




 本文介绍了大数据的4V特性,详细讲解了MapReduce的映射和规约原理,并通过实例展示了如何使用Python实现MapReduce操作。同时,讨论了Hadoop框架下的MapReduce处理海量数据的方式,以及Hadoop生态系统中的其他工具如HDFS、YARN、Pig和Hive。最后,文章提出了一个基于MapReduce的朴素贝叶斯分类器,用于根据博主的用词习惯预测性别,展示了数据抽取和模型训练的过程。
本文介绍了大数据的4V特性,详细讲解了MapReduce的映射和规约原理,并通过实例展示了如何使用Python实现MapReduce操作。同时,讨论了Hadoop框架下的MapReduce处理海量数据的方式,以及Hadoop生态系统中的其他工具如HDFS、YARN、Pig和Hive。最后,文章提出了一个基于MapReduce的朴素贝叶斯分类器,用于根据博主的用词习惯预测性别,展示了数据抽取和模型训练的过程。
一、大数据
来源
当今社会数据量呈指数级增长,这些数据来自于用户行为监测系统、分布式系统、网络分析、传感器等。
特点(4V)
海量(Volume)、高速(Velocity)、多样(Variety)、准确(Veracity)
二、MapReduce
直观理解
MapReduce主要分为两步:映射(Map)和规约(Reduce)。
Map:负责任务分解,分解为若干个“简单的任务”来并行处理,前提是这些任务没有必然的依赖关系。python中的map函数:map(function, 列表1,列表2,...)。
Reduce:负责任务合并,把Map阶段的结果进行全局汇总。python中的reduce函数:reduce(function, 序列,初始值)。
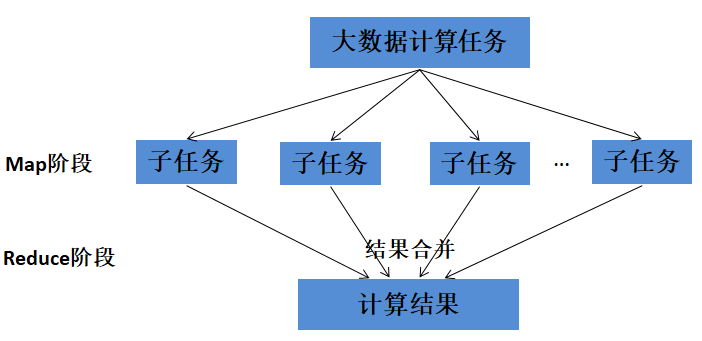
MapReduce编程模型
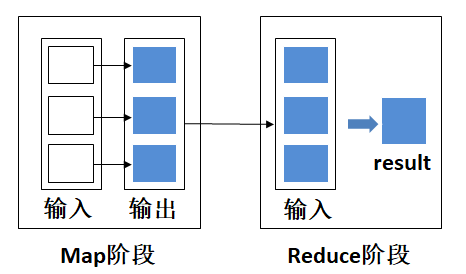
示例一:编写代码遍历一串列表,计算所有列表中数字之和。
例子一是单纯使用映射和规约两步。
a = [[1, 2, 1], [3, 2], [4, 9, 1, 0, 2]]
# 映射(建立sum函数和a之间映射关系)
sums = map(sum, a) # sums为生成器
'''
等价于:
sums = []
for sublist in a:
results = sum(sublist)
sums.append(results)
'''
# 规约(需要对返回结果的每一个元素应用一个函数)规约函数形式为reduce(function, sequence, initial)
def add(a, b):
return a + b
from functools import reduce
print(reduce(add, sums, 0))
"""
等价于:
initial = 0
current_result = initial
for element in sums:
current_result = add(current_result, element)
"""如何实现分布式计算?
在映射这一步把各个二级列表及函数说明分发到不同的计算机上,计算完成后,各计算机把结果返回主计算机(master)。然后master把结果发送给另一台计算机做规约。
示例二:单词统计。编写代码统计文档中的单词数量。
示例二的映射和规约都用键来调用,便于数据的区分和值的跟踪。
整体框架流程如下图所示:
(1)将原始数据转换为<k1,v1>形式。
(2) 解析后的<k1,v1>传给Map映射为中间结果形式<k2,v2>。
(3)<k2,v2>形成<k2,{v2,...}>传给Reduce,把相同k的值通过Reduce()输出形成<k3,v3>。

映射函数接收一键值对,返回键值对列表。本例中,接收的键值对:(文档编号,文档的文本内容),返回的键值对列表:(单词,单词的词频)。
def map_word_count(document_id, document):
counts = defaultdict(int)
for word in document.split():
counts[word] += 1
for word in counts:
yield (word, counts[word])shuffle操作:接收map生成器,将key值也就是word相同的单词词频append在一起,返回键值对{单词,词频列表}给reduce函数,reduce函数对词频列表进行sum操作。
def shuffle_words(results):
records = defaultdict(list)
for result in results:
for word, count in result:
records[wo 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









