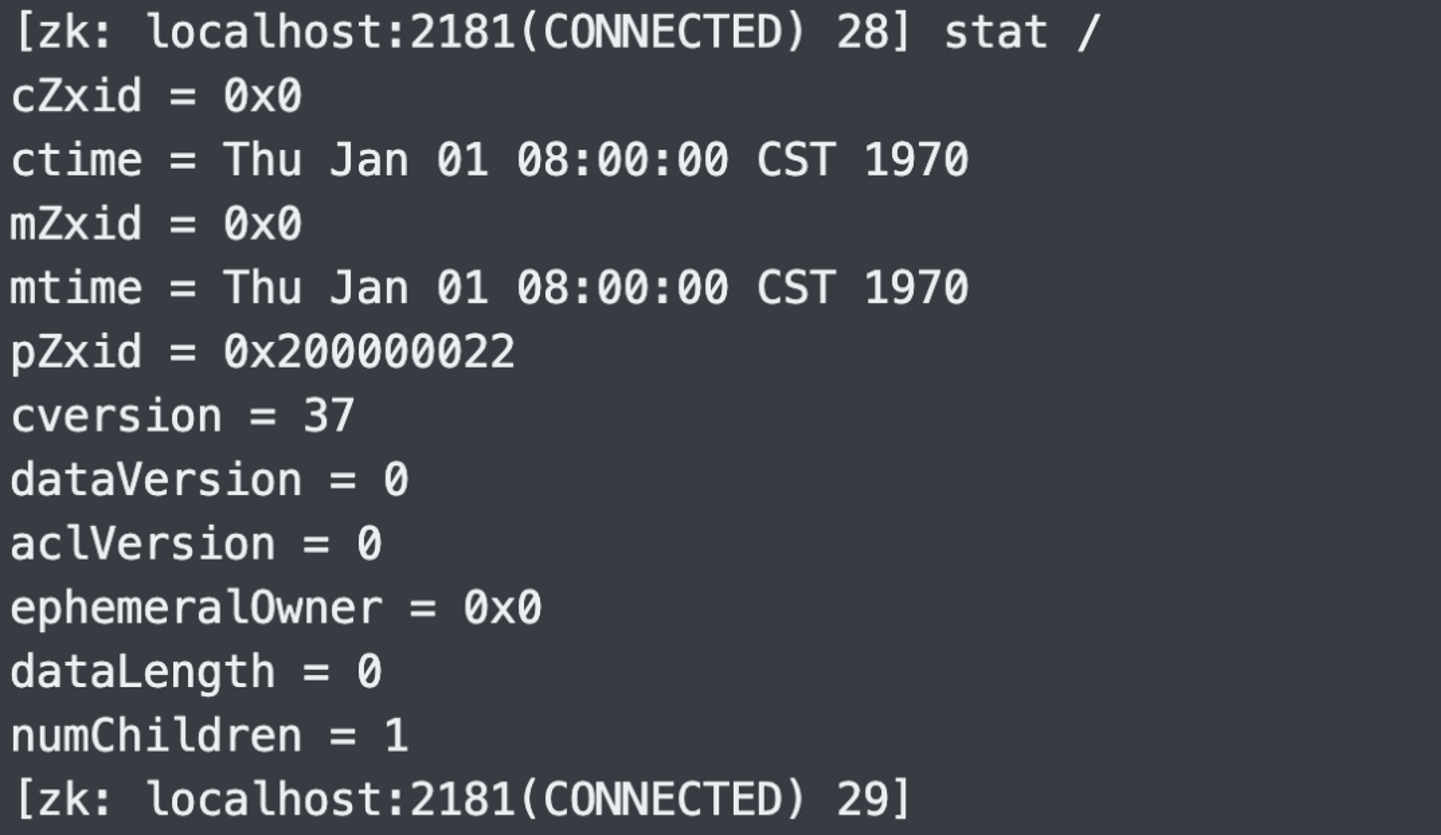
这些字段的含义我们已经介绍过了,还可以通过 ls -s 或者 get -s 获取。



















 303
303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











