







数据结构:哈希表
在进行无聊的概念原理介绍之前,我想先举个例子说明哈希表的作用,例如,我们为什么要使用哈希表?它的优势在哪?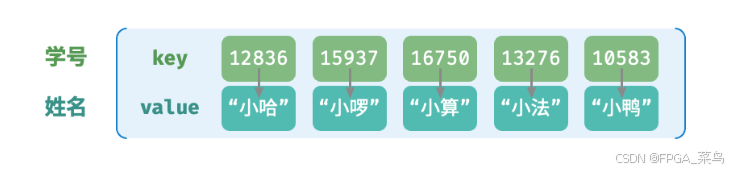
在给定的n个数据中,每个学生都有两个概念:学号、姓名。在这里要实现的功能是,通过输入学号,得到对应的姓名。
如果你使用传统的遍历查找方式查询小鸭所在的位置,需要的平均时间复杂度为O(n),最少1次最多n次。**有没有一种数据结构,能降低时间复杂度到O(1),实现快速的查找?**哈希表就能满时间复杂度要求。那其具体是怎么实现的呢?
一、哈希表的概念
哈希表(hash table),又称散列表,通过哈希算法建立key与数组index之间的映射,实现高效的元素查询。通常来说,其时间复杂度为O(1)。
二、哈希表的实现原理
先考虑最简单的情况,用一个数组来实现哈希表。在上述例子中,学号(键,key)和姓名(值,value),它们一同构成学号-姓名对(键值对,key-value pair),也就是哈希表的存储单元。每一个不同的学号-姓名对(键值对,key-value pair)在表中有一个数组索引(或者叫地址),该索引(index)由 哈希函数(hash function) 确定。也就是说,学号(键,key)与索引(index,hash(key))存在一个映射关系。得到这个索引后,就可以将学号-姓名对(键值对,key-value pair)存储在索引(index,hash(key))处。
这里每一处都可以用括号内的内容代替

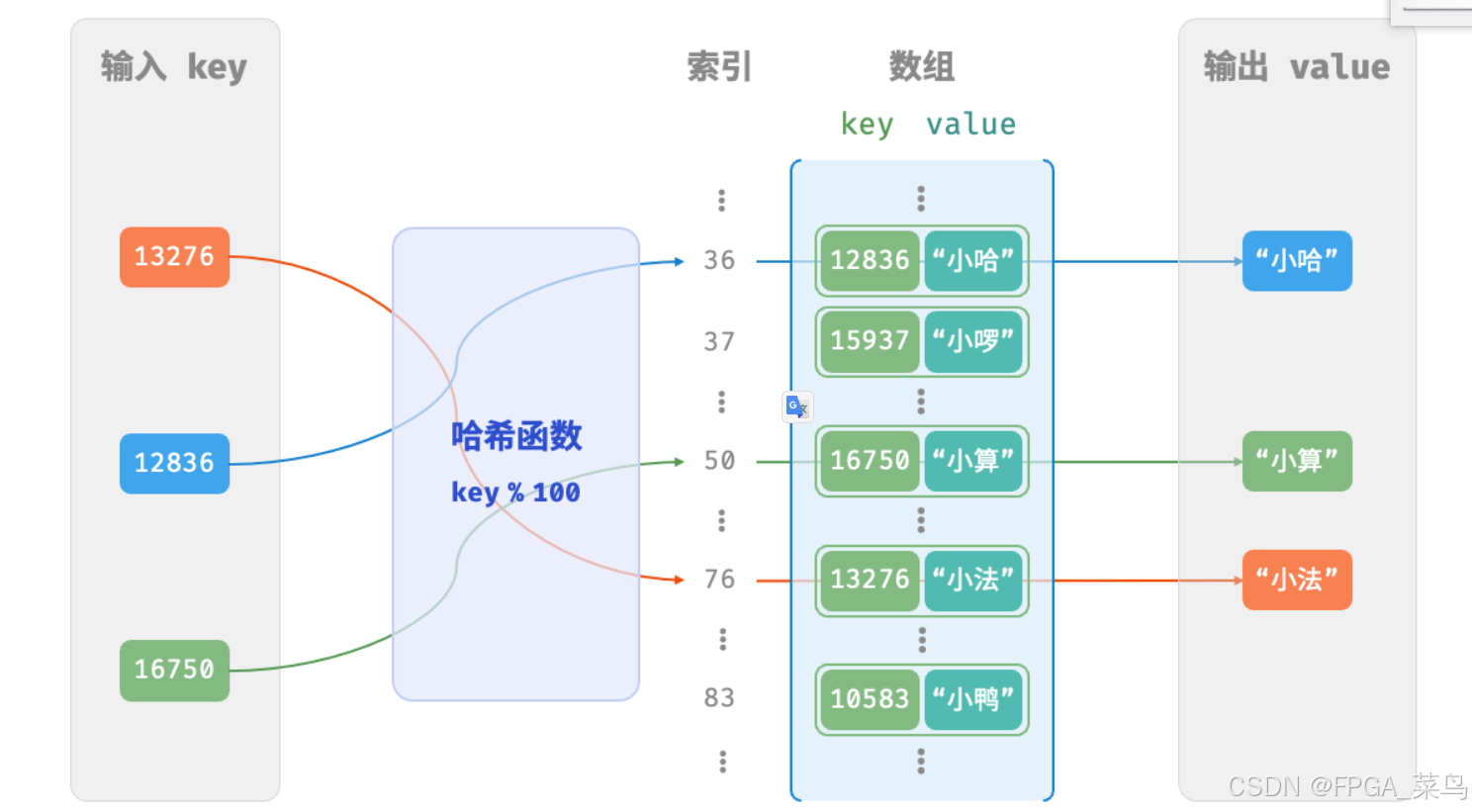
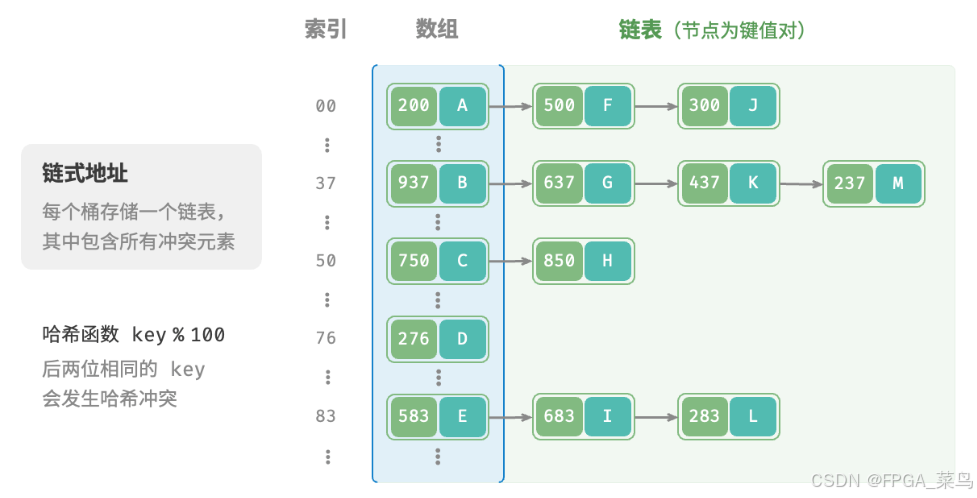
设数组长度 capacity = 100、哈希函数为 key % 100 (即:index = key % 100)。图以学号(键,key)和 value 姓名为例,展示了哈希函数的工作原理。
这里你大概已经能理解哈希表了。为了进行强化理解,以查字典再举一个例子。
假设有一本中文词典,里面包含了所有的汉字(键,key)以及其释义(值,value)。我们要做的,就是通过汉字(键,key)查找其释义(值,value)。和之前的问题一样,如果你想要在其中找到某一个汉字的释义,你就需要从头至尾核查,如果运气差,需要遍历整本词典才能找到你要查的东西。
现在,有一个拼音-页码表(哈希函数,hash function),能让你实现快速查找。(实际上,查表之前,你在脑海中进行了字-拼音的转换,**字(键,key)-拼音-页码(index)**这一转化的过程才是完整的哈希函数(hash function)。)确定页码后,你就能快速找到你想要的汉字和释义(键值对,key-value pair)了。
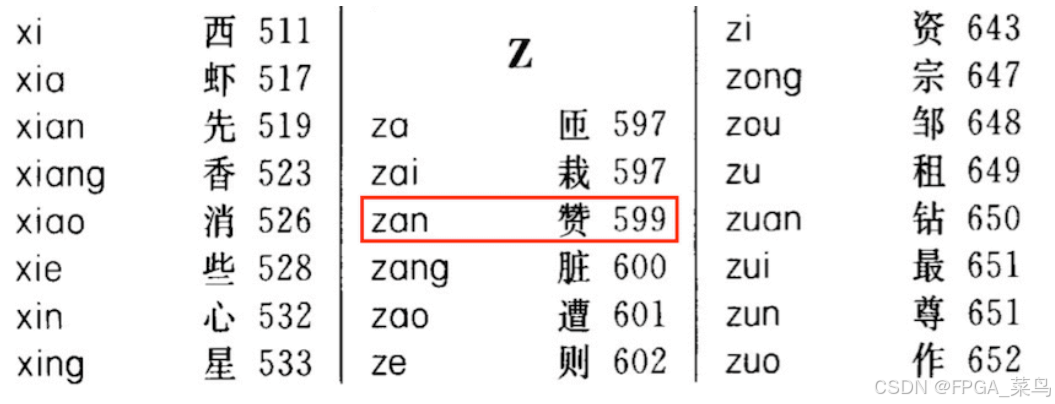
但是,上面的例子还存在一个问题,放在同一页码(index)的汉字可能不止一个,这时候通过字(键,key)给出拼音从而获取到的汉字释义(值,value)是哪个呢?这就出现了碰撞(hash collision)。
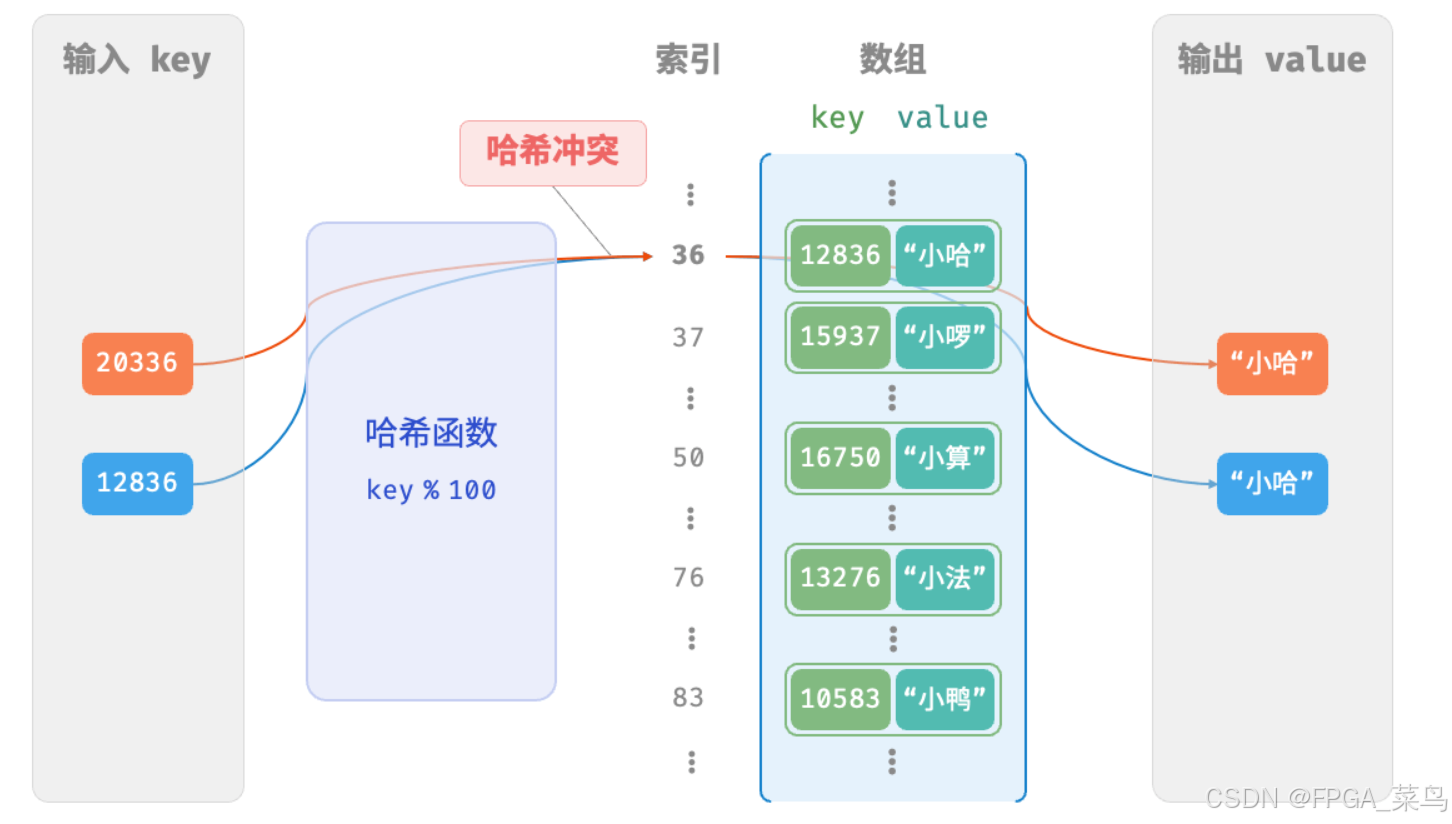
回到学号-姓名对(键值对,key-value pair)的例子,当输入的学号(键,key)后两位相同时,哈希函数的输出的姓名(值,value)也相同。例如,查询学号为 12836 和 20336 的两个学生时,得到同一个姓名 小哈:
12836 % 100 = 36
20336 % 100 = 36
理论上来说,这不是哈希表单独存在的问题,而是数据结构中一个共性的问题。数据个数少于数组长度时,这种情况只是有可能出现。如果是普通数组做逐个记录,在数据个数少于数组长度时不会有这个问题,毕竟这种数据结构减少了时间复杂度,必然在其他方面略逊一筹,这是一种快速查找付出的代价。
而如果数据个数超过数组长度时,这种冲突就是必然的,对应普通数组做逐个记录时出现存储空间不够的情况。究其原因,无论是哪种存储方式,这只是一种新型的数据结构,只是在存储 顺序上做了一些人为安排,但仍要受到 一个存储单元一个数据的约束,只是这种多个输入对应相同输出的情况在哈希表中并不会以报错的形式体现。换句话说,这个问题存在于任何数据结构中,只是哈希表会输出错误结果,而其他数据结构会直接报告错误操作。
想要解决这个问题,可以从多个方面入手:
一、存储扩容(增加数组长度)
二、改良哈希表的数据结构
1.链式地址哈希表(即每个存储单元不再是任何一种数据类型,而是一个链表,是一种复合结构。)(理论上其实也是一种扩容)
2.开放寻址哈希表
(1)线性探测
哈希冲突的关键是,后来数据想要存储的位置被先来的数据占位了。既然这个位置不能坐,那我就坐他后面。
因此插入和查找的规律如下。
插入元素:通过哈希函数计算桶索引,若发现索引处内已有元素,则从冲突位置向后线性遍历(步长通常为 1),直至找到空索引,将元素插入其中。
查找元素:若发现哈希冲突,则使用相同步长向后进行线性遍历,直到找到对应元素并返回;如果遇到空索引,说明目标元素不在哈希表中,返回 None 。
(2)平方探测
线性探测存在的问题是,数据容易产生聚集,聚体则会增加遍历的时间。为了缓解这种情况,遍历插入或查找的补偿修改为探测次数的平方。
(3)多次哈希
更改遍历方式,改为遍历预先设计好的几个不同的哈希算法。
插入元素:若f1(x)出现冲突,则尝试 使用f2(x) ,以此类推,直到找到空位后插入元素。
查找元素:在相同的哈希函数顺序下进行查找,直到找到目标元素时返回;若遇到空位或已尝试所有哈希函数,说明哈希表中不存在该元素,则返回 None 。
开放寻址的共性问题是:不能随意删除元素。设想一下,如果你需要的元素的前一个遍历元素被无故删除了,那遍历就会止于上一步,后续的遍历元素就成了死元素,无法被读取。这种情况类似于链表,你不能删除链表元素而不改变前后元素的指向指针。

在这里,可以引入懒删除机制:不直接从哈希表中移除元素,而是利用一个 常量TOMBSTONE 来标记这个索引位置。在该机制下,空和 TOMBSTONE 都代表索引位置可插入。但不同的是,查找元素时如果探测到 TOMBSTONE ,应该继续遍历,因为其之下可能还存在键值对。
一些问题
问题1:为什么普通的哈希表存储了key不去检查?
答:因为检查也没用,无非是不输出数据,和普通数据结构一样报错。当使用链式地址或开放寻址哈希表时,就需要验证key,因为验证的过程相当于遍历操作,在这里验证key是有意义的。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









