








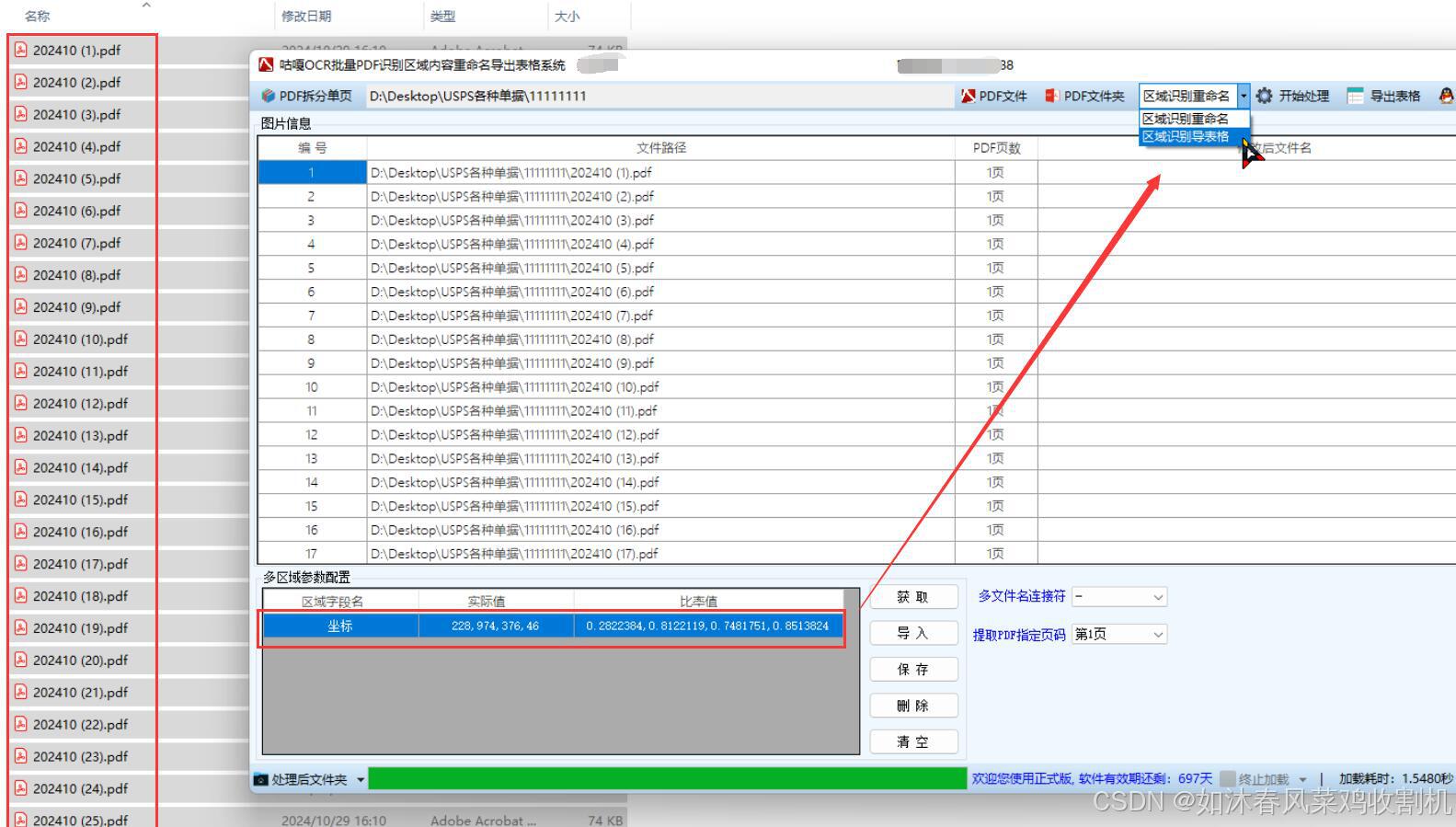

一、OCR识别技术应用于资料电子化自动归档解决方案
-
文档扫描:纸质文档通过扫描仪或高拍仪进行扫描,形成电子版PDF/图像。
-
图像预处理:将图像进行光影处理(灰度化、去噪、二值化)、倾斜校正以及扭曲处理,防止因光线、纸张倾斜影响识别结果。
-
字符切割:利用投影法将图片切割成单个字符或单词。
-
特征提取:从切割后的字符中提取出有用的特征,为后续的识别提取提供依据。
-
识别字符:这是OCR最核心的部分,涉及到深度学习、CNN等复杂的技术和算法,使用训练好的模型对新的字符图像进行识别。
-
文字后处理:文本纠错以及文本结构化,对识别结果进行矫正,以及从文本中根据特定的语言上下文关系提取需要的信息。
-
文件重命名:根据提取的信息按照预设命名组合对文件进行重命名。
-
目录创建:根据提取的信息,按照预设的目录架构设计进行新建以及识别工作。
-
文件归档:重命名的文件上传到符合识别结果的特定目录下。
以下是一个使用 WPF 和腾讯 API 实现上述 OCR 流程的详细步骤和代码示例:
步骤 1:创建 WPF 项目
- 打开 Visual Studio。
- 选择 "创建新项目"。
- 选择 "WPF 应用程序 (.NET Framework 或.NET Core)"。
- 输入项目名称,例如 "OCRWithTencentAPI",然后点击 "创建"。
步骤 2:添加必要的 NuGet 包
- 安装
Newtonsoft.Json用于处理 JSON 数据。 - 安装
System.Net.Http用于进行 HTTP 请求。
你可以在项目中通过 NuGet 包管理器添加这些包,或者在项目文件中添加以下内容:
xml
<ItemGroup>
<PackageReference Include="Newtonsoft.Json" Version="13.0.1" />
<PackageReference Include="System.Net.Http" Version="4.3.4" />
</ItemGroup>
步骤 3:设计 WPF 界面
在 MainWindow.xaml 中添加以下内容:
xml
<Window x:Class="OCRWithTencentAPI.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x=& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









