



 文章探讨了分片技术在数据库中的应用,区分了分片(如CitusData和MongoDB分片集群)与分布式数据库(如GoogleSpanner和YugabyteDB)之间的主要区别。分片依赖协调器,而分布式数据库则基于无共享架构,节点间直接通信。理解两者对数据库设计至关重要。
文章探讨了分片技术在数据库中的应用,区分了分片(如CitusData和MongoDB分片集群)与分布式数据库(如GoogleSpanner和YugabyteDB)之间的主要区别。分片依赖协调器,而分布式数据库则基于无共享架构,节点间直接通信。理解两者对数据库设计至关重要。
分片并不意味着分布式
·
9月22日
分片是一种在多个独立数据库实例之间分配数据和负载的技术。 此方法通过将原始数据集拆分为分片,然后将其分布在多个数据库实例中来利用水平可扩展性。
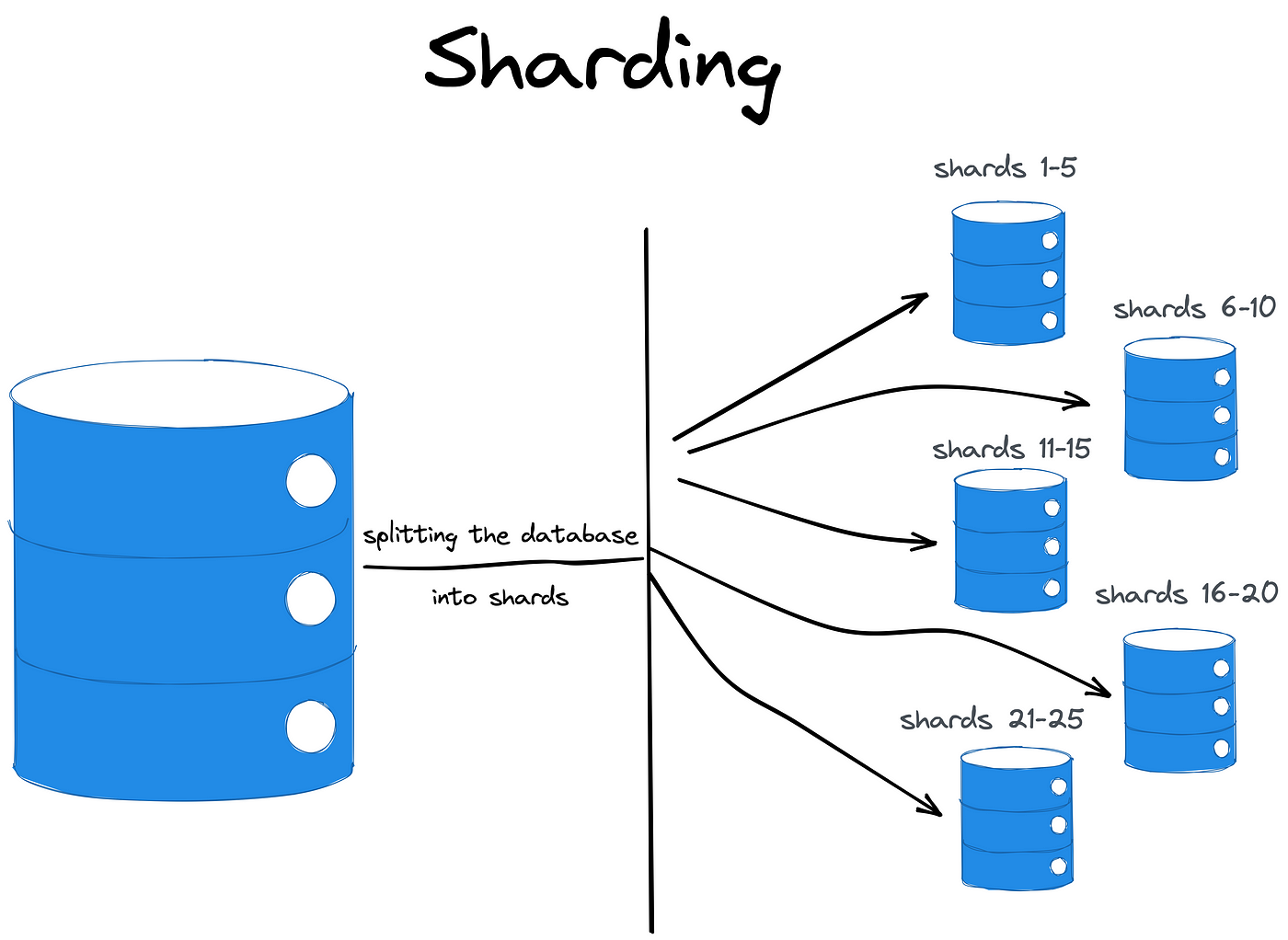
但是,即使分片的定义中出现了动词“分布”,分片数据库也不是分布式数据库。
分片解决方案
每一种分片解决方案的架构中都有一个关键组件。 该组件可以有各种名称,包括协调器、路由器或导向器:
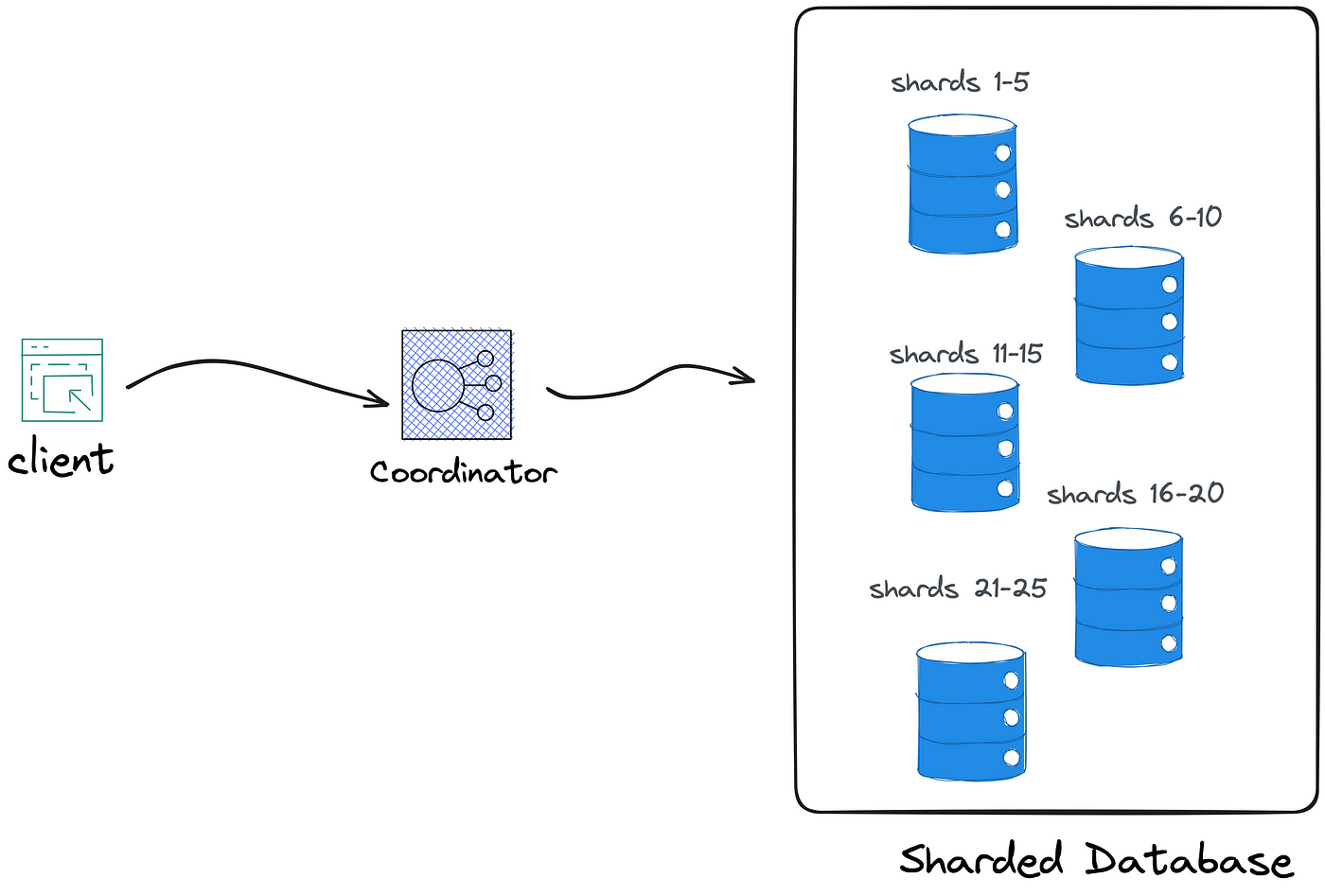
协调器是唯一了解数据分布的组件。 它将客户端请求映射到特定的分片,然后映射到相应的数据库实例。 这就是为什么客户端必须始终通过协调器路由其请求。
例如,如果客户端想要将新记录插入到“Car”表中,则请求首先发送到协调器。 协调器将记录的主键映射到其中一个分片,然后将请求转发到负责该分片的数据库实例。
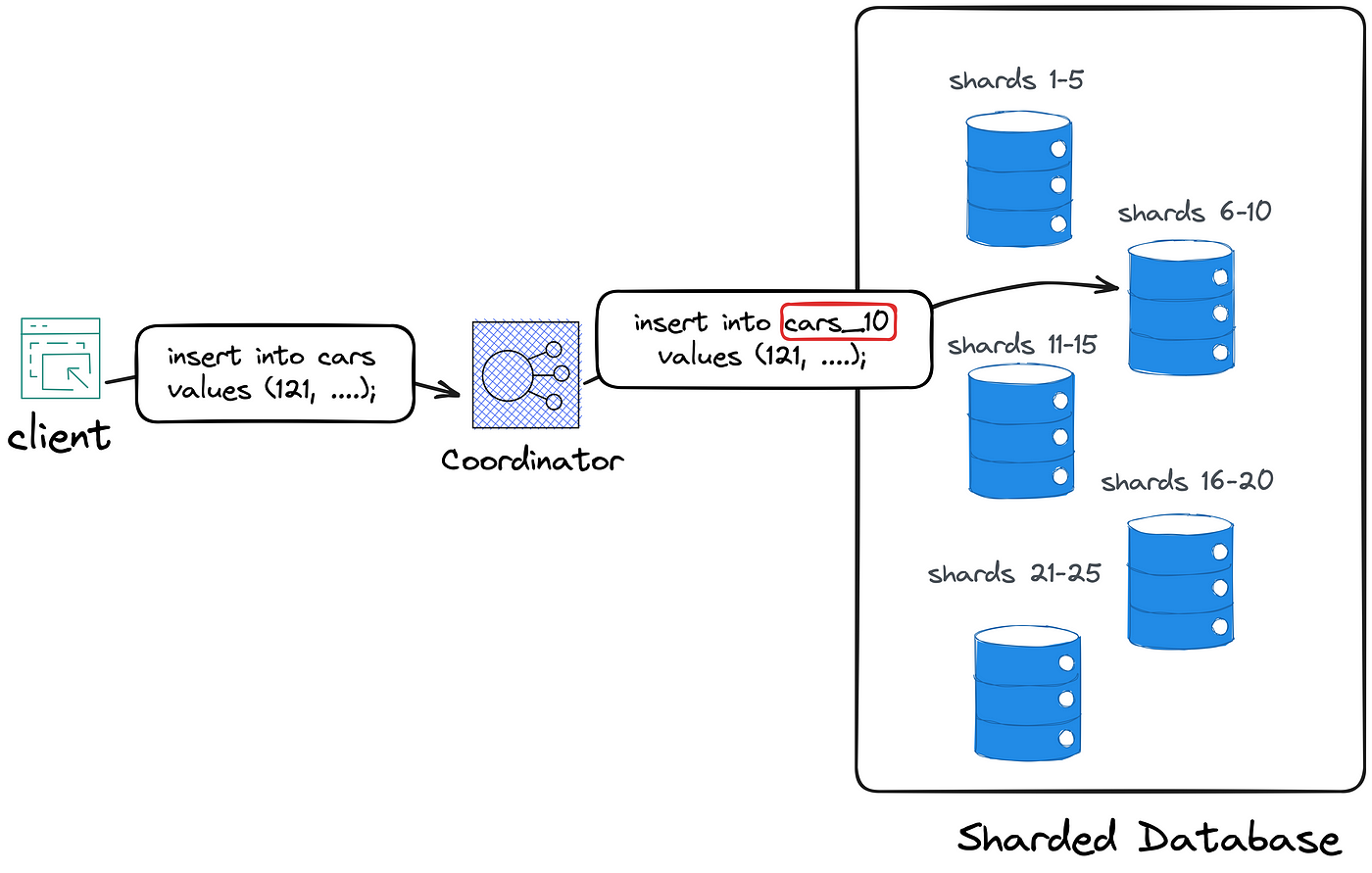
在上面的架构中,首先,协调器将键“121”映射到分片“10”,然后将记录插入到表“car_10”中,该表存储在拥有分片“10”的数据库实例上
然而,仍然存在一个问题:为什么分片解决方案中甚至需要协调器? 答案很简单。 分片存储在专为单服务器部署而设计的数据库实例上。
这些数据库实例不相互通信,也不支持任何促进此类通信的协议。 他们彼此不知情,存在于自己的孤立环境中,没有意识到他们是更大系统的一部分。
因此,协调器在分片解决方案中是不可或缺的。 如果您有兴趣深入研究分片数据库架构,请考虑探索 CitusData 或 Azure CosmosDB for PostgreSQL、Vitess for MySQL、Oracle 分布式自治数据库和 MongoDB 分片集群。
分布式数据库
与分片数据库解决方案非常相似,分布式数据库也采用类似的分片技术来跨数据库节点集群分布数据和加载。 然而,与分片解决方案不同,分布式数据库不依赖于协调器组件。
分布式数据库建立在无共享架构之上,该架构没有像协调器这样的单一组件,需要做出大量决策:
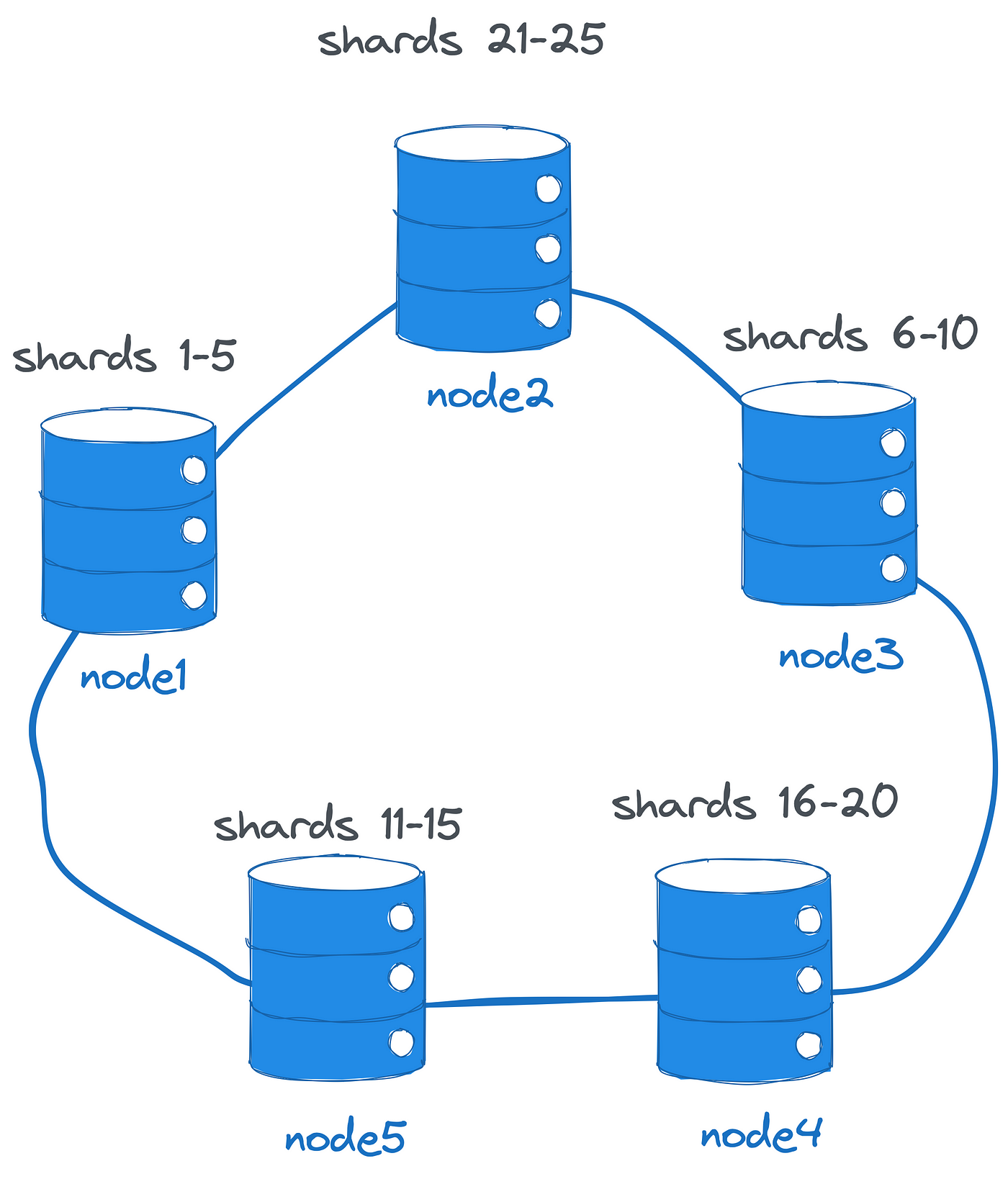
集群中的所有节点都了解彼此,从而了解数据分布。 通过直接通信,每个节点都可以将客户端请求路由到适当的分片所有者。 此外,它们还可以执行和协调多节点交易。 当扩展到更多节点时,集群会自动重新平衡并拆分分片。 节点维护数据的冗余副本(基于配置的复制因子),并且即使某些节点出现故障,也可以在不停机的情况下继续操作。
所有这些对客户端来说都是透明的,客户端只需与任何节点建立连接并允许该节点管理分布式方面。
例如,客户端可能连接到“node1”并插入 ID 为“121”的新“Car”记录。 如果“node1”是记录分片的所有者,那么它将在本地存储记录并采用共识算法将更改复制到其他节点的子集。 如果没有,“node1”会将记录转发给分片的所有者,该所有者可能是“node4”。
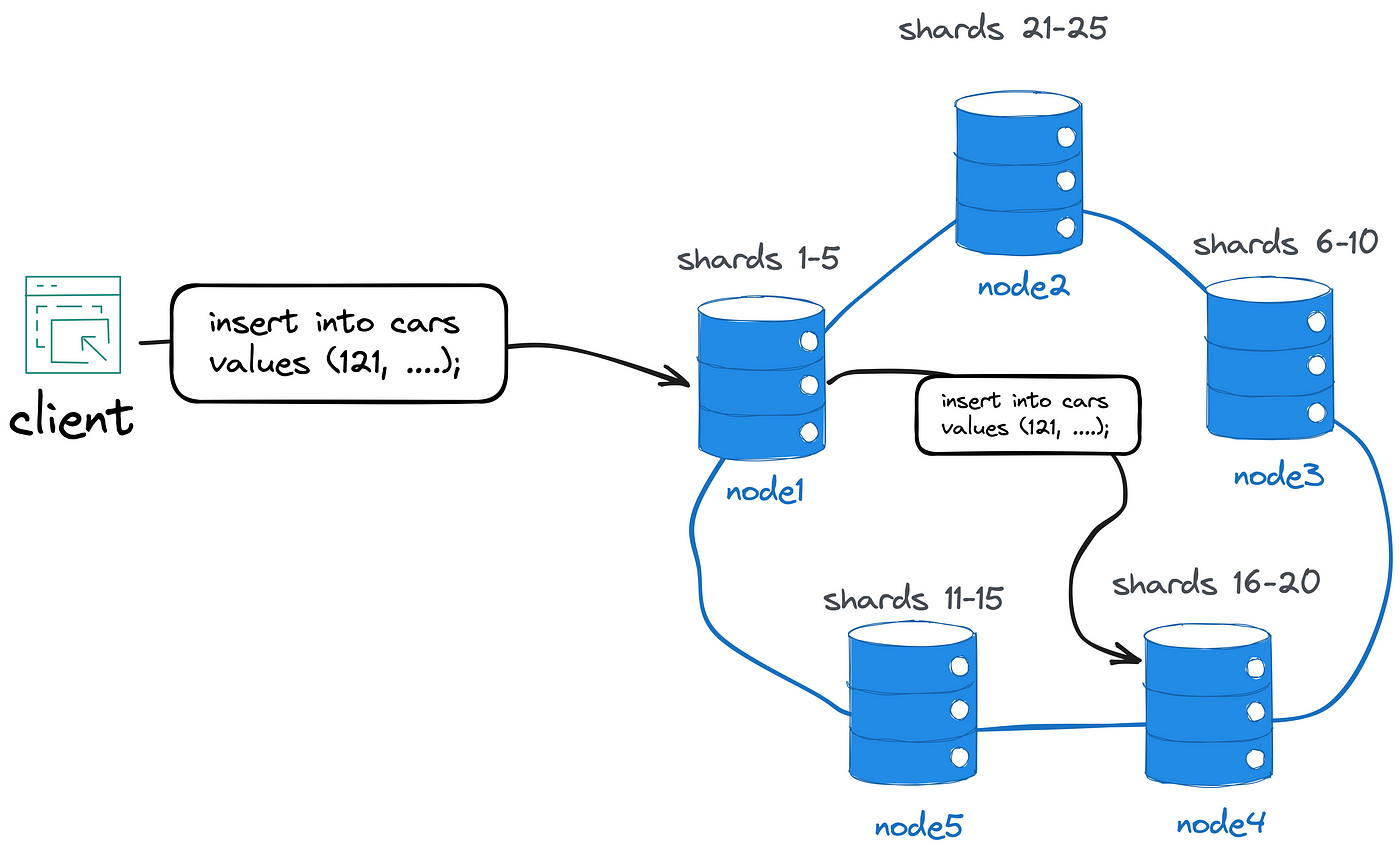
如果您有兴趣探索真正的分布式数据库的架构,请考虑研究 Google Spanner、YugabyteDB、CockroachDB、Apache Cassandra 或 Apache Ignite。
在数据库领域es,分片和分布经常被混为一谈,但它们有不同的目的。
虽然分片涉及将数据拆分到多个独立实例中,但这并不意味着系统本质上是分布式的。 分片解决方案中协调器的存在,将客户端请求引导到适当的分片,强调了这种区别。
另一方面,建立在无共享架构之上的分布式数据库缺乏这种集中的协调器。 这些系统中的节点相互了解、管理数据分发并无缝处理客户端请求。
两种架构都有其优点,了解它们的细微差别对于明智的数据库设计和选择至关重要。

















 441
441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









