







 本文详细介绍了聚类的基本概念、应用场景以及多种聚类算法的思想,包括基于分布、质心、连通性、密度和层次的算法。还探讨了如K-Means、DBSCAN、Mean Shift等流行算法,并通过实例展示了它们的效果。最后推荐了PyClustering和CLASSIX两个聚类算法库。
本文详细介绍了聚类的基本概念、应用场景以及多种聚类算法的思想,包括基于分布、质心、连通性、密度和层次的算法。还探讨了如K-Means、DBSCAN、Mean Shift等流行算法,并通过实例展示了它们的效果。最后推荐了PyClustering和CLASSIX两个聚类算法库。
一、聚类简介
1、概述
实质上是机器学习中的一种无监督学习方法。并不需要我们对数据进行标记。通常,它被用作在一组示例中找到有意义的结构、解释性基础过程、生成特征、进行分组的等。
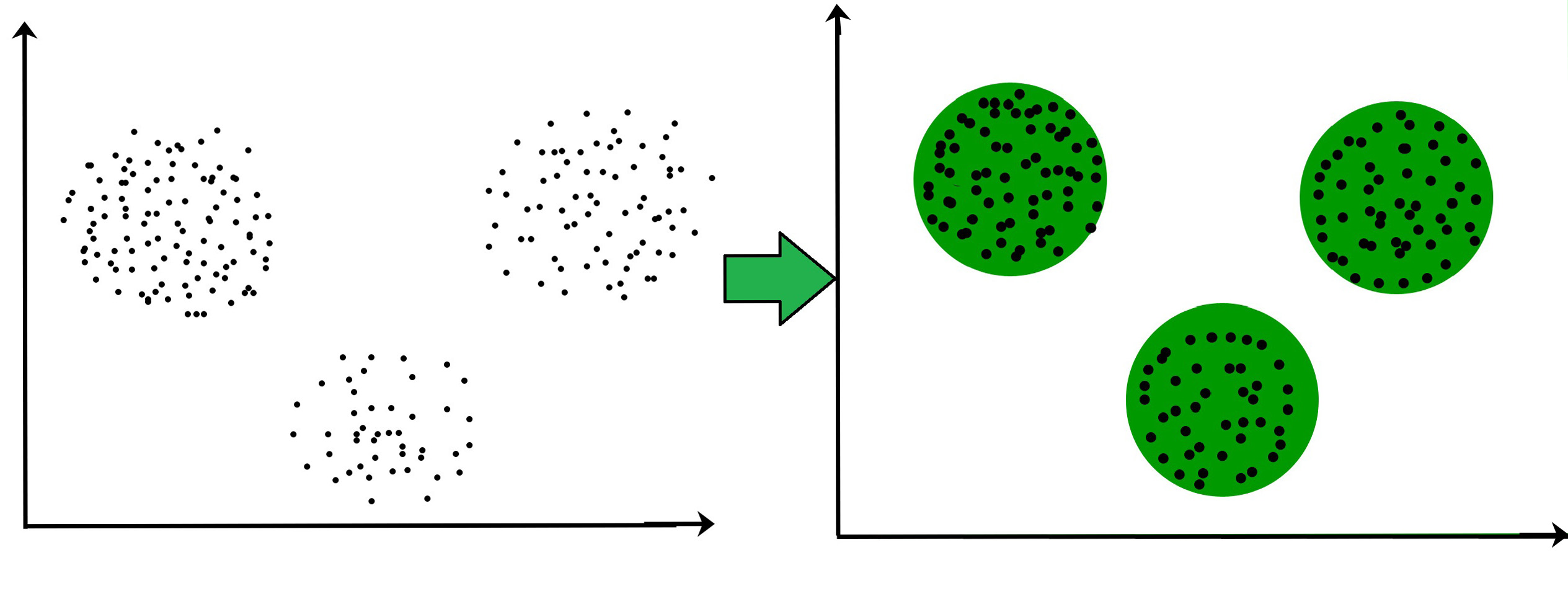
聚类是将总体或数据点划分为多个组的任务,以使同一组中的数据点与同一组中的其他数据点更相近。
例如下面的分簇
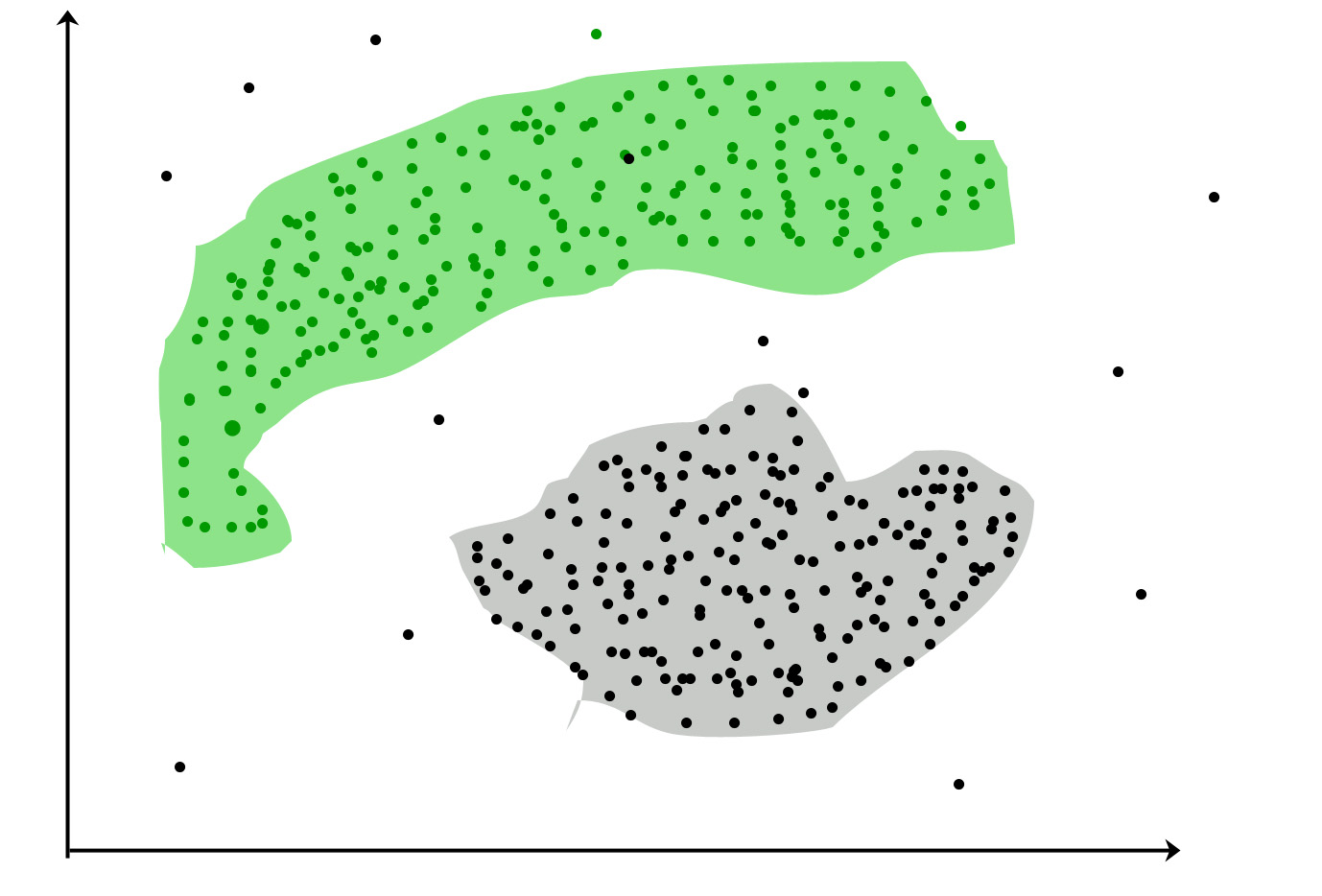
但是簇不总是规则形状的。
2、常见应用
在癌细胞的识别中:聚类算法被广泛用于癌细胞的识别。它将癌性和非癌性数据集分为不同的组。</
实质上是机器学习中的一种无监督学习方法。并不需要我们对数据进行标记。通常,它被用作在一组示例中找到有意义的结构、解释性基础过程、生成特征、进行分组的等。
聚类是将总体或数据点划分为多个组的任务,以使同一组中的数据点与同一组中的其他数据点更相近。
例如下面的分簇
但是簇不总是规则形状的。
在癌细胞的识别中:聚类算法被广泛用于癌细胞的识别。它将癌性和非癌性数据集分为不同的组。</
 494
210
494
210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文

























