







 本文介绍了GPU的存储器架构,包括全局内存、本地内存、寄存器堆、常量内存和纹理内存。全局内存可供所有块读写,但速度较慢。寄存器是最快的存储器,而本地内存作为寄存器溢出的补充。常量内存用于存储只读数据,纹理内存则针对特定访问模式提供加速。通过对这些内存类型的深入理解,可以优化CUDA程序的性能。
本文介绍了GPU的存储器架构,包括全局内存、本地内存、寄存器堆、常量内存和纹理内存。全局内存可供所有块读写,但速度较慢。寄存器是最快的存储器,而本地内存作为寄存器溢出的补充。常量内存用于存储只读数据,纹理内存则针对特定访问模式提供加速。通过对这些内存类型的深入理解,可以优化CUDA程序的性能。
一、存储器架构
在GPU上的代码执行被划分为流多处理器、块和线程。GPU有几个不同的存储器空间,每个存储器空间都有特定的特征和用途以及不同的速度和范围。这个存储空间按层次结构划分为不同的组块,比如全局内存、共享内存、本地内存、常量内存和纹理内存,每个组块都可以从程序中的不同点访问。
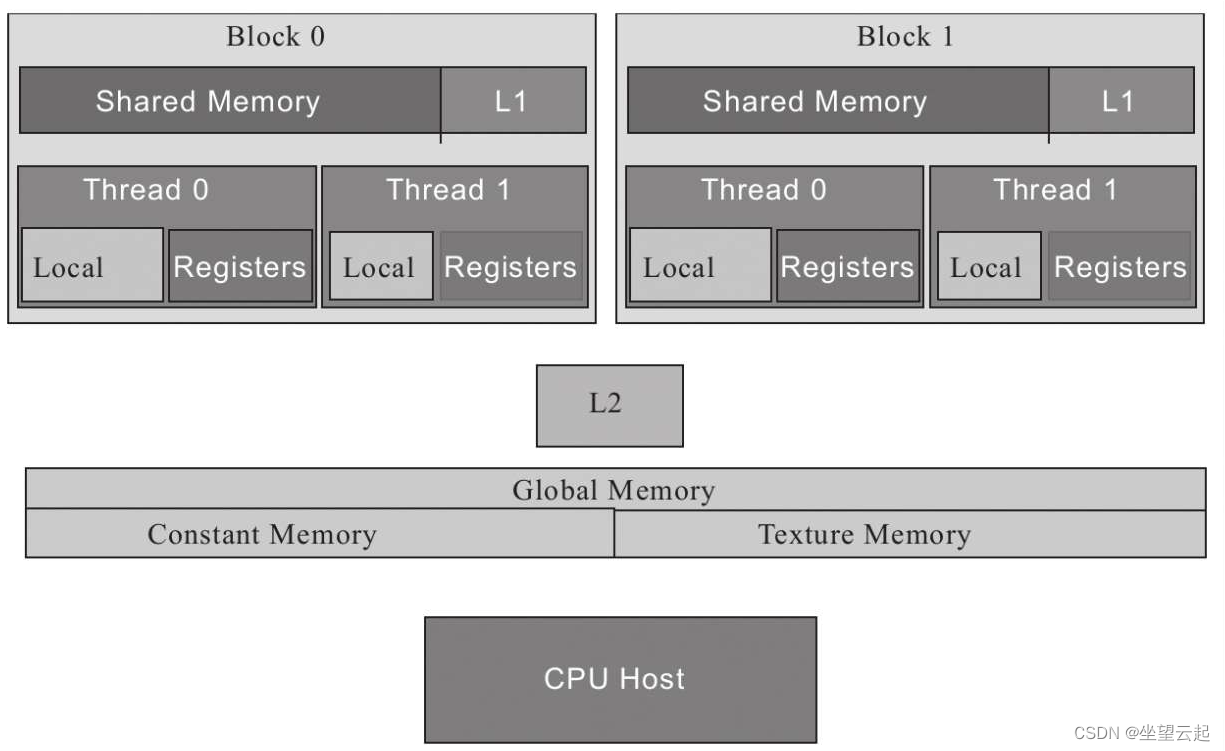
GPU有一级和二级缓存(即L1缓存和L2缓存)。常量内存则是用于存储常量和内核参数之类的只读数据。最后,存在纹理内存,这种内存可以利用各种2D和3D的访问模式。
二、全局内存
所有的块都可以对全局内存进行读写。该存储器较慢,但是可以从你的代码的任何地方进行读写。缓存可加速对全局内存的访问。所有通过cudaMalloc分配的存储器都是全局内存。
使用全局内存示例
#include <stdio.h>
#define N 5
__global__ void gpu_global_memo
 订阅专栏 解锁全文
订阅专栏 解锁全文



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











